大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
| 项目 | 内容 |
|---|---|
| 论文名 | MixMatch: A Holistic Approach to Semi-Supervised Learning |
| 作者 | David Berthelot,Nicholas Carlini,Ian Goodfellow,Avital Oliver,Nicolas Papernot,Colin Raffel |
| 主要内容 | 整合目前主流的半监督学习算法,提出MixMatch算法,主要创新点在对无标签样本进行低熵标签的猜测过程,以及使用修改的MixUp算法将有标签数据和无标签数据混合。 |
| 发表时间 | 2019年 |
Abstract
作者整合了目前主流的半监督学习算法,然后提出了新的MixMatch算法,该算法对经过数据增强的无标签样本进行低熵标签的猜测,并使用MixUp将有标签数据和无标签数据混合在一起。算法在许多数据集上获得了SOTA的结果。
Introduction
深度神经网络依赖大量标签数据,但标签数据采集困难,而无标记数据更容易获得。
无监督学习就是为了减轻对标签数据的需求并使模型可以利用无标签数据的。近期的许多无监督学习方法添加了一个在无标签数据上计算的损失项,鼓励模型可以更好地推广到未知的数据上去。损失项可分为三类:
- 熵最小化——它鼓励模型输出对于无标记数据有把握的预测;
- 一致性正则化——它鼓励模型在输入存在扰动的情况下产生相同的输出;
- 通用正则化——它鼓励模型更好地推广并且避免过拟合于训练集。
作者表示,MixMatch引入了一个单一的损失,优雅地结合了这些主流的半监督学习方法。与之前的方法不同,MixMatch同时对准了所有的属性,获得了如下好处:
- MixMatch在所有标准的图像基准上获得了SOTA的结果,并且在CIFAR-10上将错误率降低了4倍;
- 作者在消融实验中将展示MixMatch比其各部分之和要更好;
- MixMatch对于私有学习很有帮助,它使PATE框架中的学生获得了SOTA的结果,同时加强了隐私保障和准确性。
总的来说,MixMatch引入了一个对于无标签数据的统一损失项,它在维持一致性并与传统正则化技术保持兼容性的同时减少了熵。
Related Work
下面将采用一个通用的模型表示, p m o d e l ( y ∣ x ; θ ) p_{model}(y|x;\theta) pmodel(y∣x;θ),它对于一个输入 x x x使用参数 θ \theta θ在类标签 y y y上产生一个分布。
1. 一致性正则化
监督学习中一个通用的正则化技术是数据增强,它在假定类别语义不受影响的情况下对输入进行转换。粗略的说,这可以通过生成一个近乎无限的,新的,修改过的数据流来人为地扩大训练集的大小。一致性正则化将数据增强应用于半监督学习,通过借助一个思想:分类器应该对一个无标记的样本输出同样的类别分布,即使它已经经过了增强。更正式的说,一致性正则化要求一个无标记样本 x x x应该被分类为与他的一个增强 A u g m e n t ( x ) Augment(x) Augment(x)一样。
在最简单的情况下,对于一个无标签的点 x x x,之前的工作添加了一个损失项:
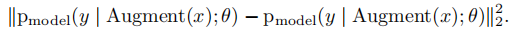

A u g m e n t ( x ) Augment(x) Augment(x)是一个随机转换,所以式中的两项并不相同。“Mean Teacher”将其中的一项替换为一个使用原模型参数值的指数滑动平均的模型的输出。这类方法的一个缺点是它们使用了特定领域的数据增强策略。“Virtual Adversarial Training”(VAT)解决了这个问题,通过计算一个加性噪声,并应用在输入上来最大限度的改变输出分类的分布。
MixMatch通过使用对图像的标准数据增强(随机水平翻转和裁剪)来利用一种形式的一致性正则化。
2. 熵最小化
在许多半监督学习方法中,一个潜在的通用假设是分类器的决策边界不应该通过边缘数据分布的高密度区域。一个执行这一假设的方法是要求分类器在无标签数据上输出低熵的预测。
MixMatch通过在无标签数据的目标分布上使用一个“锐化”函数来隐式地实现了熵最小化。
3. 传统的正则化
正则化指的是对一个模型施加约束,使其更难记住训练数据并且因此使它更好的推广到未知数据上去的一般方法。作者使用权重衰减,它惩罚模型参数的 L 2 L_2 L2范数。使用MixUp鼓励样本“之间”的凸行为。作者使用MixUp作为一个正则化器(将其应用于标签数据)以及半监督学习方法(将其应用于无标签数据)。
MixMatch
给定一个有标签样本的批次 χ \chi χ以及它们的one-hot标签( L L L个可能的标签中的一个)和一个相同大小的无标签样本的批次 U U U,MixMatch生成一个经过处理的增强过的标签样本的批次 χ ′ \chi’ χ′和一个增强过的包含“猜测”标签的无标签样本的批次 U ′ U’ U′。 U ′ U’ U′和 χ ′ \chi’ χ′接下来被分别用于计算有标签和无标签的损失项。综合损失 L L L如下定义:
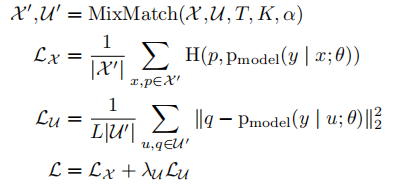

这里 H ( p , q ) H(p,q) H(p,q)表示分布 p 和 q p和q p和q的交叉熵, T , K , α , 和 λ ′ T,K,\alpha,和\lambda’ T,K,α,和λ′是超参数。下面是完整的MixMatch算法。

