在大数据时代,任何公司的成功都取决于数据驱动的决策和业务流程。在这种情况下,数据集成对于任何业务的成功秘诀都是至关重要的,并且掌握诸如Informatica Powercenter 9.X之类的端到端敏捷数据集成平台必将使您走上职业发展的快速通道。使用Informatica PowerCenter Designer进行ETL和数据挖掘的职业是前所未有的最佳时机。
Informatica面试问题(基于场景):
1.区分源限定符和过滤器转换吗?
| 源限定符转换 | 滤镜转换 |
|---|---|
| 1.在从源读取数据时,它过滤行。 | 1.它从映射数据中筛选行。 |
| 2.只能过滤来自关系源的行。 | 2.可以过滤任何类型的源系统中的行。 |
| 3.它限制了从源中提取的行集。 | 3.它限制了发送到目标的行集。 |
| 4.通过最小化映射中使用的行数来提高性能。 | 4.它被添加到源附近,以尽早过滤掉不需要的数据并最大化性能。 |
| 5.在这种情况下,过滤条件使用标准SQL在数据库中执行。 | 5.它使用任何语句或转换函数定义条件以获取TRUE或FALSE。 |
2.如何删除Informatica中的重复记录?有多少种方法可以做到?
有几种删除重复项的方法。
- 如果源是DBMS,则可以使用Source Qualifier中的属性来选择不同的记录。
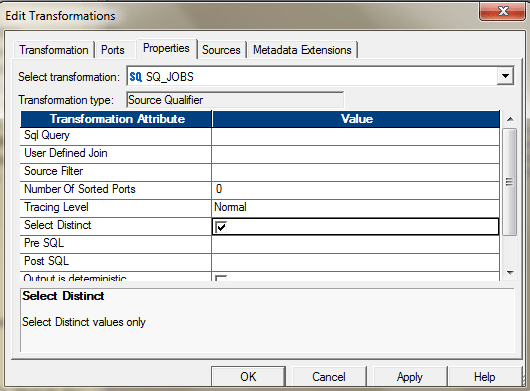
 或者,您也可以使用SQL Override执行相同的操作。
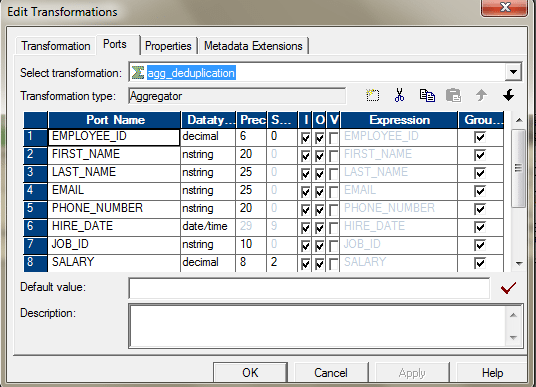
或者,您也可以使用SQL Override执行相同的操作。 - 您可以使用Aggregator并选择所有端口作为键来获取不同的值。将所有必需的端口传递到聚合器后,选择所有那些端口,您需要选择这些端口以进行重复数据删除。如果要基于整个列查找重复项,请按键将所有端口选择为分组。
 映射将如下所示。
映射将如下所示。 - 您可以使用Sorter并使用Sort Distinct属性来获得不同的值。通过以下方式配置分类器以启用此功能。
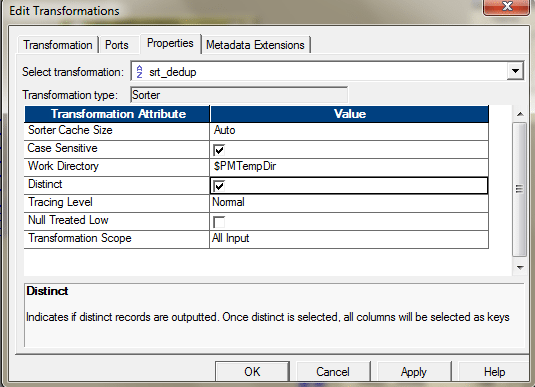
- 如果对数据进行了排序,则可以使用“表达式”和“过滤器”转换来识别和删除重复项。如果您的数据未排序,则可以首先使用排序器对数据进行排序,然后应用以下逻辑:
- 将源代码带到Mapping设计器中。
- 假设数据未排序。我们正在使用分类器对数据进行分类。排序的关键字为Employee_ID。
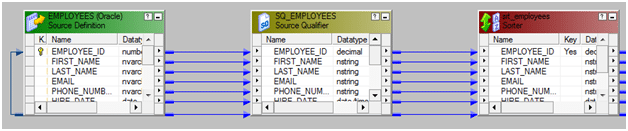 如下所述配置分拣器。
如下所述配置分拣器。 - 使用一个表达式转换来标记重复项。我们将使用可变端口根据Employee_ID识别重复的条目。
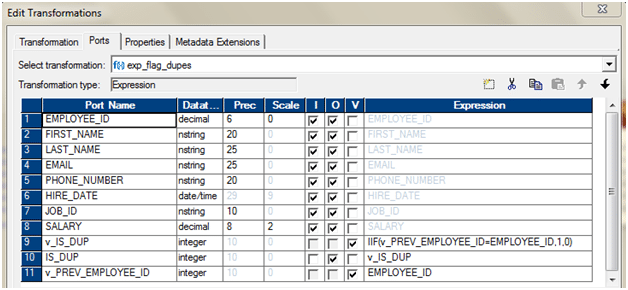
- 使用过滤器转换,只传递IS_DUP =0。从上一个表达式转换开始,我们将IS_DUP = 0附加到唯一的记录上,这是唯一的。如果IS_DUP> 0,则表示这些是重复条目。
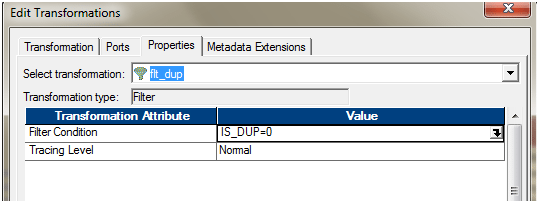
- 将端口添加到目标。整个映射应如下所示。

5。当您将Lookup转换的属性更改为使用动态高速缓存时,新端口将添加到转换中。NewLookupRow。
动态缓存可以在读取数据时更新缓存。
如果源中有重复的记录,则还可以使用动态查找缓存,然后使用路由器仅选择不同的记录。
3. Source Qualifier和Joiner Transformation之间有什么区别?
Source Qualifier可以联接来自同一源数据库的数据。通过将源链接到一个Source Qualifier转换,我们可以将两个或多个具有主键-外键关系的表连接起来。
如果我们需要加入中间流或源是异构的,那么我们将必须使用Joiner转换来加入数据。
4.区分连接器和查找转换。
下面是查找和联接转换之间的区别:
- 在查找中,我们可以覆盖查询,但在连接器中,不能。
- 在查找中,我们可以提供不同类型的运算符,例如–“>,<,> =,<=,!=”,但在连接器中仅提供“ =”(等于)运算符。
- 在查找中,我们可以使用查找覆盖来限制在读取关系表时的行数,但是在联接器中,我们不能在读取时限制行数。
- 在Joiner中,我们可以基于-Normal Join,Master Outer,Detail Outer和Full Outer Join联接表,但是在查找中,此功能不可用。Lookup的行为类似于数据库的Left Outer Join。
5.查找转换是什么意思?解释查找转换的类型。
映射中的查找转换用于在平面文件,关系表,视图或同义词中查找数据。我们还可以从源限定符创建查找定义。
我们具有以下类型的查找。
- 关系或平面文件查找。在平面文件或关系表上执行查找。
- 管道查找。在应用程序源(例如JMS或MSMQ)上执行查找。
- 连接或未连接的查找。
- 连接的Lookup转换接收源数据,执行查找,然后将数据返回到管道。
- 未连接的Lookup转换未连接到源或目标。管道中的转换使用以下命令调用Lookup转换:LKP表达式。未连接的Lookup转换将一列返回到调用转换。
- 缓存或非缓存查找。我们可以配置查找转换以缓存查找数据,或在每次调用查找时直接查询查找源。如果“查找”源是“平面文件”,则始终会缓存查找。
6.如何提高木匠转换的性能?
