大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
#写在前面
老习惯,正文之前瞎扯一通。HMM学了很久,最初是在《统计学自然语言处理》里面就学到了相关内容,并且知道HMM CRF一直都是NLP比较底层比较基础且较为有效的算法模型(虽然感觉还是挺难的),之前仅仅局限在了解前向算法和维特比算法上。也没有去写代码,只知道个大概思路。最近从52nlpHMM系列讲解再次入手,结合多篇博客、github项目以及李航的《统计学习方法》比较全面的对HMM做了一次学习,要求对自己强制输出,所以在整体公式推导没有什么大问题之后,昨天花了一天完善了代码,今天来做一个全面的讲解,为人为己。
本文还是坚持自己的风格,讲解和公式穿插进行,数学公式永远是最精炼的语言
^_^
本文目标
- Why – 什么场景下需要HMM模型
- What – HMM模型的相关概念定义
- How – HMM模型中的3个经典问题
- Code – python实现一个HMM基础框架以及简单应用
- 总结与后续问题
#Why – 什么场景下需要HMM模型
X是一个时间和状态都是离散随机过程,Xn是n时刻下的状态,如果Xn + 1对于过去状态的条件概率分布仅是Xn的一个函数,即我们通常说的状态仅与上一个状态有关,则该过程是一个一阶马尔科夫过程。公式如下:
P(Xn+1=x∣X0,X1,X2,…,Xn)=P(Xn+1=x∣Xn)
上面回顾了一下马尔科夫模型,现在来看一个实际的例子:
现在有某地一周的天气预报:
1 Sun 2 Sun 3 Rain 4 Sun 5 Rain 6 Rain 7 Sun
现在我们假设知道某地以往所有的天气,现在我们假设这是在沙漠地区,那么我们有一个2阶的状态转移矩阵:
sun rain
sun 0.9 0.1
rain 0.8 0.2
那么我们现在可以很轻松的判断这一周出现这种天气的概率是多少。但是突然有一天,你被关进了一个小黑屋,你不能直接知道外面的天气,你只能看看小屋子里面苔藓的干湿情况,并且你知道天气能影响苔藓的干湿情况。那么现在如果你想了解天气情况以及相关的信息,你该怎么办?
这里先来小小总结一下,我们现实生活中有很多这种类似的例子,上述例子中天气是我们不能直接观测的(被关小黑屋的情况)称为隐藏状态,苔藓的干湿被称为观察状态,观察到的状态序列与隐藏过程有一定的概率关系,这时我们使用隐马尔科夫模型对这样的过程建模,这个模型包含了一个底层隐藏的随时间改变的马尔科夫过程,以及一个与隐藏状态某种程度相关的可观察到的状态集合。我们生活中有很多这种无法被直接观测的例子,比如语音设备中的某些内部产出,或者是投骰子中某些骰子的状态选择(4,6,8面骰子的案例,网上很多这里不赘述),或者是词性标注中的词语词性等等。整个HMM模型都是围绕观测状态和隐藏状态建模和处理的。我们先留个印象,让我们继续往后看。
#What – HMM模型的相关概念定义
隐马尔可夫模型(Hidden Markov Model,HMM)是统计模型,它用来描述一个含有隐含未知参数的马尔可夫过程。以上描述来自百度百科。
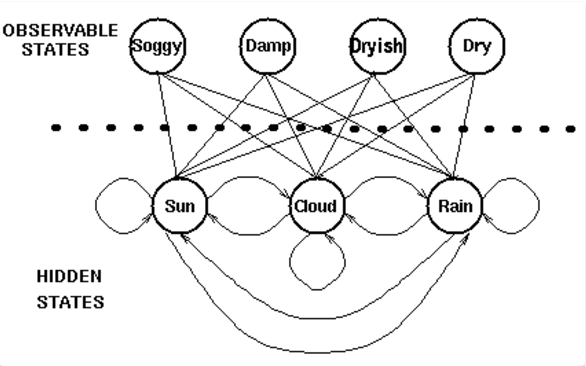
