大家好,又见面了,我是你们的朋友全栈君。
一、什么是协同过滤?
协同过滤是利用集体智慧的一个典型方法。要理解什么是协同过滤 (Collaborative Filtering, 简称 CF),首先想一个简单的问题,如果你现在想看个电影,但你不知道具体看哪部,你会怎么做?大部分的人会问问周围的朋友,看看最近有什么好看的电影推荐,而我们一般更倾向于从口味比较类似的朋友那里得到推荐。这就是协同过滤的核心思想。
协同过滤一般是在海量的用户中发掘出一小部分和你品位比较类似的,在协同过滤中,这些用户成为邻居,然后根据他们喜欢的其他东西组织成一个排序的目录作为推荐给你。当然其中有一个核心的问题:
- 如何确定一个用户是不是和你有相似的品位?
- 如何将邻居们的喜好组织成一个排序的目录?
协同过滤相对于集体智慧而言,它从一定程度上保留了个体的特征,就是你的品位偏好,所以它更多可以作为个性化推荐的算法思想。可以想象,这种推荐策略在 Web 2.0 的长尾中是很重要的,将大众流行的东西推荐给长尾中的人怎么可能得到好的效果,这也回到推荐系统的一个核心问题:了解你的用户,然后才能给出更好的推荐。
协同过滤推荐算法是诞生最早,并且较为著名的推荐算法。主要的功能是预测和推荐。算法通过对用户历史行为数据的挖掘发现用户的偏好,基于不同的偏好对用户进行群组划分并推荐品味相似的商品。协同过滤推荐算法分为两类,分别是基于用户的协同过滤算法(user-based collaboratIve filtering),和基于物品的协同过滤算法(item-based collaborative filtering)。简单的说就是:人以类聚,物以群分。
二、协同过滤的基本流程
首先,要实现协同过滤,需要以下几个步骤
- 收集用户偏好
- 找到相似的用户或物品
- 计算推荐
1、收集用户偏好
要从用户的行为和偏好中发现规律,并基于此给予推荐,如何收集用户的偏好信息成为系统推荐效果最基础的决定因素。用户有很多方式向系统提供自己的偏好信息,而且不同的应用也可能大不相同,下面举例进行介绍:


以上列举的用户行为都是比较通用的,推荐引擎设计人员可以根据自己应用的特点添加特殊的用户行为,并用他们表示用户对物品的喜好。在一般应用中,我们提取的用户行为一般都多于一种,关于如何组合这些不同的用户行为,基本上有以下两种方式:
-
将不同的行为分组
一般可以分为“查看”和“购买”等等,然后基于不同的行为,计算不同的用户 / 物品相似度。类似于当当网或者 Amazon 给出的“购买了该图书的人还购买了 …”,“查看了图书的人还查看了 …” -
加权操作
根据不同行为反映用户喜好的程度将它们进行加权,得到用户对于物品的总体喜好。一般来说,显式的用户反馈比隐式的权值大,但比较稀疏,毕竟进行显示反馈的用户是少数;同时相对于“查看”,“购买”行为反映用户喜好的程度更大,但这也因应用而异。
收集了用户行为数据,我们还需要对数据进行一定的预处理,其中最核心的工作就是:减噪和归一化。
-
减噪
用户行为数据是用户在使用应用过程中产生的,它可能存在大量的噪音和用户的误操作,我们可以通过经典的数据挖掘算法过滤掉行为数据中的噪音,这样可以是我们的分析更加精确。 -
归一化
如前面讲到的,在计算用户对物品的喜好程度时,可能需要对不同的行为数据进行加权。但可以想象,不同行为的数据取值可能相差很大,比如,用户的查看数据必然比购买数据大的多,如何将各个行为的数据统一在一个相同的取值范围中,从而使得加权求和得到的总体喜好更加精确,就需要我们进行归一化处理。最简单的归一化处理,就是将各类数据除以此类中的最大值,以保证归一化后的数据取值在 [0,1] 范围中。
进行的预处理后,根据不同应用的行为分析方法,可以选择分组或者加权处理,之后我们可以得到一个用户偏好的二维矩阵,一维是用户列表,另一维是物品列表,值是用户对物品的偏好,一般是 [0,1] 或者 [-1, 1] 的浮点数值。
2、找到相似的用户或物品
当已经对用户行为进行分析得到用户喜好后,我们可以根据用户喜好计算相似用户和物品,然后基于相似用户或者物品进行推荐,这就是最典型的 CF 的两个分支:基于用户的 CF 和基于物品的 CF。这两种方法都需要计算相似度,下面我们先看看最基本的几种计算相似度的方法。
(1)、相似度的计算
关于相似度的计算,现有的几种基本方法都是基于向量(Vector)的,其实也就是计算两个向量的距离,距离越近相似度越大。在推荐的场景中,在用户 – 物品偏好的二维矩阵中,我们可以将一个用户对所有物品的偏好作为一个向量来计算用户之间的相似度,或者将所有用户对某个物品的偏好作为一个向量来计算物品之间的相似度。下面我们详细介绍几种常用的相似度计算方法:
- 欧几里德距离(Euclidean Distance)
最初用于计算欧几里德空间中两个点的距离,假设 x,y 是 n 维空间的两个点,它们之间的欧几里德距离是:

