流程图如下。
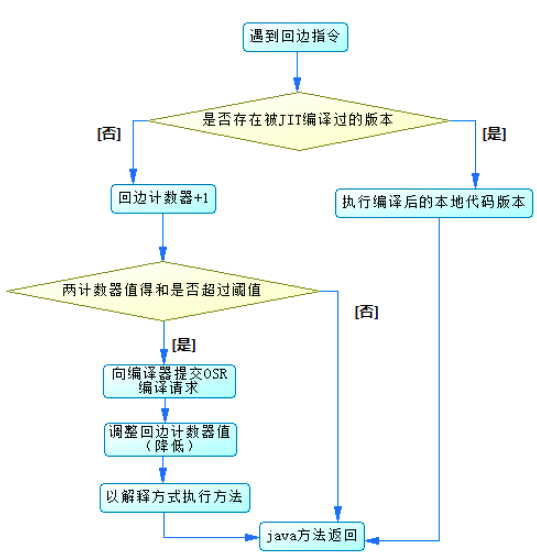

决定一个方法是否为热点代码的因素有两个:方法的调用次数、循环回边的执行次数。即时编译便是根据这两个计数器的和来触发的。为什么 Java 虚拟机需要维护两个不同的计数器呢?
实际上,除了以方法为单位的即时编译之外,Java 虚拟机还存在着另一种以循环为单位的即时编译,叫做 On-Stack-Replacement(OSR)编译。循环回边计数器便是用来触发这种类型的编译的。
OSR 实际上是一种技术,它指的是在程序执行过程中,动态地替换掉 Java 方法栈桢,从而使得程序能够在非方法入口处进行解释执行和编译后的代码之间的切换。事实上,去优化(deoptimization)采用的技术也可以称之为 OSR。
在不启用分层编译的情况下,触发 OSR 编译的阈值是由参数 -XX:CompileThreshold 指定的阈值的倍数。
该倍数的计算方法为:
(OnStackReplacePercentage - InterpreterProfilePercentage)/100
其中 -XX:InterpreterProfilePercentage 的默认值为 33,当使用 C1 时 -XX:OnStackReplacePercentage 为 933,当使用 C2 时为 140。
也就是说,默认情况下,C1 的 OSR 编译的阈值为 13500,而 C2 的为 10700。
在启用分层编译的情况下,触发 OSR 编译的阈值则是由参数 -XX:TierXBackEdgeThreshold 指定的阈值乘以系数。
OSR 编译在正常的应用程序中并不多见。它只在基准测试时比较常见,因此并不需要过多了解。
通过调用TemplateTable::_goto()函数来完成goto()指令的机器代码生成。如下:
// 将当前栈帧中保存的Method* 拷贝到rcx中 0x00007fffe101dd10: mov -0x18(%rbp),%rcx // 如果开启了profile则执行分支跳转相关的性能统计 // If no method data exists, go to profile_continue. // Otherwise, assign to mdp 0x00007fffe101dd14: mov -0x20(%rbp),%rax 0x00007fffe101dd18: test %rax,%rax 0x00007fffe101dd1b: je 0x00007fffe101dd39 // 将JumpData::taken_off_set存储到%rax中 0x00007fffe101dd21: mov 0x8(%rax),%rbx // 增加DataLayout::counter_increment,值为1 0x00007fffe101dd25: add $0x1,%rbx // sbb是带借位减法指令 0x00007fffe101dd29: sbb $0x0,%rbx // 存储回JumpData::taken_off_set中 0x00007fffe101dd2d: mov %rbx,0x8(%rax) // The method data pointer needs to be updated to reflect the new target. // 将JumpData::displacement_off_set // %rax中存储的是MethodData* 0x00007fffe101dd31: add 0x10(%rax),%rax // 将计算出的值存储到栈中interpreter_frame_mdx_offset偏向处 0x00007fffe101dd35: mov %rax,-0x20(%rbp) // **** profile_continue **** // 将当前字节码位置往后偏移1字节处开始的2字节数据读取到rdx中 0x00007fffe101dd39: movswl 0x1(%r13),%edx // 将rdx中的值字节次序变反 0x00007fffe101dd3e: bswap %edx // 将rdx中的值右移16位,上述两步就是为了计算跳转分支的偏移量 0x00007fffe101dd40: sar $0x10,%edx // 将rdx中的数据从2字节扩展成4字节 0x00007fffe101dd43: movslq %edx,%rdx // 将当前字节码地址加上rdx保存的偏移量,计算跳转的目标地址 0x00007fffe101dd46: add %rdx,%r13