HMM模型大概长像如下,偷的52NLP的图,这个模型包含了一个底层隐藏的随时间改变的马尔科夫过程,通常是一阶的,对应下图就是天气之间的状态转移概率关系。以及一个与隐藏状态某种程度相关的可观察到的状态集合,对应就是天气如何影响苔藓,即我们的术语叫做发射概率或者混淆概率。

##HMM模型的5元组
每个模型都有自己相关的概念,弄清算法之前我们先来看看这个模型的基本概念,5元组。
(S,K,π,A,B):以上分别对应了HMM中的5个重要概念
S:隐藏状态的集合(Sun Cloud Rain),N为隐状态个数 N=3
K : 输出状态或者说观测状态的集合(Soggy Damp Dryish Dry),M为观测状态个数M=4
π : 对应隐藏状态的初始化概率 (sun : 0.5 cloud : 0.3 rain : 0.2)
A : 隐藏状态的状态转移概率,是一个NN的概率矩阵
B : 隐藏状态到观测状态的混淆矩阵,是一个NM的发射概率矩阵
另外符号体系中会有对于每个序列的状态序列和观测序列,如一周的观测和状态,定义下
O : 某特定观测序列
X : 某特定隐藏状态序列
仍然是盗的图,方便大家看一下,和我上面写的基本一致。来自《统计学自然语言处理》
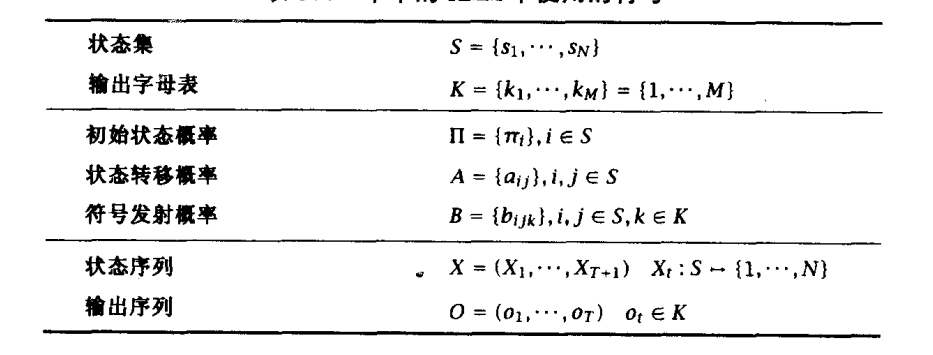
##HMM中的3个经典问题
关于HMM这个模型建立起来之后,其实有很多问题可以去讨论,但是一般讲学中我们讨论3个问题,即评估,预测,学习,下面我们来一起看一波吧~
这里为了解释方便,请大家无条件的接受以下两个基础条件:
1.已知对应问题的观测状态集合K
2.已知对应问题的隐藏状态集合S
如果没有以上两个问题,可能就不太属于今天要讨论的范畴了,可能属于聚类后者其他研究,总之这里我们不予考虑。
3个经典问题如下:
·观察序列概率的计算 评估(前向算法)
·隐藏状态序列最大概率解 预测(维特比算法)
·马尔科夫参数求解(π,A,B) 学习(EM算法 前后向算法)
#How – HMM模型中的3个经典问题
##评估
评估描述
给定观测序列O(o1,o2,…,oT)和模型u = (π,A,B),求出P(O | u),即给定模型下观测序列的概率是多少?对应于之前的例子,就是给定天气的转移矩阵,天气和苔藓的发射矩阵,以及天气的初始化列表(这些都是已知的,以前统计好的,具体方法这里不用纠结)。然后求出给定一周苔藓的状态,你判断这个状态存在的概率有多大(这个评估这里只是介绍方法,想想感觉这个案例这里没有什么特别大的实际意义)。
###评估理论推导
解决该问题有个很直观的想法就是把所有的隐藏状态都走一遍,然后看对应观测状态概率有多大,一起加起来就是这个状态的可能性。我们用数学式子表示如下:
自己写公式还是很费力的,第二个公式中bxtxt+1ot这种写法是因为有些HMM模型的发射概率是在发射弧上面,即和该状态与下状态有关,所以写成这种样子,有时候如果只与当前状态有关可以写成btot的形式。
第一个公式:利用全概率公式求解所有可能隐状态序列下的概率之和。
第二个公式:已知状态下序列的概率。
第三个公式:任意隐藏序列的概率。
第四个公式:利用每个概率表示公式1,这里bxtot表示了发射只与当前状态有关,与2略不同,只是多了一个假设条件便于表示。另外此处说明下由于序列长度不同,该公式可能与其他某些书中公式有点差异,但基本思想一致,只不过具体表现上针对不同情况略有不同。最后一个bXTOT是在连乘之后的,不在求积符号里面!
