在使用Redis时,我们一般会为Redis的缓存空间设置一个大小,不会让数据无限制地放入Redis缓存中。可以使用下面命令来设定缓存的大小,比如设置为4GB:
CONFIG SET maxmemory 4gb
既然 Redis 设置了缓存的容量大小,那缓存被写满就是不可避免的。当缓存被写满时,我们需要考虑下面两个问题:决定淘汰哪些数据,如何处理那些被淘汰的数据。
一、Redis的数据过期清除策略:
如果我们设置了Redis的key-value的过期时间,当缓存中的数据过期之后,Redis就需要将这些数据进行清除,释放占用的内存空间。Redis中主要使用 定期删除 + 惰性删除 两种数据过期清除策略。
1、过期策略:定期删除+惰性删除:
(1)定期删除:redis默认每隔100ms就随机抽取一些设置了过期时间的key,检查其是否过期,如果有过期就删除。注意这里是随机抽取的。为什么要随机呢?你想一想假如 redis 存了几十万个 key ,每隔100ms就遍历所有的设置过期时间的 key 的话,就会给 CPU 带来很大的负载。
为什么不用定时删除策略呢?
定时删除,用一个定时器来负责监视key,过期则自动删除。虽然内存及时释放,但是十分消耗CPU资源。在大并发请求下,CPU要将时间应用在处理请求,而不是删除key,因此没有采用这一策略。
(2)惰性删除:定期删除可能导致很多过期的key 到了时间并没有被删除掉。这时就要使用到惰性删除。在你获取某个key的时候,redis会检查一下,这个key如果设置了过期时间并且过期了,是的话就删除。
2、定期删除+惰性删除存在的问题:
如果某个key过期后,定期删除没删除成功,然后也没再次去请求key,也就是说惰性删除也没生效。这时,如果大量过期的key堆积在内存中,redis的内存会越来越高,导致redis的内存块耗尽。那么就应该采用内存淘汰机制。
二、Redis的缓存淘汰策略:
Redis共提供了8中缓存淘汰策略,其中 volatile-lfu 和 allkeys-lfu 是Redis 4.0版本新增的。
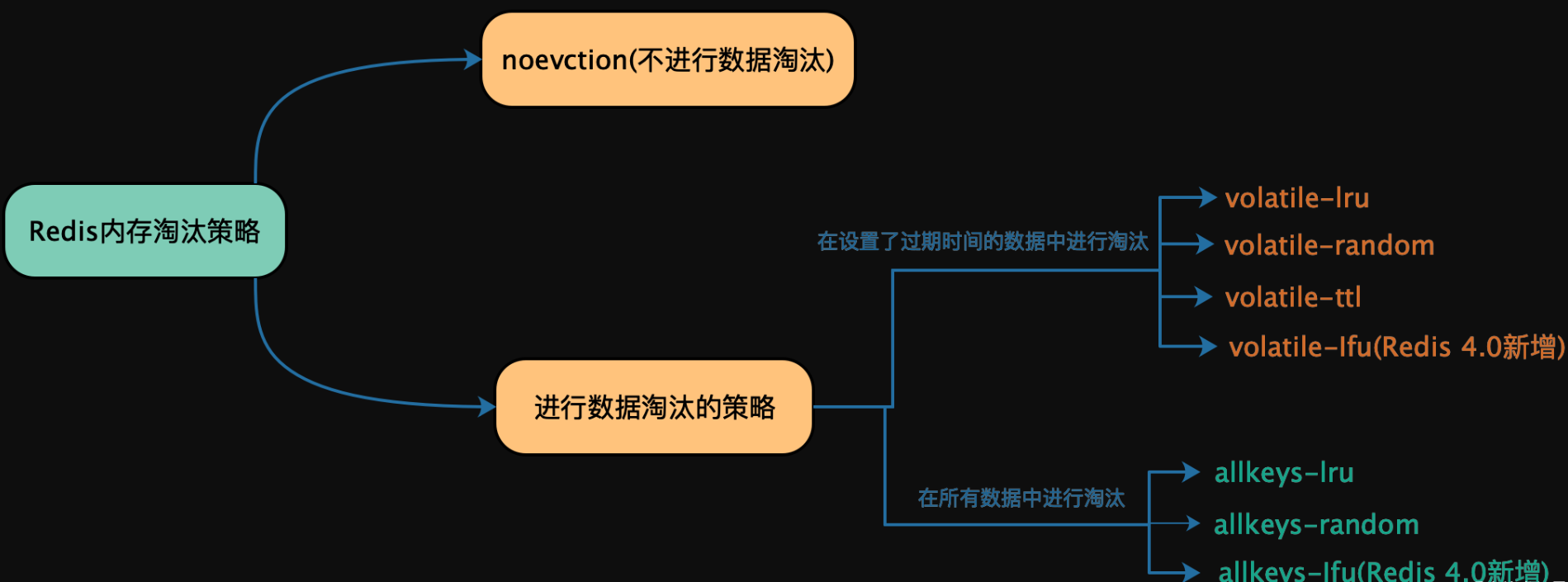

1、noeviction:不进行淘汰数据。一旦缓存被写满,再有写请求进来,Redis就不再提供服务,而是直接返回错误。Redis 用作缓存时,实际的数据集通常都是大于缓存容量的,总会有新的数据要写入缓存,这个策略本身不淘汰数据,也就不会腾出新的缓存空间,我们不把它用在 Redis 缓存中。
2、volatile-ttl:在设置了过期时间的键值对中,移除即将过期的键值对。
3、volatile-random:在设置了过期时间的键值对中,随机移除某个键值对。
