大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定


本文记录了HBase中Safepoint导致长时间STW此问题的解决思路及办法。
上篇文章回顾:HBase Replication详解
过 程 记 录
现象:小米有一个比较大的公共离线HBase集群,用户很多,每天有大量的MapReduce或Spark离线分析任务在进行访问,同时有很多其他在线集群Replication过来的数据写入,集群因为读写压力较大,且离线分析任务对延迟不敏感,所以其G1GC的MaxGCPauseMillis设置是500ms。
但是随着时间的推移,我们发现了一个新的现象,线程的STW时间可以到3秒以上,但是实际GC的STW时间却只有几百毫秒!
打印GC日志
-
-XX:+PrintGC
-
-XX:+PrintGCDetails
-
-XX:+PrintGCApplicationStoppedTime
-
-XX:+PrintHeapAtGC
-
-XX:+PrintGCDateStamps
-
-XX:+PrintAdaptiveSizePolicy
-
-XX:+PrintTenuringDistribution
具体的日志log示例如下:
[Times: user=1.51 sys=0.67, real=0.14 secs]
2019-06-25T12:12:43.376+0800: 3448319.277: Total time for which application threads were stopped: 2.2645818 seconds, Stopping threads took: xxx seconds-XX:+PrintGCApplicationStoppedTime会打出类似上面的日志,这个stopped时间是JVM里所有STW的时间,不止GC。我们遇到的现象就是stopped时间远大于上面的GC real耗时,比如GC只耗时0.14秒,但是线程却stopped了2秒多。这个时候大概率就是GC时线程进入Safepoint耗时过长,所以需要2个新的GC参数来打印出Safepoint的情况。
打印Safepoint相关日志
-
-XX:+PrintSafepointStatistics
-
-XX:PrintSafepointStatisticsCount=1
需要注意的是Safepoint的情况是打印到标准输出里的,具体的日志log示例如下:
vmop [threads: total initially_running wait_to_block]
65968.203: ForceAsyncSafepoint [931 1 2]这部分日志是时间戳,VM Operation的类型,以及线程概况,比如上面就显示有2个线程在等待进入Safepoint:
[time: spin block sync cleanup vmop] page_trap_count
[2255 0 2255 11 0] 1接下来的这部分日志是到达Safepoint时的各个阶段以及执行操作所花的时间:
spin:因为JVM在决定进入全局Safepoint的时候,有的线程在Safepoint上,而有的线程不在Safepoint上,这个阶段是等待未在Safepoint上的用户线程进入Safepoint。
block:即使进入Safepoint,用户线程这时候仍然是running状态,保证用户不在继续执行,需要将用户线程阻塞
sync:spin+block的耗时
所以上面的日志就是说,有2个线程进入Safepoint特别慢,其他线程等待这2个线程进入Safepoint等待了2255ms。
打印进入Safepoint慢的线程
-
-XX:+SafepointTimeout
-
-XX:SafepointTimeoutDelay=2000
这两个参数的意思是当有线程进入Safepoint超过2000毫秒时,会认为进入Safepoint超时了,这时会打出来哪些线程没有进入Safepoint,具体日志如下:
# SafepointSynchronize::begin: Timeout detected:
# SafepointSynchronize::begin: Timed out while spinning to reach a safepoint.
# SafepointSynchronize::begin: Threads which did not reach the safepoint:
# "RpcServer.listener,port=24600" #32 daemon prio=5 os_prio=0 tid=0x00007f4c14b22840 nid=0xa621 runnable [0x0000000000000000]
java.lang.Thread.State: RUNNABLE
# SafepointSynchronize::begin: (End of list)从上面的日志可以看出来是RpcServer.listener进入Safepoint耗时过长,那么该如何解决这个问题呢?这就需要了解一点GC和Safepoint的背景知识了。
GC及Safepoint
GC
GC(Garabage Collection):垃圾回收,是Java这种自动内存管理语言中的关键技术。GC要解决的三个关键问题是:哪些内存可以回收?什么时候回收?以及如何回收?对于哪些内存可以回收,常见的有引用计数算法和可达性分析算法来判断对象是否存活。可达性分析算法的基本思路是从GC Roots出发向下搜索,搜索走过的路径称为引用链,当一个对象到GC Roots没有任何引用链相连时,则称该对象不可达,也就是说可以回收了。常见的GC Roots对象有:
-
虚拟机栈中引用的对象
-
方法区中静态属性引用的对象
-
方法区中常量引用的对象
-
Native方法栈中引用的对象
Safepoint
Java虚拟机HotSpot的实现中,使用一组称为OopMap的数据结构来存放对象引用,从而可以快速且准确的完成GC Root扫描。但程序执行的过程中,引用关系随时都可能发生变化,而HotSpot虚拟机只会在特殊的指令位置才会生成OopMap来记录引用关系,这些位置便被称为Safepoint。换句话说,就是在Safepoint这个点上,虚拟机对于调用栈、寄存器等一些重要的数据区域里什么地方包含了什么引用是十分清楚的,这个时候是可以很快完成GC Roots的扫描和可达性分析的。HotSpot会在所有方法的临返回之前,以及所有Uncounted loop的循环回跳之前放置Safepoint。当需要GC时候,虚拟机会首先设置一个标志,然后等待所有线程进入Safepoint,但是不同线程进入Safepoint的时间点不一样,先进入Safepoint的线程需要等待其他线程全部进入Safepoint,所以Safepoint是会导致STW的。
Counted loop
JVM认为比较短的循环,所以不会放置Safepoint,比如用int作为index的循环。与其对应的是Uncounted loop。
Uncounted loop
JVM会在每次循环回跳之前放置Safepoint,比如用long作为index的循环。所以一个常见的问题是当某个线程跑进了Counted loop时,JVM启动了GC,然后需要等待这个线程把循环跑完才能进入Safepoint,如果这个循环是个大循环,且循环内执行的比较慢,而且不存在其他函数调用产生其他Safepoint,这时就需要等待该线程跑完循环才能从其他位置进入Safepoint,这就导致了其他线程可能会长时间的STW。
解 决 问 题
UseCountLoopSafepoints
-XX:+UseCountedLoopSafepoints这个参数会强制在Counted loop循环回跳之前插入Safepoint,也就是说即使循环比较短,JVM也会帮忙插入Safepoint了,用于防止大循环执行时间过长导致进入Safepoint卡住的问题。但是这个参数在JDK8上是有Bug的,可能会导致JVM Crash,而且是到JDK9才修复的,具体参考JDK-8161147。鉴于我们使用的是OpenJDK8,所以只能放弃该方案。
修改循环index为long型
上面的Safepoint Timeout日志已经明确指出了,进Safepoint慢的线程是RpcServer里的listener线程,所以在仔细读了一遍代码之后,发现其调用到的函数cleanupConnections里有个大循环,具体代码如下:
/** cleanup connections from connectionList. Choose a random range
* to scan and also have a limit on the number of the connections
* that will be cleanedup per run. The criteria for cleanup is the time
* for which the connection was idle. If 'force' is true then all
* connections will be looked at for the cleanup.
