大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
一、Uplift模型
因果推断在互联网界应用主要是基于Uplift model来预测额外收益提升ROI。Uplift模型帮助商家计算人群营销敏感度,驱动收益模拟预算和投放策略制定,促成营销推广效率的最大化。同时如何衡量和预测营销干预带来的“增量提升”,而不是把营销预算浪费在“本来就会转化”的那部分人身上,成为智能营销算法最重要的挑战。
举个例子?:对用户A和用户B都投放广告,投放广告后用户A的CVR(转化量/点击量)为5%,用户B的CVR为4%,那么是否就给用户A投广告呢?仅从投放广告后的结果来看是这样的。但如果投放广告前用户A的CVR为4%,用户B的CVR为2%,那么我们就认为广告投放本身所带来的收益B要比A多,所以把广告投给用户B。
Uplift模型的作用就是计算人群营销敏感度,具体就是计算每个用户的增益,再根据广告主设置的预算以及其它限制看是否对该用户投放广告。
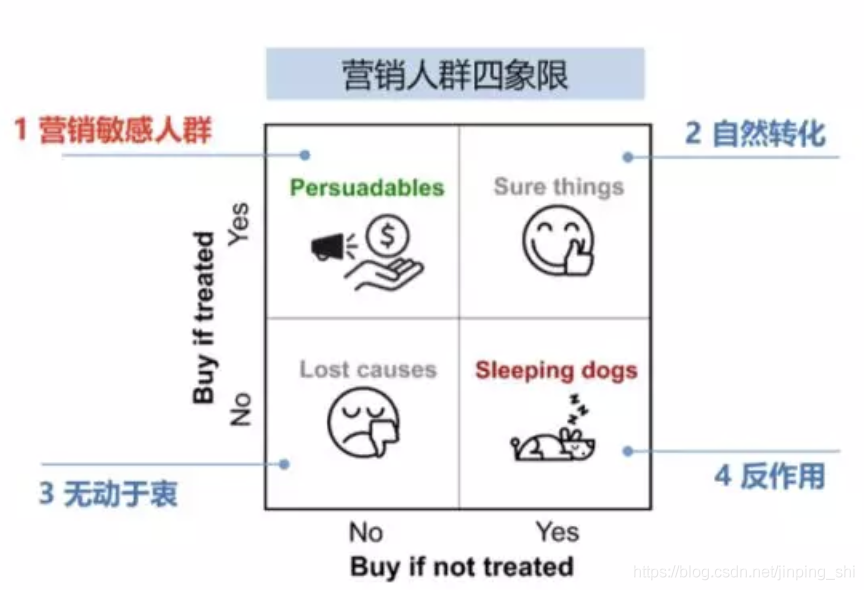

- persuadables: 不发券就不购买、发券才会购买的人群,即优惠券敏感人群
- sure thing:无论是否发券,都会购买,自然转化
- lost causes:无论是否发券都不会购买,这类用户实在难以触达到,直接放弃
- sleeping dogs:与persuadables相反,对营销活动比较反感,不发券的时候会有购买行为,但发券后不会再购买。
建模时主要针对persuadables人群,并且要避免sleeping dogs人群。如果使用reponse model,则难以区分这几类人群,因为模型只预测是否购买,可能转化的用户中persuadable的比例相当少,并不是营销中的target。
Uplift模型用于预测/估计某种干预对个体状态/行为的因果效应。可以形式化为以下等式:
τ i = p ( Y i ∣ X i , T i = 1 ) − p ( Y i ∣ X i , T i = 0 ) (1) \tau_i=p(Y_i|X_i, T_i=1)-p(Y_i|X_i, T_i=0)\tag1 τi=p(Yi∣Xi,Ti=1)−p(Yi∣Xi,Ti=0)(1)
其中, Y i Y_i Yi表示潜在结果(比如转化率,点击率等), X i X_i Xi表示用户的特征, T i = 1 T_i=1 Ti=1表示进行干预, T i = 0 T_i=0 Ti=0表示不进行干预,应用在广告营销中就可以形象的表示为某用户在经过广告投放行为之后,用户发生某种行为(点击或购买)增加的概率。
注意到,对于一个用户,我们只能对他进行干预或者不干预,即只能观测到 T 1 = 1 T_1=1 T1=1或 T 1 = 0 T_1=0 T1=0,所以对于一个个体的增益 τ i \tau_i τi是观测不到的。
所以我们可以考虑总体的(人群的子人群,即用一个人群的因果效果来表示一个单个人的因果效果),即平均因果效应(Average treatment effect,简记为ATE): A T E = E ( Y i ( 1 ) − Y i ( 0 ) ) = E ( Y i ( 1 ) ) − E ( Y i ( 0 ) ) (2) ATE=E(Y_i(1)-Y_i(0))=E(Y_i(1))-E(Y_i(0))\tag2 ATE=E(Yi(1)−Yi(0))=E(Yi(1))−E(Yi(0))(2)
T i ∈ { 0 , 1 } T_i\in\{0, 1\} Ti∈{
0,1}表示是否进行干预,那么可有 Y i o b s = T i Y i ( 1 ) + ( 1 − T i ) Y i ( 0 ) (3) Y_i^{obs}=T_iY_i(1)+(1-T_i)Y_i(0)\tag3 Yiobs=TiYi(1)+(1−Ti)Yi(0)(3)