可以看出,当 n=2 时,欧几里德距离就是平面上两个点的距离。
当用欧几里德距离表示相似度,一般采用以下公式进行转换:距离越小,相似度越大。

- 皮尔逊相关系数(Pearson Correlation Coefficient)
皮尔逊相关系数一般用于计算两个定距变量间联系的紧密程度,它的取值在 [-1,+1] 之间。

sx, sy是 x 和 y 的样品标准偏差。
- Cosine 相似度(Cosine Similarity)
Cosine 相似度被广泛应用于计算文档数据的相似度:

Tanimoto 系数(Tanimoto Coefficient)
- Tanimoto 系数
也称为 Jaccard 系数,是 Cosine 相似度的扩展,也多用于计算文档数据的相似度:

2、相似邻居的计算
介绍完相似度的计算方法,下面我们看看如何根据相似度找到用户 – 物品的邻居,常用的挑选邻居的原则可以分为两类:图 1 给出了二维平面空间上点集的示意图。

- 固定数量的邻居:K-neighborhoods 或者 Fix-size neighborhoods
不论邻居的“远近”,只取最近的 K 个,作为其邻居。如图 1 中的 A,假设要计算点 1 的 5- 邻居,那么根据点之间的距离,我们取最近的 5 个点,分别是点 2,点 3,点 4,点 7 和点 5。但很明显我们可以看出,这种方法对于孤立点的计算效果不好,因为要取固定个数的邻居,当它附近没有足够多比较相似的点,就被迫取一些不太相似的点作为邻居,这样就影响了邻居相似的程度,比如图 1 中,点 1 和点 5 其实并不是很相似。
- 基于相似度门槛的邻居:Threshold-based neighborhoods
与计算固定数量的邻居的原则不同,基于相似度门槛的邻居计算是对邻居的远近进行最大值的限制,落在以当前点为中心,距离为 K 的区域中的所有点都作为当前点的邻居,这种方法计算得到的邻居个数不确定,但相似度不会出现较大的误差。如图 1 中的 B,从点 1 出发,计算相似度在 K 内的邻居,得到点 2,点 3,点 4 和点 7,这种方法计算出的邻居的相似度程度比前一种优,尤其是对孤立点的处理。
3、计算推荐
经过前期的计算已经得到了相邻用户和相邻物品,下面介绍如何基于这些信息为用户进行推荐。
- 基于用户的 CF(User CF)
基于用户的 CF 的基本思想相当简单,基于用户对物品的偏好找到相邻邻居用户,然后将邻居用户喜欢的推荐给当前用户。计算上,就是将一个用户对所有物品的偏好作为一个向量来计算用户之间的相似度,找到 K 邻居后,根据邻居的相似度权重以及他们对物品的偏好,预测当前用户没有偏好的未涉及物品,计算得到一个排序的物品列表作为推荐。图 2 给出了一个例子,对于用户 A,根据用户的历史偏好,这里只计算得到一个邻居 – 用户 C,然后将用户 C 喜欢的物品 D推荐给用户 A。

- 基于物品的 CF(Item CF)
基于物品的 CF 的原理和基于用户的 CF 类似,只是在计算邻居时采用物品本身,而不是从用户的角度,即基于用户对物品的偏好找到相似的物品,然后根据用户的历史偏好,推荐相似的物品给他。从计算的角度看,就是将所有用户对某个物品的偏好作为一个向量来计算物品之间的相似度,得到物品的相似物品后,根据用户历史的偏好预测当前用户还没有表示偏好的物品,计算得到一个排序的物品列表作为推荐。图 3 给出了一个例子,对于物品 A,根据所有用户的历史偏好,喜欢物品 A 的用户都喜欢物品 C,得出物品 A 和物品 C 比较相似,而用户 C 喜欢物品 A,那么可以推断出用户 C 可能也喜欢物品 C。

