大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
前言:
论文:https://arxiv.org/pdf/2010.13415.pdf
代码:GitHub – 131250208/TPlinker-joint-extraction
这篇论文是最新的基于joint方式进行的联合抽取实体关系的模型。主要创新点是提出了新的标注数据方法,具体可以看论文,本篇的主要目的是解读代码逻辑,更多想法细节可以先看论文。
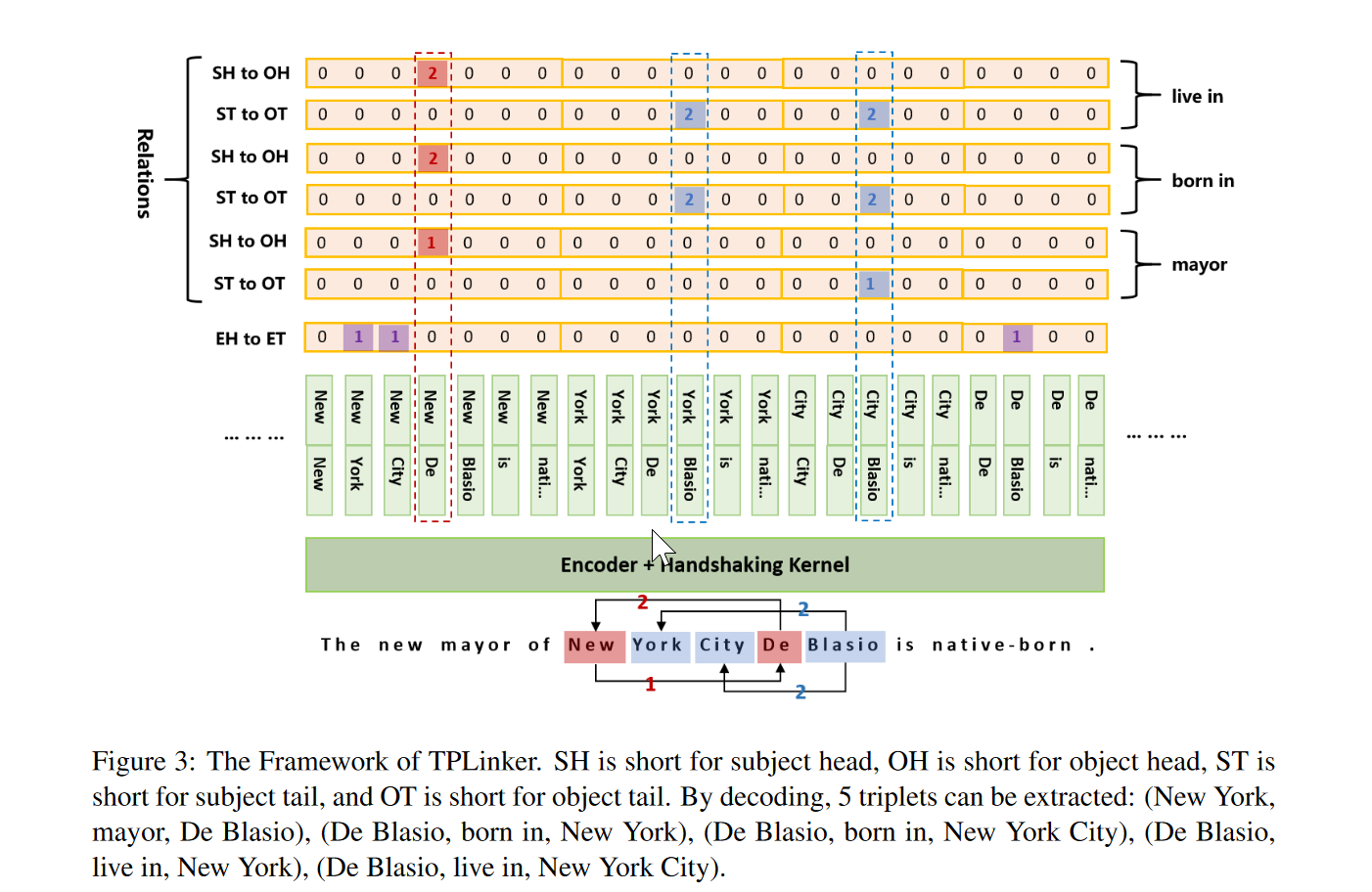

我们还是重点分两部分来看:输入数据部分+模型
输入数据部分
我们都假设seq的长度都是5
追踪train_dataloader–>indexed_train_data–>data_maker–>DataMaker4Bert
DataMaker4Bert位于tplinker.py
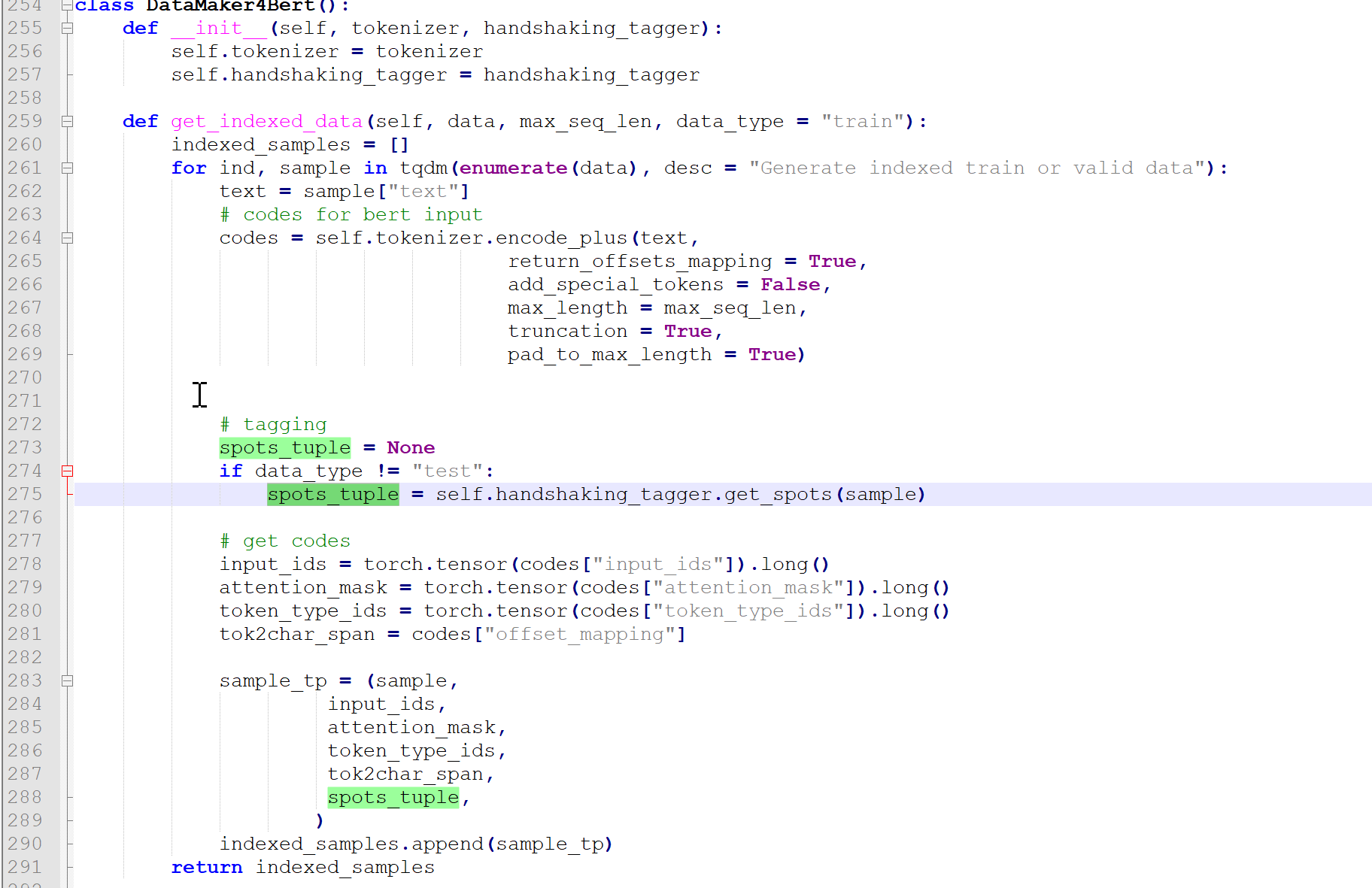
其输入就是tokenizer和handshaking_tagger,其中tokenizer比较好理解就是bert输入前的编码id,重点看一下handshaking_tagger,用到了它的get_spots类函数
追踪handshaking_tagger–>tplinker.py下的HandshakingTaggingScheme类
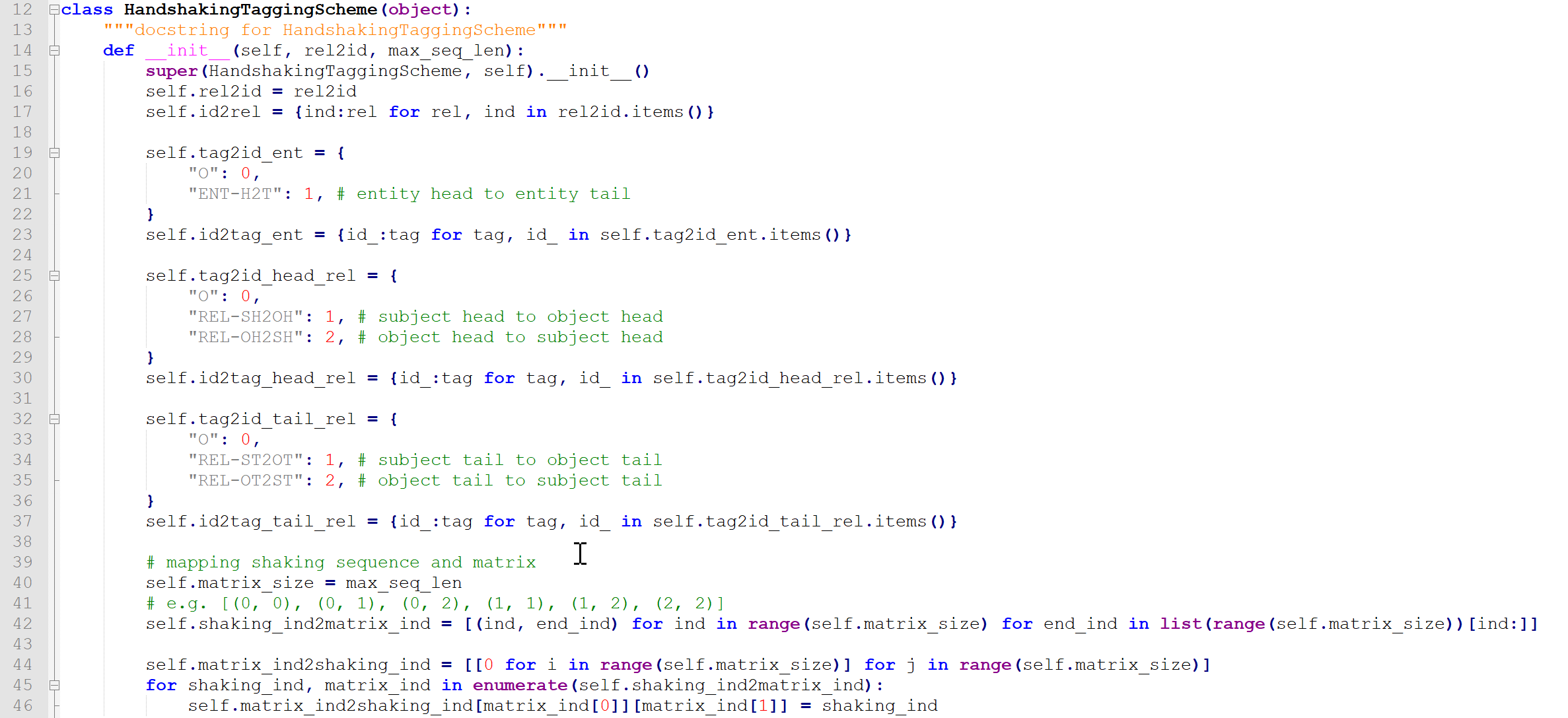
19-23就是实体标签就是2种,26-37行就是关系标签三种(0,1,2),44行的shaking_ind2matrix_ind就是上三角铺平序列
self.matrix_ind2shaking_ind就是没有优化前的完整矩阵,是一个二维矩阵,其上位三角每个元素储存着上三角铺平序列的相对应的位置序号
看他的get_spots函数
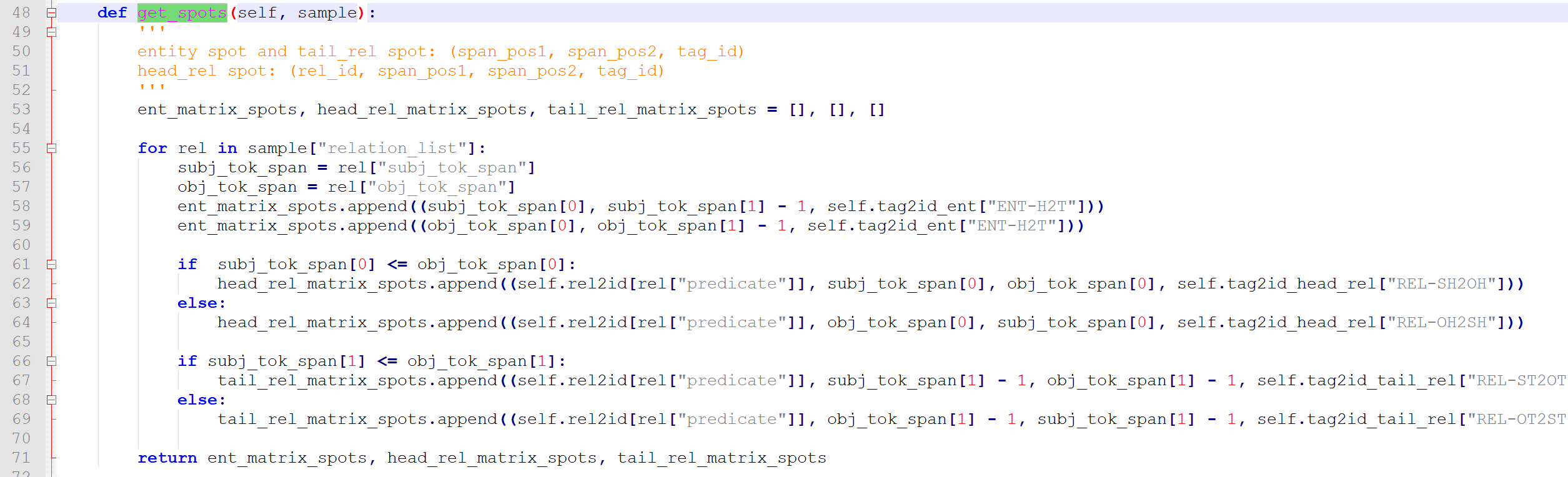
其56-59行就是将实体保存起来,形式是:【起始位置,尾部位置,实体标签(1)】
61-64行是实体头部存储,形式是:【关系类别,实体_1 头部,实体_2头部,关系标签(1,2)】
66-69行是实体尾部存储,形式是:【关系类别,实体_1 尾部,实体_2尾部,关系标签(1,2)】