这里详细介绍了在合理的假设下,即在一个确定的特征 X i X_i Xi下,用户是随机分到treatment组和对照组的,那么 ( 2 ) (2) (2)式可化为 A T E = E ( Y i ∣ T i = 1 ) − E ( Y i ∣ T i = 0 ) = E ( Y i o b s ∣ X i = x , T i = 1 ) − E ( Y i o b s ∣ X i = x , T i = 0 ) (4) ATE=E(Y_i|T_i=1)-E(Y_i|T_i=0)=E(Y_i^{obs}|X_i=x,T_i=1)-E(Y_i^{obs}|X_i=x,T_i=0)\tag4 ATE=E(Yi∣Ti=1)−E(Yi∣Ti=0)=E(Yiobs∣Xi=x,Ti=1)−E(Yiobs∣Xi=x,Ti=0)(4)
从而可以设计随机化的A/B Test。
二、建模
补贴活动提升的购买意愿为 τ ( X i ) = P ( Y i = 1 ∣ X i , T i = 1 ) − P ( Y i = 1 ∣ X i , T i = 0 ) \tau(X_i)=P(Y_i=1|X_i,T_i=1)-P(Y_i=1|X_i,T_i=0) τ(Xi)=P(Yi=1∣Xi,Ti=1)−P(Yi=1∣Xi,Ti=0),由于我们得不到一个用户的 τ i \tau_i τi,所以无法得到真正的label,造成监督学习无法进行。在缺少真正 τ i \tau_i τi的情况下,一般有三大类方法来评估 τ i \tau_i τi:The Class Transformation Method、Meta-Learning Method、Tree-Based Method。
2.1 The Class Transformation Method
该方法应该归于Meta-Learning Method,这里为了不混淆单列出来。该方法适用于Treatment和Outcome都是二类分类的情况,通过将预测目标做单类的转换,从而实现单模型预测。
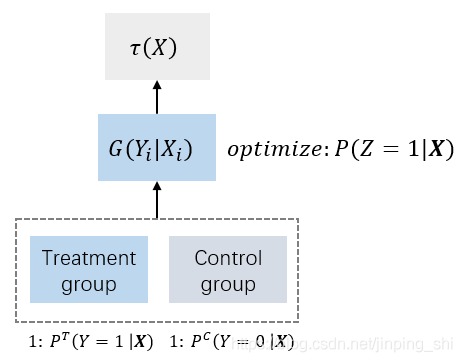
首先,定义新的变量 Z i = Y i o b s T i + ( 1 − Y i o b s ) ( 1 − T i ) (5) Z_{i}=Y_{i}^{o b s} T_{i}+\left(1-Y_{i}^{o b s}\right)\left(1-T_{i}\right)\tag5 Zi=YiobsTi+(1−Yiobs)(1−Ti)(5)
由于Treatment和Outcome都是二类分类,所以 Y i o b s ∈ { 0 , 1 } Y_i^{o b s}\in\{0, 1\} Yiobs∈{
0,1}, T i ∈ { 0 , 1 } T_i\in\{0, 1\} Ti∈{
0,1},所以当 Y i o b s = T i = 0 Y_i^{o b s}=T_i=0 Yiobs=Ti=0或 Y i o b s = T i = 1 Y_i^{o b s}=T_i=1 Yiobs=Ti=1时, Z i = 1 Z_i=1 Zi=1。
那么对Uplift τ ( X i ) \tau(X_i) τ(Xi)有 τ ( X i ) = 2 P ( Z i = 1 ∣ X i ) − 1 (6) \tau(X_i)=2 P\left(Z_{i}=1 \mid X_{i}\right)-1\tag6 τ(Xi)=2P(Zi=1∣Xi)−1(6)
推导:
由 Z i Z_i Zi的定义可知 P ( Z i = 1 ∣ X i ) = P ( Y i = 1 , T i = 1 ∣ X i ) + P ( Y i = 0 , T i = 0 ∣ X i ) P(Z_i=1|X_i)=P(Y_i=1,T_i=1|X_i)+P(Y_i=0,T_i=0|X_i) P(Zi=1∣Xi)=P(Yi=1,Ti=1∣Xi)+P(Yi=0,Ti=0∣Xi),而根据假设有 P ( T i = 1 ∣ X i ) = P ( T i = 0 ∣ X i ) = 1 2 P(T_i=1|X_i)=P(T_i=0|X_i)=\frac{1}{2} P(Ti=1∣Xi)=P(Ti=0∣Xi)=21,所以 τ ( X i ) = P ( Y i = 1 ∣ X i , T i = 1 ) − P ( Y i = 1 ∣ X i , T i = 0 ) = P ( Y i = 1 , T i = 1 ∣ X i ) P ( T i = 1 ∣ X i ) − P ( Y i = 1 , T i = 0 ∣ X i ) P ( T i = 0 ∣ X i ) = 2 [ P ( Y i = 1 , T i = 1 ∣ X i ) − P ( Y i = 1 , T i = 0 ∣ X i ) ] = [ P ( Y i = 1 , T i = 1 ∣ X i ) − P ( Y i = 1 , T i = 0 ∣ X i ) ] + [ 1 2 − P ( Y i = 0 , T i = 1 ∣ X i ) − 1 2 + P ( Y i = 0 , T i = 0 ∣ X i ) ] = P ( Z i = 1 ∣ X i ) − P ( Z i = 0 ∣ X i ) = 2 P ( Z i = 1 ∣ X i ) − 1 \tau(X_i)=P(Y_i=1|X_i,T_i=1)-P(Y_i=1|X_i,T_i=0)\\ =\frac{P(Y_i=1,T_i=1|X_i)}{P(T_i=1|X_i)}-\frac{P(Y_i=1,T_i=0|X_i)}{P(T_i=0|X_i)}\\ =2[P(Y_i=1,T_i=1|X_i)-P(Y_i=1,T_i=0|X_i)]\\ =[P(Y_i=1,T_i=1|X_i)-P(Y_i=1,T_i=0|X_i)]\\ +[\frac{1}{2}-P(Y_i=0,T_i=1|X_i)-\frac{1}{2}+P(Y_i=0,T_i=0|X_i)]\\ =P(Z_i=1|X_i)-P(Z_i=0|X_i)\\ =2P(Z_i=1|X_i)-1 τ(Xi)=P(Yi=1∣Xi,Ti=1)−P(Yi=1∣Xi,Ti=0)=P(Ti=1∣Xi)P(Yi=1,Ti=1∣Xi)−P(Ti=0∣Xi)P(Yi=1,Ti=0∣Xi)=2[P(Yi=1,Ti=1∣Xi)−P(Yi=1,Ti=0∣Xi)]=[P(Yi=1,Ti=1∣Xi)−P(Yi=1,Ti=0∣Xi)]+[21−P(Yi=0,Ti=1∣Xi)−21+P(Yi=0,Ti=0∣Xi)]=P(Zi=1∣Xi)−P(Zi=0∣Xi)=2P(Zi=1∣Xi)−1
注意到, P ( Y i = 1 , T i = 1 ∣ X i ) = P ( T i = 1 ∣ X i ) − P ( Y i = 0 , T i = 1 ∣ X i ) = 1 2 − P ( Y i = 0 , T i = 1 ∣ X i ) P(Y_i=1,T_i=1|X_i)=P(T_i=1|X_i)-P(Y_i=0,T_i=1|X_i)=\frac{1}{2}-P(Y_i=0,T_i=1|X_i) P(Yi=1,Ti=1∣Xi)=P(Ti=1∣Xi)−P(Yi=0,Ti=1∣Xi)=21−P(Yi=0,Ti=1∣Xi),所以倒数第三个等号成立。
训练和测试过程如下图所示。从实验组和对照组筛选出 Z = 1 Z = 1 Z=1的用户作为正样本,其余的作为负样本。实际上 Z = 1 Z = 1 Z=1就是实验组中下单的用户和对照组中未下单的用户,因此可以直接将实验组和对照组用户合并,使用一个模型建模,实现了数据层面和模型层面的打通。
2.2 Meta-Learning Method
Meta-Learning方法是指基于Meta-Learner进行Uplift预估,其中Meta-Learner可以是任意的既有预测算法,如LR、SVM、RF、GBDT等。根据Meta-Learner的组合不同,通常分为:S-Learner、T-Learner、X-Learner、R-Learner。
- 优点:利用了既有预测算法的预测能力,方便易实现
- 缺点:不直接建模uplift,效果打折扣
2.2.1 S-Learner
S即Single,S-Learner是指用一个模型来估计Uplift,即在实验组和对照组样本特征中加入干预 T T T有关的特征,将实验组和对照组的样本特征、Label 合并,训练一个模型。具体步骤为:
- Step1: 基于特征 X X X和干预 T T T训练预测模型 μ ( x , t ) = E ( Y o b s ∣ X = x , T = t ) (7) \mu(x, t)=E(Y^{obs}|X=x,T=t)\tag7 μ(x,t)=E(Yobs∣X=x,T=t)(7)
- Step2: 分别估计干预和不干预时的得分,差值即为增量 τ ^ S ( x ) = μ ^ ( x , 1 ) − μ ^ ( x , 0 ) (8) \hat\tau_S(x)=\hat\mu(x,1)-\hat\mu(x,0)\tag8 τ^S(x)=μ^(x,1)−μ^(x,0)(8)