4、两种算法的比较
前面介绍了 User CF 和 Item CF 的基本原理,下面我们分几个不同的角度深入看看它们各自的优缺点和适用场景:
- 计算复杂度
Item CF 和 User CF 是基于协同过滤推荐的两个最基本的算法,User CF 是很早以前就提出来了,Item CF 是从 Amazon 的论文和专利发表之后(2001 年左右)开始流行,大家都觉得 Item CF 从性能和复杂度上比 User CF 更优,其中的一个主要原因就是对于一个在线网站,用户的数量往往大大超过物品的数量,同时物品的数据相对稳定,因此计算物品的相似度不但计算量较小,同时也不必频繁更新。但我们往往忽略了这种情况只适应于提供商品的电子商务网站,对于新闻,博客或者微内容的推荐系统,情况往往是相反的,物品的数量是海量的,同时也是更新频繁的,所以单从复杂度的角度,这两个算法在不同的系统中各有优势,推荐引擎的设计者需要根据自己应用的特点选择更加合适的算法。
- 适用场景
在非社交网络的网站中,内容内在的联系是很重要的推荐原则,它比基于相似用户的推荐原则更加有效。比如在购书网站上,当你看一本书的时候,推荐引擎会给你推荐相关的书籍,这个推荐的重要性远远超过了网站首页对该用户的综合推荐。可以看到,在这种情况下,Item CF 的推荐成为了引导用户浏览的重要手段。同时 Item CF 便于为推荐做出解释,在一个非社交网络的网站中,给某个用户推荐一本书,同时给出的解释是某某和你有相似兴趣的人也看了这本书,这很难让用户信服,因为用户可能根本不认识那个人;但如果解释说是因为这本书和你以前看的某本书相似,用户可能就觉得合理而采纳了此推荐。相反的,在现今很流行的社交网络站点中,User CF 是一个更不错的选择,User CF 加上社会网络信息,可以增加用户对推荐解释的信服程度。
- 推荐多样性和精度
研究推荐引擎的学者们在相同的数据集合上分别用 User CF 和 Item CF 计算推荐结果,发现推荐列表中,只有 50% 是一样的,还有 50% 完全不同。但是这两个算法确有相似的精度,所以可以说,这两个算法是很互补的。
关于推荐的多样性,有两种度量方法:
第一种度量方法是从单个用户的角度度量,就是说给定一个用户,查看系统给出的推荐列表是否多样,也就是要比较推荐列表中的物品之间两两的相似度,不难想到,对这种度量方法,Item CF 的多样性显然不如 User CF 的好,因为 Item CF 的推荐就是和以前看的东西最相似的。
第二种度量方法是考虑系统的多样性,也被称为覆盖率 (Coverage),它是指一个推荐系统是否能够提供给所有用户丰富的选择。在这种指标下,Item CF 的多样性要远远好于 User CF, 因为 User CF 总是倾向于推荐热门的,从另一个侧面看,也就是说,Item CF 的推荐有很好的新颖性,很擅长推荐长尾里的物品。所以,尽管大多数情况,Item CF 的精度略小于 User CF, 但如果考虑多样性,Item CF 却比 User CF 好很多。
如果你对推荐的多样性还心存疑惑,那么下面我们再举个实例看看 User CF 和 Item CF 的多样性到底有什么差别。首先,假设每个用户兴趣爱好都是广泛的,喜欢好几个领域的东西,不过每个用户肯定也有一个主要的领域,对这个领域会比其他领域更加关心。给定一个用户,假设他喜欢 3 个领域 A,B,C,A 是他喜欢的主要领域,这个时候我们来看 User CF 和 Item CF 倾向于做出什么推荐:如果用 User CF, 它会将 A,B,C 三个领域中比较热门的东西推荐给用户;而如果用 ItemCF,它会基本上只推荐 A 领域的东西给用户。所以我们看到因为 User CF 只推荐热门的,所以它在推荐长尾里项目方面的能力不足;而 Item CF 只推荐 A 领域给用户,这样他有限的推荐列表中就可能包含了一定数量的不热门的长尾物品,同时 Item CF 的推荐对这个用户而言,显然多样性不足。但是对整个系统而言,因为不同的用户的主要兴趣点不同,所以系统的覆盖率会比较好。
- 总结
从上面的分析,可以很清晰的看到,这两种推荐都有其合理性,但都不是最好的选择,因此他们的精度也会有损失。其实对这类系统的最好选择是,如果系统给这个用户推荐 30 个物品,既不是每个领域挑选 10 个最热门的给他,也不是推荐 30 个 A 领域的给他,而是比如推荐 15 个 A 领域的给他,剩下的 15 个从 B,C 中选择。所以结合 User CF 和 Item CF 是最优的选择,结合的基本原则就是当采用 Item CF 导致系统对个人推荐的多样性不足时,我们通过加入 User CF 增加个人推荐的多样性,从而提高精度,而当因为采用 User CF 而使系统的整体多样性不足时,我们可以通过加入 Item CF 增加整体的多样性,同样同样可以提高推荐的精度。
- 用户对推荐算法的适应度
前面我们大部分都是从推荐引擎的角度考虑哪个算法更优,但其实我们更多的应该考虑作为推荐引擎的最终使用者 — 应用用户对推荐算法的适应度。
对于 User CF,推荐的原则是假设用户会喜欢那些和他有相同喜好的用户喜欢的东西,但如果一个用户没有相同喜好的朋友,那 User CF 的算法的效果就会很差,所以一个用户对的 CF 算法的适应度是和他有多少共同喜好用户成正比的。
Item CF 算法也有一个基本假设,就是用户会喜欢和他以前喜欢的东西相似的东西,那么我们可以计算一个用户喜欢的物品的自相似度。一个用户喜欢物品的自相似度大,就说明他喜欢的东西都是比较相似的,也就是说他比较符合 Item CF 方法的基本假设,那么他对 Item CF 的适应度自然比较好;反之,如果自相似度小,就说明这个用户的喜好习惯并不满足 Item CF 方法的基本假设,那么对于这种用户,用 Item CF 方法做出好的推荐的可能性非常低。
四、实例演示
1、基于用户的协同过滤算法
基于用户的协同过滤算法是通过用户的历史行为数据发现用户对商品或内容的喜欢(如商品购买,收藏,内容评论或分享),并对这些喜好进行度量和打分。根据不同用户对相同商品或内容的态度和偏好程度计算用户之间的关系。在有相同喜好的用户间进行商品推荐。简单的说就是如果A,B两个用户都购买了x,y,z三本图书,并且给出了5星的好评。那么A和B就属于同一类用户。可以将A看过的图书w也推荐给用户B。
- 寻找偏好相似的用户
我们模拟了5个用户对两件商品的评分,来说明如何通过用户对不同商品的态度和偏好寻找相似的用户。在示例中,5个用户分别对两件商品进行了评分。这里的分值可能表示真实的购买,也可以是用户对商品不同行为的量化指标。例如,浏览商品的次数,向朋友推荐商品,收藏,分享,或评论等等。这些行为都可以表示用户对商品的态度和偏好程度。