下面是改善Joiner Transformation性能的方法。
- 尽可能在数据库中执行联接。 在某些情况下,这是不可能的,例如从两个不同的数据库或平面文件系统联接表。要在数据库中执行联接,我们可以使用以下选项: 创建并使用会话前存储过程来联接数据库中的表。 使用Source Qualifier转换执行联接。
- 尽可能合并排序的数据
- 对于未排序的Joiner转换,将行较少的源指定为主源。
- 对于排序的Joiner转换,将重复键值较少的源指定为主源。
7.查找中的缓存类型是什么?
基于在查找转换/会话属性级别完成的配置,我们可以具有以下类型的查找缓存。
- 未缓存的查询–在这里,查询转换不会创建缓存。对于每条记录,它会转到查找源,执行查找并返回值。因此,对于10K行,它将使用Lookup源10K次以获取相关值。
- 缓存的查找–为了减少与查找源和Informatica Server的来回通信,我们可以配置查找转换以创建缓存。这样,就可以缓存来自“查找源”的全部数据,并根据“高速缓存”执行所有查找。
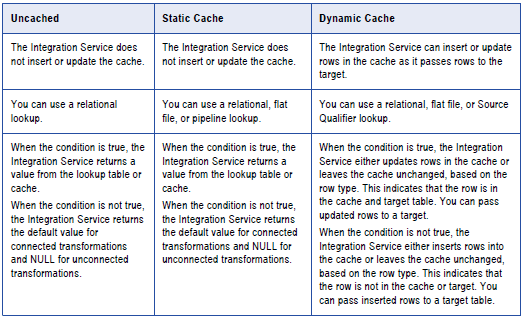
根据配置的缓存的类型,我们可以有两种类型的缓存:静态和动态。
集成服务根据所配置的查找缓存的类型执行不同的操作。下表将Lookup转换与未缓存的查找,静态缓存和动态缓存进行了比较:
永久缓存
默认情况下,在成功完成各个会话后,将删除查找缓存,但是我们可以配置为保留缓存,以备下次使用。
共享缓存
我们可以在多个转换之间共享查找缓存。我们可以在同一映射中的转换之间共享未命名的缓存。我们可以在相同或不同映射的转换之间共享命名的缓存。
8.如何使用或不使用更新策略来更新记录?
我们可以使用会话配置来更新记录。我们可以有几个选项来处理数据库操作,例如插入,更新,删除。
在会话配置过程中,可以使用会话的“属性”选项卡中的“将源行视为”设置为所有行选择一个数据库操作。
- 插入:–将所有行都视为插入。
- 删除:–将所有行都视为删除。
- 更新:–将所有行都视为更新。
- 数据驱动: -Integration Service遵循更新策略标志行中编码的说明,以进行插入,删除,更新或拒绝。
一旦确定了如何处理会话中的所有行,我们还可以为单个行设置选项,从而对每个行的行为提供额外的控制。我们需要在会话属性的“映射”选项卡上的“转换”视图中定义这些选项。
- 插入:–选择此选项可在目标表中插入一行。
- 删除:–选择此选项可从表中删除行。
- 更新:-在这种情况下,您有以下选择:
- 作为更新进行更新:–如果目标表中存在每行,则更新标记为要更新的行。
- 作为插入更新:–插入标记为更新的每一行。
- 更新else插入:–更新该行(如果存在)。否则,将其插入。
- 截断表:–选择此选项可在装入数据之前截断目标表。
脚步:
- 设计映射就像“仅插入”映射一样,没有查找,更新策略转换。
- 首先设置“将源行视为”属性,如下图所示。
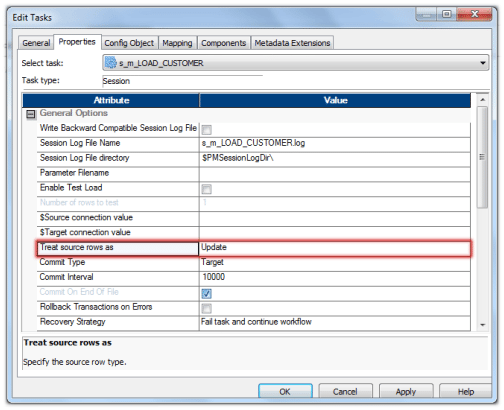
- 接下来,如下所示设置目标表的属性。选择属性插入和更新,否则插入。
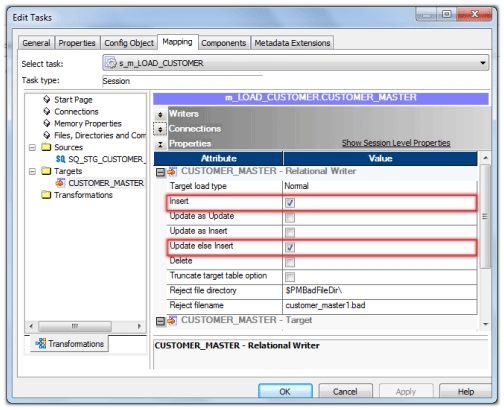
这些选项将使会话成为“更新”和“插入”记录,而无需使用“目标表”中的“更新策略”。
当我们需要用很少的记录和更少的插入来更新一个巨大的表时,我们可以使用此解决方案来提高会话性能。
此类情况的解决方案是不使用“查找转换和更新策略”来插入和更新记录。
随着查找表大小的增加,查找转换的性能可能不会更好,并且还会降低性能。
9.为什么更新策略和联合转换处于活动状态?举例说明。
- 更新策略更改行类型。它可以基于为评估行而创建的表达式来分配行类型。类似于IIF(ISNULL(CUST_DIM_KEY),DD_INSERT,DD_UPDATE)。此表达式将行类型更改为CUST_DIM_KEY为NULL的“插入”和CUST_DIM_KEY不为null的“更新”。
- 更新策略可以拒绝行。通过适当的配置,我们还可以过滤掉一些行。因此,有时输入行的数量可能不等于输出行的数量。
就像IIF(IISNULL(CUST_DIM_KEY),DD_INSERT,
IIF(SRC_CUST_ID!= TGT_CUST_ID),DD_UPDATE,DD_REJECT))
在这里,我们正在检查CUST_DIM_KEY是否不为null,然后SRC_CUST_ID是否等于TGT_CUST_ID。如果它们相等,则对这些行不执行任何操作;他们被拒绝了。
联合转型
在联合转换中,尽管进入联合的行总数与从联合中通过的行总数相同,但是行的位置没有保留,即输入流1中的行号1可能不是行号在输出流中为1。Union甚至不保证输出是可重复的。因此,这是一个积极的转变。
10.如何仅将空记录加载到目标中?通过映射流程进行解释。
让我们说,这是我们的来源
| Cust_id | 客户名称 | 客户数量 | Cust_Place | Cust_zip |
|---|---|---|---|---|
| 101 | 广告 | 160 | 吉隆坡 | 700098 |
| 102 | BG | 170 | J | 560078 |
| 空值 | 空值 | 180 | H | 780098 |
目标结构也相同,但是,我们有两个表,一个表将包含NULL记录,另一个表将包含非NULL记录。
我们可以如下所述设计映射。
SQ –> EXP –> RTR –> TGT_NULL / TGT_NOT_NULL EXP –表达式转换创建输出端口
O_FLAG = IIF((ISNULL(cust_id)或ISNULL(cust_name)或ISNULL(cust_amount)或ISNULL(cust_zip)或ISNULL(cust_zip)),’NULL’,’NNULL’)*\假设您需要重定向的值是null***
要么
O_FLAG = IIF((ISNULL(cust_name)AND ISNULL(cust_no)AND ISNULL(cust_amount)AND ISNULL(cust_place)AND ISNULL(cust_zip)),’NULL’,’NNULL’)*\假设您需要重定向以防万一的值是null***
RTR –路由器转换两组
组1连接到TGT_NULL(表达式O_FLAG =’NULL’) 组2连接到TGT_NOT_NULL(表达式O_FLAG =’NNULL’)
11.如何通过映射流将备用记录加载到不同的表中?