优点:
- S-Learner简单直观、直接使用既有预测算法
- 预测仅依赖一个模型,避免了多模型的误差累积
- 更多的数据(利用了全量数据训练模型)和特征工程对预测准确率有利
缺点:
- 该方法不直接建模uplift
- 需要额外进行特征工程工作(由于模型拟合的是 Y Y Y,所以若 T T T直接作为一个特征放进去,可能由于对 Y Y Y的预测能力不足而未充分利用)
2.2.2 T-Learner
T即Two,T-Learner是指用两个模型来估计Uplift,即用两个模型分别建模干预、不干预的情况,取差值作为Uplift。具体步骤为:
- Step1: 对treatment组数据和control组数据分别训练预测模型 μ 0 ( x ) = E ( Y ( 0 ) ∣ X = x ) (9) \mu_0(x)=E(Y(0)|X=x)\tag9 μ0(x)=E(Y(0)∣X=x)(9) μ 1 ( x ) = E ( Y ( 1 ) ∣ X = x ) (10) \mu_1(x)=E(Y(1)|X=x)\tag{10} μ1(x)=E(Y(1)∣X=x)(10)
- Step2: 两个模型分别打分 τ ^ T ( x ) = μ ^ 1 ( x ) − μ ^ 0 ( x ) (11) \hat\tau_T(x)=\hat\mu_1(x)-\hat\mu_0(x)\tag{11} τ^T(x)=μ^1(x)−μ^0(x)(11)
预测时,对每个待预测用户都分别用两个模型预测一下。
优点:
- T-Learner一样简单直观、直接使用既有预测算法
- 将不同的数据集中的增量效果转换为模型间的差异,不需要太多的特征工程工作
- 当有随机试验的数据时该方法作为baseline很方便
缺点:
- 该方法存在双模型误差累积问题
- 同时当数据差异过大时(如数据量、采样偏差等),对准确率影响较大
- 间接计算增量,无法对模型进行优化
2.2.3 X-Learner
X-Learner算法是在Two Model模型基础上提出的,基于利用观察到的样本结果去预估未观察到的样本结果的思想,对增量进行近似,同时还会对结果进行倾向性权重调整,以达到优化近似结果的目的。具体步骤为:
- Step1: 对treatment组数据和control组数据分别训练预测模型 μ 0 ( x ) = E ( Y ( 0 ) ∣ X = x ) (12) \mu_0(x)=E(Y(0)|X=x)\tag{12} μ0(x)=E(Y(0)∣X=x)(12) μ 1 ( x ) = E ( Y ( 1 ) ∣ X = x ) (13) \mu_1(x)=E(Y(1)|X=x)\tag{13} μ1(x)=E(Y(1)∣X=x)(13)
- Step2: 用treatment组模型预测control组数据,control组模型预测treatment组数据,分别做与Y的差值得到增量的近似 D 0 = μ ^ 1 ( X 0 ) − Y 0 (14) D_0=\hat\mu_1(X_0)-Y_0\tag{14} D0=μ^1(X0)−Y0(14) D 1 = Y 1 − μ ^ 0 ( X 1 ) (15) D_1=Y_1-\hat\mu_0(X_1)\tag{15} D1=Y1−μ^0(X1)(15)
- 以此为目标再训练两个预测模型,拟合uplift τ 0 ( x ) = E ( D 0 ∣ X = x ) (16) \tau_0(x)=E(D_0|X=x)\tag{16} τ0(x)=E(D0∣X=x)(16) τ 1 ( x ) = E ( D 1 ∣ X = x ) (17) \tau_1(x)=E(D_1|X=x)\tag{17} τ1(x)=E(D1∣X=x)(17)
- 预测得到两个近似增量,做加权得到uplift结果,加权函数可用倾向性得分 τ ^ ( x ) = g ( x ) τ ^ 0 ( x ) + ( 1 − g ( x ) ) τ ^ 1 ( x ) (18) \hat{\tau}(x)=g(x) \hat{\tau}_{0}(x)+(1-g(x)) \hat{\tau}_{1}(x)\tag{18} τ^(x)=g(x)τ^0(x)+(1−g(x))τ^1(x)(18)