从表格中很难直观发现5个用户间的联系,我们将5个用户对两件商品的评分用散点图表示出来后,用户间的关系就很容易发现了。在散点图中,Y轴是商品1的评分,X轴是商品2的评分,通过用户的分布情况可以发现,A,C,D三个用户距离较近。用户A(3.3 6.5)和用户C(3.6 6.3),用户D(3.4 5.8)对两件商品的评分较为接近。而用户E和用户B则形成了另一个群体。

散点图虽然直观,但无法投入实际的应用,也不能准确的度量用户间的关系。因此我们需要通过数字对用户的关系进行准确的度量,并依据这些关系完成商品的推荐。
- 欧几里德距离评价
欧几里德距离评价是一个较为简单的用户关系评价方法。原理是通过计算两个用户在散点图中的距离来判断不同的用户是否有相同的偏好。公式参考上面的介绍。
通过公式我们获得了5个用户相互间的欧几里德系数,也就是用户间的距离。系数越小表示两个用户间的距离越近,偏好也越是接近。不过这里有个问题,太小的数值可能无法准确的表现出不同用户间距离的差异,因此我们对求得的系数取倒数,使用户间的距离约接近,数值越大。在下面的表格中,可以发现,用户A&C用户A&D和用户C&D距离较近。同时用户B&E的距离也较为接近。与我们前面在散点图中看到的情况一致。