好了,公式也推到了,写写代码就能跑了(完结撒花~)!
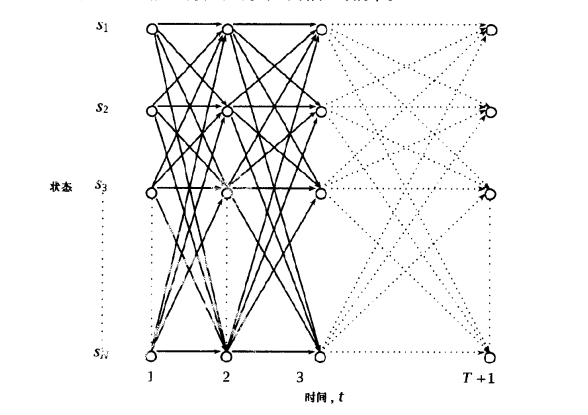
其实并没有进度条君命还长呢,我们仔细看看上面公式,计算一下时间复杂度。一共N^T次方的可能序列,好了打住,不用往后看了,这已经指数级别了。我们可以看到计算公式里面实际是由大量冗余乘法计算的,现在给大家介绍动态规划的前向算法来巧妙的解决实际计算问题。
###评估实际算法:前向计算
我们定义前向变量算子αt(i)=P(O1,O2,…,Ot,Xt = Si | u),前向变量表示t时刻,si状态结束是之前路径上的总概率。可知,对αT(i)求和便能得到评估结果。而此时时间复杂度因为有了动态规划,乘法次数在TN^2的级别,进步不少哦,只需要额外的少量空间(TN)即可。
###python前向算法代码
OK,这一部分差不多到这里,已经可以评估出这个观测序列存在的概率了,下面附上一点点python代码,以下符号体系和上述相同,应该比较好理解,重点在于熟悉numpy对矩阵的操作,这使得python的代码看起来十分的简洁!
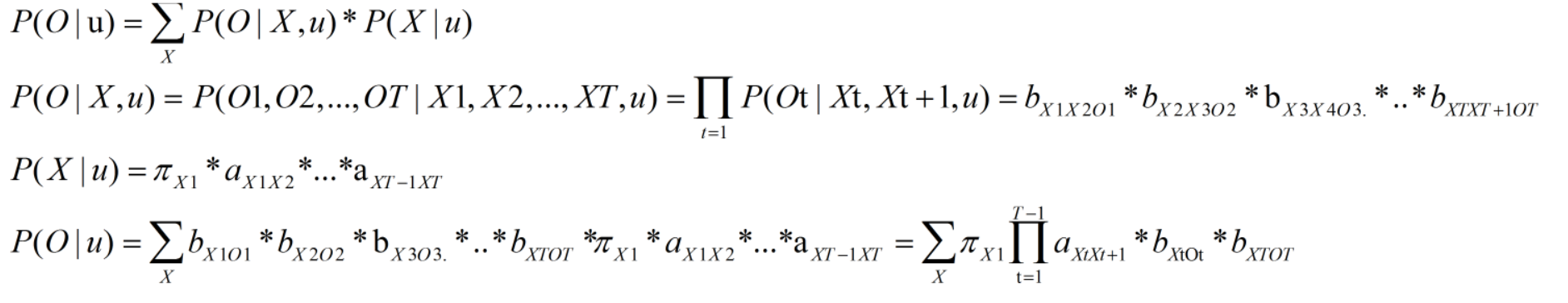
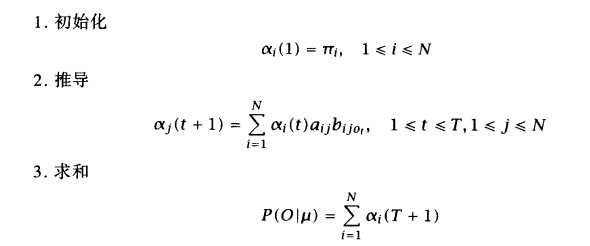
#计算公式中的alpha二维数组
def _forward(self,observationsSeq):
T = len(observationsSeq)
N = len(self.pi)
alpha = np.zeros((T,N),dtype=float)
alpha[0,:] = self.pi * self.B[:,observationsSeq[0]] #numpy可以简化循环
for t in range(1,T):
for n in range(0,N):
alpha[t,n] = np.dot(alpha[t-1,:],self.A[:,n]) * self.B[n,observationsSeq[t]] #使用内积简化代码
return alpha
##预测
预测描述
给定观测序列O(o1,o2,…,oT)和模型u = (π,A,B),求出最大概率的隐藏序列X(X1,X2…,XT),那么解法思路和上述一样,只不过将求和变成求最大值,并且相同的思路我们可以利用动态规划来解决这个问题,这里该方法有一个较为有名的算法“维特比算法”。下面引用了数学之美的一段话。
维特比算法是一个特殊但应用最广的动态规划算法,利用动态规划,可以解决任何一个图中的最短路径问题。而维特比算法是针对一个特殊的图——篱笆网络的有向图(Lattice )的最短路径问题而提出的。 它之所以重要,是因为凡是使用隐含马尔可夫模型描述的问题都可以用它来解码,包括今天的数字通信、语音识别、机器翻译、拼音转汉字、分词等。——《数学之美》
###维特比算法
argmax(P(X|O,u)),我们想求出最有可能的X序列(X1,X2,…,XT),我们依葫芦画瓢写出对应的维特比中间变量θt(j) = max(P(X1,X2,…Xt=Sj,O1,O2,…,Ot|u)) (这个公式确实有点难写出来,不过是想还是很容易理解)。这里我们根据上一时刻的概率,根据转移概率求出此刻最可能的情况,以此递归,最终能找到最优解。下面是具体推导过程,该过程中引入了一个变量来存储该节点的前一个路过节点,代码中用argmax(θ(j-1))表示。
推导公式如下,解释下:
第一个公式:状态1时刻概率都是初始概率,这里注意有人用1有人用0,完全看是不是写代码方便了