想法是在记录中添加一个序列号,然后将记录号除以2。如果该数是可分割的,则将其移至一个目标,如果不是,则将其移至另一个目标。
- 拖动源并连接到表达式转换。
- 将序列生成器的下一个值添加到表达式转换中。
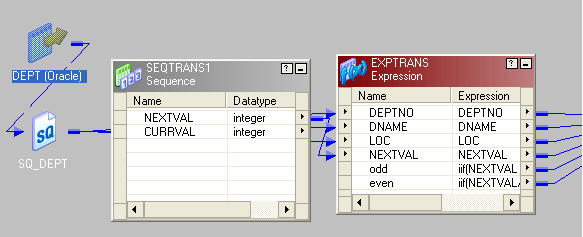
- 在表达式转换中,有两个端口,一个是“奇数”,另一个是“偶数”。
- 编写如下表达式
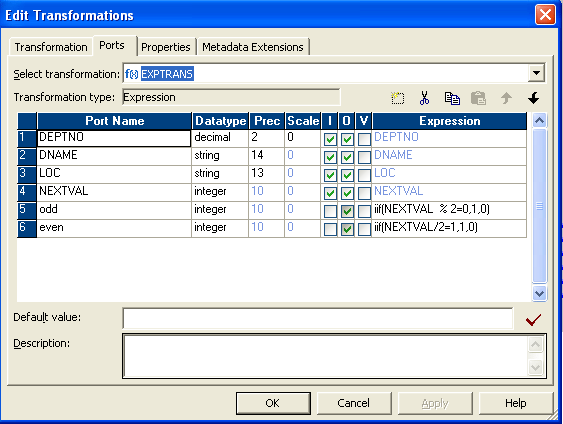
- 将路由器转换连接到表达式。
- 在路由器中制作两个组。
- 给条件如下
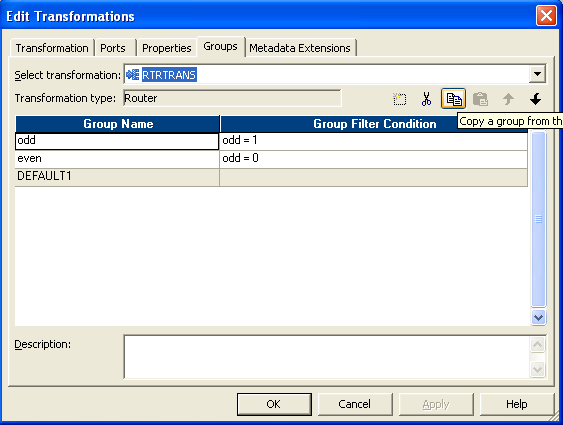
- 然后将两组发送到不同的目标。这就是整个流程。
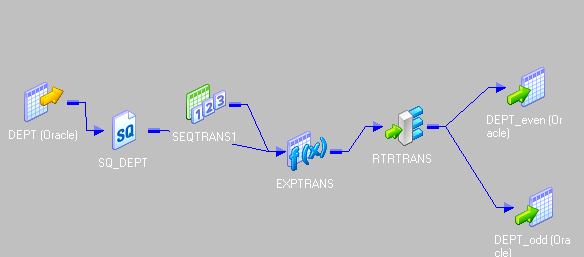
12.如何将第一条记录和最后一条记录加载到目标表中?有多少种方法可以做到?通过映射流程进行解释。
其背后的想法是向记录添加序列号,然后从记录中获取前1名和后1名。
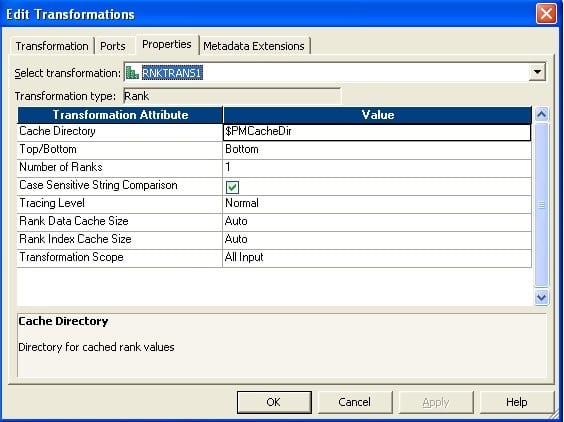
- 将端口从源限定符拖放到两个秩转换。
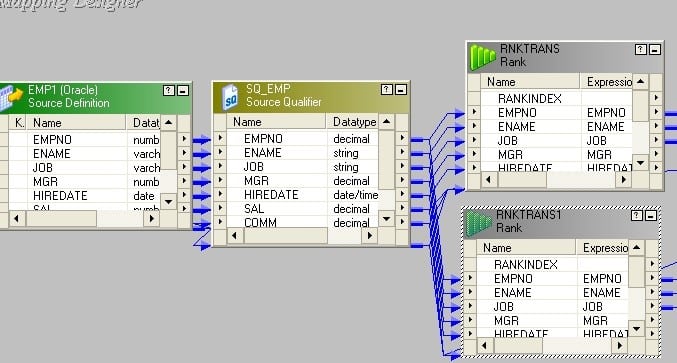
- 创建一个具有起始值1的可重用序列生成器,并将下一个值连接到两个秩转换。
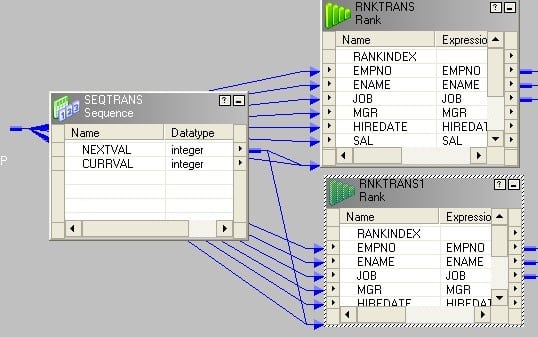
- 如下设置等级属性。新添加的序列端口应选择为等级端口。无需选择任何端口作为“按端口分组” – 1
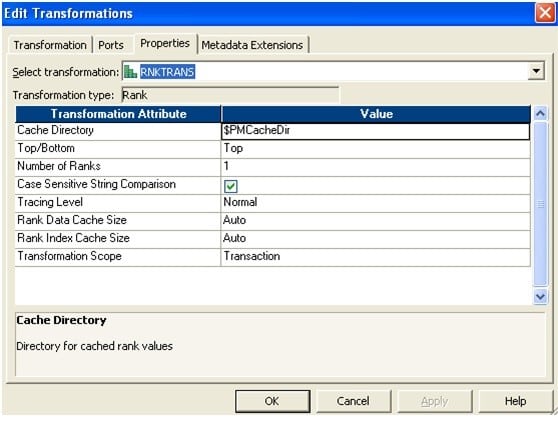
- 等级– 2
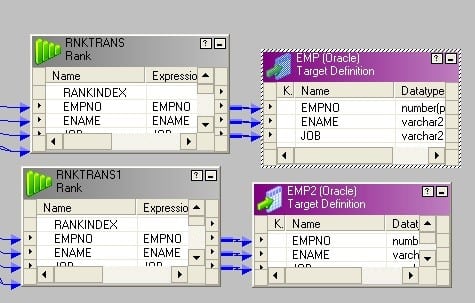
- 制作目标的两个实例。 将输出端口连接到目标。
13.我在源表中有100条记录,但是我想将1、5、10、15、20…..100加载到目标表中。我怎样才能做到这一点?解释详细的映射流程。
这适用于任何n = 2、3、4、5、6 …对于我们的示例,n =5。我们可以对任何n应用相同的逻辑。
其背后的想法是在记录中添加序列号,然后将序列号除以n(在这种情况下为5)。如果完全可分割,即没有余数,则将它们发送到另一个目标,再将它们发送到另一个目标。
- 在源限定符之后连接一个表达式转换。
- 将序列生成器的下一个值端口添加到表达式转换中。
- 在表达式中创建一个新端口(验证),然后如下图所示编写表达式。
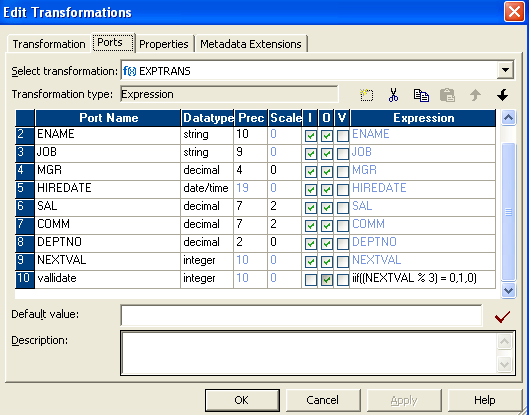
- 将过滤器转换连接到表达式,然后将条件写入属性,如下图所示。
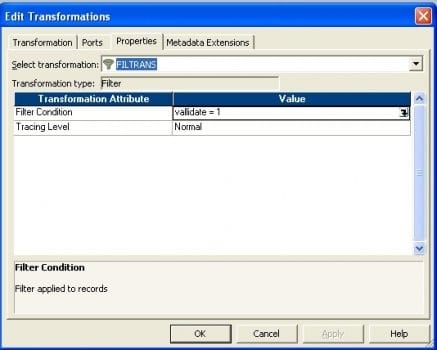
- 最后连接到目标。
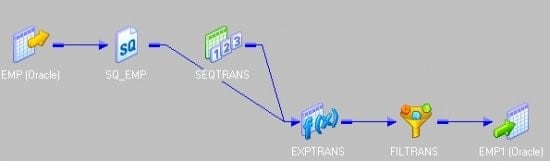
14.如何将唯一记录加载到一个目标表中,并将重复记录加载到另一目标表中?