最后我们来看dataloader总返回是什么即DataMaker4Bert的返回值:
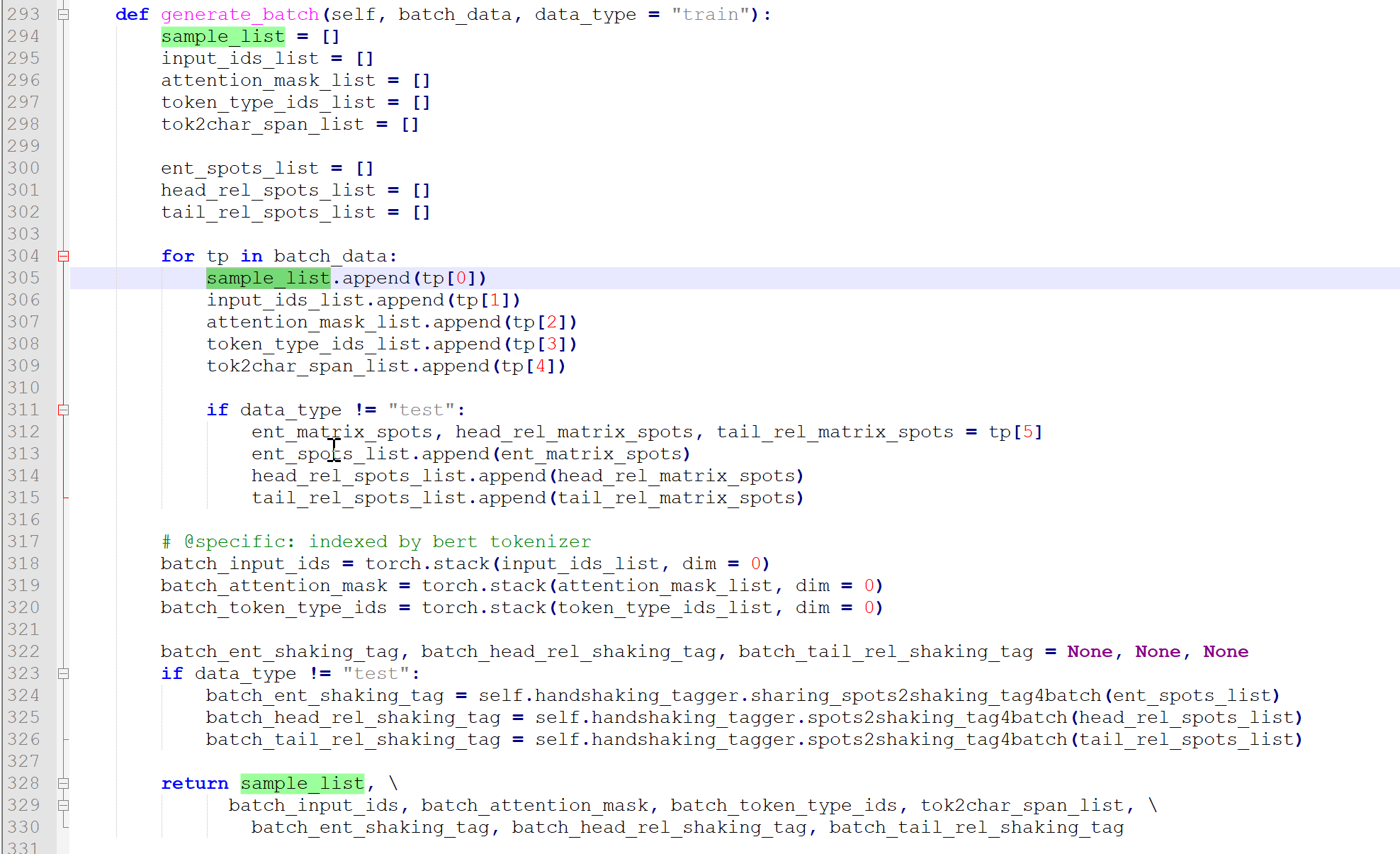
sample_list, batch_input_ids, batch_attention_mask, batch_token_type_ids, tok2char_span_list基本就是通过BertTokenizerFast生成的id。
重点来看batch_ent_shaking_tag, batch_head_rel_shaking_tag, batch_tail_rel_shaking_tag这三个
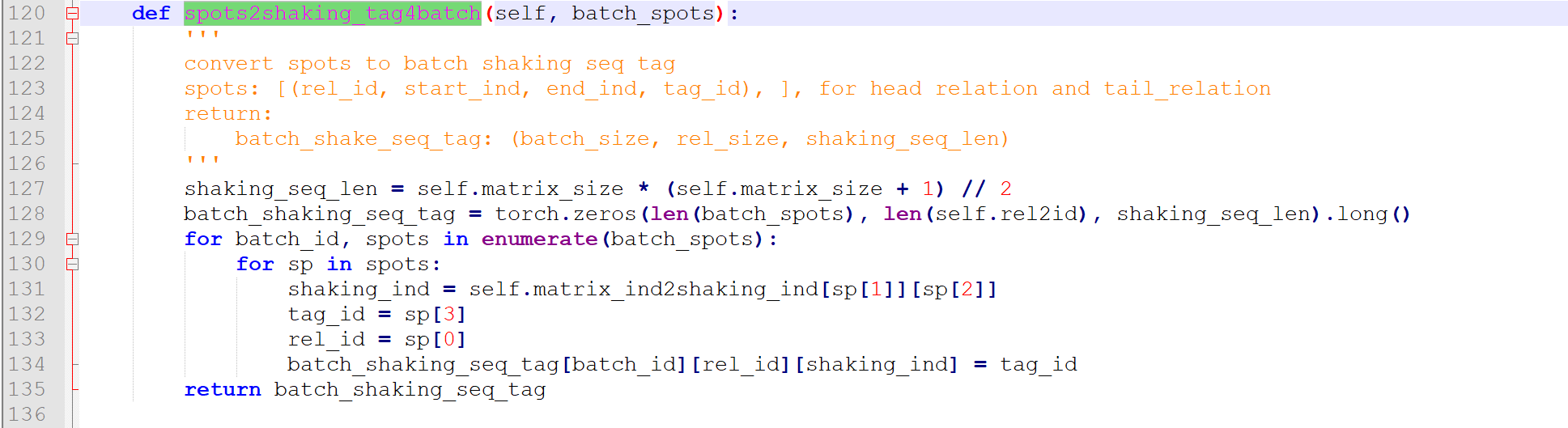
其中实体batch_ent_shaking_tag用到了handshaking_tagger的sharing_spots2shaking_tag4batch的函数

生成的batch_shaking_seq_tag维度就是[batch,5+4+3+2+1]
111-112行就是声明这么一个tensor。
113-117行就是对这个序列标注。
其中关系batch_head_rel_shaking_tag, batch_tail_rel_shaking_tag用到了handshaking_tagger的spots2shaking_tag4batch的函数,其实和sharing_spots2shaking_tag4batch差不多,但是其得到的batch_shaking_seq_tag维度是:
【batch,n,5+4+3+2+1】
n 是关系总数
即batch_head_rel_shaking_tag, batch_tail_rel_shaking_tag的维度都是【batch,n,5+4+3+2+1】
总结一下最后的返回值就是:

模型
tplinker/train.py
核心入口就是389-393
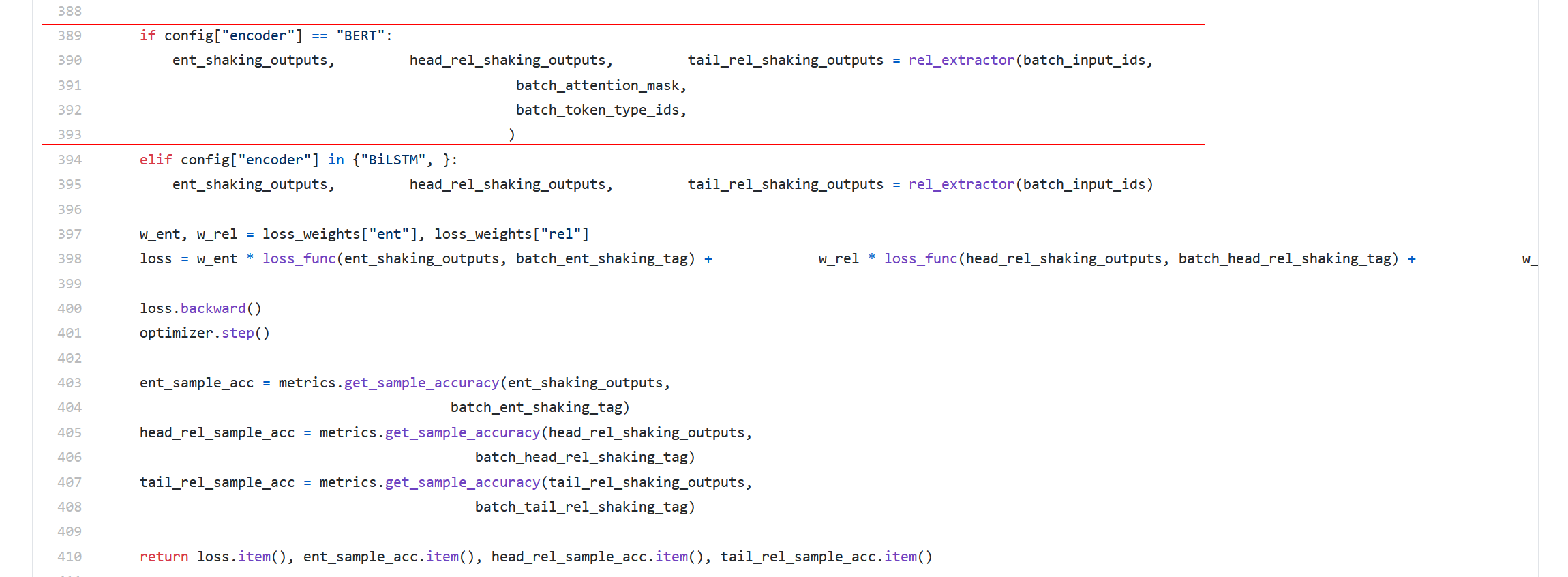
即tplinker.py下的TPLinkerBert
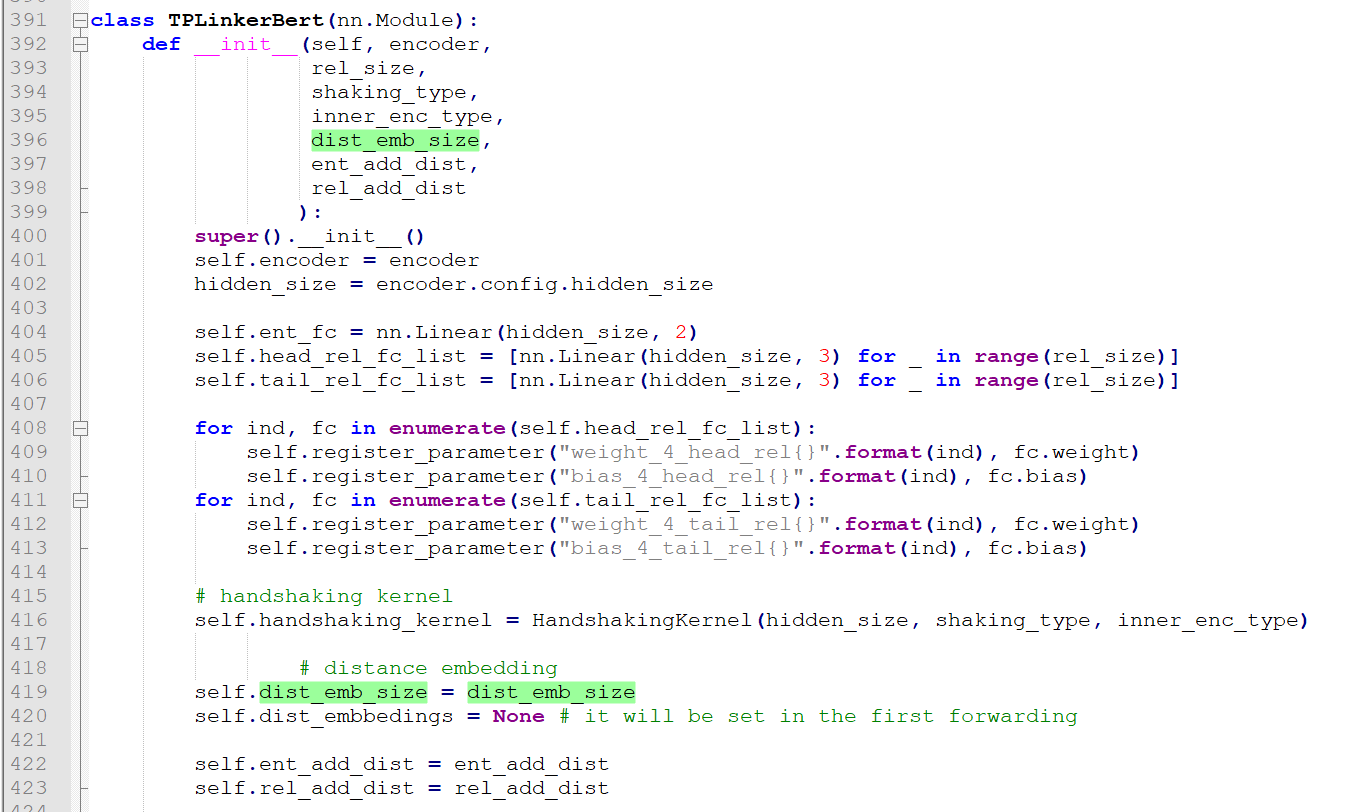
404行就是为了做实体预测最后维度是 2(标签就是0和1)