其中, g ( x ) = P ( T = 1 ∣ X = x ) g(x)=P(T=1|X=x) g(x)=P(T=1∣X=x),可以认为是样本数据集中 T = 1 T=1 T=1的比例。所以若 T = 1 T=1 T=1的比例极小,则 g ( x ) g(x) g(x)就很小,则 τ ^ 1 \hat\tau_1 τ^1的权重更大,即更倾向于使用control组数据训练的模型。
优点:
- 适合实验组和对照组样本数量差别较大场景
- 对于增量的先验知识可以参与建模,并且引入权重系数,减少误差(在Step3中,我们得到了两个近似的增量值,并直接对其建模。如果我们本身对业务有足够的了解,知道增量的一些相关先验知识(线性/非线性等),那么这些先验知识是可以参与建模过程并帮助我们提升模型精度的)
缺点:
- 多模型造成误差累加
- 流程相对复杂、计算成本较高
- 并没有说明多大差别才适用X-Learner,我们在实际应用中的离线评估部分,X-Learner虽然偶尔表现优异,但并没有持续显著优于其他模型
2.2.4 R-Learner
R-Learner算法思想不同于Two、Single和X-Learner。其核心思想是通过 Robinson’s transfomation 定义一个损失函数,然后通过最小化损失函数的方法达到对增量进行建模的目的。具体步骤为:
- Step1:通过交叉验证的方式,每次预测一组,得到整个数据集的预测结果 m ^ \hat{m} m^和倾向得分 e ^ \hat{e} e^ e ( x ) = E [ W = 1 ∣ X = x ] (19) e(x)=E[W=1|X=x]\tag{19} e(x)=E[W=1∣X=x](19) m ( x ) = E [ Y = 1 ∣ X = x ] (20) m(x)=E[Y=1|X=x]\tag{20} m(x)=E[Y=1∣X=x](20)
- Step2:最小化损失函数,估计增量,其中 q ( i ) q(i) q(i)表示样本 i i i在CV的第几组 L ^ n { τ ( ⋅ ) } = 1 n ∑ i = 1 n [ { Y i − m ^ ( − q ( i ) ) ( X i ) } − { W i − e ^ ( − q ( i ) ) ( X i ) } τ ( X i ) ] 2 (21) \widehat{L}_{n}\{\tau(\cdot)\}=\frac{1}{n} \sum_{i=1}^{n}[\{Y_{i}-\hat{m}^{(-q(i))}(X_{i})\}-\{W_{i}-\hat{e}^{(-q(i))}(X_{i})\} \tau(X_{i})]^{2}\tag{21} L
n{
τ(⋅)}=n1i=1∑n[{
Yi−m^(−q(i))(Xi)}−{
Wi−e^(−q(i))(Xi)}τ(Xi)]2(21)具体实现时,将损失函数改为
L ^ n { τ ( ⋅ ) } = 1 n ∑ i = 1 n [ { Y i − m ^ ( − q ( i ) ) ( X i ) } { W i − e ^ ( − q ( i ) ) ( X i ) } − τ ( X i ) ] 2 ⋅ { W i − e ^ ( − q ( i ) ) ( X i ) } 2 (22) \widehat{L}_{n}\{\tau(\cdot)\}= \frac{1}{n} \sum_{i=1}^{n}[\frac{\{Y_{i}-\hat{m}^{(-q(i))}(X_{i})\}}{\{W_{i}-\hat{e}^{(-q(i))}(X_{i})\}}- \tau(X_{i})]^{2}\cdot \{W_{i}-\hat{e}^{(-q(i))}(X_{i})\}^2\tag{22} L
n{
τ(⋅)}=n1i=1∑n[{
Wi−e^(−q(i))(Xi)}{
Yi−m^(−q(i))(Xi)}−τ(Xi)]2⋅{
Wi−e^(−q(i))(Xi)}2(22)
优点:
- 灵活且易于使用
- 损失函数可以接深度网络等
缺点:
- 模型精度依赖于 m ^ \hat{m} m^和 e ^ \hat{e} e^的精度
2.3 Tree-Based Method
传统机器学习模型中,树模型主要的思路就是通过对特征点进行分裂,将X划分到一个又一个subspace中,这与补贴场景下,希望找到某一小部分增量很高的用户的想法几乎是完美重合。