源表:
| COL1 | COL2 | COL3 |
|---|---|---|
| a | b | c |
| x | y | z |
| a | b | c |
| r | f | u |
| a | b | c |
| v | f | r |
| v | f | r |
目标表1:包含所有唯一行的表
| COL1 | COL2 | COL3 |
|---|---|---|
| a | b | c |
| x | y | z |
| r | f | u |
| v | f | r |
目标表2:包含所有重复行的表
| COL1 | COL2 | COL3 |
|---|---|---|
| a | b | c |
| a | b | c |
| v | f | r |
- 将源拖动到映射,并将其连接到聚合器转换。
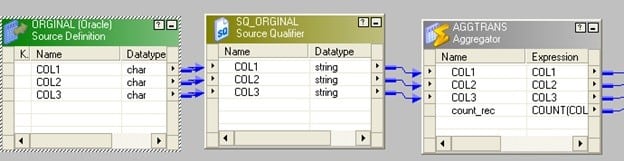
- 在聚合器转换中,按关键字列分组并添加新端口。将其称为count_rec即可对键列进行计数。
- 从上一步将路由器连接到聚合器。在路由器中,分为两组:一组称为“原始”,另一组称为“重复”。 原始写入count_rec = 1,重复写入count_rec> 1。
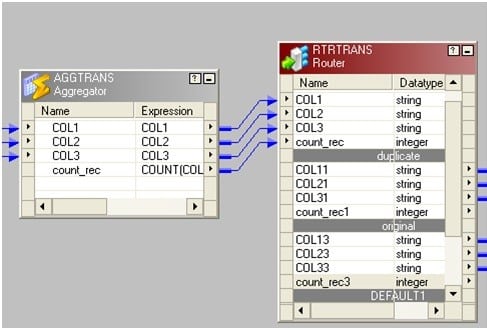 下图描述了组名和过滤条件。 将两个组连接到相应的目标表。
下图描述了组名和过滤条件。 将两个组连接到相应的目标表。
15.区分路由器和过滤器转换吗?

16.我有两个不同的源结构表,但是我想加载到单个目标表中吗?我该怎么办?通过映射流程详细说明。
- 如果要联接数据源,可以使用联接器。使用联接器,并使用匹配列联接表。
- 如果表具有一些公共列,并且我们需要垂直连接数据,那么我们也可以使用Union转换。创建一个并集转换,将来自两个源的匹配端口添加到两个不同的输入组,并将输出组发送到目标。 这里的基本思想是使用Joiner或Union转换将数据从两个源移动到单个目标。根据要求,我们可以决定使用哪个。
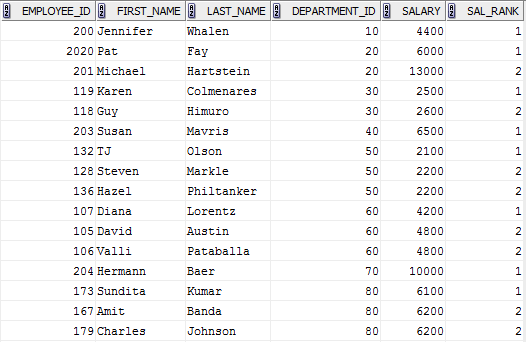
17.如何通过Informatica在每个部门中加载超过1个Max Sal或在oracle中编写sql查询?
SQL查询:
您可以使用这种查询为每个部门获取1个以上的最高工资。
选择*从(
SELECT EMPLOYEE_ID,FIRST_NAME,LAST_NAME,DEPARTMENT_ID,SALARY,RANK()超过(从DEPARTMENT_ID到ORDER BY SALARY的部分)从员工的SAL_RANK
SAL_RANK <= 2
Informatica方法:
我们可以使用Rank转换来实现。
使用Department_ID作为组密钥。
在属性选项卡中,选择顶部,3。
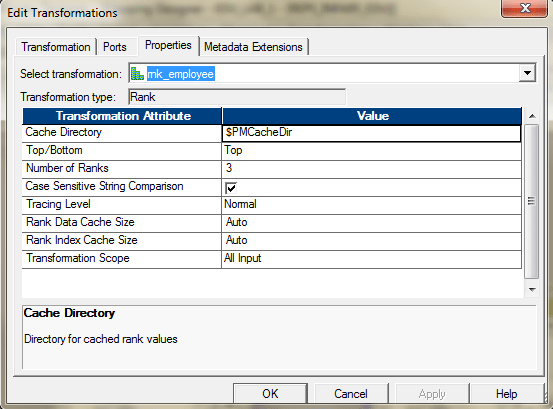
整个映射应如下所示。

这将使我们在各自部门中获得最高薪水的前3名员工。
18.如何将源中的单行转换成目标的三行?
