selenium简介
Selenium是一个用于Web应用程序自动化测试工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera等。
主要功能包括:测试与浏览器的兼容性——测试你的应用程序看是否能够很好得工作在不同浏览器和操作系统之上。
测试系统功能——创建回归测试检验软件功能和用户需求。支持自动录制动作和自动生成 .Net、Java、Perl等不同语言的测试脚本(这里主要是针对selenium ide)
selenium历程
04年,诞生了Selenium Core,Selenium Core是基于浏览器并且采用JavaScript编程语言的测试工具,运行在浏览器的安全沙箱中,设计理念是将待测试产品、Selenium Core和测试脚本均部署到同一台服务器上来完成自动化测试的工作。
05年,Selenium RC诞生,就是selenium1 ,这个时候,Selenium Core其实是Selenium RC的核心。
Selenium RC让待测试产品、Selenium Core和测试脚本三者分散在不同的服务器上。(测试脚本只关心将HTTP请求发送到指定的URL上,selenium本身不需要关心HTTP请求由于什么程序编程语言编写而成)
Selenium RC包括两部分:一个是Selenium RC Server,一个是提供各种编程语言的客户端驱动来编写测试脚本
07年,Webdriver诞生,WebDriver的设计理念是将端到端测试与底层具体的测试工具分隔离,并采用设计模式Adapter适配器来达到目标。WebDriver的API组织更多的是面向对象。
08/09年,selenium2诞生,selenium2其实是selenium rc和webdriver的合并,合并的根本原因是相互补充各自的缺点
09年,selenium3诞生,这个版本剔除了selenium rc , 主要由 selenium webdriver和selenium Grid组成, 我们日常使用的其实就是selenium webdriver,至于selenium grid是一个分布式实现自动化测试的工具
那么今天我们就要说说selenium3(selenium webdriver)的工作原理,下面简称selenium(以上具体时间可能不太准确,我也是通过网络资料了解到的,抛砖引玉–)
selenium原理
我们使用Selenium实现自动化测试,主要需要3个东西