传统分类树模型是希望通过信息理论(information theory)中的信息熵等思想,用计算信息增益的方法去解决分类问题。而在uplift tree model中,其本质也还是想要通过衡量分裂前后的变量差值去决策是否分裂节点,不过这里的这个决策差值的计算方法不再是信息增益(information gain),而是不同的直接对增量uplift建模的计算方法,其中包括了利用分布散度对uplift建模和直接对uplift建模。
下面介绍三个Tree-Based算法,Uplift-Tree,CausalForest,CTS。
2.3.1 Uplift-Tree
分布散度是用来度量两个概率分布之间差异性的值,当两个分布相同时,两个离散分布的散度为非负且等于零。我们可以把实验组和对照组理解为两个概率分布,然后利用分布散度作为非叶节点分裂标准,最大化实验组和对照组的样本类别分布之间的差异,减少样本不确定度。
计算分布散度 D ( P T ( Y ) : P C ( Y ) ) D(P^T(Y):P^C(Y)) D(PT(Y):PC(Y)),常见的分布散度有KL 散度 (Kullback-Leibler divergence)、欧式距离 (Squared Euclidean distance) 和卡方散度(Chi-squared divergence),对应着下面三种方式 K L ( P : Q ) = ∑ i p i log p i q i (23) K L(P: Q) =\sum_{i} p_{i} \log \frac{p_{i}}{q_{i}}\tag{23} KL(P:Q)=i∑pilogqipi(23) E ( P : Q ) = ∑ i ( p i − q i ) 2 (24) E(P: Q) =\sum_{i}\left(p_{i}-q_{i}\right)^{2}\tag{24} E(P:Q)=i∑(pi−qi)2(24) χ 2 ( P : Q ) = ∑ i ( p i − q i ) 2 q i (25) \chi^{2}(P: Q) =\sum_{i} \frac{\left(p_{i}-q_{i}\right)^{2}}{q_{i}}\tag{25} χ2(P:Q)=i∑qi(pi−qi)2(25)
其中 p p p表示treatment组, q q q表示control组, i i i表示取值,如是二分离问题,则 i ∈ { 0 , 1 } i\in\{0, 1\} i∈{
0,1}
上述三种分布散度有个共同点,当两个概率分布相同时,值为0;当两个概率分布差异越大时,值越大。欧式距离的优点是对称,且值更稳定。
分布散度还有个特点:通过公式可以推导,当结点中对照组数据为空时,KL散度会退化为决策树分裂准则中的信息增益;欧式距离和卡方散度将会退化为基尼指数。而当结点中实验组数据为空时,欧式距离将会化为基尼指数。这也是该类分裂准则的优点之一。
其模型主要构造流程为:

举个例子?:

剪枝:
剪枝是为了使模型具有更好的泛化能力。标准决策树的剪枝有多种方法,最简单的则是看剪枝前后对验证集准确率是否有帮助,但在增量建模中该方法不太好实现。
论文中提出了一个度量方法——maximum class probability difference,核心思想是看结点中Treatment组和Control组的差异,如果单独的根节点更大则剪枝。具体步骤如下:
- Step1: 在训练阶段,对每个结点,记录其差异(绝对值)最大的类,以及正负号
y ∗ ( t ) = arg max y ∗ ∣ P T ( y ∗ ∣ t ) − P C ( y ∗ ∣ t ) ∣ (26) y^*(t)=\arg\max_{y^*}\left|P^{T}\left(y^{*} \mid t\right)-P^{C}\left(y^{*} \mid t\right)\right|\tag{26} y∗(t)=argy∗max∣∣PT(y∗∣t)−PC(y∗∣t)∣∣(26)
