一、读写分离的原理:
1、实现原理:

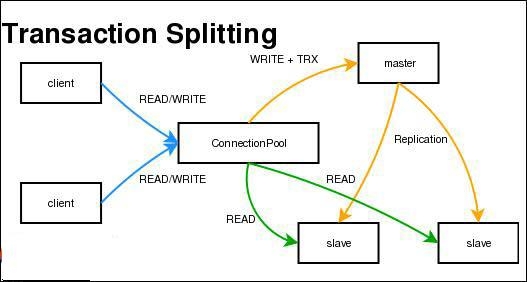
读写分离解决的是,数据库的写操作,影响了查询的效率,适用于读远大于写的场景。读写分离的实现基础是主从复制,主数据库利用主从复制将自身数据的改变同步到从数据库集群中,然后主数据库负责处理写操作(当然也可以执行读操作),从数据库负责处理读操作,不能执行写操作。并可以根据压力情况,部署多个从数据库提高读操作的速度,减少主数据库的压力,提高系统总体的性能。
2、读写分离提高性能的原因:
(1)增加物理服务器,负荷分摊;
假如我们有1主3从,假设现在1分钟内有10条写入,150条读取。那么,1主3从相当于共计40条写入,而读取总数没变,因此平均下来每台服务器承担了10条写入和50条读取(主库不承担读取操作)。因此,虽然写入没变,但是读取大大分摊了,提高了系统性能。另外,当读取被分摊后,又间接提高了写入的性能。所以,总体性能提高了,也就是拿机器和带宽换性能。
(2)主从只负责各自的写和读,极大程度的缓解X锁和S锁争用;
(3)从库可配置MyISAM引擎,提升查询性能以及节约系统开销;
(4)主从复制另外一大功能是增加冗余,提高可用性,当一台数据库服务器宕机后能通过调整另外一台从库来以最快的速度恢复服务。
3、Mysql读写分写的实现方式:
(1)基于程序代码内部实现:
在代码中根据select 、insert进行路由分类,这类方法也是目前生产环境下应用最广泛的。优点是性能较好,因为程序在代码中实现,不需要增加额外的硬件开支,缺点是需要开发人员来实现,运维人员无从下手。
(2)基于中间代理层实现:
代理一般介于应用服务器和数据库服务器之间,代理数据库服务器接收到应用服务器的请求后根据判断后转发到后端数据库,有以下代表性的代理层。
①mysql_proxy。mysql_proxy是Mysql的一个开源项目,通过其自带的lua脚本进行sql判断。
②Atlas。是由 奇虎360, Web平台部基础架构团队开发维护的一个基于MySQL协议的数据中间层项目。它是在mysql-proxy 0.8.2版本的基础上,对其进行了优化,增加了一些新的功能特性。360内部使用Atlas运行的mysql业务,每天承载的读写请求数达几十亿条。支持事务以及存储过程。
③Amoeba。由阿里巴巴集团在职员工陈思儒使用序java语言进行开发,阿里巴巴集团将其用户生产环境下,但是他并不支持事物以及存储过程。
经过上述简单的比较,不是所有的应用都能够在基于程序代码中实现读写分离,像一些大型的java应用,如果在程序代码中实现读写分离对代码的改动就较大,所以,像这种应用一般会考虑使用代理层来实现。
二、读写分离的搭建:
有关读写分离的搭建步骤,可以阅读这两篇博客:
https://blog.csdn.net/starlh35/article/details/78735510
https://blog.csdn.net/justdb/article/details/17331569
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/100074.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