- 测试脚本,可以是python,java编写的脚本程序(也可以叫做client端)
- 浏览器驱动, 这个驱动是根据不同的浏览器开发的,不同的浏览器使用不同的webdriver驱动程序且需要对应相应的浏览器版本,比如:geckodriver.exe(chrome)
- 浏览器,目前selenium支持市)面上大多数浏览器,如:火狐,谷歌,IE等
selenium脚本
from selenium import webdriver
driver = webdriver.Chrome()
执行上述代码,我们会发现程序打开了Chrome浏览器(前提:你已经正确配置了Chrom驱动和对应的版本)
那么 selenium 是如何实现这个过程呢?ok,那我们就来分析一下selenium的工作原理。
源码分析
如图,按住Ctrl 建,点击Chrome,我们可以看到webdriver的代码
C:\Python36\Lib\site-packages\selenium\webdriver\chrome\webdriver.py
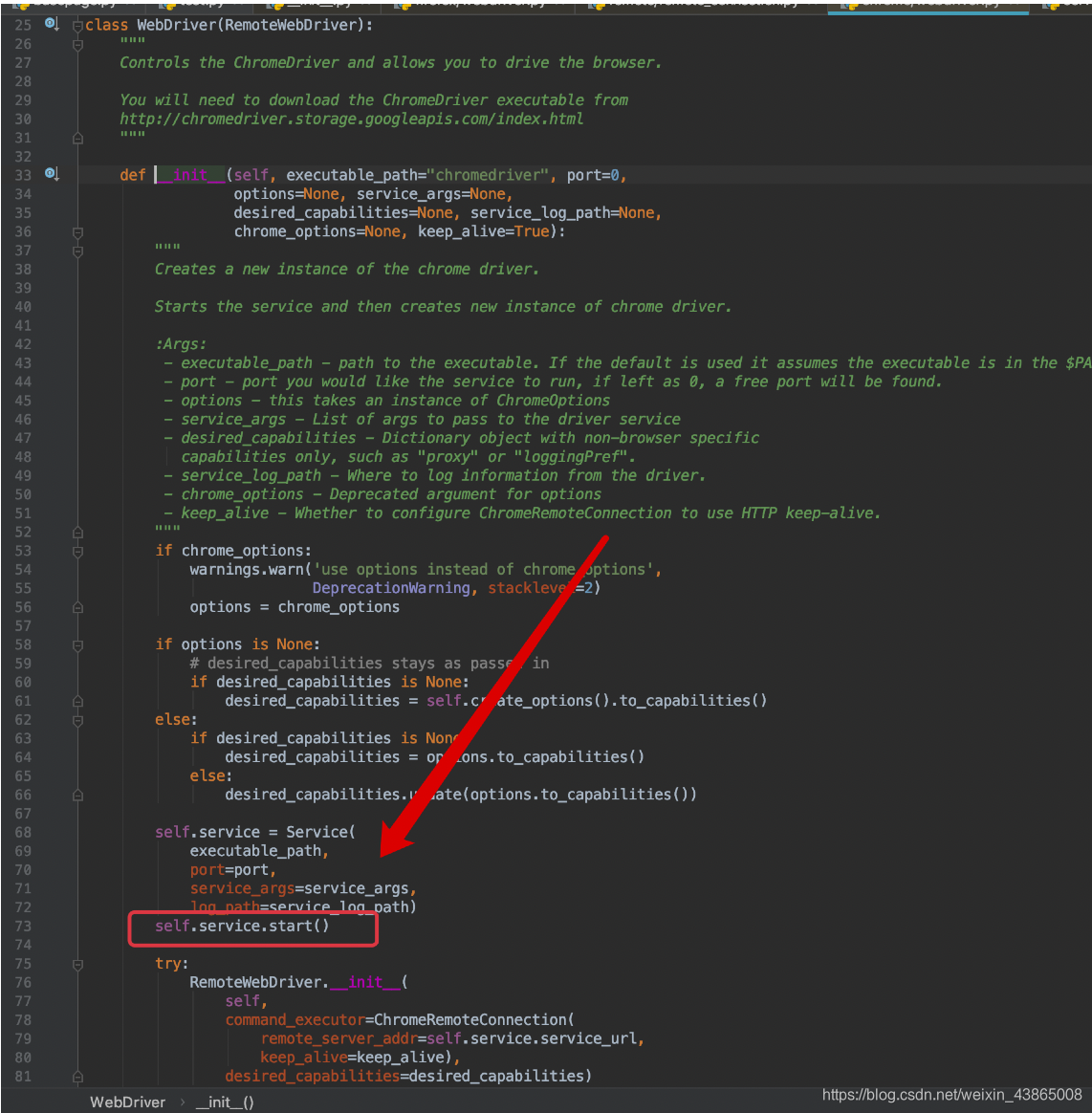