如果UseLoopCounter为true时才会有如下汇编,在执行如下汇编时,各个寄存器的状态如下:
increment backedge counter for backward branches
rax: MDO ebx: MDO bumped taken-count rcx: method rdx: target offset r13: target bcp r14: locals pointer
汇编如下:
// 校验rdx是否大于0,如果大于0说明是往前跳转,如果小于0说明是往后跳转,如果大于0则跳转到dispatch,这样只有回边才会进行统计 0x00007fffe101dd49: test %edx,%edx 0x00007fffe101dd4b: jns 0x00007fffe101de30 // 跳转到dispatch // 执行这里时,说明有回边需要统计 // 检查Method::_method_counters是否为NULL,如果非空则跳转到has_counters 0x00007fffe101dd51: mov 0x20(%rcx),%rax 0x00007fffe101dd55: test %rax,%rax 0x00007fffe101dd58: jne 0x00007fffe101ddf4 // 如果为空,则通过InterpreterRuntime::build_method_counters()函数创建一个新的MethodCounters 0x00007fffe101dd5e: push %rdx 0x00007fffe101dd5f: push %rcx 0x00007fffe101dd60: callq 0x00007fffe101dd6a 0x00007fffe101dd65: jmpq 0x00007fffe101dde8 0x00007fffe101dd6a: mov %rcx,%rsi 0x00007fffe101dd6d: lea 0x8(%rsp),%rax 0x00007fffe101dd72: mov %r13,-0x38(%rbp) 0x00007fffe101dd76: mov %r15,%rdi 0x00007fffe101dd79: mov %rbp,0x200(%r15) 0x00007fffe101dd80: mov %rax,0x1f0(%r15) 0x00007fffe101dd87: test $0xf,%esp 0x00007fffe101dd8d: je 0x00007fffe101dda5 0x00007fffe101dd93: sub $0x8,%rsp 0x00007fffe101dd97: callq 0x00007ffff66b581c 0x00007fffe101dd9c: add $0x8,%rsp 0x00007fffe101dda0: jmpq 0x00007fffe101ddaa 0x00007fffe101dda5: callq 0x00007ffff66b581c 0x00007fffe101ddaa: movabs $0x0,%r10 0x00007fffe101ddb4: mov %r10,0x1f0(%r15) 0x00007fffe101ddbb: movabs $0x0,%r10 0x00007fffe101ddc5: mov %r10,0x200(%r15) 0x00007fffe101ddcc: cmpq $0x0,0x8(%r15) 0x00007fffe101ddd4: je 0x00007fffe101dddf 0x00007fffe101ddda: jmpq 0x00007fffe1000420 0x00007fffe101dddf: mov -0x38(%rbp),%r13 0x00007fffe101dde3: mov -0x30(%rbp),%r14 0x00007fffe101dde7: retq 0x00007fffe101dde8: pop %rcx 0x00007fffe101dde9: pop %rdx // 将创建出新的MethodCounters存储到%rax中 0x00007fffe101ddea: mov 0x20(%rcx),%rax //如果创建失败,则跳转到到dispatch分支 0x00007fffe101ddee: je 0x00007fffe101de30 // ....