405是关系头部的一个全连接(标签有三个0,1,2),注意每一个关系有一个独立的MLP层所以self.head_rel_fc_list是一个列表
406就是关系尾部啦
上述就是关系和实体关系预测了,可以看到实体和各个关系都单独被分了一个mlp层,假设有2中关系,其实上面就有5个MLP层即 :1个实体预测层+(1个头部层+1个尾部层)*2
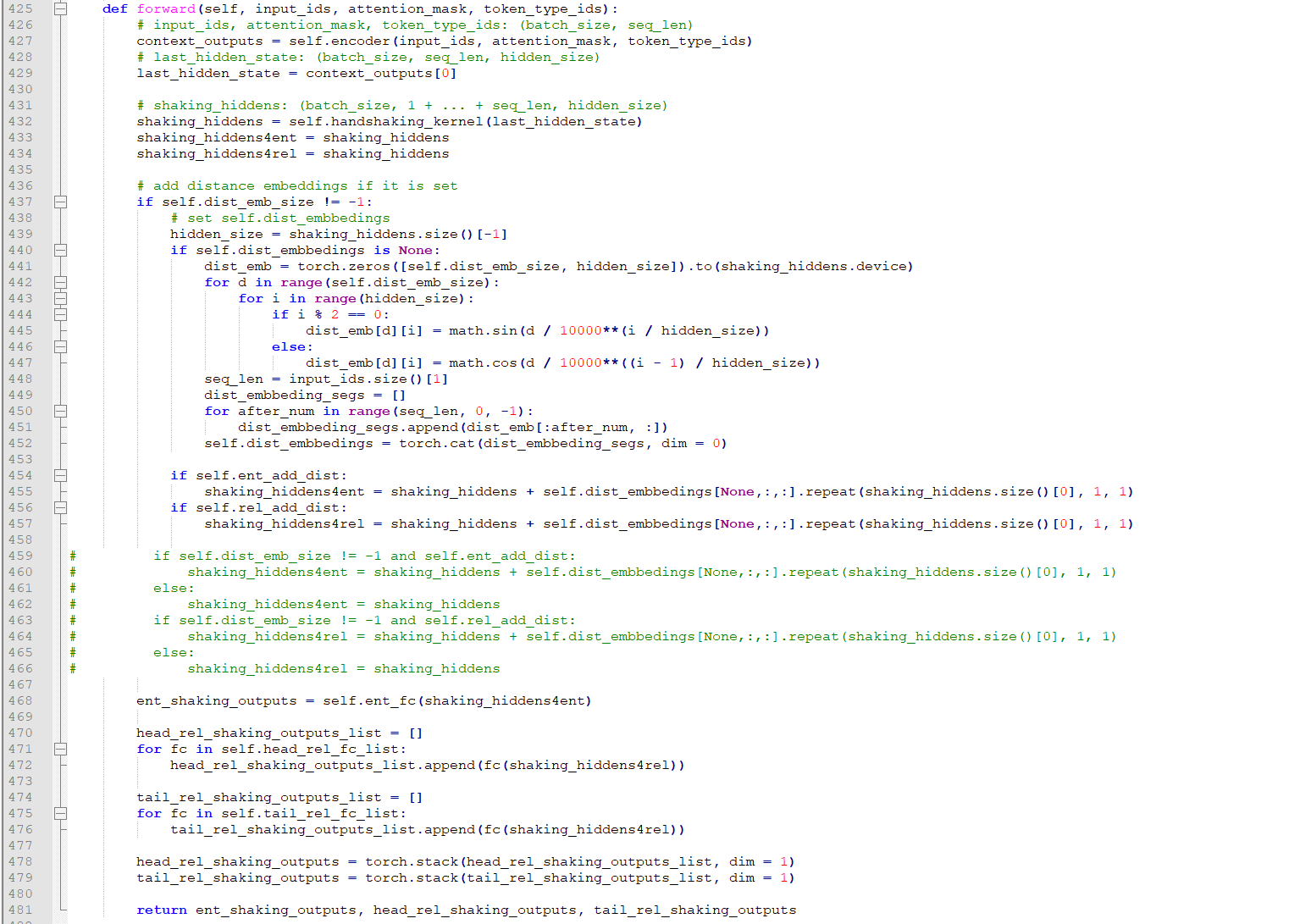
这是上游,底层的话大家都一样,共享编码(有很多种,bert啦,Bilstm,这里我们看bert),对应到代码 ,shaking_hiddens4ent就是共享编码
468行就是用这个编码过实体抽取的mlp层得到预测结果
471-472行就是用这个编码过各个关系的头部的MLP层,得到两个关系实体的头部预测
474-476行就是用这个编码过各个关系的尾部的MLP层,得到两个关系实体的尾部预
好啦,下面来看共享编码shaking_hiddens4ent是怎么来的,根据432行–>416行得到是common.components.py 里面的HandshakingKernel,其核心代码:

输入的seq_hiddens维度是[batch,seq_len, hidden_size],其获得就可以简单看成是一句话经过bert后的编码,这里使用的是transformers这个python包,用的其AutoModel的即train.py下的278行,说白了就是用bert作为底层的encoder,下面假设seq_len是5

回到HandshakingKernel(上上副图),这里不得不讲一下论文中的优化到上三角,假设我们一句话有5个单词,本来矩阵是5*5,但是优化后只要上三角就可以啦,其实第一行是5列,第二行就是4列,第三行是3列,第四行是2列,第四行是1列,然后把他们平铺成一个序列即5+4+3+2+1.
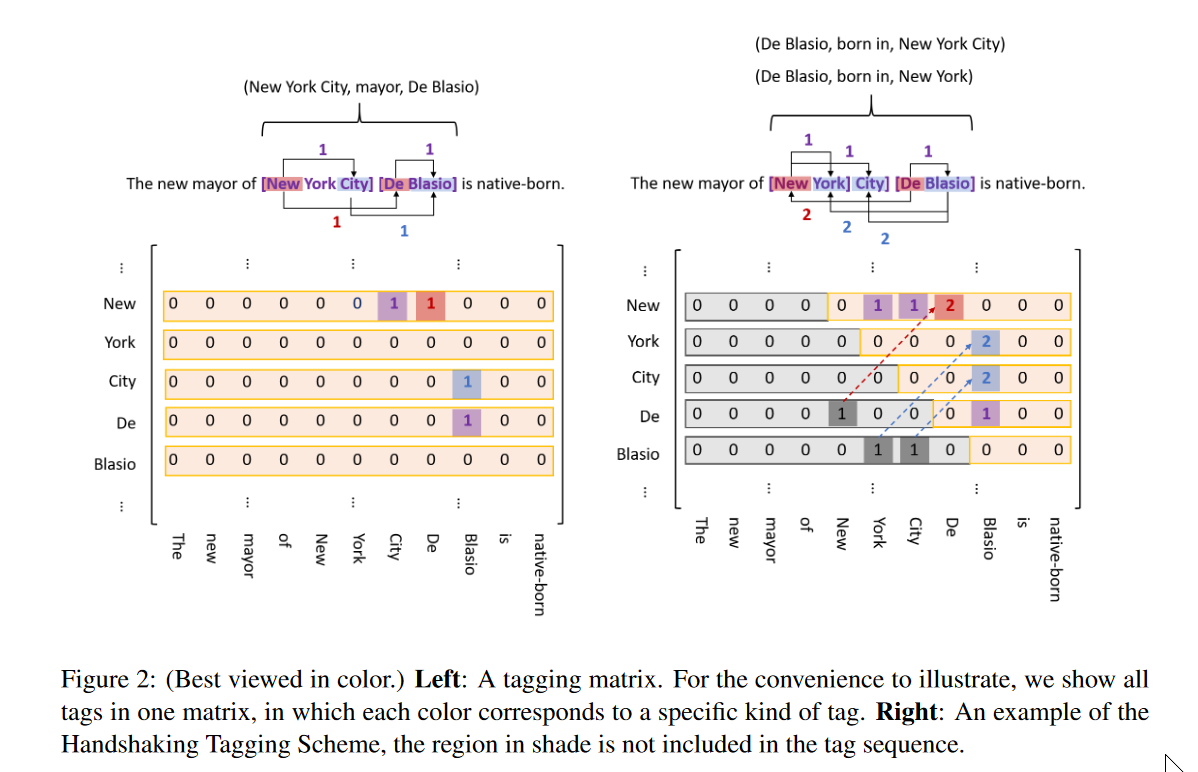
进一步对应到论文的部分就是:

从当前往后看即5,4,3,2,1 主要这里是j>=i就是要包括自身,因为自身单独一个单词可能就是一个实体
所以HandshakingKernel主要就是在做这个事情:
(1)代码中144行其实就是一个个遍历行,146行就是从当前取到最后,当是第一行时,ind是0,hidden_each_step维度是[batch,1,hidden_size]代表整句话第一个word的编码,为了进行拼接147行repeat_hiddens在第二个维度进行了复制,维度变成了[batch,5,hidden_size],相当于将当前单词编码复制了5份,visible_hiddens维度就是[batch,5,hidden_size],是从当前单词往后(包括自身)各个单词的编码,现在要计算得到上三角第一行的编码,即150行的shaking_hiddens,将当前单词和其后的各个单词的编码进行concat维度是[batch,5,hidden_size*2],然后151行又过了一个MLP层,转化为了shaking_hiddens [batch,5,hidden_size]
(2)当是上三角第二行时,ind是1,hidden_each_step维度是[batch,1,hidden_size]代表第二个单词的编码,visible_hiddens维度就是[batch,4,seq_len],代表其后的各个单词的编码,为了拼接repeat_hiddens维度是[batch,4,hidden_size]即将hidden_each_step第二个单词复制了4份,shaking_hiddens此时是[batch,4,hidden_size*2],然后151行又过了一个MLP层,转化为了shaking_hiddens[batch,4,hidden_size]
(3)同理当是上三角第三行时,最后shaking_hiddens维度是[batch,3,hidden_size],以此例推
所以163行的shaking_hiddens_list是一个列表,就是记录上三角一行行的编码,当句子有5个单词时,该列表有五个元素,维度分别是:
[batch,5,hidden_size],[batch,4,hidden_size],[batch,3,hidden_size],[batch,2,hidden_size],[batch,1,hidden_size]
161行long_shaking_hiddens在第二个维度进行concat即维度是:[batch,5+4+3+2+1,hidden_size],平铺变成了一个sequence。
long_shaking_hiddens就是公共编码就是shaking_hiddens4ent。