通过源码的第 68-73行,我们可以看到,他启动了一个 service对象,然后调用了 sart() 方法,那么我们继续看一下第 73 行 start()方法具体做了什么。
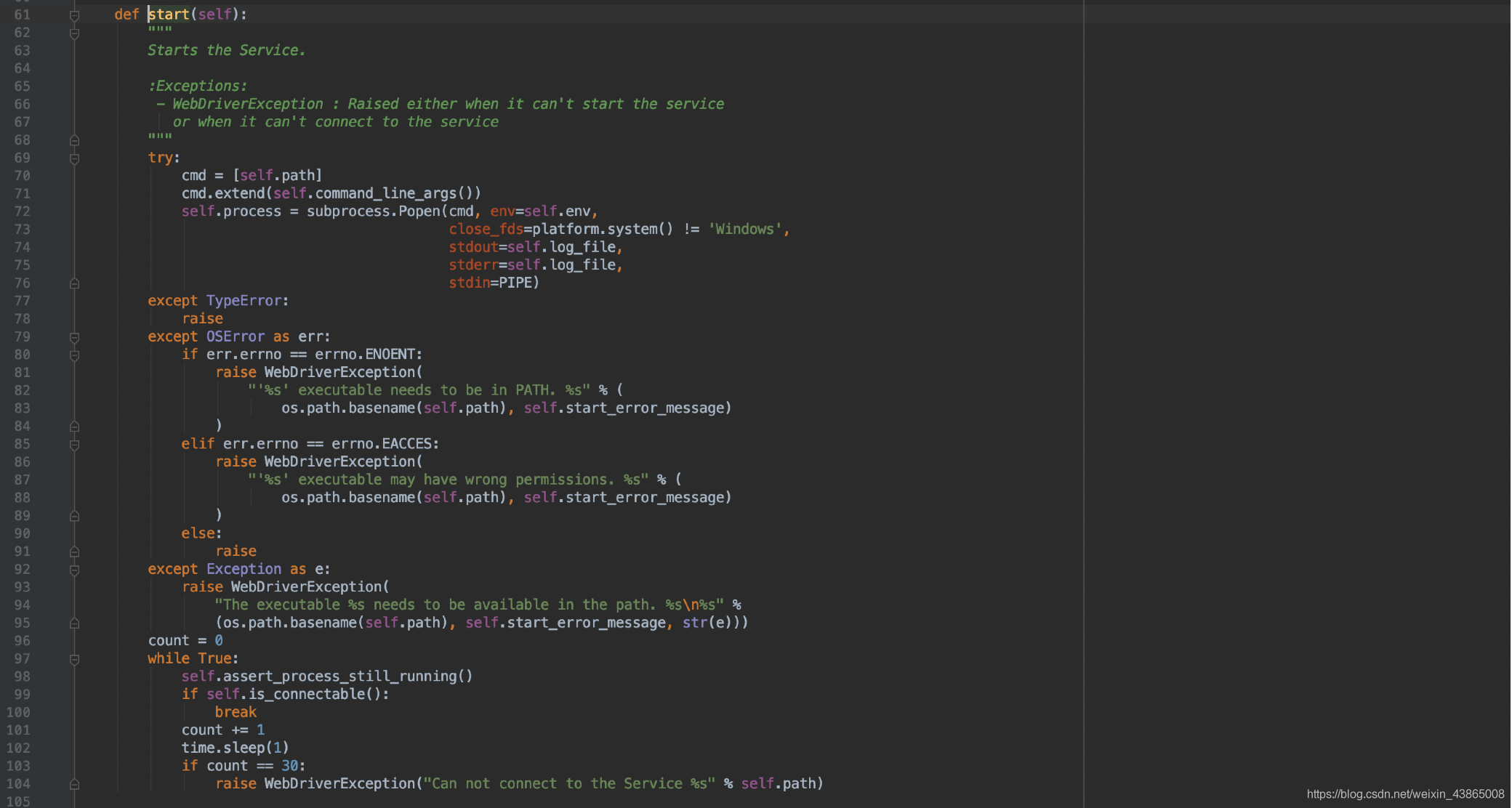
我们可以看到,第69-76行,他执行了一个cmd命令,这个命令主要是启动了一个ChromeDriver.exe浏览器驱动,我们每次在执行脚本前,程序会自动帮我们启动浏览器驱动,这个效果就跟我们自己手动启动是一样的效果。

启动驱动程序后,绑定的端口9515,且允许本地访问这个服务,其实我们可以查看一下本地电脑任务管理器,确实启动了一个服务进程程序。
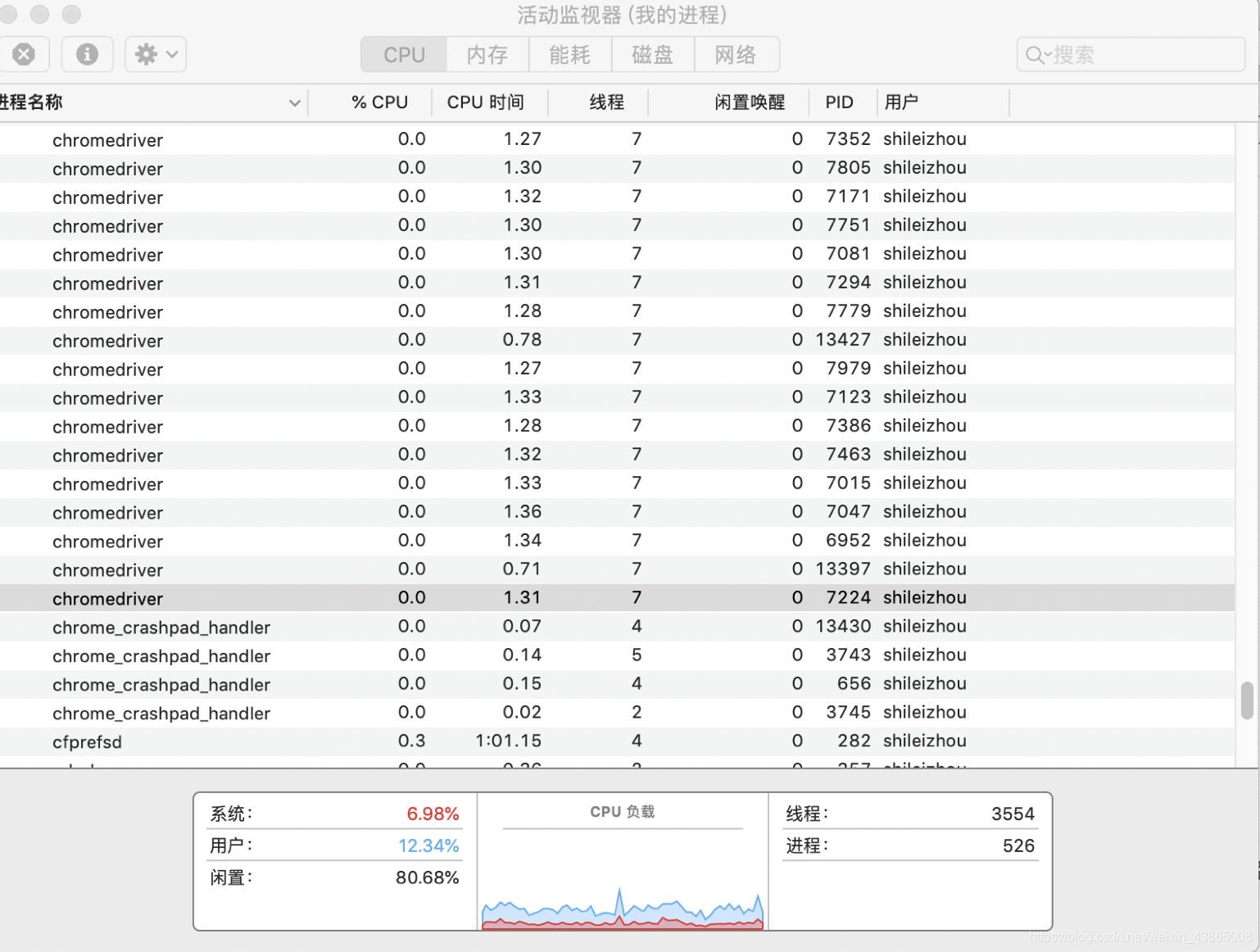
第一步工作我们已经知道了执行脚本webdriver.Chrome()会自动执行 chromedirver.exe驱动程序,然后开启一个进程
如何打开浏览器
我们继续看源码 C:\Python36\Lib\site-packages\selenium\webdriver\chrome\webdriver.py 的51-57行代码,调用了父类RemoteWebDriver 的初始化方法,我们看这个方法做了什么事?