- 皮尔逊相关度评价
皮尔逊相关度评价是另一种计算用户间关系的方法。他比欧几里德距离评价的计算要复杂一些,但对于评分数据不规范时皮尔逊相关度评价能够给出更好的结果。以下是一个多用户对多个商品进行评分的示例。这个示例比之前的两个商品的情况要复杂一些,但也更接近真实的情况。我们通过皮尔逊相关度评价对用户进行分组,并推荐商品。
这里我们使用用户评分数据如下:其中P1-P5表示五个用户,A-F表示六个商品。
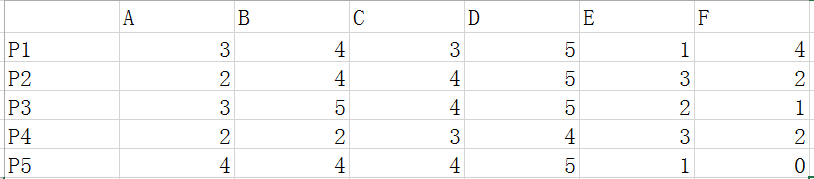
- 皮尔逊相关系数
皮尔逊相关系数的计算公式参考上面介绍,结果是一个在-1与1之间的系数。该系数用来说明两个用户间联系的强弱程度。 假如我们需要给P5用户推荐东西,那么我们需要计算P5和P1-4的皮尔逊相关系数。计算结果如下:
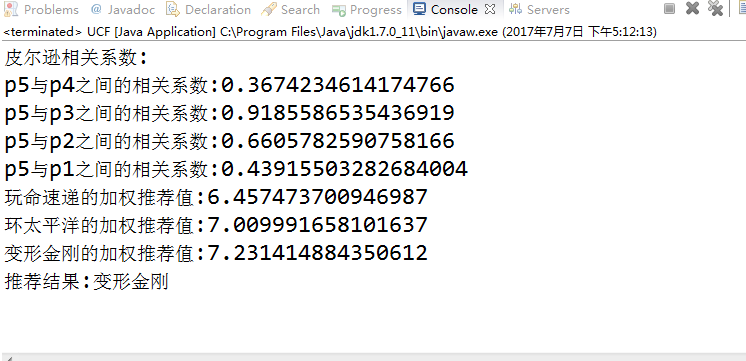
p5与p4之间的相关系数:0.3674234614174766
p5与p3之间的相关系数:0.9185586535436919
p5与p2之间的相关系数:0.6605782590758166
p5与p1之间的相关系数:0.43915503282684004
- 为相似的用户提供推荐物品
目前我们得到的数据情况如下:我们需要为P5推荐三部电影中的一部,有直接推荐和加权排序推荐两种方法。

直接推荐:假如我们需要为用户P5推荐电影,首先我们检查相似度列表,发现用户P5和用户P3的相似度最高。因此,我们可以对用户P5推荐P3的相关数据。但这里有一个问题。我们不能直接推荐前面A-F的商品。因为这这些商品用户P5已经浏览或者购买过了。不能重复推荐。因此我们要推荐用户P5还没有浏览或购买过的商品。如果直接推荐我们可以选择P3用户评价最高的商品,也就是环太平洋和变形金刚两个数据。
加权排序推荐:我们根据不同用户间的相似度,对不同商品的评分进行相似度加权。按加权后的结果对商品进行排序,然后推荐给用户P5。这样,用户P5就获得了更好的推荐结果。