我们可以为此使用Normalizer转换。如果我们不想使用Normalizer,则有一种替代方法。
我们有一个包含3列的源表:Col1,Col2和Col3。表格中只有1行,如下所示:
| Col1 | Col2 | Col3 |
|---|---|---|
| 一种 | b | C |
有一个目标表仅包含1列Col。设计一个映射,以便目标表包含3行,如下所示:
| 上校 |
|---|
| 一种 |
| b |
| C |
- 创建3个表达式转换exp_1,exp_2和exp_3,每个具有1个端口。
- 将col1从Source Qualifier连接到exp_1中的端口。
- 将col2从Source Qualifier连接到exp_2中的端口。
- 将col3从源限定符连接到exp_3中的端口。
- 制作目标的3个实例。将端口从exp_1连接到target_1。
- 将端口从exp_2连接到target_2,并将端口从exp_3连接到target_3。
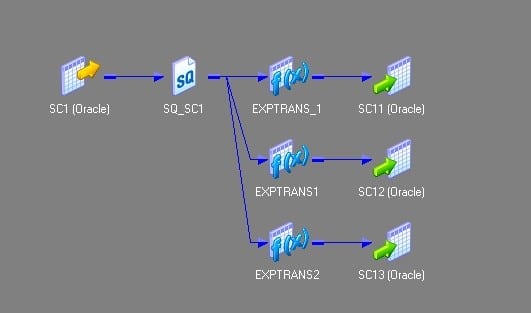
19.我有三个相同的源结构表。但是,我想加载到单个目标表中。我该怎么做呢?通过映射流程详细说明。
我们将不得不在此处使用“联合转换”。联合转换是一个多输入组转换,它只有一个输出组。
- 将所有源拖到映射设计器中。
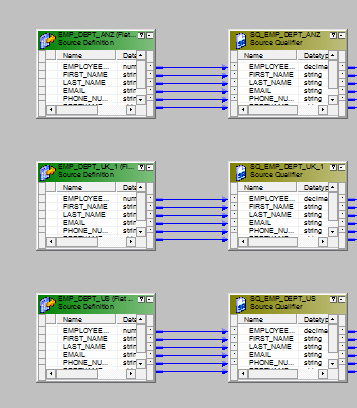
- 添加一个并集转换并按如下配置它。
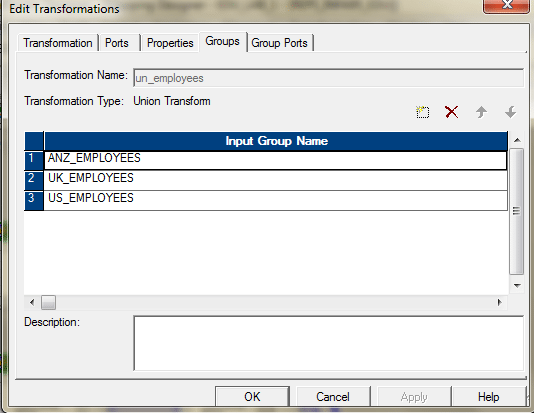 组端口选项卡。
组端口选项卡。 - 将源与并转换的三个输入组连接。
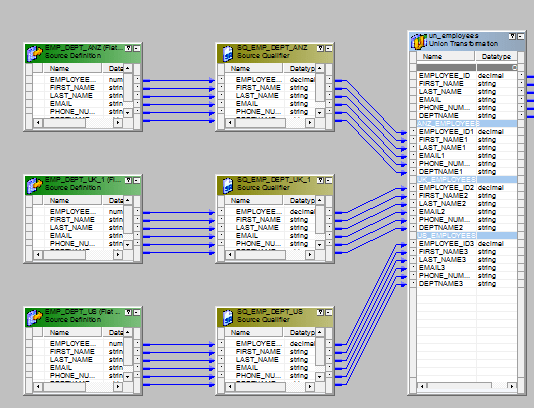
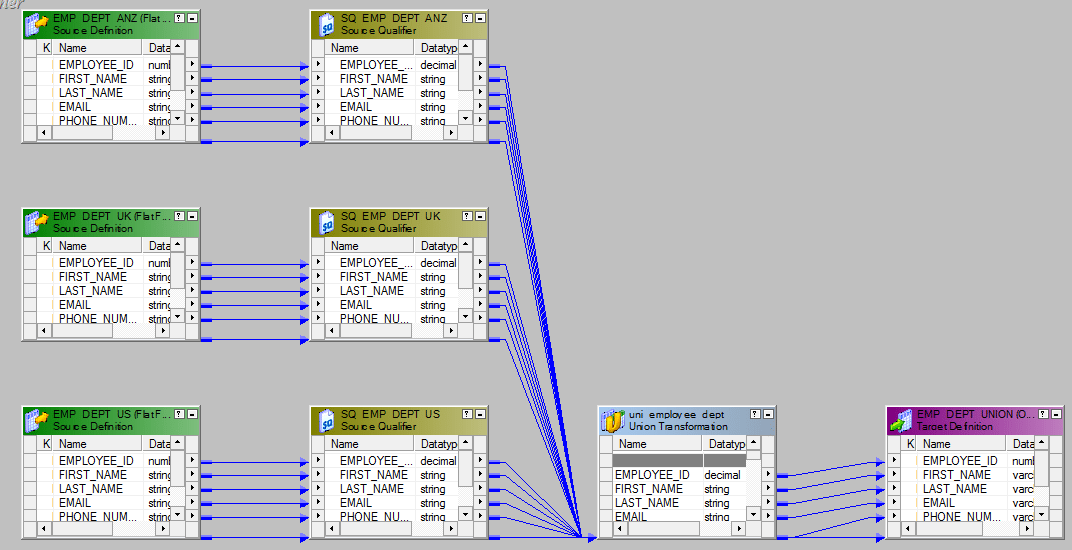
- 将输出发送到目标或通过表达式转换发送到目标。整个映射应如下所示。
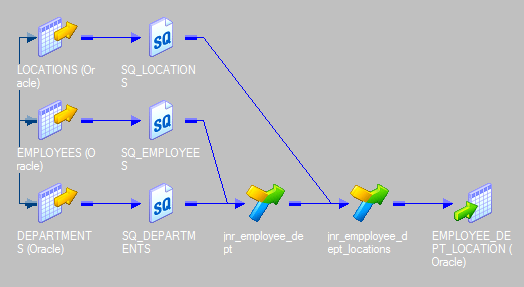
20.如何使用joiner连接三个源?解释映射流程。
我们不能使用单个连接器连接两个以上的源。要联接三个源,我们需要进行两次联接转换。
假设,我们要使用Joiner联接三个表–“员工”,“部门”和“位置”。我们将需要两个连接器。Joiner-1将加入,Employees and Departments和Joiner-2将加入,Joiner-1和Locations表的输出。
步骤如下。
- 将三个源带入映射设计器。
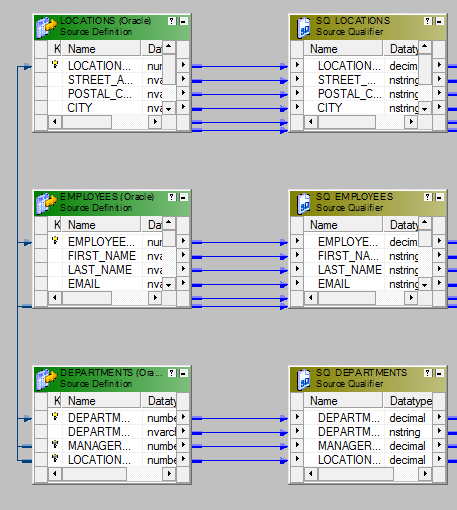
- 创建Joiner -1以使用Department_ID加入员工和部门。
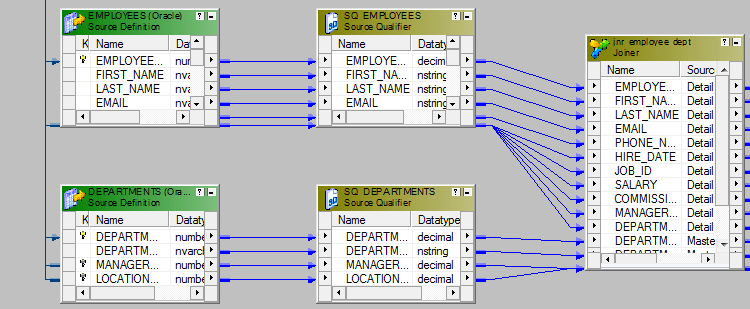
- 创建下一个连接器Joiner-2。从Joiner-1中获取输出,从Locations Table中获取端口,并将它们带到Joiner-2中。使用Location_ID连接这两个数据源。
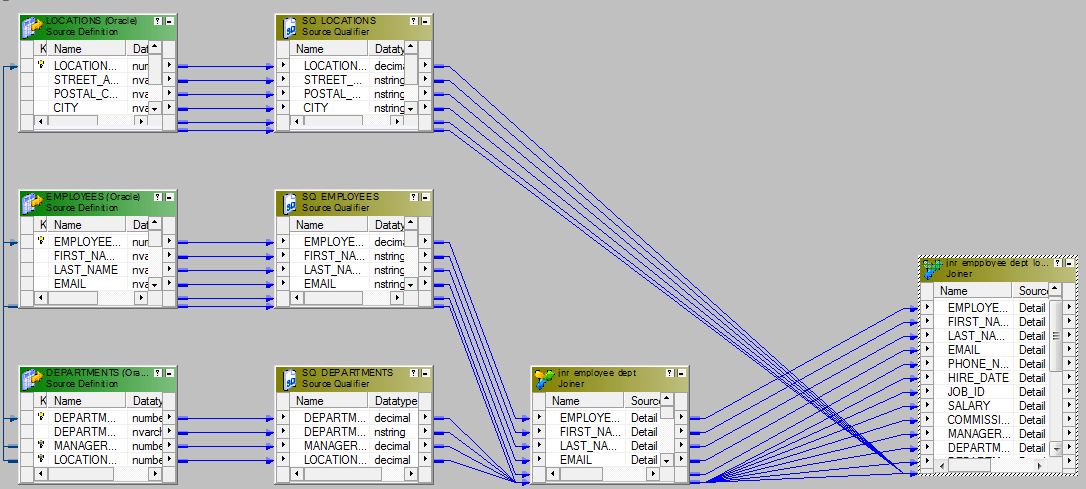
- 最后一步是将所需的端口从Joiner-2发送到目标,或通过表达式转换发送到目标表。
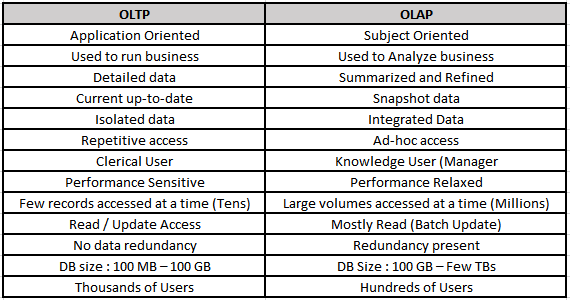
21. OLTP和OLAP有什么区别?
22.数据仓库中的模式有哪些类型,它们之间有什么区别?
