大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
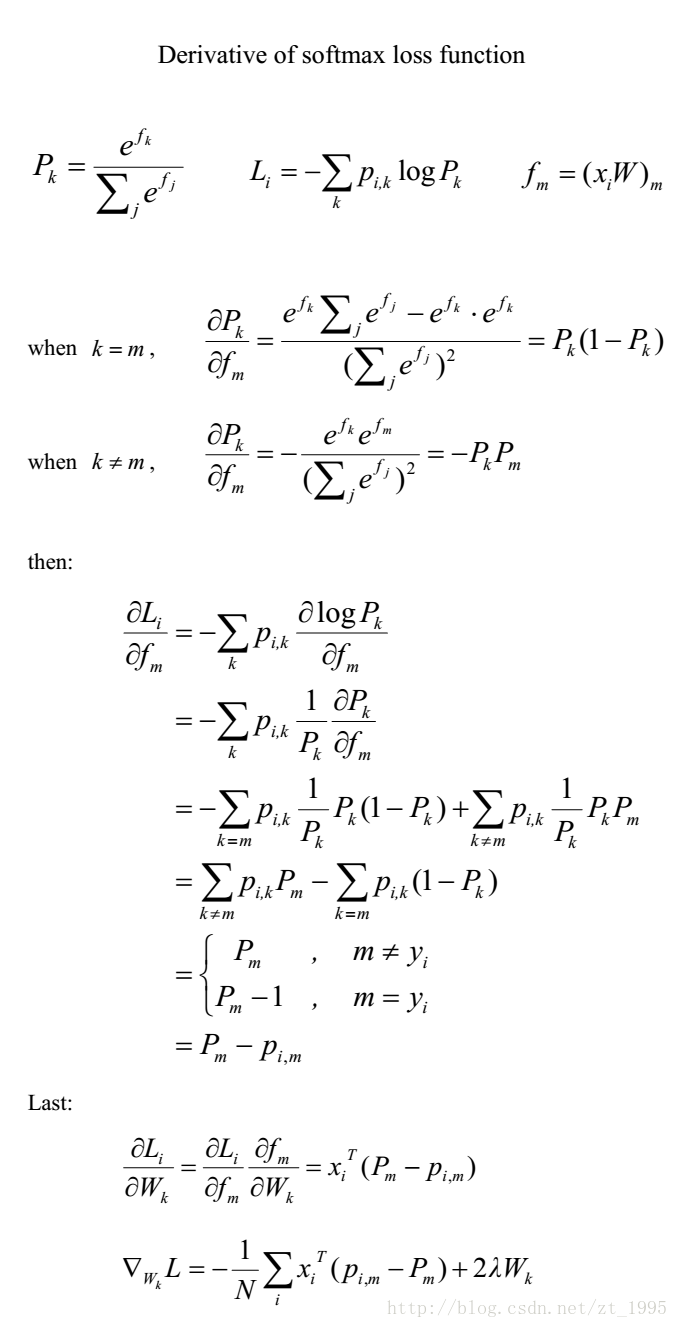

来源:https://blog.csdn.net/zt_1995/article/details/62227603
其实整个推导,上面这个图片已经介绍得十分清楚了,但是仍有很多小步骤被省略掉了,我会补上详细的softmax求导的过程:
(1)softmax函数
\quad 首先再来明确一下softmax函数,一般softmax函数是用来做分类任务的输出层。softmax的形式为:
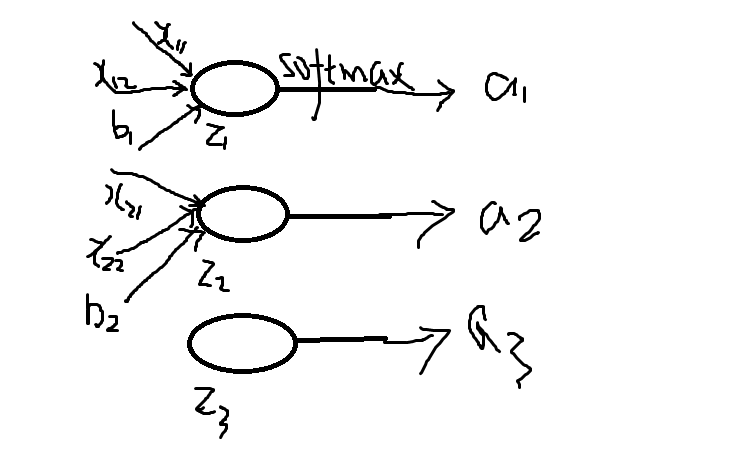
S i = e z i ∑ k e z k S_i = \frac{e^{z_i}}{\sum_ke^{z_k}} Si=∑kezkezi 其中 S i S_i Si表示的是第i个神经元的输出,接下来我们定义一个有多个输入,一个输出的神经元。神经元的输出为 z i = ∑ i j x i j + b z_i = \sum_{ij}x_{ij}+b zi=∑ijxij+b,其中 w i j w_{ij} wij是第 i i i个神经元的第 j j j个权重,b是偏移值. z i z_i zi表示网络的第 i i i个输出。给这个输出加上一个softmax函数,可以写成: a i = e z i ∑ k e z k a_i = \frac{e^{z_i}}{\sum_ke^{z_k}} ai=∑kezkezi, 其中 a i a_i ai表示softmax函数的第i个输出值。这个过程可以用下图表示:
(2)损失函数
softmax的损失函数一般是选择交叉熵损失函数,交叉熵函数形式为 C = − ∑ i y i l n a i C=-\sum_i{y_i lna_i} C=−∑iyilnai,其中y_i表示真实的标签值
(3)需要用到的高数的求导公式
c'=0(c为常数)
(x^a)'=ax^(a-1),a为常数且a≠0
(a^x)'=a^xlna
(e^x)'=e^x
(logax)'=1/(xlna),a>0且 a≠1
(lnx)'=1/x
(sinx)'=cosx
(cosx)'=-sinx
(tanx)'=(secx)^2
(secx)'=secxtanx
(cotx)'=-(cscx)^2
(cscx)'=-csxcotx
(arcsinx)'=1/√(1-x^2)
(arccosx)'=-1/√(1-x^2)
(arctanx)'=1/(1+x^2)
(arccotx)'=-1/(1+x^2)
(shx)'=chx
(chx)'=shx
(uv)'=uv'+u'v
(u+v)'=u'+v'
(u/)'=(u'v-uv')/^2
(3)进行推导
我们需要求的是loss对于神经元输出 z i z_i zi的梯度,求出梯度后才可以反向传播,即是求:
∂ C ∂ z i \frac{\partial C}{\partial z_i} ∂zi∂C, 根据链式法则(也就是复合函数求导法则) ∂ C ∂ a j ∂ a j ∂ z i \frac{\partial C}{\partial a_j}\frac{\partial a_j}{\partial z_i} ∂aj∂C∂zi∂aj,初学的时候这个公式理解了很久,为什么这里是 a j a_j aj而不是 a i a_i ai呢?这里我们回忆一下softmax的公示,分母部分包含了所有神经元的输出,所以对于所有输出非i的输出中也包含了 z i z_i zi,所以所有的a都要参与计算,之后我们会看到计算需要分为 i = j i=j i=j和 i ≠ j i \neq j i̸=j两种情况分别求导数。
