欢迎访问我的GitHub
https://github.com/zq2599/blog_demos
内容:所有原创文章分类汇总及配套源码,涉及Java、Docker、Kubernetes、DevOPS等;
关于Flink SQL Client
Flink Table & SQL的API实现了通过SQL语言处理实时技术算业务,但还是要编写部分Java代码(或Scala),并且还要编译构建才能提交到Flink运行环境,这对于不熟悉Java或Scala的开发者就略有些不友好了;
SQL Client的目标就是解决上述问题(官方原话with a build tool before being submitted to a cluster.)
局限性
遗憾的是,在Flink-1.10.0版本中,SQL Client只是个Beta版本(不适合用于生产环境),并且只能连接到本地Flink,不能像mysql、cassandra等客户端工具那样远程连接server,这些在将来的版本会解决:

环境信息
接下来采用实战的方式对Flink SQL Client做初步尝试,环境信息如下:
- 电脑:MacBook Pro2018 13寸,macOS Catalina 10.15.3
- Flink:1.10.0
- JDK:1.8.0_211
本地启动flink
- 下载flink包,地址:http://ftp.kddilabs.jp/infosystems/apache/flink/flink-1.10.0/flink-1.10.0-bin-scala_2.11.tgz
- 解压:tar -zxvf flink-1.10.0-bin-scala_2.11.tgz
- 进目录flink-1.10.0/bin/,执行命令./start-cluster.sh启动本地flink;
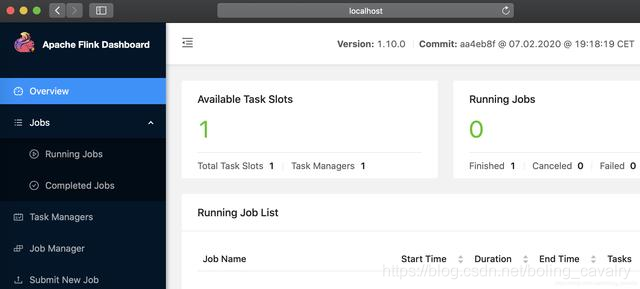
- 访问该机器的8081端口,可见本地flink启动成功:
启动SQL Client CLI
-
在目录flink-1.10.0/bin/执行./sql-client.sh即可启动SQL Client CLI,如下图所示,红框中的BETA提醒着在生产环境如果要用此工具:

-
第一个要掌握的是HELP命令:
-
从hello world开始把,执行命令select ‘Hello world!’;,控制台输出如下图所示,输入Q可退出:
两种展示模式
- 第一种是table mode,效果像是对普通数据表的查询,设置该模式的命令:
SET execution.result-mode=table;
- 第二种是changelog mode,效果像是打印每一次数据变更的日志,设置该模式的命令:
SET execution.result-mode=changelog;
- 设置table mode后,执行以下命令作一次简单的分组查询:
SELECT name,
COUNT(*) AS cnt
FROM (VALUES ('Bob'), ('Alice'), ('Greg'), ('Bob'))
AS NameTable(name)
GROUP BY name;
-
为了便于对比,下图同时贴上两种模式的查询结果,注意绿框中显示了该行记录是增加还是删除:
-
不论是哪种模式,查询结构都保存在SQL Client CLI进程的堆内存中;
-
在chenglog模式下,为了保证控制台可以正常输入输出,查询结果只展示最近1000条;
-
table模式下,可以翻页查询更多结果,结果数量受配置项max-table-result-rows以及可用堆内存限制;
进一步体验
前面写了几行SQL,对Flink SQL Client有了最基本的感受,接下来做进一步的体验,内容如下:
- 创建CSV文件,这是个最简单的图书信息表,只有三个字段:名字、数量、类目,一共十条记录;
- 创建SQL Client用到的环境配置文件,该文件描述了数据源以及对应的表的信息;
- 启动SQL Client,执行SQL查询上述CSV文件;
- 整个操作步骤如下图所示:
操作
- 首先请确保Flink已经启动;
- 创建名为book-store.csv的文件,内容如下:
name001,1,aaa
name002,2,aaa
name003,3,bbb
name004,4,bbb
name005,5,bbb
name006,6,ccc
name007,7,ccc
name008,8,ccc
name009,9,ccc
name010,10,ccc
- 在flink-1.10.0/conf目录下创建名为book-store.yaml的文件,内容如下:
tables:
- name: BookStore
type: source-table
update-mode: append
connector:
type: filesystem
path: "/Users/zhaoqin/temp/202004/26/book-store.csv"
format:
type: csv
fields:
- name: BookName
type: VARCHAR
- name: BookAmount
type: INT
- name: BookCatalog
type: VARCHAR
line-delimiter: "\n"
comment-prefix: ","
schema:
- name: BookName
type: VARCHAR
- name: BookAmount
type: INT
- name: BookCatalog
type: VARCHAR
- name: MyBookView
type: view
query: "SELECT BookCatalog, SUM(BookAmount) AS Amount FROM BookStore GROUP BY BookCatalog"
execution:
planner: blink # optional: either 'blink' (default) or 'old'
type: streaming # required: execution mode either 'batch' or 'streaming'
result-mode: table # required: either 'table' or 'changelog'
max-table-result-rows: 1000000 # optional: maximum number of maintained rows in
# 'table' mode (1000000 by default, smaller 1 means unlimited)
time-characteristic: event-time # optional: 'processing-time' or 'event-time' (default)
parallelism: 1 # optional: Flink's parallelism (1 by default)
periodic-watermarks-interval: 200 # optional: interval for periodic watermarks (200 ms by default)
max-parallelism: 16 # optional: Flink's maximum parallelism (128 by default)
min-idle-state-retention: 0 # optional: table program's minimum idle state time
max-idle-state-retention: 0 # optional: table program's maximum idle state time
# (default database of the current catalog by default)
restart-strategy: # optional: restart strategy
type: fallback # "fallback" to global restart strategy by default
# Configuration options for adjusting and tuning table programs.
# A full list of options and their default values can be found
# on the dedicated "Configuration" page.
configuration:
table.optimizer.join-reorder-enabled: true
table.exec.spill-compression.enabled: true
table.exec.spill-compression.block-size: 128kb
# Properties that describe the cluster to which table programs are submitted to.
deployment:
response-timeout: 5000
- 对于book-store.yaml文件,有以下几处需要注意:
a. tables.type等于source-table,表明这是数据源的配置信息;
b. tables.connector描述了详细的数据源信息,path是book-store.csv文件的完整路径;
c. tables.format描述了文件内容;
d. tables.schema描述了数据源表的表结构;
e. type为view表示MyBookView是个视图(参考数据库的视图概念);
- 在flink-1.10.0目录执行以下命令,即可启动SQL Client,并指定book-store.yaml为环境配置:
bin/sql-client.sh embedded -d conf/book-store.yaml
- 查全表:
SELECT * FROM BookStore;
- 按照BookCatalog分组统计记录数:
SELECT BookCatalog, COUNT(*) AS BookCount FROM BookStore GROUP BY BookCatalog;
- 查询视图:
select * from MyBookView;
至此,Flink SQL Client的初次体验就完成了,咱们此工具算是有了基本了解,接下来的文章会进一步使用Flink SQL Client做些复杂的操作;
欢迎关注公众号:程序员欣宸
微信搜索「程序员欣宸」,我是欣宸,期待与您一同畅游Java世界…
https://github.com/zq2599/blog_demos
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/2628.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...