再回到tplinker.py下的TPLinkerBert
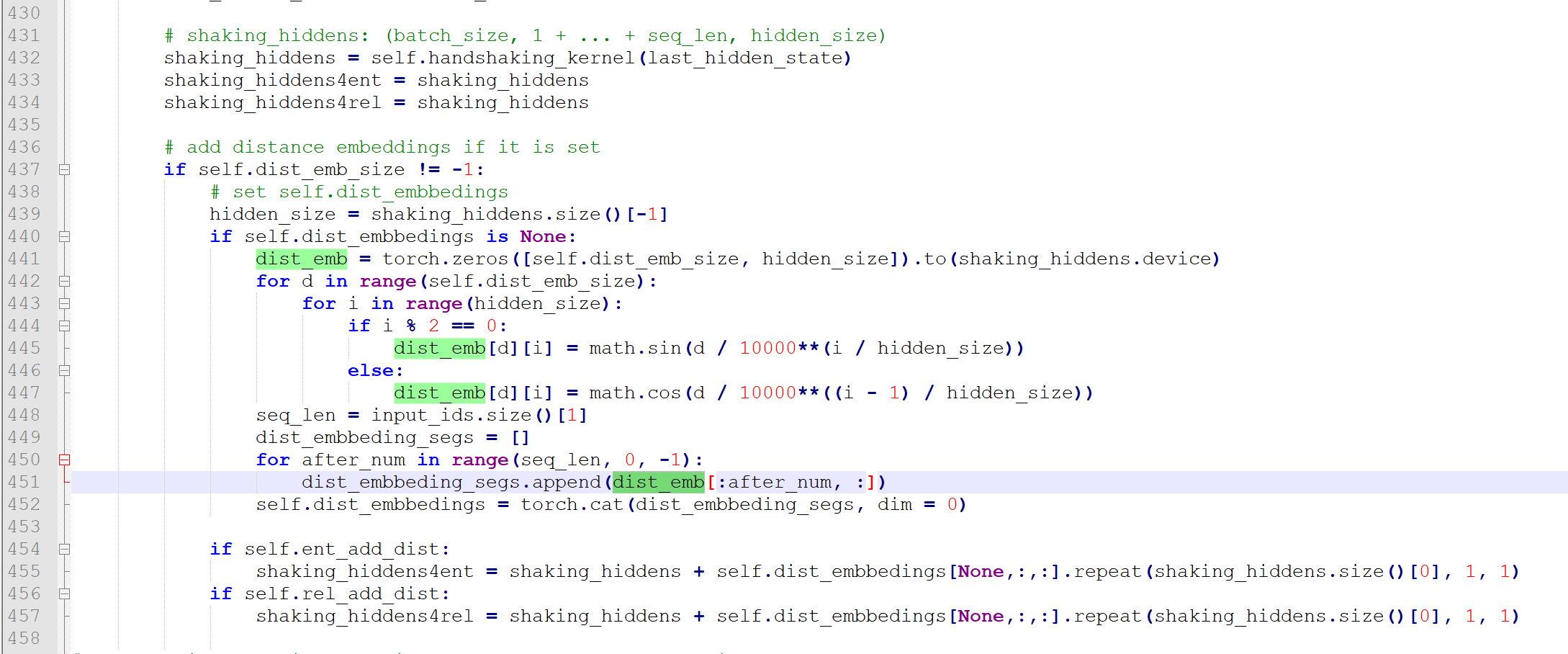
432行shaking_hiddens就是上述的输出,维度是是[batch,5+4+3+2+1,hidden_size],437-457行是加距离emb。
440-447就是一个初始化(可以看到是用sin,cos初始化的,是不是想起来训练word2vec的初始化啦)
注意450-452其实就是将距离emb也平铺成成一个序列,方便和shaking_hiddens运算。用了类似HandshakingKernel的手段进行平铺,451行的dist_emb的维度是[5,hidden_size],每一个距离一个emb(5中距离,0-4),上三角第一行的覆盖的距离范围是0-4,所以451行dist_embbeding_segs列表第一个元素维度是[5,hidden_size],上三角第二行的覆盖的距离范围就只有0-3,所以451行dist_embbeding_segs列表第一个元素维度是[4,hidden_size],注意dist_embbeding_segs第一个元素的前四个距离的编码和
dist_embbeding_segs第二个元素的四个距离的编码其实是一样的。一共就5种距离编码!!!
452行的self.dist_embbedings就是concat成一个序列即其维度是[5+4+3+2+1,hidden_size]
所以455行shaking_hiddens是[batch,5+4+3+2+1,hidden_size] ,self.dist_embbedings经过在第一维(batch)repeat后也是[batch,5+4+3+2+1,hidden_size],进行相加,就得到了加位置编码的最终共享编码。再往下就是我们一开始说的实体和关系网络

ent_shaking_outputs:实体预测 [batch,5+4+3+2+1,2]
head_rel_shaking_outputs, 关系实体头部预测 [batch,n,5+4+3+2+1,3]
tail_rel_shaking_outputs关系实体尾部部预测 [batch,n,5+4+3+2+1,3]
注意这里的n代表的是关系总数,478和479就是将各个关系的结果concat起来的,其实