存在三种不同的数据模型。
- 星型模式
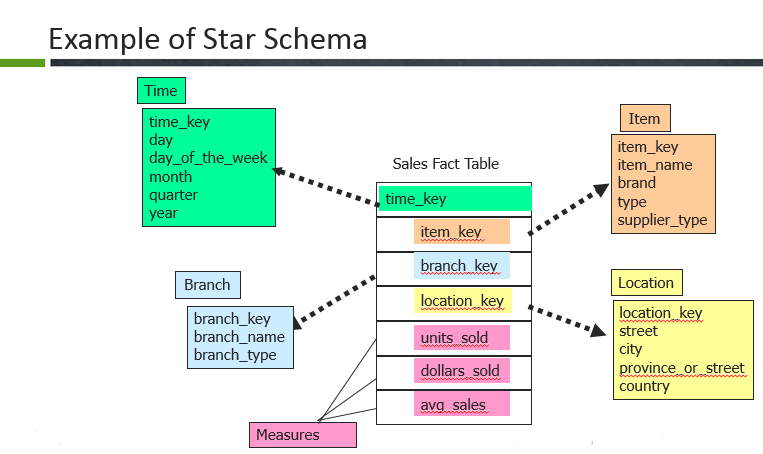 在这里,销售事实表是事实表,每个维表的代理键在这里都是通过外键引用的。示例:时间键,项目键,分支键,位置键。事实表被维表(例如分支,位置,时间和项目)包围。事实表中有维键,例如time_key,item_key,branch_key和location_keys,度量值是untis_sold,已售美元和平均销售额。通常,事实表与维相比包含更多行,因为事实表包含维的所有主键采取自己的措施。
在这里,销售事实表是事实表,每个维表的代理键在这里都是通过外键引用的。示例:时间键,项目键,分支键,位置键。事实表被维表(例如分支,位置,时间和项目)包围。事实表中有维键,例如time_key,item_key,branch_key和location_keys,度量值是untis_sold,已售美元和平均销售额。通常,事实表与维相比包含更多行,因为事实表包含维的所有主键采取自己的措施。 - 雪花模式
 在雪花中,事实表被维表包围,维表也被规范化以形成层次结构。因此,在此示例中,诸如位置,项目之类的维表被进一步规范化为形成层次结构的较小维。
在雪花中,事实表被维表包围,维表也被规范化以形成层次结构。因此,在此示例中,诸如位置,项目之类的维表被进一步规范化为形成层次结构的较小维。 - 事实星座
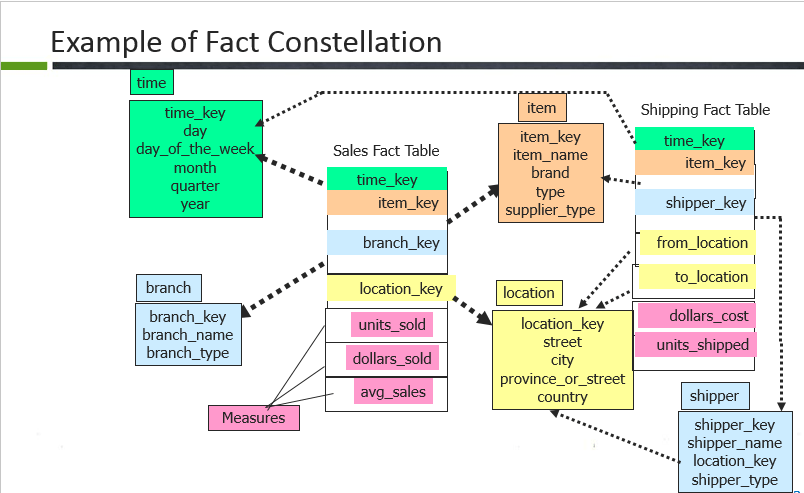 实际上星座中,有许多事实表共享相同的维表。此示例说明了一个事实星座,其中事实表的销售和运输共享维度表的时间,分支,项目。
实际上星座中,有许多事实表共享相同的维表。此示例说明了一个事实星座,其中事实表的销售和运输共享维度表的时间,分支,项目。
23.什么是尺寸表?解释不同的尺寸。
维度表是描述企业业务实体的表,以时间,部门,位置,产品等分层,分类的信息表示。
数据仓库中的维类型
维度表由有关事实的属性组成。维度存储业务的文字描述。没有这些维度,我们就无法衡量事实。尺寸表的不同类型将在下面详细说明。
- 一致的维度: 一致的维度意味着与它们所连接的每个可能的事实表完全相同的事物。 例如:连接到销售事实的日期维度表与连接到库存事实的日期维度相同。
- 垃圾维度: 垃圾维度是与任何特定维度无关的随机交易代码标志和/或文本属性的集合。垃圾维度只是一种结构,可提供方便的位置来存储垃圾属性。 例如:假设我们有性别层面和婚姻状况层面。在事实表中,我们需要维护两个引用这些维度的键。取而代之的是创建一个包含性别和婚姻状况所有组合的垃圾维度(交叉联接性别和婚姻状况表并创建一个垃圾表)。现在,我们只能在事实表中维护一个键。
- 退化维: 退化维是从事实表派生的维,没有自己的维表。 例如:事实表中的交易代码。
- 角色扮演维度: 在同一数据库中经常用于多个目的的维度称为角色扮演维度。例如,日期维度可用于“销售日期”,“交货日期”或“雇用日期”。
24.什么是事实表?解释各种事实。
星型模式中的集中表称为事实表。事实表通常包含两种类型的列。包含度量的列称为事实和列,它们是维表的外键。事实表的主键通常是由维表的外键组成的组合键。
数据仓库中的事实类型
事实表是由业务流程的度量,度量或事实组成的表。这些可测量的事实用于了解业务价值并预测未来业务。下面将详细说明不同类型的事实。
- 可加的事实:可 加的事实是可以通过事实表中的所有维度进行汇总的事实。销售事实是加法事实的一个很好的例子。
- 半 累加事实:半累加事实是可以针对事实表中某些维度进行汇总的事实,而不能对其他事实进行汇总。 例如:每日余额事实可以通过客户维度进行汇总,而不能通过时间维度进行汇总。
- 非可 加事实:非可加事实是不能针对事实表中存在的任何维度进行汇总的事实。 例如:具有百分比和比率的事实。
事实表:
在现实世界中,可能有一个事实表,其中不包含任何度量或事实。这些表称为“事实事实表”。 例如:仅包含产品密钥和日期密钥的事实表是事实。该表中没有度量。但是您仍然可以获得一段时间内出售的产品数量。