第二个公式:状态t时刻为t-1时刻θ变量*转移概率的最大值
第三个公式:状态t时刻回溯上一个最大概率路径。
θ1(j) = πj
θt(j) = max( θt-1(i) * aij * bj ot) i∈[1,N]
φt(j) = argmax( θt-1(i) * aij ) i∈[1,N]
给张示意图吧,有关更多维特比的内容,可以去网上搜索更多资料。
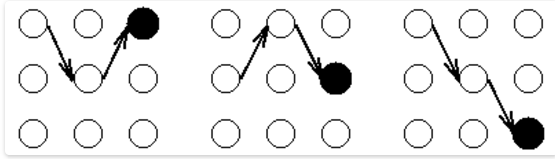
###python 维特比算法代码
下面仍然给一段python代码:
#维特比算法进行预测,即解码,返回最大路径与该路径概率
def viterbi(self,observationsSeq):
T = len(observationsSeq)
N = len(self.pi)
prePath = np.zeros((T,N),dtype=int)
dpMatrix = np.zeros((T,N),dtype=float)
dpMatrix[0,:] = self.pi * self.B[:,observationsSeq[0]]
for t in range(1,T):
for n in range(N):
probs = dpMatrix[t-1,:] * self.A[:,n] * self.B[n,observationsSeq[t]]
prePath[t,n] = np.argmax(probs)
dpMatrix[t,n] = np.max(probs)
maxProb = np.max(dpMatrix[T-1,:])
maxIndex = np.argmax(dpMatrix[T-1,:])
path = [maxIndex]
for t in reversed(range(1,T)):
path.append(prePath[t,path[-1]])
path.reverse()
return maxProb,path
##学习
说了半天,终于说到以前没有说的问题了,之前的两个问题其实都比较容易理解,学习是HMM经典问题里面比较难的问题,要求是给定一个观察序列,求出模型的参数(π,A,B)。想想就很头疼,这怎么求,有一个办法就是拿已经标记好的去统计,这是一种方法。另外就是我们今天要讲的前后向算法了。这个算法又叫baum-welch算法,是在EM算法提出之前就已经存在了,之后被证明为一种特殊的EM算法。一般的博客会从后向变量开始往后讲,但是我觉得从理解的角度出发,我们还是先来看看这个EM算法。
###EM算法实例理解
首先我们想一下学习参数我们需要做些什么,有哪些难点。首先我们不知道隐藏状态序列是什么样子的,再一个我们要求转移矩阵之类。我们想从概率最大入手或者说极大似然,但是只有知道u=(π,A,B)我们才能求出最可能的序列,有了最可能的序列我们才有可能估算最可能的参数集。这仿佛是一个循环的“鸡生蛋,蛋生鸡”的故事。此问题就是EM算法的应用场景,那么我们举个简单的例子,看一下EM算法的思想。
此处会借用http://blog.csdn.net/zouxy09/article/details/8537620/博主的例子,特此说明,为了保证博文的完整性,这里简要说明。更详细说明请看上面链接。
假设现在有N1个男生,N2个女生。并且男女身高集X1,X2均服从高斯分布X1N(μ1,б1^2),X2N(μ2,б2^2),其中均值和标准差μi,бi(i∈1,2)均是未知参数。我们现在随机抽取了n个人,假设抽取人身高序列为Oi(i∈1,…,n)。那么我们希望在u=(π,A,B)参数下使得该序列出现可能性最大。用数学公式表示如下:
现在就是想办法对求出上式u,最直接的思路就是对(π,A,B)分别求导,在分布已知(隐藏状态确认)的情况下还是比较好求,前提是对似然函数L(u)求lg,这样可以将上面的式子编程∑,方便计算。下面给出极大似然的一般步骤:
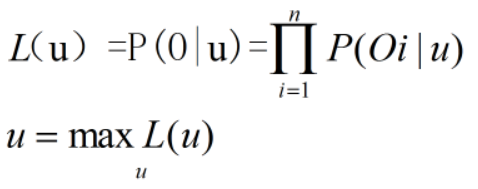
求最大似然函数估计值的一般步骤:
(1)写出似然函数;
(2)对似然函数取对数,并整理;
(3)求导数,令导数为0,得到似然方程;
(4)解似然方程,得到的参数即为所求;
那么现在的问题就是,我们不知道这个人是男的还是女的,我们就不知道怎么去算这个概率了。那么既然是一个循环,我们随便找一个点切入好了。假设u0=(π0,A0,B0),那么我们可以计算出对应一个身高数据是男生还是女生的概率大小,然后我们根据这个比例去算该情况下最可能的参数u1。解释下下面的公式,其中X为隐藏状态序列,O为观测序列,在观测和之前参数条件下求现在条件期望的最大值对应的新参数。这里可能有点绕口,大家可以仔细想下,就是对应不同的X序列我们求出一个状态概率,这个概率来自于上一次的参数。然后根据这个序列我们求出新参数下的概率,然后对其相乘求和,这就是一个期望的概念。这个公式我尽量的想去形象化的理解,但总感觉说不太通,这里我就不多解释了,总之,在数学推导上,这个式子是完全可以用EM算法得到的。虽然这个存在于EM之前,我们这里就不纠结了,大家默认就好。
到这里我们实际上就可以利用约束最优化的问题去求解HMM中的参数学习问题了。现在虽然是数学公式,而且看得有点头晕,但是最少我们可以求出一个新参数了,此处并没有证明这个算法是全局最优或者是单调的,这个不知道当时那个作者有没有考虑这个问题,总之后来人们证明了baum-welch算法是EM算法的一个特例。并且证明了单调性,这个之后再讲,我们先看看baum-welch算法是如何操作的。
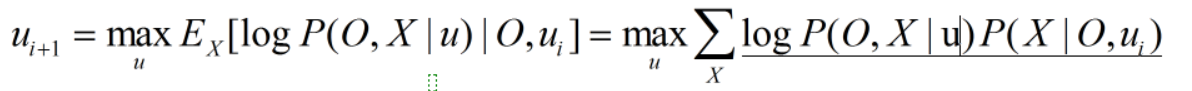
###baum-welch算法的思路
注意:因为实在不想自己抄一遍公式,所以后文中符号体系与上述内容略有不符,O表示观测序列,I表示隐藏状态序列,λ表示参数即上述u。
有上面这个公式之后,我这里直接借用李航书中的计算,因为涉及到最优化问题,暂时还没有系统的学习,所以直接上截图吧。这里特别说明(10.33)书中是有特别注释的,其省略了常数因子1/P(O|λ),所以写成了联合概率的形式。
同理之后得出下面结论:
好了,看着上面的代码,都是在以上期望公式+约束最大化产生的结果,我们已经可以快完成整个算法了,现在的最后一步就是如何去计算公式中的几个概率。


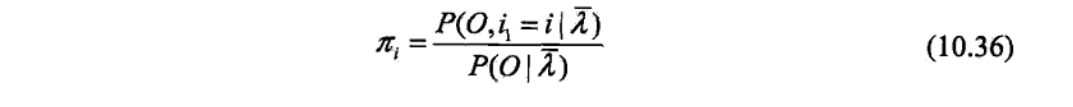
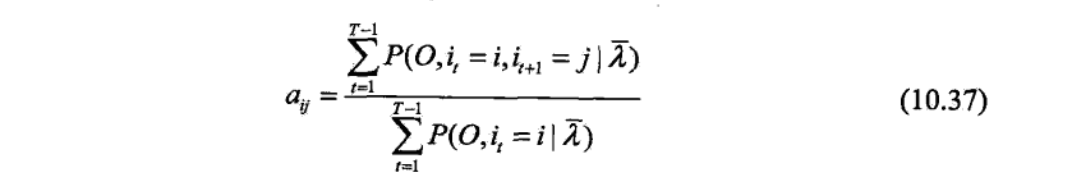
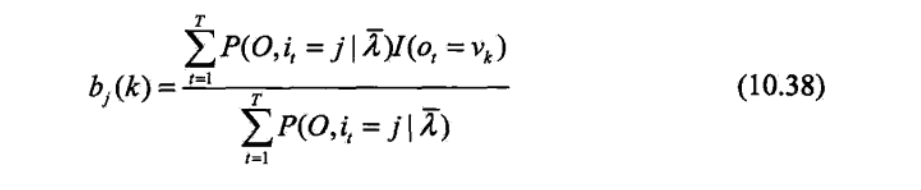
P(O,i1=i|λ)
p(O,it=i,it+1=j|λ)
终于到了讲前后向算法的时候了,个人认为前后向算法的引入就是为了计算上面概率的,而不是一开始就引入了后向变量,这个因果关系上我认为这样说比较符合当时的推导思路吧。
后向算法与前向算法相同,这里给出后向变量的定义:
βt(i) = P(Ot+1,OT|it=i,λ) 该公式表示在it时刻状态为i的情况下,后面到T时刻观测序列的概率情况。
由于最后一个时刻没有OT+1,所以直接硬性规定β(T) = 1,递归公式如下:
β1(i) = 1 i∈[1,N]
βt(i) = ∑j aij*bjot+1βt+1(j) i∈[1,N] t∈[1,T-1]
推导P(O,i1=i|λ)
αt(i) = P(O1,O2...Ot,it=i|λ)
βt(i) = P(Ot+1,...,OT|it=i,λ)
P(O,it=i|λ) = P(O1,O2...Ot,it=i,Ot+1,..OT |λ)
= P(O1,O2...Ot,it=i|λ) * P(Ot+1,...,OT|it=i,O1,O2...Ot,λ)
= P(O1,O2...Ot,it=i|λ) * P(Ot+1,...,OT|it=i,λ)
= αt(i) * βt(i)
这里推导的公式,有一个独立性的假设,这里并不太清楚,感觉可能观测序列就是独立的吧?不然这个等式也就变不过来了。
好勒,我们再来看两个变量,这两个变量分别表示,从某t时刻i状态的概率,和某t时候i状态到下个状态j的概率。这是Baum-welch算法里面描述的两个期望。
根据以上两个期望,我们带入重估函数里面,得到如下结果。
上面式子虽然是数学推导而来,但是同样具有特别强的概率含义。


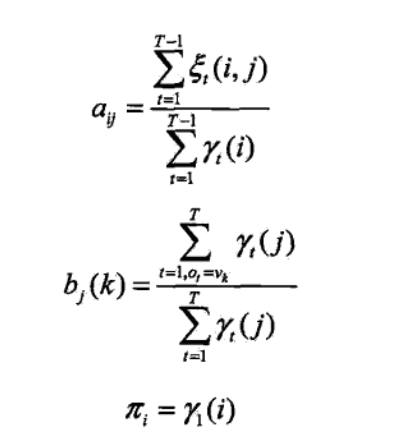

这次真的完结撒花了!小结一下,我们从EM算法的思想入手,考虑了我们的迭代函数,对就是这个期望
然后我们直接对他求导,差分开来,利用拉格朗日乘子法求出了各个重估函数,并且他们具有很明显的概率意义。之后我们引入了前后向算法来表示P(O,it=i|λ)概率,这一步完全是方便计算。最后我们引入两个中间期望变量γ和ε。好了下面给出代码啦_~
###python代码baum-welch算法
#计算公式中的beita二维数组
def _backward(self,observationsSeq):
T = len(observationsSeq)
N = len(self.pi)
beta = np.zeros((T,N),dtype=float)
beta[T-1,:] = 1
for t in reversed(range(T-1)):
for n in range(N):
beta[t,n] = np.sum(self.A[n,:] * self.B[:,observationsSeq[t+1]] * beta[t+1,:])
return beta
#前后向算法学习参数
def baumWelch(self,observationsSeq,criterion=0.001):
T = len(observationsSeq)
N = len(self.pi)
while True:
# alpha_t(i) = P(O_1 O_2 ... O_t, q_t = S_i | hmm)
# Initialize alpha
alpha = self._forward(observationsSeq)
# beta_t(i) = P(O_t+1 O_t+2 ... O_T | q_t = S_i , hmm)
# Initialize beta
beta = self._backward(observationsSeq)
#根据公式求解XIt(i,j) = P(qt=Si,qt+1=Sj | O,λ)
xi = np.zeros((T-1,N,N),dtype=float)
for t in range(T-1):
denominator = np.sum( np.dot(alpha[t,:],self.A) * self.B[:,observationsSeq[t+1]] * beta[t+1,:])