head_rel_shaking_outputs_list和tail_rel_shaking_outputs_list都是一个有n个元素的列表,为一个元素的维度都是[batch,5+4+3+2+1,3]
至此我们得到了预测结果
下面我们看两方面:解码得到三元组和计算Loss
(1)解码
我们再来看一下通过这三个结果ent_shaking_outputs、head_rel_shaking_outputs、tail_rel_shaking_outputs怎么解码出实体关系
即tplinker.py下的HandshakingTaggingScheme类,其方法就是 decode_rel_fr_shaking_tag
主要算法流程就是:

总结来说就是:
4-8 先进行实体抽取得到字典D(key是实体头部,value是实体尾部)
第9-35就开始一个一个遍历关系
10-16 通过关系得到有关系的两个实体的尾部得到E
18-26 先通过关系得到有关系的两个实体的头部,然后结合字典D,可以得到后续两个实体尾部set(s),set(o),这是真实的的抽取的实体
27-34 通过set(s),set(o)看看在不在关系抽取实体的E里面,如果在就是成功抽取了一条三元组。
代码是:
其输入可以从Evaluation.ipynb看
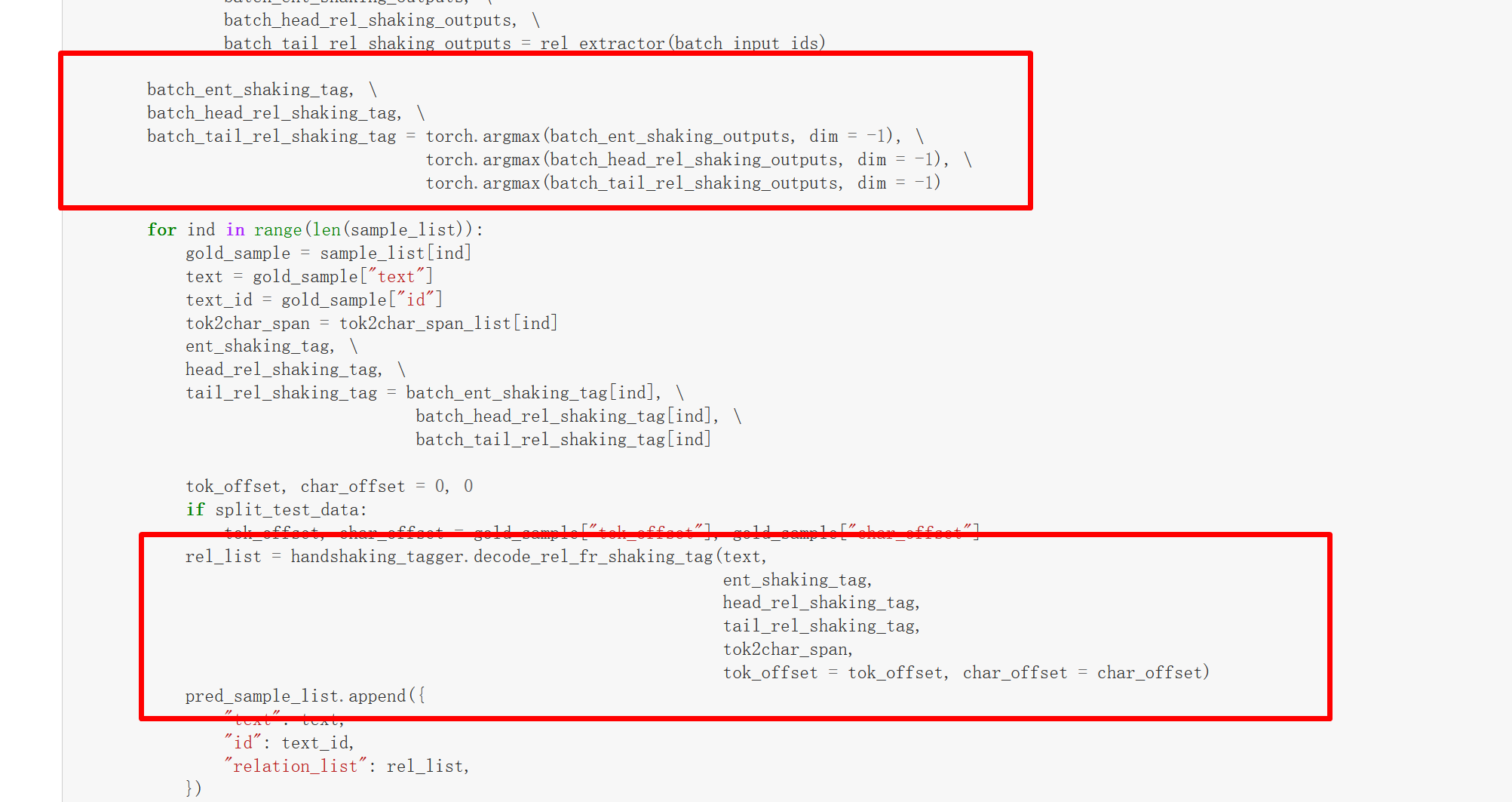
通过argmax其实就是取出预测的结果
ent_shaking_tag 【batch,5+4+3+2+1,1】 head_rel_shaking_tag【batch,n,5+4+3+2+1,1】 tail_rel_shaking_tag【batch,n,5+4+3+2+1,1】
这就是decode_rel_fr_shaking_tag的输入:

先用self.get_sharing_spots_fr_shaking_tag进行解析

self.shaking_ind2matrix_ind是: [(0, 0), (0, 1), (0, 2), (1, 1), (1, 2), (2, 2)]即上三角
所以spots就是相当于是一个列表,每一个元素就是类似(0,0,预测标签)、(0,1,预测标签)等。