首先来求前半部分:
∂ C ∂ a j = − ∑ j y i l n a j ∂ a j = − ∑ j y j 1 a j \frac{\partial C}{ \partial a_j} = \frac{-\sum_jy_ilna_j}{\partial a_j} = -\sum_jy_j\frac{1}{a_j} ∂aj∂C=∂aj−∑jyilnaj=−∑jyjaj1,接下来求第二部分的导数,如果 i = j i=j i=j, ∂ a i ∂ z i = ∂ ( e z i ∑ k e z k ) ∂ z i = ∑ k e z k e z i − ( e z i ) 2 ( ∑ k e z k ) 2 = ( e i z ∑ k e z k ) ( 1 − e z i ∑ k e z k ) = a i ( 1 − a i ) \frac{\partial a_i}{\partial z_i} = \frac{\partial(\frac{e^{z_i}}{\sum_ke^{z_k}})}{\partial z_i}=\frac{\sum_ke^{z_k}e^{z_i}-(e^{z_i})^2}{(\sum_ke^{z_k})^2}=(\frac{e^z_i}{\sum_ke^{z_k}})(1 – \frac{e^{z_i}}{\sum_ke^{z_k}})=a_i(1-a_i) ∂zi∂ai=∂zi∂(∑kezkezi)=(∑kezk)2∑kezkezi−(ezi)2=(∑kezkeiz)(1−∑kezkezi)=ai(1−ai),如果 i ≠ j i \neq j i̸=j, ∂ a i ∂ z i = ∂ e z j ∑ k e z k ∂ z i = − e z j ( 1 ∑ k e k z ) 2 e z i = − a i a j \frac{\partial a_i}{\partial z_i}=\frac{\partial\frac{e^{z_j}}{\sum_ke^{z_k}}}{\partial z_i} = -e^{z_j}(\frac{1}{\sum_ke^z_k})^2e^{z_i}=-a_ia_j ∂zi∂ai=∂zi∂∑kezkezj=−ezj(∑kekz1)2ezi=−aiaj,接下来把上面的组合之后得到 ∂ C ∂ z i = ( − ∑ j y j 1 a j ) ∂ a j ∂ z i = − y i a i a i ( 1 − a i ) + ∑ j ≠ i y j a j a i a j = − y i + y i a i + ∑ j ≠ i y j a i = − y i + a i ∑ j y j \frac{\partial C}{\partial z_i}=(-\sum_{j}y_j\frac{1}{a_j})\frac{\partial a_j}{\partial z_i}=-\frac{y_i}{a_i}a_i(1-a_i)+\sum_{j \neq i}\frac{y_j}{a_j}a_ia_j=-y_i+y_ia_i+\sum_{j \neq i}\frac{y_j}a_i=-y_i+a_i\sum_{j}y_j ∂zi∂C=(−∑jyjaj1)∂zi∂aj=−aiyiai(1−ai)+∑j̸=iajyjaiaj=−yi+yiai+∑j̸=iayji=−yi+ai∑jyj,推导完成!
(4)对于分类问题来说,我们给定的结果 y i y_i yi最终只有一个类别是1,其他是0,因此对于分类问题,梯度等于:
∂ C ∂ z i = a i − y i \frac{\partial C}{\partial z_i}=a_i – y_i ∂zi∂C=ai−yi
最后放一份CS231N的代码实现,帮助进一步理解:
#coding=utf-8
import numpy as np
def softmax_loss_native(W, X, y, reg):
'''
Softmax_loss的暴力实现,利用了for循环
输入的维度是D,有C个分类类别,并且我们在有N个例子的batch上进行操作
输入:
- W: 一个numpy array,形状是(D, C),代表权重
- X: 一个形状为(N, D)为numpy array,代表输入数据
- y: 一个形状为(N,)的numpy array,代表类别标签
- reg: (float)正则化参数
f返回:
- 一个浮点数代表Loss
- 和W形状一样的梯度
'''
loss = 0.0
dW = np.zeros_like(W) #dW代表W反向传播的梯度
num_classes = W.shape[1]
num_train = X.shape[0]
for i in xrange(num_train):
scores = X[i].dot(W)
shift_scores = scores - max(scores) #防止数值不稳定
loss_i = -shift_scores[y[i]] + np.log(sum(np.exp(shift_scores)))
loss += loss_i
for j in xrange(num_classes):
softmax_output = np.exp(shift_scores[j]) / sum(np.exp(shift_scores))
if j == y[i]:
dW[:, j] += (-1 + softmax_output) * X[i]
else:
dW[:, j] += softmax_output * X[i]
loss /= num_train
loss += 0.5 * reg * np.sum(W * W)
dW = dW / num_train + reg * W
return loss, dW
def softmax_loss_vectorized(W, X, y, reg):
loss = 0.0
dW = np.zeros_like(W)
num_class = W.shape[1]
num_train = X.shape[0]
scores = X.dot(W)
shift_scores = scores - np.max(scores, axis=1).reshape(-1, 1)
softmax_output = np.exp(shift_scores) / np.sum(np.exp(shift_scores), axis=1).reshape(-1, 1)
loss = -np.sum(np.log(softmax_output[range(num_train), list(y)]))
loss /= num_train
loss += 0.5 * reg * np.sum(W * W)
dS = softmax_output.copy()
dS[range(num_train), list(y)] += -1
dW = (x.T).dot(dS)
dW = dW/num_train + reg*W
return loss, dW
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/234527.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