4、volatile-lru:在设置了过期时间的键值对中,移除最近最少使用的键值对。
5、volatile-lfu:在设置了过期时间的键值对中,移除最近最不频繁使用的键值对
6、allkeys-random:在所有键值对中,随机移除某个key。
7、allkeys-lru:在所有的键值对中,移除最近最少使用的键值对。
8、allkeys-lfu:在所有的键值对中,移除最近最不频繁使用的键值对
通常情况下推荐优先使用 allkeys-lru 策略。这样可以充分利用 LRU 这一经典缓存算法的优势,把最近最常访问的数据留在缓存中,提升应用的访问性能。
如果你的业务数据中有明显的冷热数据区分,建议使用 allkeys-lru 策略。
如果业务应用中的数据访问频率相差不大,没有明显的冷热数据区分,建议使用 allkeys-random 策略,随机选择淘汰的数据就行。
如果没有设置过期时间的键值对,那么 volatile-lru,volatile-lfu,volatile-random 和 volatile-ttl 策略的行为, 和 noeviction 基本上一致。
三、Redis中的LRU和LFU算法:
1、LRU算法:
LRU 算法的全称是 Least Recently Uses,按照最近最少使用的原则来筛选数据,最不常用的数据会被筛选出来。LRU 会把所有的数据组织成一个链表,链表的头和尾分别表示 MRU 端和 LRU 端,分别代表最近最常使用的数据和最近最不常用的数据。我们看一个例子。
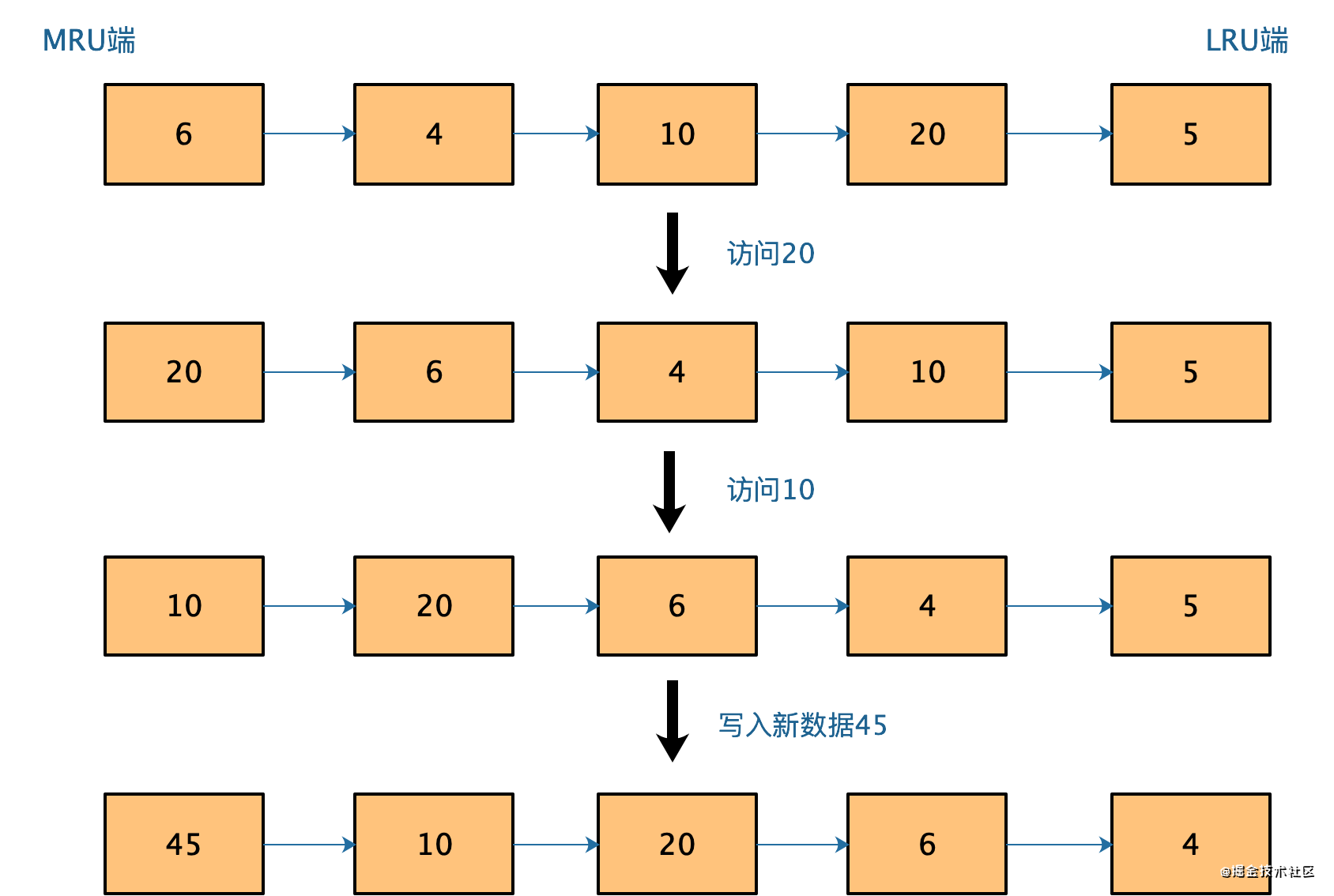
如果有一个新数据 45 要被写入缓存,但此时已经没有缓存空间了,也就是链表没有空余位置了,那么LRU 算法做两件事:数据 45 是刚被访问的,所以它会被放到 MRU 端;算法把 LRU 端的数据 5 从缓存中删除,相应的链表中就没有数据 5 的记录了。LRU认为刚刚被访问的数据,肯定还会被再次访问,所以就把它放在 MRU 端;长久不访问的数据,肯定就不会再被访问了,所以就让它逐渐后移到 LRU 端,在缓存满时,就优先删除它。
LRU 算法在实际实现时,需要用链表管理所有的缓存数据,移除元素时直接从链表队尾移除,增加时加到头部就可以了,但这会带来额外的空间开销。而且,当有数据被访问时,需要在链表上把该数据移动到 MRU 端,如果有大量数据被访问,就会带来很多链表移动操作,会很耗时,进而会降低 Redis 缓存性能。