for i in range(N):
molecular = alpha[t,i] * self.A[i,:] * self.B[:,observationsSeq[t+1]] * beta[t+1,:]
xi[t,i,:] = molecular / denominator
#根据xi就可以求出gamma,注意最后缺了一项要单独补上来
gamma = np.sum(xi,axis=2)
prod = (alpha[T-1,:] * beta[T-1,:])
gamma = np.vstack((gamma, prod /np.sum(prod)))
newpi = gamma[0,:]
newA = np.sum(xi,axis=0) / np.sum(gamma[:-1,:],axis=0).reshape(-1,1)
newB = np.zeros(self.B.shape,dtype=float)
for k in range(self.B.shape[1]):
mask = observationsSeq == k
newB[:,k] = np.sum(gamma[mask,:],axis=0) / np.sum(gamma,axis=0)
if np.max(abs(self.pi - newpi)) < criterion and \
np.max(abs(self.A - newA)) < criterion and \
np.max(abs(self.B - newB)) < criterion:
break
self.A,self.B,self.pi = newA,newB,newpi
###Baum-welch算法可行性
Baum-welch算法的公式实际就是EM的Q函数,下面大致看下怎么推到的吧,其中用到了Jensen不等式,还是截图吧,只能理解,还不能把推倒理由讲彻底,这就是数学的魅力吧!
Jensen公式很重要的一点就是把log给变了位置,这样后续计算也是十分有利的,方便引入约束最优化问题。但是Baum-welch过程中貌似直接用期望公式的变化达到了这一点,本人暂时还没想特别明白。之后有人证明了EM算法的局部最优性,这是一个收敛的算法,并且局部最优。大家知道这些就差不多了,更为详细的还是去看数学书吧。

#词性标注实例
(此时,这博客已经写了8个小时了。)
上面讲完了所有的代码和推导,现在举个简单的小例子来看看HMM的效果。
先坑,有空补
#一些问题
多样本标注:
现在我们可以根据一个观测值去计算参数,但是对于多个序列,我们如何去操作呢,这是一个很实际的问题,能不能像神经网络里面一下,每个样本修改一点参数,到达较好的效果,网上有一些说法,可以取均值或者其他,这个如果有大神了解,欢迎指导。
Gaussian-HMM:
hmmlearn里面碰到了Gaussian-HMM的东西,一般我们假设观测和隐状态是离散的,不过可能并不都是这样。这是考虑观测连续且服从高斯分布的情况
github上面有比较完整的代码,想看的可以看下下,暂时没有提供完整的应用代码,只是简单的算法实现,以及基础工具。
https://github.com/Continue7777/HMM/
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/201144.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