如下在启动分层编译时才会生成的汇编:
// **** has_counters **** // 开启profile性能收集才会生成的汇编 // 获取Method::_method_data属性到rbx中,并校验其是否为空,如果为空则跳转到no_mdo 0x00007fffe101ddf4: mov 0x18(%rcx),%rbx 0x00007fffe101ddf8: test %rbx,%rbx 0x00007fffe101ddfb: je 0x00007fffe101de17 //Method::_method_data属性不为空,则增加Method::_method_data::_backedge_counter计数值,如果超过阈值则跳转到backedge_counter_overflow 0x00007fffe101ddfd: mov 0x70(%rbx),%eax 0x00007fffe101de00: add $0x8,%eax 0x00007fffe101de03: mov %eax,0x70(%rbx) 0x00007fffe101de06: and $0x1ff8,%eax 0x00007fffe101de0c: je 0x00007fffe101df22 // 跳转到backedge_counter_overflow // 跳转到dispatch 0x00007fffe101de12: jmpq 0x00007fffe101de30 // **** no_mdo **** // 增加Method::_method_counters::backedge_counter的调用计数,如果超过阈值则跳转到backedge_counter_overflow 0x00007fffe101de17: mov 0x20(%rcx),%rcx 0x00007fffe101de1b: mov 0xc(%rcx),%eax 0x00007fffe101de1e: add $0x8,%eax 0x00007fffe101de21: mov %eax,0xc(%rcx) 0x00007fffe101de24: and $0x1ff8,%eax 0x00007fffe101de2a: je 0x00007fffe101df22 // 跳转到backedge_counter_overflow // **** dispatch **** // r13已经变成目标跳转地址,这里是加载跳转地址的第一个字节码到rbx中 0x00007fffe101de30: movzbl 0x0(%r13),%ebx 0x00007fffe101de35: movabs $0x7ffff73b9e40,%r10 0x00007fffe101de3f: jmpq *(%r10,%rbx,8) // **** profile_method **** // 通过call_VM()函数来调用InterpreterRuntime::profile_method()函数 0x00007fffe101de43: callq 0x00007fffe101de4d 0x00007fffe101de48: jmpq 0x00007fffe101dec8 0x00007fffe101de4d: lea 0x8(%rsp),%rax 0x00007fffe101de52: mov %r13,-0x38(%rbp) 0x00007fffe101de56: mov %r15,%rdi 0x00007fffe101de59: mov %rbp,0x200(%r15) 0x00007fffe101de60: mov %rax,0x1f0(%r15) 0x00007fffe101de67: test $0xf,%esp 0x00007fffe101de6d: je 0x00007fffe101de85 0x00007fffe101de73: sub $0x8,%rsp 0x00007fffe101de77: callq 0x00007ffff66b4d84 0x00007fffe101de7c: add $0x8,%rsp 0x00007fffe101de80: jmpq 0x00007fffe101de8a 0x00007fffe101de85: callq 0x00007ffff66b4d84 0x00007fffe101de8a: movabs $0x0,%r10 0x00007fffe101de94: mov %r10,0x1f0(%r15) 0x00007fffe101de9b: movabs $0x0,%r10 0x00007fffe101dea5: mov %r10,0x200(%r15) 0x00007fffe101deac: cmpq $0x0,0x8(%r15) 0x00007fffe101deb4: je 0x00007fffe101debf 0x00007fffe101deba: jmpq 0x00007fffe1000420 0x00007fffe101debf: mov -0x38(%rbp),%r13 0x00007fffe101dec3: mov -0x30(%rbp),%r14 0x00007fffe101dec7: retq // 结束call_VM()函数结束 // 调用set_method_data_pointer_for_bcp()函数生成的汇编 // restore target bytecode 0x00007fffe101dec8: movzbl 0x0(%r13),%ebx 0x00007fffe101decd: push %rax 0x00007fffe101dece: push %rbx // 获取Method::_method_data并存储到%rax中 0x00007fffe101decf: mov -0x18(%rbp),%rbx 0x00007fffe101ded3: mov 0x18(%rbx),%rax // 如果Method::_method_data为NULL,则跳转到set_mdp 0x00007fffe101ded7: test %rax,%rax 0x00007fffe101deda: je 0x00007fffe101df17 // 通过call_VM_leaf()函数调用InterpreterRuntime::bcp_to_di()函数 0x00007fffe101dee0: mov %r13,%rsi 0x00007fffe101dee3: mov %rbx,%rdi 0x00007fffe101dee6: test $0xf,%esp 0x00007fffe101deec: je 0x00007fffe101df04 0x00007fffe101def2: sub $0x8,%rsp 0x00007fffe101def6: callq 