1. 数据增强
在有标签数据和无标签数据上均应用数据增强。对于有标签数据 χ \chi χ的批次中的每一个 x b x_b xb,生成一个转换过的版本 x ^ b = A u g m e n t ( x b ) \hat{x}_b=Augment(x_b) x^b=Augment(xb)。对于无标签数据的批次中的每一个 u b u_b ub,生成 K K K个增强 u ^ b , k = A u g m e n t ( u b ) , k ∈ ( 1 , . . . , K ) \hat{u}_{b,k}=Augment(u_b),k\in(1,…,K) u^b,k=Augment(ub),k∈(1,...,K)。使用这些独立的增强去为每一个 u b u_b ub生成一个“猜测的标签” q b q_b qb,通过下一小节所述的过程。
2. 标签猜测
对于 U U U中的每一个无标签样本,MixMatch使用模型的预测生成一个样本标签的“猜测”。这个猜测接下来会被用于无监督损失项。
首先计算模型对于 u b u_b ub的所有 K K K个增强的预测分布的平均值:
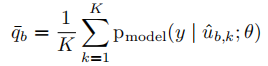
Sharpening. 在生成标签猜测的过程中,作者添加了额外的一步,受到熵最小化在半监督学习中的成功的鼓舞。给定对于增强的预测的平均 q ‾ b \overline{q}_b qb,使用一个锐化函数来减少标签分布的熵。定义如下:
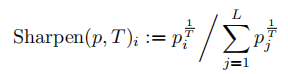
这里 p p p是一些输入分类分布(在MixMatch中, p p p是增强的分类预测值平均), T T T是一个超参数。当 T → 0 T\rightarrow0 T→0时, S h a r p e n ( q ‾ b , T ) Sharpen(\overline{q}_b,T) Sharpen(qb,T)的输出将接近one-hot分布。因为我们接下来将使用 q b = S h a r p e n ( q ‾ b , T ) q_b=Sharpen(\overline{q}_b,T) qb=Sharpen(qb,T)作为模型对于 u b u_b ub的一个扩增的预测,减小这个温度 T T T将鼓励模型产生低熵预测。
3. MixUp
作者使用MixUp进行半监督学习,不同于以往的SSL工作,作者将有标签的样本和无标签的样本加上标签猜测都混合起来。为了使其能与分别的损失项兼容,作者定义了一个MixUp的稍微修改的版本。对于一组两个包含它们相应标签概率的样本 ( x 1 , p 1 ) , ( x 2 , p 2 ) (x_1,p_1),(x_2,p_2) (x1,p1),(x2,p2)我们通过下式计算 ( x ′ , p ′ ) (x’,p’) (x′,p′):
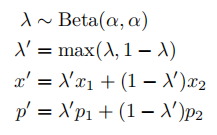
这里 α \alpha α是一个超参数。原始的MixUp省略了第二步(即它设置 λ ′ = λ \lambda’=\lambda λ′=λ)。给定在同一个批次中被连接的有标签和无标签样本,我们需要保留这个批次的顺序来适当地计算单独的损耗组件。这在上式第二部被实现,它确保 x ′ x’ x′距离 x 1 x_1 x1比距离 x 2 x_2 x2更近。为了应用MixUp,首先收集所有的有标签数据以及它们的标签和所有的无标签数据以及它们的猜测标签:
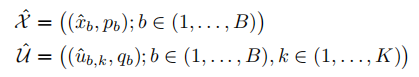
接着,融合这些收集并且打乱结果去形成 W W W,它将作为一个MixUp的数据源。对于 χ ^ \hat{\chi} χ^中 i t h i^{th} ith样本-标签对,计算 M i x U p ( χ ^ i , W i ) MixUp(\hat{\chi}_i,W_i) MixUp(χ^i,Wi)并且将结果添加进入集合 χ ′ \chi’ χ′。计算 U i ′ = M i x U p ( U ^ i , W i + ∣ χ ^ ∣ ) U_i’=MixUp(\hat{U}_i,W_{i+|\hat{\chi}|}) Ui′=MixUp(U^i,Wi+∣χ^∣),其中 i ∈ ( 1 , . . . , ∣ U ^ ∣ ) i\in(1,…,|\hat{U}|) i∈(1,...,∣U^∣),使用 W W W中剩余的未被用于构建 χ ′ \chi’ χ′的部分。
总的来说,MixMatch将 χ \chi χ转换成 χ ′ \chi’ χ′,一个包含了数据增强和应用了MixUp的有标签样本的集合(有可能和一个无标签样本混合)。类似的, U U U被转换成 U ′ U’ U′,一个对于每个无标签数据的多个数据增强以及相应的猜测标签的集合。
4. 损失函数
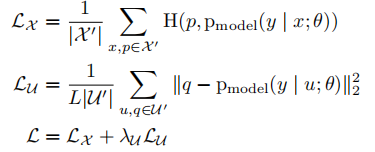
对于 χ ′ \chi’ χ′,计算标签和模型预测之间的交叉熵;对于 U ′ U’ U′,计算预测和猜测标签之间的 L 2 L_2 L2损失。使用 L 2 L_2 L2损失是因为,它是有界限的,并且对于不正确的预测不那么敏感。这里不通过计算猜测的标签来传播梯度。
5. 超参数
MixMatch中的大部分超参数都可以是固定的,不需要被调整。特别地,对于所有的实验,作者设置 T = 0.5 T=0.5 T=0.5以及 K = 2 K=2 K=2。另外,作者仅仅在每个数据集上调整 α \alpha α和 λ u \lambda_u λu;作者发现 α = 0.75 和 λ u = 100 \alpha=0.75和\lambda_u=100 α=0.75和λu=100是一个调整的好的起始点。在所有的实验中,作者在前16000步的训练过程中线性增加 λ u \lambda_u λu到它的最大值。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/234624.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...