s ∗ ( t ) = sgn ( P T ( y ∗ ∣ t ) − P C ( y ∗ ∣ t ) ) (27) s^{*}(t)=\operatorname{sgn}\left(P^{T}\left(y^{*} \mid t\right)-P^{C}\left(y^{*} \mid t\right)\right)\tag{27} s∗(t)=sgn(PT(y∗∣t)−PC(y∗∣t))(27) - Step2: 在验证阶段,利用Step1计算好的 y ∗ y^* y∗, s ∗ s^* s∗,以及验证数据计算的概率值,计算叶结点和根节点的得分 d 1 ( r ) = ∑ i = 1 k N ( l i ) N ( r ) s ∗ ( l i ) ( P T ( y ∗ ( l i ) ∣ l i ) − P C ( y ∗ ( l i ) ∣ l i ) ) (28) d_{1}(r)=\sum_{i=1}^{k} \frac{N\left(l_{i}\right)}{N(r)} s^{*}\left(l_{i}\right)\left(P^{T}\left(y^{*}\left(l_{i}\right) \mid l_{i}\right)-P^{C}\left(y^{*}\left(l_{i}\right)\mid l_{i}\right)\right)\tag{28} d1(r)=i=1∑kN(r)N(li)s∗(li)(PT(y∗(li)∣li)−PC(y∗(li)∣li))(28)
d 2 ( r ) = s ∗ ( r ) ( P T ( y ∗ ( r ) ∣ r ) − P C ( y ∗ ( r ) ∣ r ) ) (29) d_{2}(r)=s^{*}(r)\left(P^{T}\left(y^{*}(r) \mid r\right)-P^{C}\left(y^{*}(r) \mid r\right)\right)\tag{29} d2(r)=s∗(r)(PT(y∗(r)∣r)−PC(y∗(r)∣r))(29) - Step3: 最后,若 d 1 ( r ) ≤ d 2 ( r ) d_1(r)\le d_2(r) d1(r)≤d2(r),则进行剪枝
2.3.2 CausalForest
顾名思义,类比RandomForest,CausalForest是指由多个CausalTree模型融合得到的Forest模型,而对于CausalForest,这里可以是任意单Tree-Based方法。
分层分到足够细,近似认为消除了Confounder,则指定叶子节点的Uplift为 τ ^ ( x ) = 1 ∣ { i : W i = 1 , X i ∈ L } ∣ ∑ { i : W i = 1 , X i ∈ L } Y i − 1 ∣ { i : W i = 0 , X i ∈ L } ∣ ∑ { i : W i = 0 , X i ∈ L } Y i (30) \hat{\tau}(x)=\frac{1}{\left|\left\{i: W_{i}=1, X_{i} \in L\right\}\right|} \sum_{\left\{i: W_{i}=1, X_{i} \in L\right\}}^{Y_{i}} -\frac{1}{\left|\left\{i: W_{i}=0, X_{i} \in L\right\}\right|} \sum_{\left\{i: W_{i}=0, X_{i} \in L\right\}}^{Y_{i}} \tag{30} τ^(x)=∣{
i:Wi=1,Xi∈L}∣1{
i:Wi=1,Xi∈L}∑Yi−∣{
i:Wi=0,Xi∈L}∣1{
i:Wi=0,Xi∈L}∑Yi(30)
基于不同的样本子集训练多个CausalTree,用均值作为最终的结果 τ ^ ( x ) = B − 1 ∑ b = 1 B τ ^ b ( x ) (31) \hat{\tau}(x)=B^{-1} \sum_{b=1}^{B} \hat{\tau}_{b}(x)\tag{31} τ^(x)=B−1b=1∑Bτ^b(x)(31)
2.3.3 CTS
CTS(Contextual Treatment Selection),是一种Tree-Based的uplift modeling方法,可用于MultiTreatment和General Response Type(分类或回归)的问题。不同于分布散度,在该标准下,我们会直接最大化每个节点上实验组和对照组之间label期望的差值(可以理解为该节点上样本的Uplift值),并以此来分裂节点。
CTS树具体构造流程为:

相比于meta-learner,uplift下树模型由于往往是直接对uplift进行建模和利用特征直接对人群进行切分,因此模型精度往往比较高一些。但是在实际应用中,还是需要要注意树模型的收敛性以及它的泛化能力。
三、评估
常用分类和回归算法,可以通过 AUC、准确率和 RMSE 等去评估模型的好坏。而由于Uplift Model 中不可能同时观察到同一用户在不同干预策略下的响应,即无法获取用户真实增量, 我们也就无法直接利用上述评价指标去衡量模型的好坏。因此,Uplift Model 通常都是通过划分十分位数来对齐实验组和对照组数据,去进行间接评估。常用的评估方 法有 Qini 曲线、AUUC 等。
3.1 Qini curve
Qini 曲线是衡量 Uplift Model 精度方法之一,通过计算曲线下的面积,类似 AUC 来评价模型的好坏。其计算流程如下:
(1)在测试集上,将实验组和对照组分别按照模型预测出的增量由高到底排序,根据用户数量占实验组和对照组用户数量的比例,将实验组和对照组分别划分为十份,分别是
Top10%, 20%, . . . , 100%。(2) 计算Top10%,20%,…,100%的Qini系数,生成Qini曲线数据(Top10%,Q(Top10%)),
(…,…), (Top100%, Q(Top100%))。Qini 系数定义如下:
其中,用户下单是指输出结果为1

可以看出,Qini 系数分母是实验组和对照组的总样本量,如果实验组和对照组用户数量差别比较大,结果将变得不可靠。
3.2 AUUC
AUUC(Area Under the Uplift Curve) 的计算流程与 Qini 曲线的计算流程一样,计算前 10%、20%、. . . 、100% 的指标,绘制曲线,然后求曲线下的面积,衡量模型的好坏。不同是 AUUC 指标计算方法与 Qini 指标计算不同,AUUC 指标定义如下:
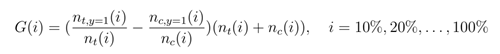
与 Qini 指标含义相同,当 i 取10% 时, n t ( i ) n_t(i) nt(i)表示实验组前 10% 用户数量, n c ( i ) n_c(i) nc(i)表示对照组前 10% 用户数量。可以看出,AUUC 指标计算方法可以避免实验组和对照组用户数量差别较大导致的指标不可靠问题。
值得注意的是,当分桶时,对照组边界点预估出的增量与实验组边界点的预估值有较大差别时候,以上的两个评估指标似乎都显得不那么可靠了。因此在实际中,我们使用的往往是AUUC 另外的一种计算方法:

3.3 如何理解离线指标AUUC?
AUUC是一个很重要且奇怪的指标。说重要,是因为它几乎是Uplift Model在离线阶段唯一一个直观的,可解释的评估模型优劣的指标。说奇怪,是因为它虽然本质上似乎借鉴了分类模型评价指标AUC的一些思想,但是习惯了AUC的算法工程师们在初次接触的时候一定会被它搞得有点迷糊。
作为在分类模型评估上的标杆,AUC的优秀不用过多赘述。其中最优秀的一点是它的评价结果稳定到可以超越模型和样本本身而成立,只要是分类问题,AUC0.5是随机线,0.6的模型还需要迭代一下找找提升的空间,0.6-0.8是模型上线的标准,而0.9以上的模型就需要考虑一下模型是否过拟合和是否有未知强相关特征参与了模型训练。一法抵万法,我们可以抛开特征,样本和模型构建的细节而直接套用这套准则。
然而这个特点对于AUUC就完全是奢望了。通过AUUC的公式可以看出,AUUC最终形成的指标的绝对值大小是取决于样本的大小的。也就是说,在一套测试样本上,我们的AUUC可能是0到1W,而换了一套样本,这个值可能就变成了0到100W。这使得不同测试样本之间模型的评估变为了不可能。也使得每次模型离线的迭代的前提必须是所有模型都使用同一套测试样本。当我们训练完一个新的模型,跑出一个40万的auuc,我们完全无从得知这个值背后代表着模型精度如何,我们只能拿出旧的模型在同样测试集上跑出auuc然后相互比较。这无疑让整个训练迭代过程变得更痛苦了一点。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/234946.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