上面的计算结果中,我们按照(变形金刚–环太平洋–玩命速递)的顺序把结果推荐给用户P5。
以上是基于用户的协同过滤算法。这个算法依靠用户的历史行为数据来计算相关度。也就是说必须要有一定的数据积累(冷启动问题)。对于新网站或数据量较少的网站,还有一种方法是基于物品的协同过滤算法。
下面给出该算法的Java描述:
package com.kang;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Map.Entry;
//基于用户的协同过滤算法
public class UCF {
public static void main(String[] args) {
Map<String, Map<String, Integer>> userPerfMap = new HashMap<String, Map<String, Integer>>();
Map<String, Integer> pref1 = new HashMap<String, Integer>();
pref1.put("A", 3);
pref1.put("B", 4);
pref1.put("C", 3);
pref1.put("D", 5);
pref1.put("E", 1);
pref1.put("F", 4);
userPerfMap.put("p1", pref1);
Map<String, Integer> pref2 = new HashMap<String, Integer>();
pref2.put("A", 2);
pref2.put("B", 4);
pref2.put("C", 4);
pref2.put("D", 5);
pref2.put("E", 3);
pref2.put("F", 2);
userPerfMap.put("p2", pref2);
Map<String, Integer> pref3 = new HashMap<String, Integer>();
pref3.put("A", 3);
pref3.put("B", 5);
pref3.put("C", 4);
pref3.put("D", 5);
pref3.put("E", 2);
pref3.put("F", 1);
userPerfMap.put("p3", pref3);
Map<String, Integer> pref4 = new HashMap<String, Integer>();
pref4.put("A", 2);
pref4.put("B", 2);
pref4.put("C", 3);
pref4.put("D", 4);
pref4.put("E", 3);
pref4.put("F", 2);
userPerfMap.put("p4", pref4);
Map<String, Integer> pref5 = new HashMap<String, Integer>();
pref5.put("A", 4);
pref5.put("B", 4);
pref5.put("C", 4);
pref5.put("D", 5);
pref5.put("E", 1);
pref5.put("F", 0);
userPerfMap.put("p5", pref5);
Map<String, Double> simUserSimMap = new HashMap<String, Double>();
System.out.println("皮尔逊相关系数:");
for (Entry<String, Map<String, Integer>> userPerfEn : userPerfMap.entrySet()) {
String userName = userPerfEn.getKey();
if (!"p5".equals(userName)) {
double sim = getUserSimilar(pref5, userPerfEn.getValue());
System.out.println("p5与" + userName + "之间的相关系数:" + sim);
simUserSimMap.put(userName, sim);
}
}
Map<String, Map<String, Integer>> simUserObjMap = new HashMap<String, Map<String, Integer>>();
Map<String, Integer> pobjMap1 = new HashMap<String, Integer>();
pobjMap1.put("玩命速递", 3);
pobjMap1.put("环太平洋", 4);
pobjMap1.put("变形金刚", 3);
simUserObjMap.put("p1", pobjMap1);
Map<String, Integer> pobjMap2 = new HashMap<String, Integer>();
pobjMap2.put("玩命速递", 5);
pobjMap2.put("环太平洋", 1);
pobjMap2.put("变形金刚", 2);
simUserObjMap.put("p2", pobjMap2);
Map<String, Integer> pobjMap3 = new HashMap<String, Integer>();
pobjMap3.put("玩命速递", 2);
pobjMap3.put("环太平洋", 5);
pobjMap3.put("变形金刚", 5);
simUserObjMap.put("p3", pobjMap3);
System.out.println("推荐结果:" + getRecommend(simUserObjMap, simUserSimMap));
}
//Claculate Pearson Correlation Coefficient
public static double getUserSimilar(Map<String, Integer> pm1, Map<String, Integer> pm2) {
int n = 0;// 数量n
int sxy = 0;// Σxy=x1*y1+x2*y2+....xn*yn
int sx = 0;// Σx=x1+x2+....xn
int sy = 0;// Σy=y1+y2+...yn
int sx2 = 0;// Σx2=(x1)2+(x2)2+....(xn)2
int sy2 = 0;// Σy2=(y1)2+(y2)2+....(yn)2
for (Entry<String, Integer> pme : pm1.entrySet()) {
String key = pme.getKey();
Integer x = pme.getValue();
Integer y = pm2.get(key);
if (x != null && y != null) {
n++;
sxy += x * y;
sx += x;
sy += y;
sx2 += Math.pow(x, 2);
sy2 += Math.pow(y, 2);
}
}
// p=(Σxy-Σx*Σy/n)/Math.sqrt((Σx2-(Σx)2/n)(Σy2-(Σy)2/n));
double sd = sxy - sx * sy / n;
double sm = Math.sqrt((sx2 - Math.pow(sx, 2) / n) * (sy2 - Math.pow(sy, 2) / n));
return Math.abs(sm == 0 ? 1 : sd / sm);
}
//获取推荐结果
public static String getRecommend(Map<String, Map<String, Integer>> simUserObjMap,
Map<String, Double> simUserSimMap) {
Map<String, Double> objScoreMap = new HashMap<String, Double>();
for (Entry<String, Map<String, Integer>> simUserEn : simUserObjMap.entrySet()) {
String user = simUserEn.getKey();
double sim = simUserSimMap.get(user);
for (Entry<String, Integer> simObjEn : simUserEn.getValue().entrySet()) {
double objScore = sim * simObjEn.getValue();//加权(相似度*评分)
String objName = simObjEn.getKey();
if (objScoreMap.get(objName) == null) {
objScoreMap.put(objName, objScore);
} else {
double totalScore = objScoreMap.get(objName);
objScoreMap.put(objName, totalScore + objScore);//将所有用户的加权评分作为最后的推荐结果数据
}
}
}
List<Entry<String, Double>> enList = new ArrayList<Entry<String, Double>>(objScoreMap.entrySet());
Collections.sort(enList, new Comparator<Map.Entry<String, Double>>() {//排序
public int compare(Map.Entry<String, Double> o1, Map.Entry<String, Double> o2) {
Double a = o1.getValue() - o2.getValue();
if (a == 0) {
return 0;
} else if (a > 0) {
return 1;
} else {
return -1;
}
}
});
for (Entry<String, Double> entry : enList) {
System.out.println(entry.getKey()+"的加权推荐值:"+entry.getValue());
}
return enList.get(enList.size() - 1).getKey();//返回推荐结果
}
}程序运行结果如下:
2、基于物品的协同过滤算法
基于物品的协同过滤算法与基于用户的协同过滤算法很像,将商品和用户互换。通过计算不同用户对不同物品的评分获得物品间的关系。基于物品间的关系对用户进行相似物品的推荐。这里的评分代表用户对商品的态度和偏好。简单来说就是如果用户A同时购买了商品1和商品2,那么说明商品1和商品2的相关度较高。当用户B也购买了商品1时,可以推断他也有购买商品2的需求。
- 寻找相似的物品