所以,在 Redis 中,LRU 算法被做了简化,以减轻数据淘汰对缓存性能的影响。具体来说:Redis 默认会记录每个数据的最近一次访问的时间戳(由键值对数据结构 RedisObject 中的 lru 字段记录)。然后,Redis 在决定淘汰的数据时,第一次会随机选出 N 个数据,把它们作为一个候选集合。接下来,Redis 会比较这 N 个数据的 lru 字段,把 lru 字段值最小的数据从缓存中淘汰出去。当需要再次淘汰数据时,Redis 需要挑选数据进入第一次淘汰时创建的候选集合。这里的挑选标准是:能进入候选集合的数据的 lru 字段值必须小于候选集合中最小的 lru 值。当有新数据进入候选数据集后,如果候选数据集中的数据个数达到了 N 个,Redis 就把候选数据集中 lru 字段值最小的数据淘汰出去。这样一来,Redis 缓存不用为所有的数据维护一个大链表,也不用在每次数据访问时都移动链表项,提升了缓存的性能。
Redis 提供了一个配置参数 maxmemory-samples,这个参数就是 Redis 选出的数据个数 N。例如,我们执行如下命令,可以让 Redis 选出 100 个数据作为候选数据集:
CONFIG SET maxmemory-samples 100
RedisObject 的定义如下:(简单理解为一个 key-value)
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time). */
int refcount;
void *ptr;
} robj;
2、LFU算法:
LFU是在Redis4.0后出现的,它的核心思想是根据key的最近被访问的频率进行淘汰,很少被访问的优先被淘汰,被访问的多的则被留下来。LFU算法能更好的表示一个key被访问的热度。假如你使用的是LRU算法,一个key很久没有被访问到,只刚刚是偶尔被访问了一次,那么它就被认为是热点数据,不会被淘汰,而有些key将来是很有可能被访问到的则被淘汰了。如果使用LFU算法则不会出现这种情况,因为使用一次并不会使一个key成为热点数据。它的使用与LRU有所区别:
LFU (Least Frequently Used) :最近最不频繁使用,跟使用的次数有关,淘汰使用次数最少的。
LRU (Least Recently Used):最近最少使用,跟使用的最后一次时间有关,淘汰最近使用时间离现在最久的。
LRU的最近最少使用实际上并不精确,考虑下面的情况,如果在 “|” 处删除,那么A距离的时间最久,但实际上A的使用频率要比D频繁,所以合理的淘汰策略应该是淘汰D。LFU就是为应对这种情况而生的。
~~~~~A~~~~~A~~~~~A~~~~A~~~~~A~~~~~A~~|
~~R~~R~~R~~R~~R~~R~~R~~R~~R~~R~~R~~R~|