* @param force all connections will be looked at for cleanup
*/
private void cleanupConnections(boolean force) {
if (force || numConnections > thresholdIdleConnections) {
long currentTime = System.currentTimeMillis();
if (!force && (currentTime - lastCleanupRunTime) < cleanupInterval) {
return;
}
int start = 0;
int end = numConnections - 1;
if (!force) {
start = rand.nextInt() % numConnections;
end = rand.nextInt() % numConnections;
int temp;
if (end < start) {
temp = start;
start = end;
end = temp;
}
}
int i = start;
int numNuked =0;
while (i <= end) {
Connection c;
synchronized (connectionList) {
try {
c = connectionList.get(i);
} catch (Exception e) {return;}
}
if (c.timedOut(currentTime)) {
if (LOG.isDebugEnabled())
LOG.debug(getName() + ": disconnecting client " + c.getHostAddress());
closeConnection(c);
numNuked++;
end--;
//noinspection UnusedAssignment
c = null;
if (!force && numNuked == maxConnectionsToNuke) break;
}
else i++;
}
lastCleanupRunTime = System.currentTimeMillis();
}
}如注释所说,它会从connectionList中随机选择一个区间,然后遍历这个区间内的connection,并清理掉其中已经timeout的connection。但是,connectionList有可能很大,因为出问题的集群是个离线集群,会有多个MR/Spark Job来进行访问,而每个Job又会同时起多个Mapper/Reducer/Executer来进行访问,其每一个都是一个HBase Client,而Client为了性能考虑,默认连同一个RegionServer的connection数使用了配置4,这就导致connectionList里面可能存在大量的从client连接过来的connection。更为关键的是,这里循环的index是int类型,所以这是一个Counted loop,JVM不会在每次循环回跳的时候插入Safepoint。当GC发生时,如果RpcServer的listener线程刚好执行到该函数里的循环内部时,则必须等待循环跑完才能进入Safepoint,而此时其他线程也必须一起等着,所以从现象上看就是长时间的STW。
Debug的过程很曲折,但问题解决起来其实很简单,就是把这里的循环index从int类型改为long型即可,这样JVM会在每次循环回跳前插入Safepoint,即使GC时候执行到了循环内部,也只需执行到单次循环体结束便可以进入Safepoint,无需等待整个循环跑完。具体代码修改如下:
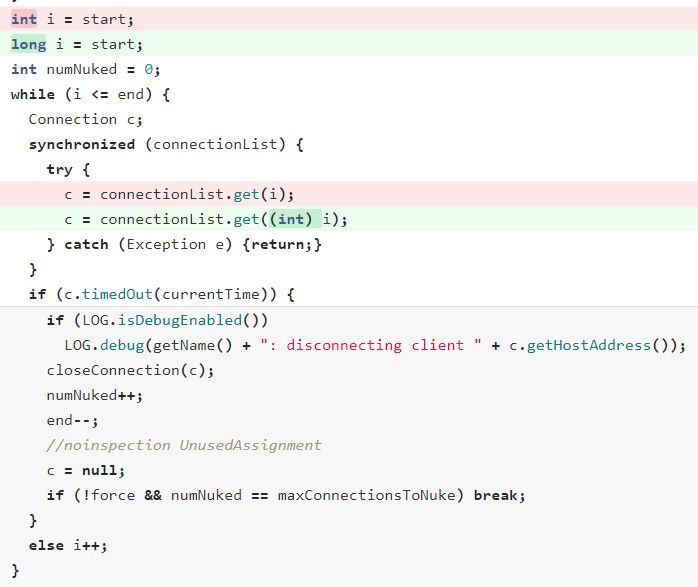
至此,问题得到解决。
最后,本文重点不是介绍Safepoint原理,主要是对一次线上真实Case的的踩坑记录,希望文中的JVM参数配置和Debug过程可以对大家有所帮助,如有错误,欢迎指正。
参考文档:
https://bugs.openjdk.java.net/browse/JDK-8161147
http://calvin1978.blogcn.com/articles/safepoint.html
https://xhao.io/2018/02/safepoint-1/
https://www.zhihu.com/question/29268019
《深入理解Java虚拟机》周志明著
本文首发于公众号“小米云技术”,转载请注明出处。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/234865.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