这里有一行最重要的代码,62行self.start_session(capabilities, browser_profile) 这个方法,继续看一下这个方法的源码做了什么工作

分析这部分源码可以发现22行是向地址localhost:9515/session发送了一个post请求,参数是json格式的,然后返回特定的响应信息给程序(这里主要就是新建了一个sessionid),最终打开了浏览器
ok,打开浏览器的操作完成了
如何执行对应操作
查看C:\Python36\Lib\site-packages\selenium\webdriver\chrome\webdriver.py源码(第一个源码中的76-81行)

点击ChromeRemoteConnection查看一下源码
第24行访问的是localhost:9515/session地址,第25-28行,定义了一些和我们使用的浏览器(chrome)特有的接口地址,我们再看一下父类RemoteConnection里面源码
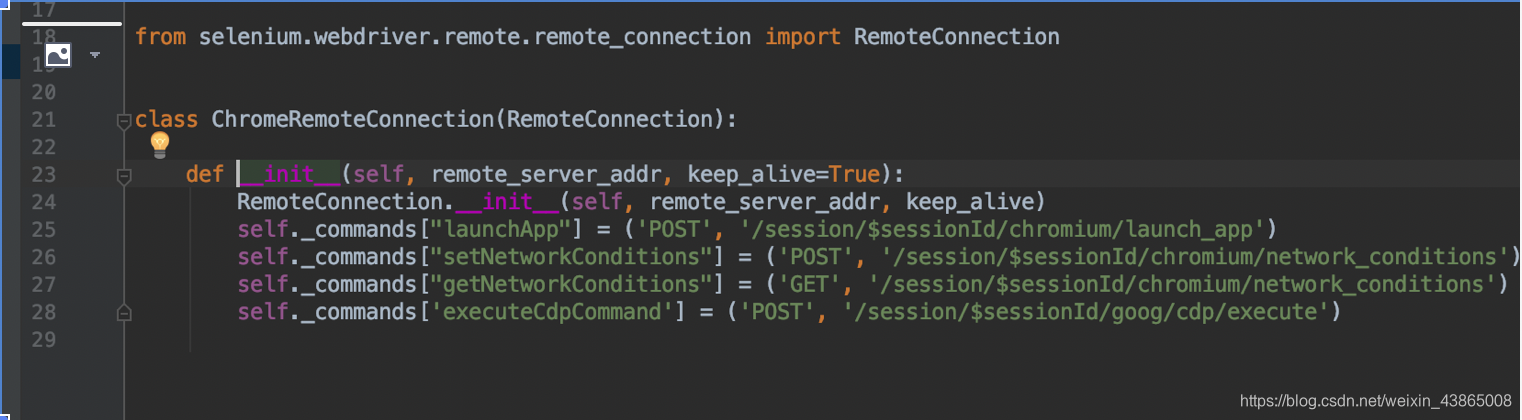
这个类里面定义了所有的selenium操作需要的接口地址(这些接口地址全部封装在浏览器驱动程序中),那么所有的浏览器操作就是通过访问这些接口来实现的
其中 Command.GET: (‘POST’, ‘/session/$sessionId/url’) 这个地址就是实现访问一个网址的url ,我们先记录一下后面有用
ok,所有的操作对应接口地址我们知道了,那么又怎样执行这些接口来达到在浏览器上实现各种操作呢?继续看紧接着接口地址定义下面的源码
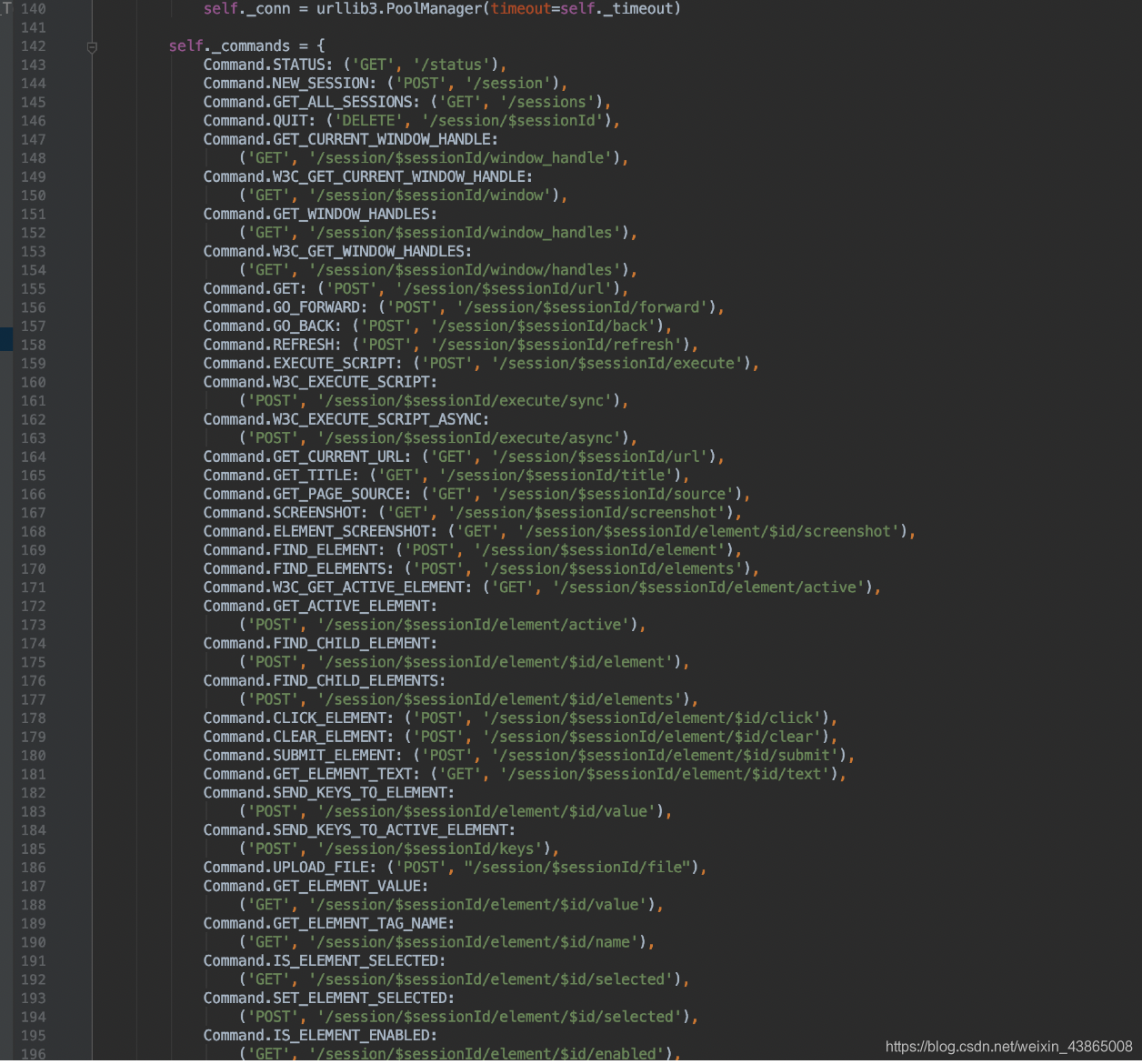