表格中是两个用户对5件商品的评分。在这个表格中我们用户和商品的位置进行了互换,通过两个用户的评分来获得5件商品之间的相似度情况。单从表格中我们依然很难发现其中的联系,因此我们选择通过散点图进行展示。

在散点图中,X轴和Y轴分别是两个用户的评分。5件商品按照所获的评分值分布在散点图中。我们可以发现,商品1,3,4在用户A和B中有着近似的评分,说明这三件商品的相关度较高。而商品5和2则在另一个群体中。
- 欧几里德距离评价
在基于物品的协同过滤算法中,我们依然可以使用欧几里德距离评价来计算不同商品间的距离和关系。
通过欧几里德系数可以发现,商品间的距离和关系与前面散点图中的表现一致,商品1,3,4距离较近关系密切。商品2和商品5距离较近。

- 皮尔逊相关度评价
我们选择使用皮尔逊相关度评价来计算多用户与多商品的关系计算。下面是5个用户对5件商品的评分表。我们通过这些评分计算出商品间的相关度。

- 皮尔逊相关度计算公式
通过计算可以发现,商品1&2,商品3&4,商品3&5和商品4&5相似度较高。下一步我们可以依据这些商品间的相关度对用户进行商品推荐。

- 为用户提供基于相似物品的推荐
这里我们遇到了和基于用户进行商品推荐相同的问题,当需要对用户3基于商品3推荐商品时,需要一张新的商品与已有商品间的相似度列表。在前面的相似度计算中,商品3与商品4和商品5相似度较高,因此我们计算并获得了商品4,5与其他商品的相似度列表。

以下是通过计算获得的新商品与已有商品间的相似度数据。

- 加权排序推荐
这里是用户3已经购买过的商品4,5与新商品A,B,C直接的相似程度。我们将用户3对商品4,5的评分作为权重。对商品A,B,C进行加权排序。用户3评分较高并且与之相似度较高的商品被优先推荐。