接下来就是看tag_id(预测标签)是不是预测的是不是实体,是的话就保存到head_ind2entities(对应到论文算法就是D字典),形式大概就是{3:[4,6]}
两个实体,都是以从位置3开始的,分别以位置4和6结束。
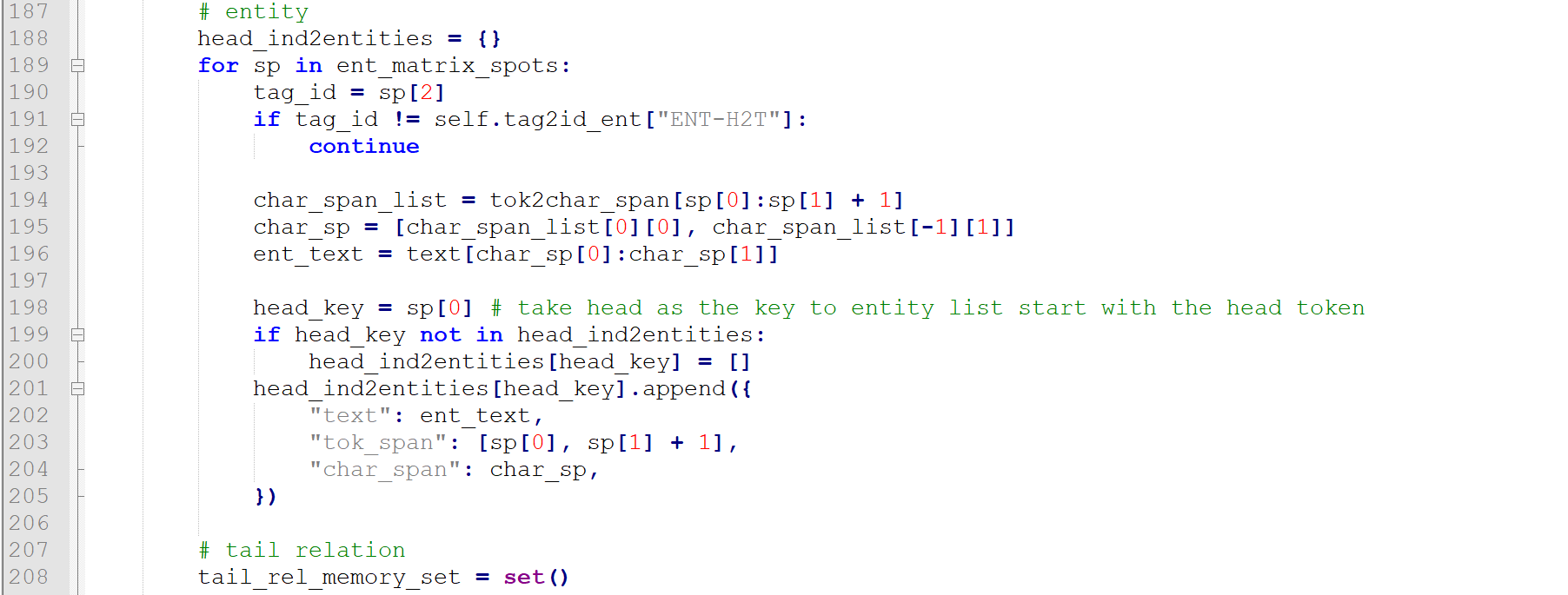
接下来根据关系解析出有关系一对实体的尾部,保存在tail_rel_memory_set:形式类似“1-10-30”,第一种关系,对应的一对实体尾部分别是10和30(对应论文算法的E)

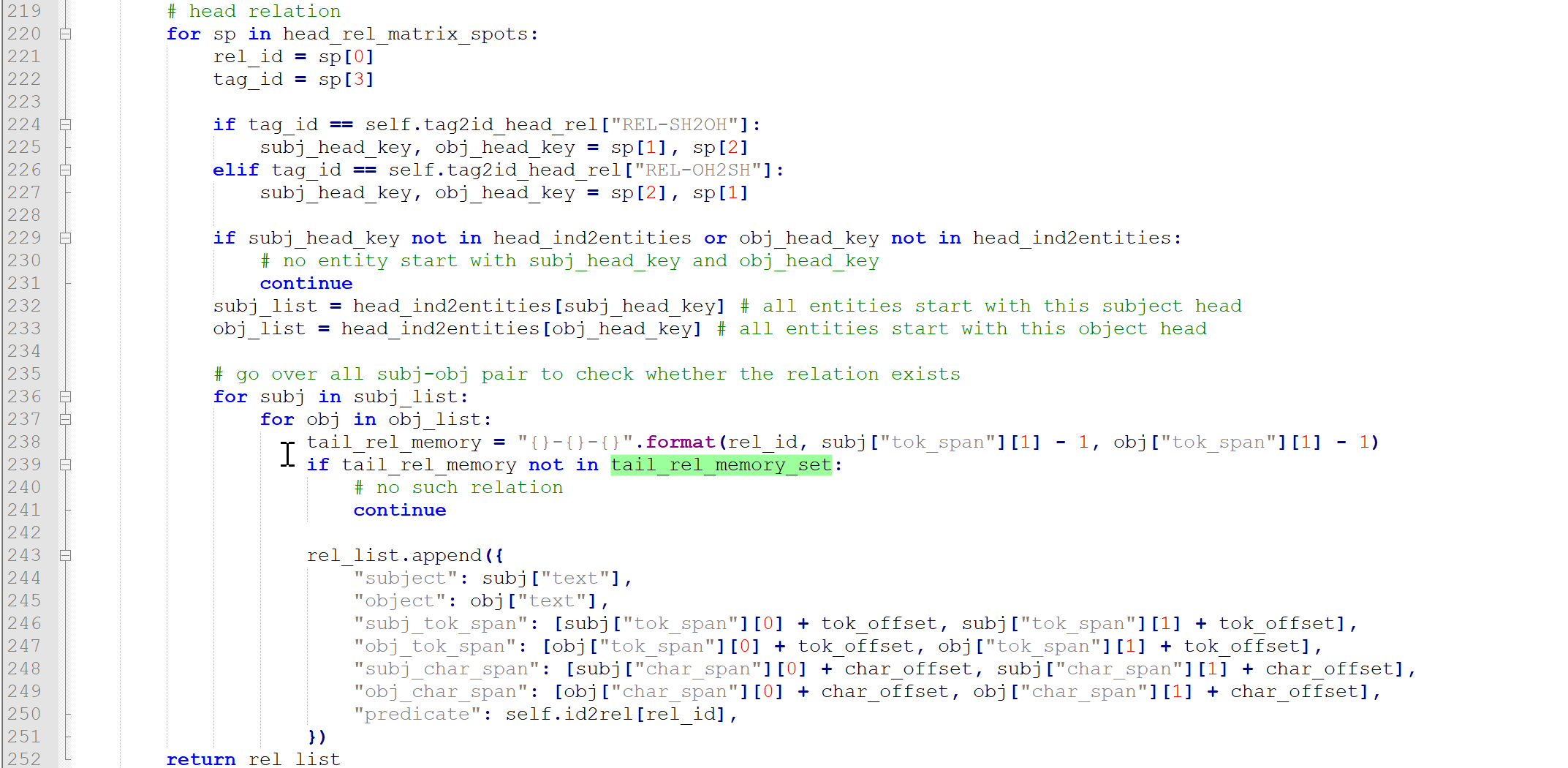
接下来224-227根据关系解析出有关系一对实体的头部,但是229行会看一看是不是在预测的实体(D字典)当中,如果不在就跳过了,如果在的话,取其value,即取以该位置开头的所有实体,对应的是232行和233行的subj_list、obj_list,接着看236行和237行的subj和obj这些都是预测出的真实实体尾部,238是根据关系推断出的实体尾部,看看subj和obj合起来是不是匹配,不匹配的话跳过,匹配的话就成功抽取一条三元组保存了。
(2)计算loss

398行可以看到就是将实体loss和关系预测的实体对头实体Loss和关系预测的实体对尾实体Loss进行加权得到Loss,权重的大小部分:
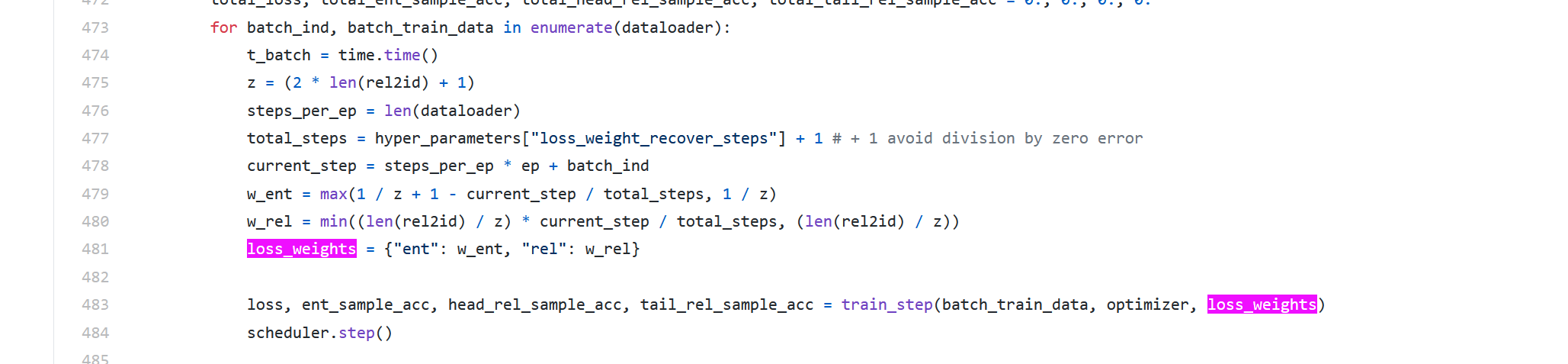
w_ent就是实体权重
w_rel是关系权重
动态权重,通过479-480行可以看到,随着step加大,w_ent的权重递减,w_rel权重递增。也就是开始关注实体,先保证实体抽准确,后面再越来越关注关系抽取
注意:我们的模型输出:
ent_shaking_outputs : [batch, 5+4+3+2+1,2]
head_rel_shaking_outputs :[batch,n,5+4+3+2+1,3]
tail_rel_shaking_outputs : [batch,n,5+4+3+2+1,3]
label是:
batch_ent_shaking_tag :[batch, 5+4+3+2+1]
batch_head_rel_shaking_tag :[batch, n,5+4+3+2+1]
batch_tail_rel_shaking_tag :[batch, n,5+4+3+2+1]