0x00007ffff66b4bb4 0x00007fffe101defb: add $0x8,%rsp 0x00007fffe101deff: jmpq 0x00007fffe101df09 0x00007fffe101df04: callq 0x00007ffff66b4bb4 // rax: mdi // mdo is guaranteed to be non-zero here, we checked for it before the call. // 将Method::_method_data存储到%rbx中 0x00007fffe101df09: mov 0x18(%rbx),%rbx // 增加Method::_method_data::_data偏移 0x00007fffe101df0d: add $0x90,%rbx 0x00007fffe101df14: add %rbx,%rax // **** set_mdp **** // 通过interpreter_frame_mdx_offset来获取mdx 0x00007fffe101df17: mov %rax,-0x20(%rbp) 0x00007fffe101df1b: pop %rbx 0x00007fffe101df1c: pop %rax // 结束set_method_data_pointer_for_bcp()函数调用 0x00007fffe101df1d: jmpq 0x00007fffe101de30
调用的InterpreterRuntime::profile_method()函数的实现如下:
IRT_ENTRY(void, InterpreterRuntime::profile_method(JavaThread* thread))
// use UnlockFlagSaver to clear and restore the _do_not_unlock_if_synchronized
// flag, in case this method triggers classloading which will call into Java.
UnlockFlagSaver fs(thread);
assert(ProfileInterpreter, "must be profiling interpreter");
frame fr = thread->last_frame();
assert(fr.is_interpreted_frame(), "must come from interpreter");
methodHandle method(thread, fr.interpreter_frame_method());
Method::build_interpreter_method_data(method, THREAD);
IRT_END
// Build a MethodData* object to hold information about this method
// collected in the interpreter.
void Method::build_interpreter_method_data(methodHandle method, TRAPS) {
// Do not profile method if current thread holds the pending list lock,
// which avoids deadlock for acquiring the MethodData_lock.
if (InstanceRefKlass::owns_pending_list_lock((JavaThread*)THREAD)) {
return;
}
// Grab a lock here to prevent multiple MethodData*s from being created.
MutexLocker ml(MethodData_lock, THREAD);
if (method->method_data() == NULL) {
ClassLoaderData* loader_data = method->method_holder()->class_loader_data();
MethodData* method_data = MethodData::allocate(loader_data, method, CHECK);
method->set_method_data(method_data);
}
}
就是为Method::_method_data属性创建MethodData对象并赋值。
// 只有开启UseOnStackReplacement时才会生成如下汇编 // 当超过阈值后会跳转到此分支 // **** backedge_counter_overflow **** // 对rdx中的数取补码 0x00007fffe101df22: neg %rdx // 将r13的地址加到rdx上,这两步是计算跳转地址 0x00007fffe101df25: add %r13,%rdx // 通过调用call_VM()函数来调用InterpreterRuntime::frequency_counter_overflow()函数 0x00007fffe101df28: callq 0x00007fffe101df32 0x00007fffe101df2d: jmpq 0x00007fffe101dfb0 0x00007fffe101df32: mov %rdx,%rsi 0x00007fffe101df35: lea 0x8(%rsp),%rax 0x00007fffe101df3a: mov %r13,-0x38(%rbp) 0x00007fffe101df3e: mov %r15,%rdi 0x00007fffe101df41: mov %rbp,0x200(%r15) 0x00007fffe101df48: mov %rax,0x1f0(%r15) 0x00007fffe101df4f: test $0xf,%esp 0x00007fffe101df55: je 0x00007fffe101df6d 0x00007fffe101df5b: sub $0x8,%rsp 0x00007fffe101df5f: callq 0x00007ffff66b45c8 0x00007fffe101df64: add $0x8,%rsp 0x00007fffe101df68: jmpq 0x00007fffe101df72 0x00007fffe101df6d: callq 0x00007ffff66b45c8 0x00007fffe101df72: movabs $0x0,%r10 0x00007fffe101df7c: mov %r10,0x1f0(%r15) 0x00007fffe101df83: movabs $0x0,%r10 0x00007fffe101df8d: mov %r10,0x200(%r15) 0x00007fffe101df94: cmpq $0x0,0x8(%r15) 0x00007fffe101df9c: je 0x00007fffe101dfa7 0x00007fffe101dfa2: jmpq 0x00007fffe1000420 0x00007fffe101dfa7: mov -0x38(%rbp),%r13 0x00007fffe101dfab: mov -0x30(%rbp),%r14 0x00007fffe101dfaf: retq // 结束call_VM()函数的调用 // 恢复待执行的字节码 0x00007fffe101dfb0: movzbl 0x0(%r13),%ebx // rax: osr nmethod (osr ok) or NULL (osr not possible) // ebx: target bytecode // rdx: scratch // r14: locals pointer // r13: bcp // 校验frequency_counter_overflow()函数返回的编译结果是否为空,如果为空则跳转到dispatch,即继续执行字节码 0x00007fffe101dfb5: test %rax,%rax 0x00007fffe101dfb8: je 0x00007fffe101de30 // 如果不为空,即表示方法编译完成,将nmethod::_entry_bci属性的偏移复制到rcx中 0x00007fffe101dfbe: mov 0x48(%rax),%ecx // 如果rcx等于InvalidOSREntryBci,则跳转到dispatch 0x00007fffe101dfc1: cmp $0xfffffffe,%ecx 0x00007fffe101dfc4: je 0x00007fffe101de30 // 开始执行栈上替换 // We have the address of an on stack replacement routine in eax // We need to prepare to execute the OSR method. First we must // migrate the locals and monitors off of the stack. 0x00007fffe101dfca: mov %rax,%r13 // save the nmethod // 通过调用call_VM()函数调用SharedRuntime::OSR_migration_begin()函数 // // 调用OSR_migration_begin方法,完成栈帧上变量和monitor的迁移 0x00007fffe101dfcd: callq 0x00007fffe101dfd7 0x00007fffe101dfd2: jmpq 0x00007fffe101e052 0x00007fffe101dfd7: lea 0x8(%rsp),%rax 0x00007fffe101dfdc: mov %r13,-0x38(%rbp) 0x00007fffe101dfe0: mov %r15,%rdi 0x00007fffe101dfe3: mov %rbp,0x200(%r15) 0x00007fffe101dfea: mov %rax,0x1f0(%r15) 0x00007fffe101dff1: test $0xf,%esp 0x00007fffe101dff7: je 0x00007fffe101e00f 0x00007fffe101dffd: sub $0x8,%rsp 0x00007fffe101e001: callq 0x00007ffff6a18a6a 0x00007fffe101e006: add $0x8,%rsp 0x00007fffe101e00a: jmpq 0x00007fffe101e014 0x00007fffe101e00f: callq 0x00007ffff6a18a6a 0x00007fffe101e014: movabs $0x0,%r10 0x00007fffe101e01e: mov %r10,0x1f0(%r15) 0x00007fffe101e025: movabs $0x0,%r10 0x00007fffe101e02f: mov %r10,0x200(%r15) 0x00007fffe101e036: cmpq $0x0,0x8(%r15) 0x00007fffe101e03e: je 0x00007fffe101e049 0x00007fffe101e044: jmpq 0x00007fffe1000420 0x00007fffe101e049: mov -0x38(%rbp),%r13 0x00007fffe101e04d: mov -0x30(%rbp),%r14 0x00007fffe101e051: retq // eax is OSR buffer, move it to expected parameter location // 将rax中的值拷贝到%rsi(j_rarg0) 0x00007fffe101e052: mov %rax,%rsi // 获取interpreter_frame_sender_sp_offset偏移处的值 0x00007fffe101e055: mov -0x8(%rbp),%rdx 0x00007fffe101e059: leaveq // remove frame anchor 0x00007fffe101e05a: pop %rcx // get return address 0x00007fffe101e05b: mov %rdx,%rsp // set sp to sender sp // Ensure compiled code always sees stack at proper alignment // -StackAlignmentInBytes为$0xfffffffffffffff0 0x00007fffe101e05e: and $0xfffffffffffffff0,%rsp // unlike x86 we need no specialized return from compiled code to the interpreter or the call stub. // push the return address 0x00007fffe101e062: push %rcx // 跳转到nmethod::_osr_entry_point,开始执行 0x00007fffe101e063: jmpq *0x88(%r13)