经过以上分析,我们按照(C-B-A)的顺序推荐商品给用户。
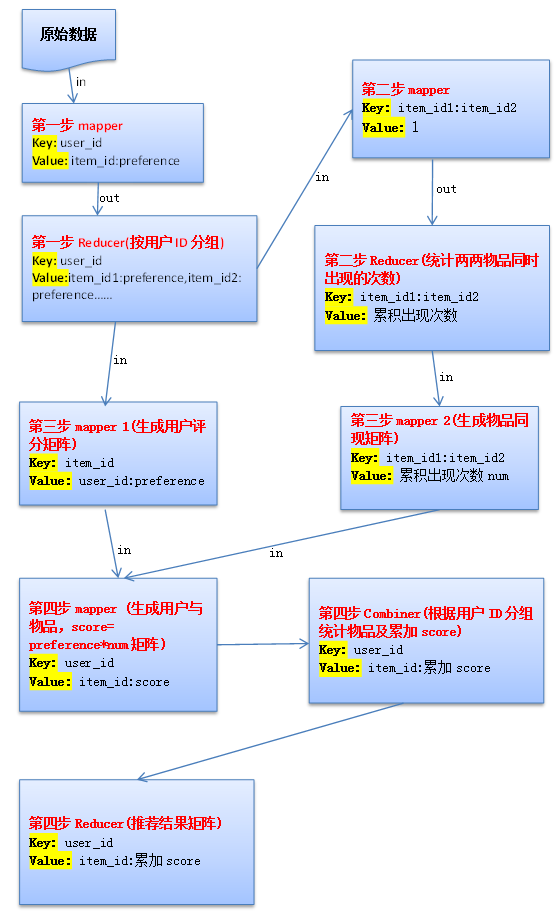
下面给出使用MapReduce实现的基本思路。
数据集字段:
User_id: 用户ID
Item_id: 物品ID
preference:用户对该物品的评分算法的思想:
1、建立物品的同现矩阵A,即统计两两物品同时出现的次数
数据格式:Item_id1:Item_id2 次数
2、 建立用户对物品的评分矩阵B,即每一个用户对某一物品的评分
数据格式:Item_id user_id:preference
3、 推荐结果=物品的同现矩阵A * 用户对物品的评分矩阵B
数据格式:user_id item_id,推荐分值
4、 过滤用户已评分的物品项
5.、对推荐结果按推荐分值从高到低排序原始数据:
1,101,5.0
1,102,3.0
1,103,2.5
2,101,2.0
2,102,2.5
2,103,5.0
2,104,2.0
3,101,2.0
3,104,4.0
3,105,4.5
3,107,5.0
4,101,5.0
4,103,3.0
4,104,4.5
4,106,4.0
5,101,4.0
5,102,3.0
5,103,2.0
5,104,4.0
5,105,3.5
5,106,4.0
6,102,4.0
6,103,2.0
6,105,3.5
6,107,4.0
Hadoop MapReduce程序分为四步:
第一步: 读取原始数据,按用户ID分组,输出文件数据格式为
1 103:2.5,101:5.0,102:3.0
2 101:2.0,102:2.5,103:5.0,104:2.0
3 107:5.0,101:2.0,104:4.0,105:4.5
4 103:3.0,106:4.0,104:4.5,101:5.0
5 101:4.0,102:3.0,103:2.0,104:4.0,105:3.5,106:4.0
6 102:4.0,103:2.0,105:3.5,107:4.0
第二步:统计两两物品同时出现的次数,输出文件数据格式为
101:101 5
101:102 3
101:103 4
101:104 4
101:105 2
101:106 2
101:107 1
102:101 3
102:102 4
102:103 4
102:104 2
102:105 2
102:106 1
102:107 1
103:101 4
103:102 4
103:103 5
103:104 3
103:105 2
103:106 2
103:107 1
104:101 4
104:102 2
104:103 3
104:104 4
104:105 2
104:106 2
104:107 1
105:101 2
105:102 2
105:103 2
105:104 2
105:105 3
105:106 1
105:107 2
106:101 2
106:102 1
106:103 2
106:104 2
106:105 1
106:106 2
107:101 1
107:102 1
107:103 1
107:104 1
107:105 2
107:107 2第三步:生成用户评分矩阵和物品同现矩阵
第一个mapper结果为用户评分矩阵,结果如下:
101 2:2.0
101 5:4.0
101 4:5.0
101 3:2.0
101 1:5.0
102 2:2.5
102 1:3.0
102 6:4.0
102 5:3.0
103 6:2.0
103 5:2.0
103 1:2.5
103 4:3.0
103 2:5.0
104 5:4.0
104 2:2.0
104 3:4.0
104 4:4.5
105 5:3.5
105 3:4.5
105 6:3.5
106 4:4.0
106 5:4.0
107 3:5.0
107 6:4.0
第二个mapper生成物品同现矩阵,结果如下:
101:101 5
101:102 3
101:103 4
101:104 4
101:105 2
101:106 2
101:107 1
102:101 3
102:102 4
102:103 4
102:104 2
102:105 2
102:106 1
102:107 1
103:101 4
103:102 4
103:103 5
103:104 3
103:105 2
103:106 2
103:107 1
104:101 4
104:102 2
104:103 3
104:104 4
104:105 2
104:106 2
104:107 1
105:101 2
105:102 2
105:103 2
105:104 2
105:105 3
105:106 1
105:107 2
106:101 2
106:102 1
106:103 2
106:104 2
106:105 1
106:106 2
107:101 1
107:102 1
107:103 1
107:104 1
107:105 2
107:107 2
第四步:做矩阵乘法,推荐结果=物品的同现矩阵A * 用户对物品的评分矩阵B
结果如下:
1 107,10.5
1 106,18.0
1 105,21.0
1 104,33.5
1 103,44.5
1 102,37.0
1 101,44.0
2 107,11.5
2 106,20.5
2 105,23.0
2 104,36.0
2 103,49.0
2 102,40.0
2 101,45.5
3 107,25.0
3 106,16.5
3 105,35.5
3 104,38.0
3 103,34.0
3 102,28.0
3 101,40.0
4 107,12.5
4 106,33.0
4 105,29.0
4 104,55.0
4 103,56.5
4 102,40.0
4 101,63.0
5 107,20.0
5 106,34.5
5 105,40.5
5 104,59.0
5 103,65.0
5 102,51.0
5 101,68.0
6 107,21.0
6 106,11.5
6 105,30.5
6 104,25.0
6 103,37.0
6 102,35.0
6 101,31.0
参考文献:
推荐系统实践-作者:项亮
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/148071.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