loss函数是:就是通过view转化维度计算交叉熵。

总结
(1)数据部分
函数主要是两个:tplinker.py下的DataMaker4Bert和HandshakingTaggingScheme
DataMaker4Bert里面一个比较重要的就是生产上三角序列,其实其用的是HandshakingTaggingScheme类函数
HandshakingTaggingScheme比较重要,这里面定义了sharing_spots2shaking_tag4batch和spots2shaking_tag4batch这样的上三角序列生产函数以及decode_rel_fr_shaking_tag这样的解码三元组函数等等
(2)model部分
rel_extractor得到ent_shaking_outputs, head_rel_shaking_outputs, tail_rel_shaking_outputs维度分别是[batch, 5+4+3+2+1,2],[batch,n,5+4+3+2+1,3],[batch,n,5+4+3+2+1,3]
其实rel_extractor就是一个关系提取器,底层如果是基于Bert的话就是TPLinkerBert,底层如果是基于BiLSTM的话就是TPLinkerBiLSTM,这里以为例:
底层是通过bert的共享编码shaking_hiddens,再加上距离编码得到最终的共享编码shaking_hiddens4ent
上层的话就是1【实体层】+(1【头】+1【尾】)*n【关系数】个mlp层,即假设有3中关系,那么就是1+2*3=7个mlp层
计算loss的话是上面三部分loss加权(动态权重)
其中将上三角平铺成序列的代码在common.components.py 里面的HandshakingKernel,平铺后得到的shaking_hiddens4ent
看到很多小伙伴私信和关注,为了不迷路,欢迎大家关注笔者的微信公众号,会定期发一些关于NLP的干活总结和实践心得,当然别的方向也会发,一起学习:

发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/234534.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