调用的SharedRuntime::OSR_migration_begin()函数的实现如下:
// OSR Migration Code
//
// This code is used convert interpreter frames into compiled frames. It is
// called from very start of a compiled OSR nmethod. A temp array is
// allocated to hold the interesting bits of the interpreter frame. All
// active locks are inflated to allow them to move. The displaced headers and
// active interpeter locals are copied into the temp buffer. Then we return
// back to the compiled code. The compiled code then pops the current
// interpreter frame off the stack and pushes a new compiled frame. Then it
// copies the interpreter locals and displaced headers where it wants.
// Finally it calls back to free the temp buffer.
//
// All of this is done NOT at any Safepoint, nor is any safepoint or GC allowed.
// 调用OSR_migration_begin方法,完成栈帧上变量和monitor的迁移
JRT_LEAF(intptr_t*, SharedRuntime::OSR_migration_begin( JavaThread *thread) )
// This code is dependent on the memory layout of the interpreter local
// array and the monitors. On all of our platforms the layout is identical
// so this code is shared. If some platform lays the their arrays out
// differently then this code could move to platform specific code or
// the code here could be modified to copy items one at a time using
// frame accessor methods and be platform independent.
frame fr = thread->last_frame();
assert( fr.is_interpreted_frame(), "" );
assert( fr.interpreter_frame_expression_stack_size()==0, "only handle empty stacks" );
// Figure out how many monitors are active.
int active_monitor_count = 0;
for(
BasicObjectLock *kptr = fr.interpreter_frame_monitor_end();
kptr < fr.interpreter_frame_monitor_begin();
kptr = fr.next_monitor_in_interpreter_frame(kptr)
) {
if( kptr->obj() != NULL ) {
active_monitor_count++;
}
}
// QQQ we could place number of active monitors in the array so that compiled code
// could double check it.
Method* moop = fr.interpreter_frame_method();
int max_locals = moop->max_locals();
// Allocate temp buffer, 1 word per local & 2 per active monitor
int buf_size_words = max_locals + active_monitor_count*2;
intptr_t *buf = NEW_C_HEAP_ARRAY(intptr_t,buf_size_words, mtCode);
// Copy the locals. Order is preserved so that loading of longs works.
// Since there's no GC I can copy the oops blindly.
assert( sizeof(HeapWord)==sizeof(intptr_t), "fix this code");
Copy::disjoint_words((HeapWord*)fr.interpreter_frame_local_at(max_locals-1),
(HeapWord*)&buf[0],
max_locals);
// Inflate locks. Copy the displaced headers. Be careful, there can be holes.
int i = max_locals;
for(
BasicObjectLock *kptr2 = fr.interpreter_frame_monitor_end();
kptr2 < fr.interpreter_frame_monitor_begin();
kptr2 = fr.next_monitor_in_interpreter_frame(kptr2)
){
if( kptr2->obj() != NULL) { // Avoid 'holes' in the monitor array
BasicLock *lock = kptr2->lock();
// Inflate so the displaced header becomes position-independent,什么意思??