可以看到主要是通过execute方法调用_request方法通过urilib3标准库向服务器发送对应操作请求地址,进而实现了浏览器各种操作
有人会问打开浏览器和操作浏览器实现各种动作是怎么关联的呢?
其实,打开浏览器也是发送请求,请求会返回一个sessionid,后面操作的各种接口地址,你也会发现接口地址中存在一个变量$sessionid,那么不难猜测打开浏览器和操作浏览器就是用过sessionid关联到一起,达到在同一个浏览器中做操作
第二步在浏览其上实现各种操作原理也完成了
selenium的工作过程
可能大家看原理的时候,会有些不理解,那么我们可以看看selenium它是如何工作的?
-
selenium client(python等语言编写的自动化测试脚本)初始化一个service服务,通过Webdriver启动浏览器驱动程序chromedriver.exe
-
通过RemoteWebDriver向浏览器驱动程序发送HTTP请求,浏览器驱动程序解析请求,打开浏览器,并获得sessionid,如果再次对浏览器操作需携带此id
-
打开浏览器,绑定特定的端口,把启动后的浏览器作为webdriver的remote server
-
打开浏览器后,所有的selenium的操作(访问地址,查找元素等)均通过RemoteConnection链接到remote server,然后使用execute方法调用_request方法通过urlib3向remote server发送请求
-
浏览器通过请求的内容执行对应动作
-
浏览器再把执行的动作结果通过浏览器驱动程序返回给测试脚本
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/100701.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