包含汇总事实的事实表通常称为摘要表。
25.通过映射详细说明SCD TYPE 1。
SCD Type1映射
SCD Type 1方法论用新数据覆盖了旧数据,因此不需要跟踪历史数据。
- 这是来源。
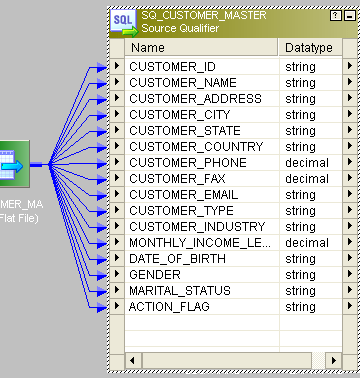
- 我们将根据关键列CUSTOMER_ID比较历史数据。
- 这是整个映射:
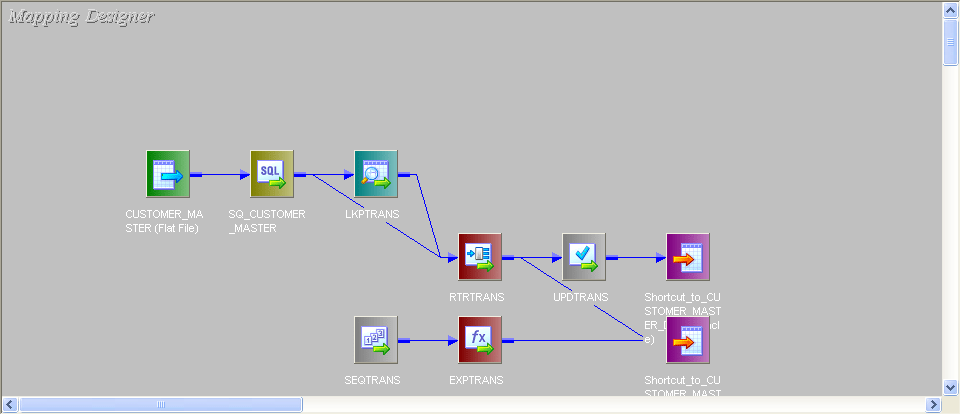
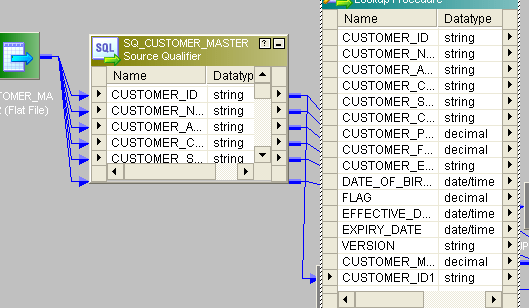
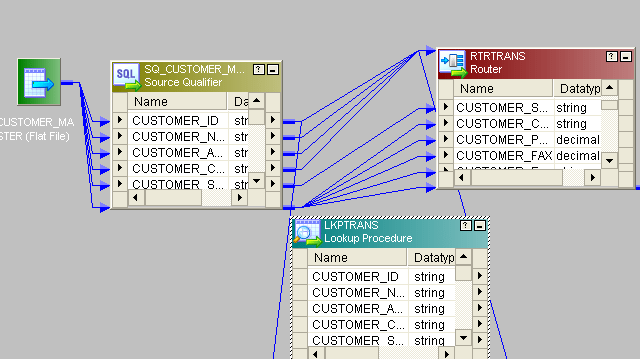
- 将查找连接到源。在“查找”中,从目标表中获取数据,并仅将CUSTOMER_ID端口从源发送到查找。
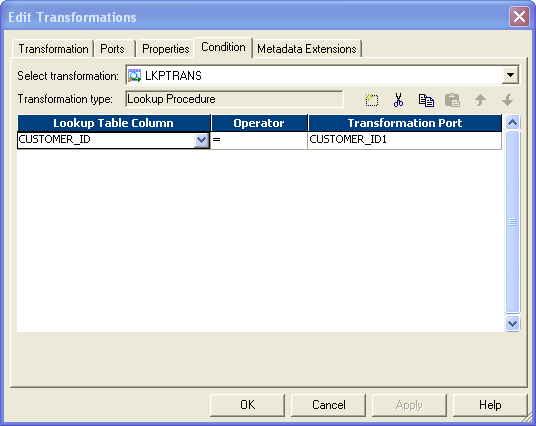
- 给出如下查询条件:
- 然后,将其余的列从源发送到一个路由器转换。
- 在路由器中创建两个组,并给出如下条件:
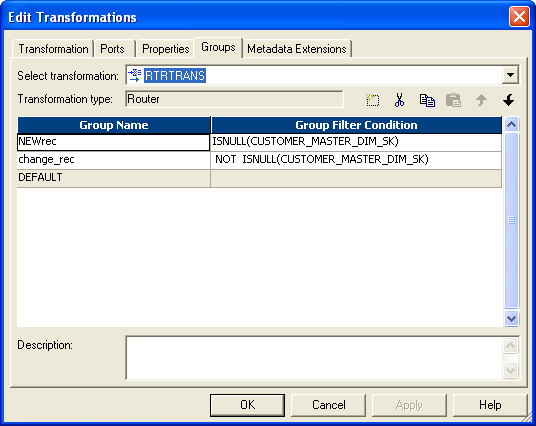
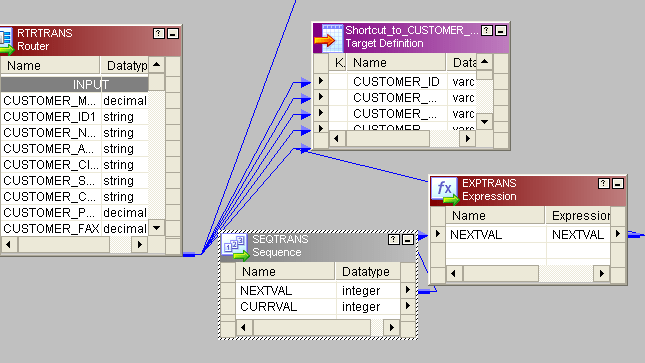
- 对于新记录,我们必须生成新的customer_id。为此,请使用一个序列生成器,并将下一列连接到表达式。来自路由器的New_rec组连接到target1(将两个target实例映射到该实例,一个实例用于新rec,另一个实例用于旧rec)。然后将next_val从表达式连接到目标的customer_id列。
- 路由器的Change_rec组带来一种更新策略并给出如下条件:
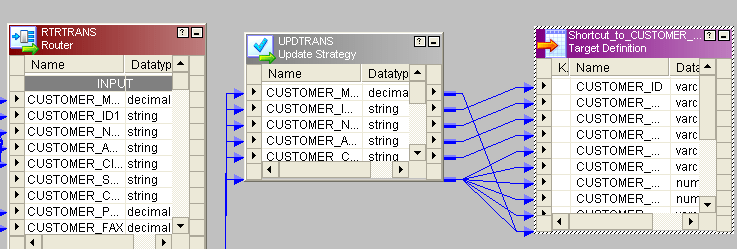
- 您可以在更新策略中给dd_update代替1,然后连接到target。
26.通过映射详细解释SCD TYPE 2。
SCD Type2映射
在“类型2缓慢变化的维”中,如果将一条新记录添加到具有新信息的现有表中,则原始和新记录都将显示具有新记录的主键。
- 为了识别new_rec,我们应该添加一个new_pm和一个vesion_no。
- 这是来源:
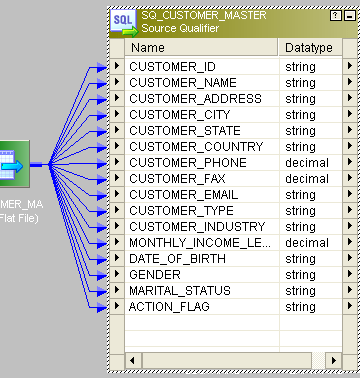
- 这是整个映射:
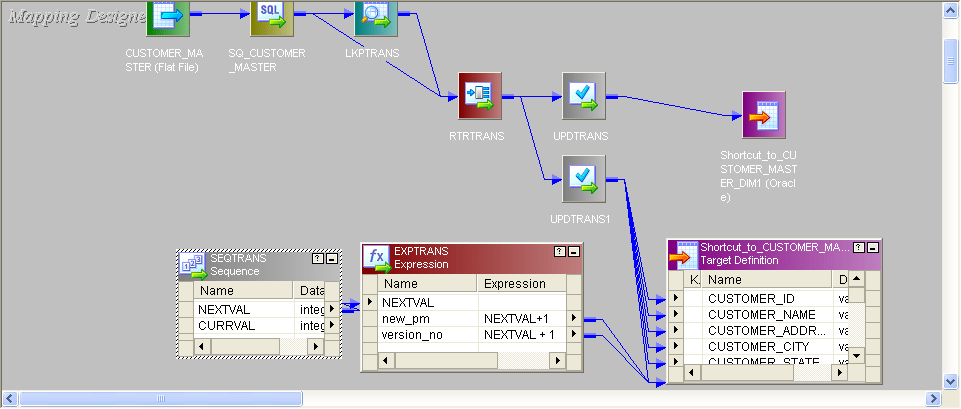
- 所有过程都类似于SCD TYPE1映射。唯一的区别是,从路由器new_rec到一个update_strategy,条件将被赋予dd_insert,并且将一个new_pm和version_no添加到发送给目标之前。
- Old_rec也将来到update_strategy条件,将给dd_insert然后将其发送到目标。
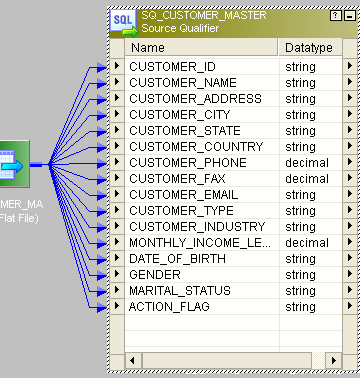
27.通过映射说明SCD TYPE 3。
SCD Type3映射
在SCD Type3中,应该添加两列以标识单个属性。它存储一次历史数据和当前数据。
- 这是来源:
- 这是整个映射:
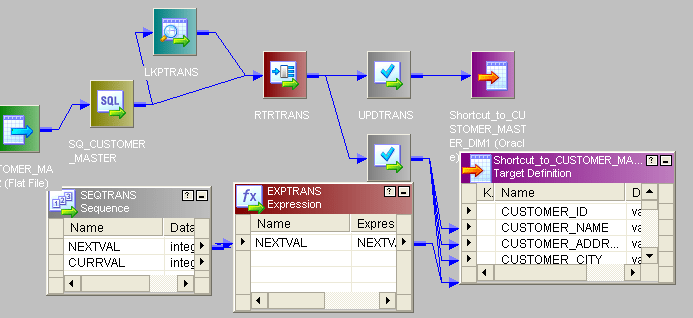
- 直到路由器转换,所有过程都与SCD type1中描述的相同。
- 唯一的区别是在路由器之后,将new_rec带到路由器并给dd_insert发送条件。
- 创建一个新的主键发送给目标。对于old_rec,发送至update_strategy并设置条件dd_insert并发送至目标。
- 您可以在old_rec表中创建一个有效日期列
28.区分可重用转换和Mapplet。
在Transformation Developer中创建的任何Informatica Transformation或从映射设计器提升为可重用转换的不可重用转换(可在多个映射中使用)都称为可重用转换。