~~~~~~~~~~C~~~~~~~~~C~~~~~~~~~C~~~~~~|
~~~~~D~~~~~~~~~~D~~~~~~~~~D~~~~~~~~~D|每个波浪号代表一秒,A 每五秒,R 每两秒,C 和 D 每十秒 , 最近被访问的字符是 D,但显然按照现有的规律,下一个被访问的更可能是 R 而不是 D。
LFU 实现比较复杂,需要考虑几个问题:
- 如果实现为链表,当对象被访问时按访问次数移动到链表的某个有序位置可能是低效的,因为可能存在大量访问次数相同的 key,最差情况是O(n)
- 某些 key 访问次数可能非常之大,理论上可以无限大,但实际上我们并不需要精确的访问次数
- 访问次数特别大的 key 可能以后都不再访问了,但是因为访问次数大而一直占用着内存不被淘汰,需要一个方法来逐步“驱除”(有点 LRU的意思),最简单的就是逐步衰减访问次数
本着能省则省的原则,Redis 只用了 24bit (server.lruclock 也是24bit)来记录上述的信息,是的不是 24byte,连32位指针都放不下!
16bit : 上一次递减时间 (解决第三个问题)
8bit : 访问次数 (解决第二个问题)
访问次数的计算如下:
uint8_t LFULogIncr(uint8_t counter) {
if (counter == 255) return 255;
double r = (double)rand()/RAND_MAX;
double baseval = counter - LFU_INIT_VAL;
if (baseval < 0) baseval = 0;
double p = 1.0/(baseval*server.lfu_log_factor+1);
if (r < p) counter++;
return counter;
}
核心就是访问次数越大,访问次数被递增的可能性越小,最大 255,可以在配置 redis.conf 中写明访问多少次递增多少。由于访问次数是有限的,所以第一个问题也被解决了,直接一个255数组或链表都可以。
16bit 部分保存的是时间戳的后16位(分钟),表示上一次递减的时间,算法是这样执行,随机采样N个key,检查递减时间,如果距离现在超过 N 分钟(可配置),则递减或者减半(如果访问次数数值比较大)。
此外,由于新加入的 key 访问次数很可能比不被访问的老 key小,为了不被马上淘汰,新key访问次数设为 5。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/100030.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