if (lock->displaced_header()->is_unlocked()){ // 无锁状态
ObjectSynchronizer::inflate_helper(kptr2->obj()); // 将锁对象膨胀为重量级锁
}
// Now the displaced header is free to move
buf[i++] = (intptr_t)lock->displaced_header();
buf[i++] = cast_from_oop<intptr_t>(kptr2->obj());
}
}
assert( i - max_locals == active_monitor_count*2, "found the expected number of monitors" );
return buf;
JRT_END
调用InstanceKlass::add_osr_nmethod()与InstanceKlass::remove_osr_nmethod()对OSR进行安装与卸载。
add_osr_nmethod用于将需要执行栈上替换的nmethod实例插入到InstanceKlass的osr_nmethods链表上,方法实现如下:
void InstanceKlass::add_osr_nmethod(nmethod* n) {
// 获取锁
OsrList_lock->lock_without_safepoint_check();
//校验必须是栈上替换方法
assert(n->is_osr_method(), "wrong kind of nmethod");
// 将_osr_nmethods_head设置成n的下一个方法
n->set_osr_link(osr_nmethods_head());
// 将n设置为_osr_nmethods_head
set_osr_nmethods_head(n);
// 如果使用分层编译
if (TieredCompilation) {
Method* m = n->method();
// 更新最高编译级别
m->set_highest_osr_comp_level(MAX2(m->highest_osr_comp_level(), n->comp_level()));
}
// 解锁
OsrList_lock->unlock();
// Get rid of the osr methods for the same bci that have lower levels.
if (TieredCompilation) {
// 查找所有低于nmethod的编译级别的属于同一方法的nmethod实例,将其从osr_nmethods链表上移除
for (int l = CompLevel_limited_profile; l < n->comp_level(); l++) {
nmethod *inv = lookup_osr_nmethod(n->method(), n->osr_entry_bci(), l, true);
if (inv != NULL && inv->is_in_use()) {
inv->make_not_entrant();
}
}
}
}
nmethod* osr_nmethods_head() const { return _osr_nmethods_head; };
与add_osr_nmethod相对应的就是remove_osr_nmethod,用于从osr_nmethod链表上移除nmethod,当nmethod被标记成not_entrant或者zombie时,或者执行CodeCache垃圾回收时会调用该方法,其源码说明如下:
void InstanceKlass::remove_osr_nmethod(nmethod* n) {
// 获取锁
OsrList_lock->lock_without_safepoint_check();
// 校验是否栈上替换方法
assert(n->is_osr_method(), "wrong kind of nmethod");
nmethod* last = NULL;
// 获取osr_nmethods链表的头元素
nmethod* cur = osr_nmethods_head();
int max_level = CompLevel_none; // Find the max comp level excluding n
Method* m = n->method();
// 遍历osr_nmethods链表直到遇到n,找到n所属的方法的所有nmehtod的最高编译级别
while(cur != NULL && cur != n) {
if (TieredCompilation && m == cur->method()) {
// Find max level before n
max_level = MAX2(max_level, cur->comp_level());
}
last = cur;
cur = cur->osr_link();
}
nmethod* next = NULL;
// 如果从链表中找到了目标nmethod
if (cur == n) {
// 将目标nmethod从链表中移除
next = cur->osr_link();
if (last == NULL) {
// Remove first element
set_osr_nmethods_head(next);
} else {
last->set_osr_link(next);
}
}
n->set_osr_link(NULL);
if (TieredCompilation) {
cur = next;
// 遍历链表,更新最大编译级别
while (cur != NULL) {
// Find max level after n
if (m == cur->method()) {
max_level = MAX2(max_level, cur->comp_level());
}
cur = cur->osr_link();
}
m->set_highest_osr_comp_level(max_level);
}
// Remember to unlock again
OsrList_lock->unlock();
}
参考文章:
(1)HotSpot中执行引擎技术详解(四)——hotspot探测
(2)下载The Java HotSpot Server Compiler论文
(4)[讨论] [HotSpot VM] JIT编译以及执行native code的流程
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/2675.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