当我们向映射添加可重用转换时,实际上是添加了转换实例。由于可重用转换的实例是该转换的指针,因此当我们在Transformation Developer中更改转换时,其实例反映了这些更改。
Mapplet是在Mapplet Designer中创建的可重用对象,其中包含一组转换,让我们在多个映射中重用转换逻辑。
Mapplet可以包含所需的任意数量的转换。就像在映射中使用mapplet时的可重用转换一样,我们使用mapplet的实例,并且对mapplet所做的任何更改都将被mapplet的所有实例继承。
29.目标负荷计划是什么意思?
目标装载顺序:
目标加载顺序(或)目标加载计划用于指定集成服务加载目标的顺序。您可以基于映射中的源限定符转换指定目标加载顺序。如果您有多个源限定符转换连接到多个目标,则可以指定集成服务将数据加载到目标中的顺序。
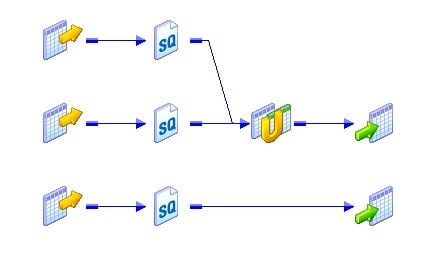
目标装载订单组:
目标加载顺序组是映射中链接的源限定符,转换和目标的集合。集成服务同时读取目标加载顺序组,并顺序处理目标加载顺序组。下图显示了单个映射中的两个目标装载顺序组。
目标装载顺序的使用:
当一个目标的数据依赖于另一目标的数据时,目标加载顺序将很有用。例如,由于主键和外键的关系,employee表数据依赖于部门数据。因此,应该首先加载部门表,然后再加载雇员表。如果要在插入,删除或更新具有主键和外键约束的表时保持引用完整性,则目标加载顺序很有用。
目标装载顺序设置:
您可以在映射设计器中设置目标加载顺序或计划。请按照以下步骤配置目标加载顺序:
1.登录到PowerCenter设计器,并创建一个包含多个目标装载订单组的映射。 2.单击工具栏中的“映射”,然后单击“目标负载计划”。将弹出以下对话框,列出映射中的所有源限定符转换以及从每个源限定符接收数据的目标。
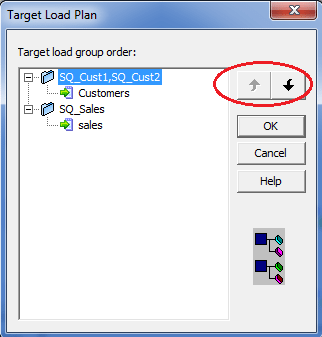
- 从列表中选择一个源限定符。
- 单击“向上”和“向下”按钮以在加载顺序内移动源限定符。
- 对要重新排序的其他源限定符重复步骤3和4。
- 单击确定。
30.编写“未连接”查找语法以及如何返回多个列。
我们只能从“未连接的查找”转换中返回一个端口。由于从另一个转换调用了未连接的查询,因此我们无法使用“未连接的查询”转换返回多个列。
但是,有一个窍门。我们可以使用SQL重写并连接需要返回的多列。当我们可以从另一个转换中查找时,我们需要使用子字符串再次分隔列。
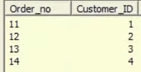
作为一种情况,我们采用一种来源,其中包含Customer_id和Order_id列。
资源:
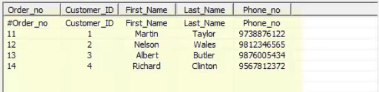
我们需要查找Customer_master表,该表包含客户信息,例如姓名,电话等。
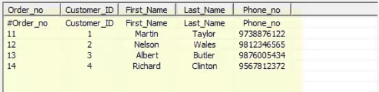
目标应如下所示:
让我们看一下未连接的查找。
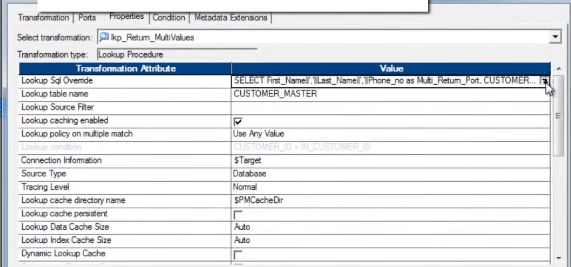
SQL Override,带有串联的端口/列:
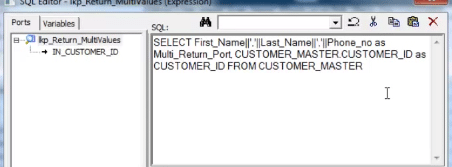
整个映射如下所示。
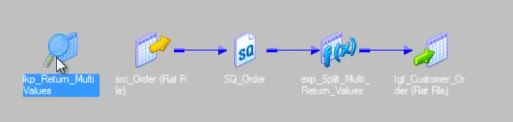
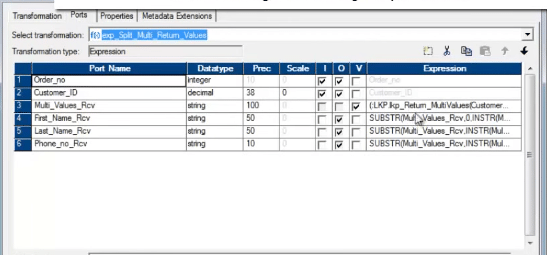
我们从一个表达式转换中调用未连接的查找。
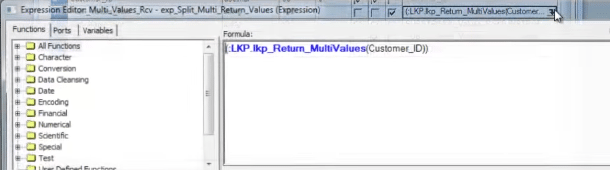
下面是表达式转换的屏幕截图。
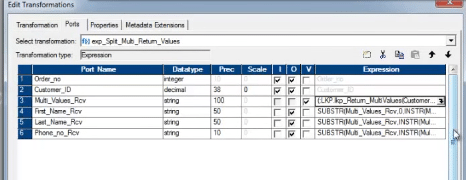
执行上述映射后,下面是填充的目标。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/2360.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
