欢迎访问我的GitHub
https://github.com/zq2599/blog_demos
内容:所有原创文章分类汇总及配套源码,涉及Java、Docker、Kubernetes、DevOPS等;
在学习和开发flink的过程中,经常需要准备数据集用来验证我们的程序,阿里云天池公开数据集中有一份淘宝用户行为数据集,稍作处理后即可用于flink学习;
下载
-
下载地址:
https://tianchi.aliyun.com/dataset/dataDetail?spm=a2c4e.11153940.0.0.671a1345nJ9dRR&dataId=649 -
如下图所示,点击红框中的图标下载(名为UserBehavior.csv.zip的文件太大无法在excel打开,因此下载体积小一些的UserBehavior.csv):
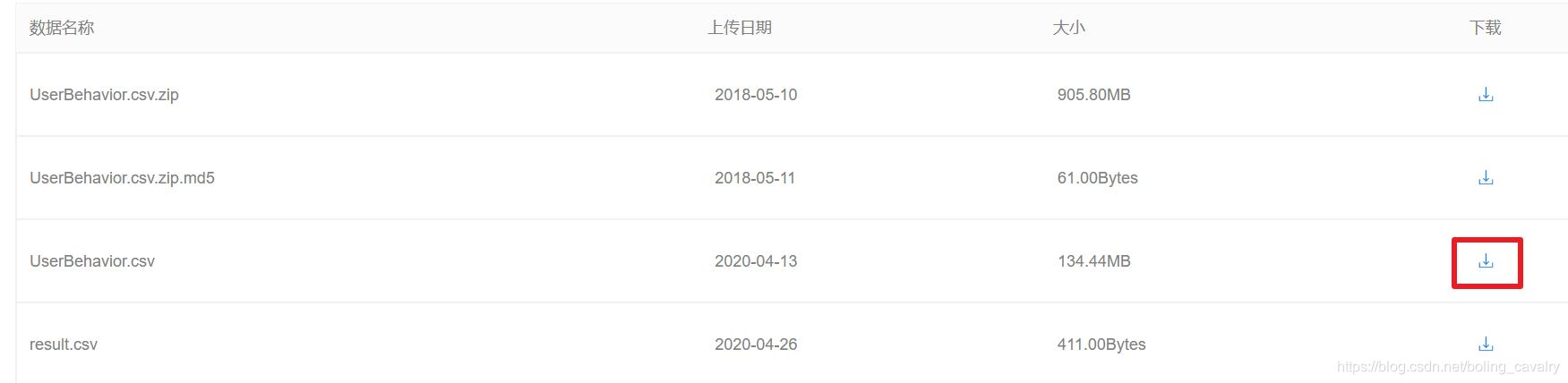

-
该CSV文件的内容,一共有五列,每列的含义如下表:
| 列名称 | 说明 |
|---|---|
| 用户ID | 整数类型,序列化后的用户ID |
| 商品ID | 整数类型,序列化后的商品ID |
| 商品类目ID | 整数类型,序列化后的商品所属类目ID |
| 行为类型 | 字符串,枚举类型,包括(‘pv’, ‘buy’, ‘cart’, ‘fav’) |
| 时间戳 | 行为发生的时间戳 |
| 时间字符串 | 根据时间戳字段生成的时间字符串 |
- 下载完毕后用excel打开,如下图所示:
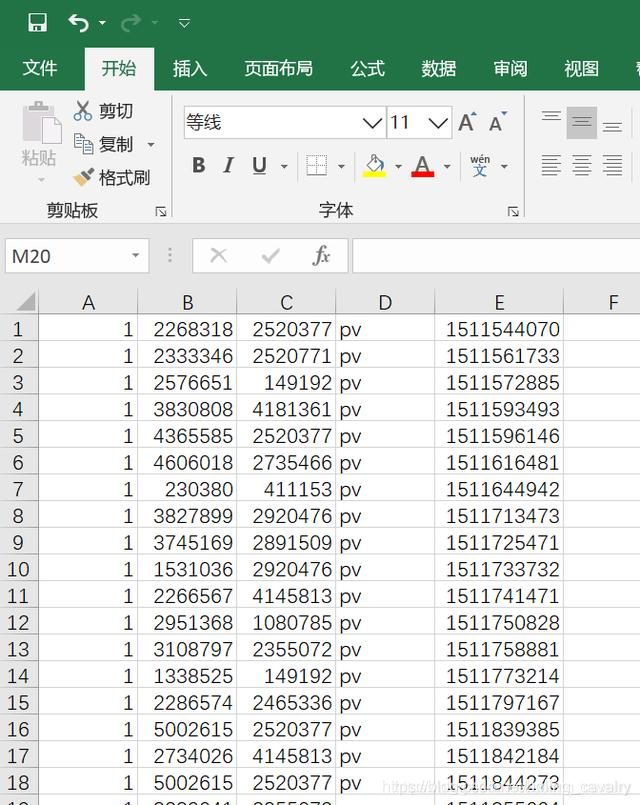
增加一个字段
为了便于检查数据,接下来在时间戳字段之后新增一个字段,内容是将该行的时间戳转成时间字符串
- 如下图,在F列的第一行位置输入表达式,将E1的时间戳转成字符串:
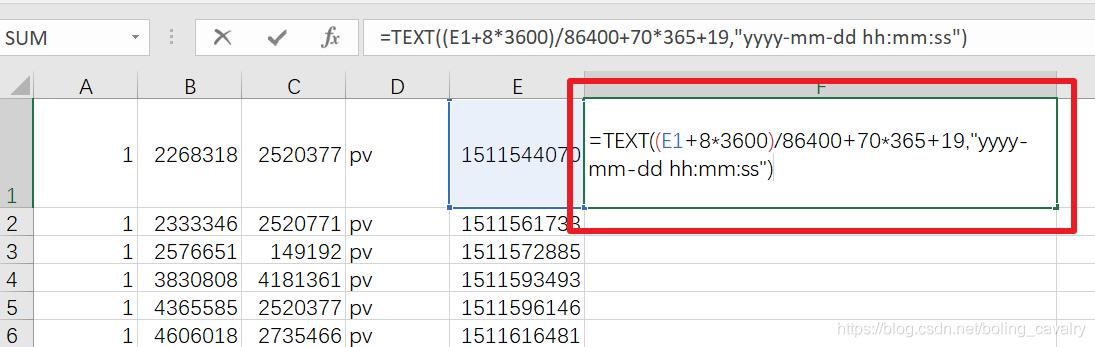
- 上图红框中的表达式内容如下:
=TEXT((E1+8*3600)/86400+70*365+19,"yyyy-mm-dd hh:mm:ss")
- !!!有个问题要格外注意!!!:上述表达式中,由于8*3600的作用,得到的时间字符串实际上是东八区时区的时间,在flink sql中,如果用DATE_FORMAT函数计算timestamp也能得到时间字符串,但是这个字符串是格林尼治时区,此时两个时间字符串的值就不同了,例如从F列看2017/11/12和2017/11/13各一条记录,但是DATE_FORMAT函数计算timestamp得到的却是2017/11/12有两条记录,解决这个问题的办法就是将表达式中的8*3600去掉,大家都用格林尼治时区;
