python爬虫–协程
基本知识
- event_loop:事件循环,相当于一个无限循环,我们可以把一些函数注册到这个事件循环上,当满足某些条件的时候,函数就会被循环执行。
- coroutine:携程对象,我们可以将携程对象注册到事件循环中,它会被时间循环调用。我们可以使用
async关键字来定义一个方法,这个方法在调用时不会被立即执行,而是返回一个协程对象。 - task:任务,它是对协程对象的进一步封装, 包含了任务的各个状态。
- future:代表将来执行或还没有执行的任务,实际上和task 没有本质区别。
- async定义-个协程.
- await用来挂起阻塞方法的执行。
协程的基本使用
import asyncio
async def request(url):
print('正在请求的url是:',url)
print('请求成功:',url)
#async修饰的函数,调用之后返回的一个协程对象
c = request('www.baidu.com')
# #创建一个事件循环对象
# loop = asyncio.get_event_loop()
#
# #将携程对象注册到loop中,然后启动loop
# loop.run_until_complete(c)
# #task的使用
# loop = asyncio.get_event_loop()
# #基于loop创建一个task对象
# task = loop.create_task(c)
# print(task)
# loop.run_until_complete(task)
# print(task)
#future的使用
loop = asyncio.get_event_loop()
task = asyncio.ensure_future(c)
print(task)
loop.run_until_complete(task)
print(task)
多任务协程实现
import asyncio
import time
async def request(url):
print('正在请求的url是:',url)
#在异步协程中如果出现同步模块相关的代码,那么就无法实现异步
#time.sleep(2)
await asyncio.sleep(2)
print('请求成功:',url)
#async修饰的函数,调用之后返回的一个协程对象
start = time.time()
urls = {
'www.123.com',
'www.234.com',
'www.345.com'
}
#存放多个任务对象
stask = []
for url in urls:
c = request(url)
task = asyncio.ensure_future(c)
stask.append(task)
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(stask))
print(time.time()-start)
多任务协程异步实现
在进行多任务协程实现前,还需要建立一个简单的本地http服务
from flask import Flask
import time
app = Flask(__name__)
@app.route('/azb')
def index_azb():
time.sleep(2)
return 'Hello azb'
@app.route('/xx')
def index_xx():
time.sleep(2)
return 'Hello xx'
@app.route('/hh')
def index_hh():
time.sleep(2)
return 'Hello hh'
if __name__ == '__main__':
app.run(threaded=True)
实现
import requests,asyncio,time
start = time.time()
urls = [
'http://127.0.0.1:5000/azb','http://127.0.0.1:5000/xx','http://127.0.0.1:5000/hh'
]
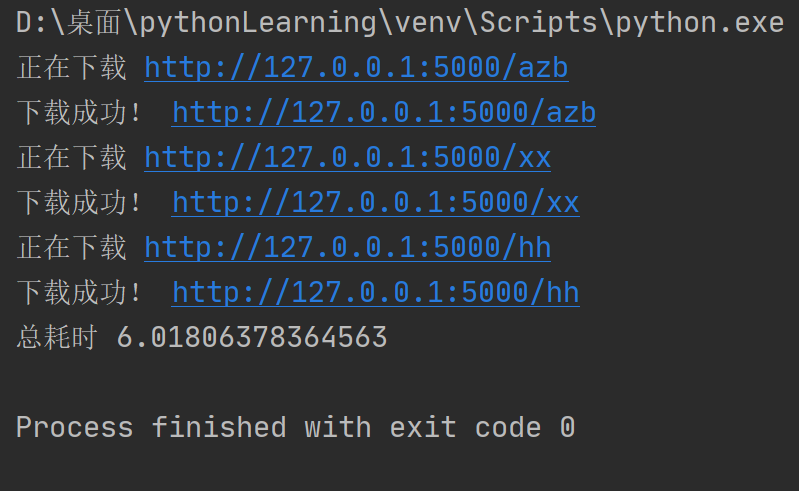
async def get_page(url):
print('正在下载',url)
#request是基于同步,必须使用基于异步的网络请求模块
response = requests.get(url=url)
print('下载成功!',url)
tasks = []
for url in urls:
c = get_page(url)
task = asyncio.ensure_future(c)
tasks.append(task)
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(tasks))
print('总耗时',time.time()-start)
aiohttp模块引入
import requests,asyncio,time,aiohttp
start = time.time()
urls = [
'http://127.0.0.1:5000/azb','http://127.0.0.1:5000/xx','http://127.0.0.1:5000/hh'
]
async def get_page(url):
async with aiohttp.ClientSession() as session:
async with await session.get(url) as response:
#text()返回字符串形式的响应数据
#read()返回的二进制形式的响应数据
#json()返回的就是json对象
#获取响应数据操作之前一定要使用await进行手动挂起
page_text = await response.text()
print(page_text)
tasks = []
for url in urls:
c = get_page(url)
task = asyncio.ensure_future(c)
tasks.append(task)
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(tasks))
print('总耗时',time.time()-start)

协程还是没有理解
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/100101.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...