- 表达式生效后,F1的内容就是E1的时间字符串,接下来F列的所有记录都作转换,鼠标放在下图红框位置时,会出现十字架标志,在此标志上双击鼠标:
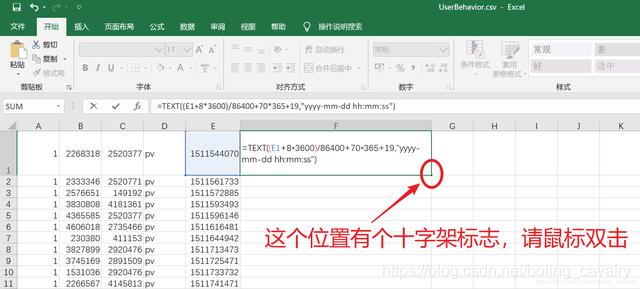
5. 完成后如下图,F列的时间信息更利于我们开发过程中核对数据:
修复乱序
- 此时的CSV文件中的数据并不是按时间字段排序的,如下图:
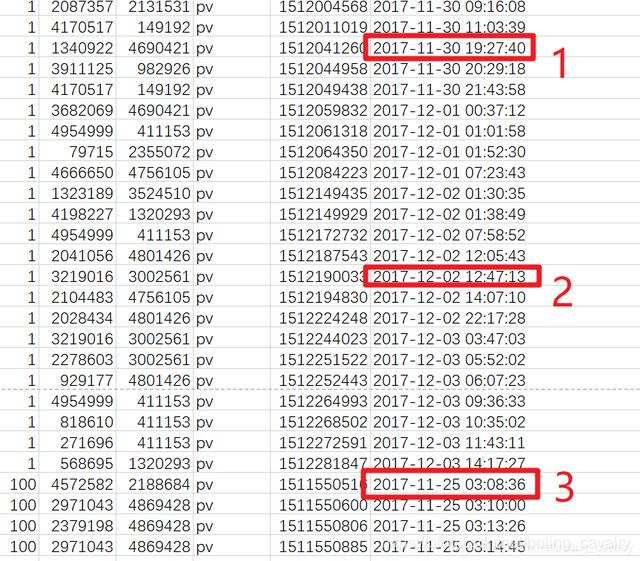
- flink在处理上述数据时,由于乱序问题可能会导致计算结果不准,以上图为例,在处理红框2中的数据时,红框3所对应的窗口早就完成计算了,虽然flink的watermark可以容忍一定程度的乱序,但是必须将容忍时间调整为7天才能将红框3的窗口保留下来不触发,这样的watermark调整会导致大量数据无法计算,因此,需要将此CSV的数据按照时间排序再拿来使用;
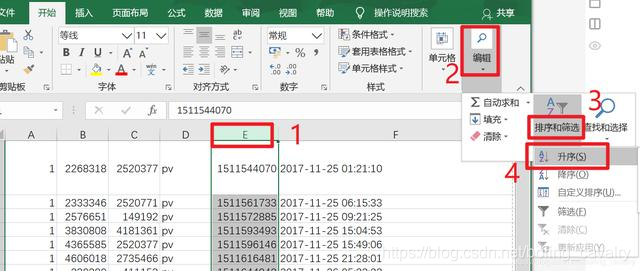
- 如下图操作即可完成排序:
4. 完成排序后如下图所示:
至此,一份淘宝用户行为数据集就准备完毕了,接下来的文章将会用此数据进行flink相关的实战;
直接下载准备好的数据
- 为了便于您快速使用,上述调整过的CSV文件我已经上传到CSDN,地址:
https://download.csdn.net/download/boling_cavalry/12381698 - 也可以在我的Github下载,地址:
https://raw.githubusercontent.com/zq2599/blog_demos/master/files/UserBehavior.7z
欢迎关注公众号:程序员欣宸
微信搜索「程序员欣宸」,我是欣宸,期待与您一同畅游Java世界…
https://github.com/zq2599/blog_demos
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/2627.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
