大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
MaxCompute Java版UDF开发
MaxCompute UDF概述
MaxCompute UDF(User Defined Function)即用户自定义函数。
背景信息
广义的UDF定义是自定义标量函数(UDF)、自定义表值函数(UDTF)及自定义聚合函数(UDAF)三种类型的自定义函数的集合。狭义的UDF仅代表用户自定义标量函数。MaxCompute UDF支持的自定义函数类型如下。
| 自定义函数类型 | 名称 | 应用场景 |
|---|---|---|
| UDF | User Defined Scalar Function。用户自定义标量函数。 | 适用于一进一出业务场景。即其输入与输出是一对一的关系,读入一行数据,输出一个值。 |
| UDTF | User Defined Table Valued Function。用户自定义表值函数,又称表格UDF。 | 适用于一进多出业务场景。即其输入与输出是一对多的关系,读入一行数据,输出多个值可视为一张表。 |
| UDAF | User Defined Aggregation Function。用户自定义聚合函数。 | 适用于多进一出业务场景。即其输入与输出是多对一的关系,将多条输入记录聚合成一个输出值。 |
除上述自定义函数外,MaxCompute还提供如下针对特殊场景的能力支撑。
| 自定义函数类型 | 应用场景 |
|---|---|
| 代码嵌入式UDF | 当需要简化MaxCompute UDF操作步骤,并希望能直接查看代码实现逻辑时,可以直接将Java或Python代码嵌入SQL脚本。 |
| SQL语言定义函数 | 当代码中存在很多相似部分时,可以通过SQL自定义函数实现,提高代码复用率的同时还可以简化操作流程。 |
| 开源地理空间UDF | 支持在MaxCompute中使用Hive地理空间函数分析空间数据。 |
注意事项
使用自定义函数时,需要注意:
- 在性能上,自定义函数的性能低于内建函数,建议您优先使用内建函数实现相同逻辑的业务需求。
- 在SQL语句中使用自定义函数时,如果计算的数据量过大并且存在倾斜,会导致作业占用的内存超出默认分配的内存。此时,您可以在Session级别设置
set odps.sql.udf.joiner.jvm.memory=xxxx;属性来解决此问题。 - 当自定义函数的名称与内建函数的名称相同时,自定义函数会覆盖同名的内建函数。
开发流程
使用Java代码编写MaxCompute UDF时,开发流程如下。


-
配置pom依赖
使用Maven编写代码时,需要先在Pom文件中添加代码相关SDK依赖,确保后续编写的代码可编译成功。例如开发自定义函数需要添加的SDK依赖为:
<dependency> <groupId>com.aliyun.odps</groupId> <artifactId>odps-sdk-udf</artifactId> <version>0.29.10-public</version> </dependency> 编写代码
根据业务需求,编写自定义函数代码。
-
调试代码
通过本地运行或单元测试方式调试自定义函数,查看运行结果是否符合预期。
-
编译并导出JAR包
调试自定义函数代码,确保本地运行成功后打包为JAR包。
-
添加资源
将JAR包作为资源上传至MaxCompute项目。
-
创建MaxCompute UDF
基于上传的JAR包资源创建自定义函数。
-
调用MaxCompute UDF
在查询数据代码中调用自定义函数。
使用说明
自定义函数的使用方法如下:
- 在归属MaxCompute项目中使用自定义函数:使用方法与内建函数类似,可以参照内建函数的使用方法使用自定义函数。
- 跨项目使用自定义函数:即在项目A中使用项目B的自定义函数,跨项目分享语句示例:
select B:udf_in_other_project(arg0, arg1) as res from table_t;。
数据类型
| MaxCompute Type | Java Type | Java Writable Type |
|---|---|---|
| TINYINT | java.lang.Byte | ByteWritable |
| SMALLINT | java.lang.Short | ShortWritable |
| INT | java.lang.Integer | IntWritable |
| BIGINT | java.lang.Long | LongWritable |
| FLOAT | java.lang.Float | FloatWritable |
| DOUBLE | java.lang.Double | DoubleWritable |
| DECIMAL | java.math.BigDecimal | BigDecimalWritable |
| BOOLEAN | java.lang.Boolean | BooleanWritable |
| STRING | java.lang.String | Text |
| VARCHAR | com.aliyun.odps.data.Varchar | VarcharWritable |
| BINARY | com.aliyun.odps.data.Binary | BytesWritable |
| DATETIME | java.util.Date | DatetimeWritable |
| TIMESTAMP | java.sql.Timestamp | TimestampWritable |
| INTERVAL_YEAR_MONTH | 不涉及 | IntervalYearMonthWritable |
| INTERVAL_DAY_TIME | 不涉及 | IntervalDayTimeWritable |
| ARRAY | java.util.List | 不涉及 |
| MAP | java.util.Map | 不涉及 |
| STRUCT | com.aliyun.odps.data.Struct | 不涉及 |
MaxCompute SDK
MaxCompute提供的SDK信息如下。
| SDK名称 | 描述 |
|---|---|
| odps-sdk-core | 提供操作MaxCompute基本资源的类。 |
| odps-sdk-commons | Java Util封装。 |
| odps-sdk-udf | UDF功能的主体接口。 |
| odps-sdk-mapred | MapReduce API。 |
| odps-sdk-graph | Graph API。 |
UDF
UDF概述
MaxCompute支持通过Java、Python语言编写代码创建UDF,扩展MaxCompute的函数能力,满足个性化业务需求。
背景信息
UDF适用于一进一出业务场景。即其输入与输出是一对一的关系,读入一行数据,输出一个值。
Java UDF
UDF代码结构
可以通过IntelliJ IDEA(Maven)或MaxCompute Studio工具使用Java语言编写UDF代码,代码中需要包含如下信息:
-
Java包(Package):可选
-
继承UDF类:必选。
-
必需携带的UDF类为com.aliyun.odps.udf.UDF。当您需要使用其他UDF类或者需要用到复杂数据类型时,请根据MaxCompute SDK添加需要的类。例如STRUCT数据类型对应的UDF类为com.aliyun.odps.data.Struct。
-
@Resolve注解:可选。格式为
@Resolve(<signature>),signature用于定义函数的输入参数和返回值的数据类型。当需要在UDF中使用STRUCT数据类型时,无法基于com.aliyun.odps.data.Struct反射分析得到Field Name和Field Type,所以需要用@Resolve注解来辅助获取。即如果需要在UDF中使用STRUCT,请在UDF Class中加上@Resolve注解,注解只会影响参数或返回值中包含com.aliyun.odps.data.Struct的重载。例如@Resolve("struct<a:string>,string->string")。 -
自定义Java类:必选。
UDF代码的组织单位,定义了实现业务需求的变量及方法。
-
evaluate方法:必选。非静态的Public方法,位于自定义的Java类中。
evaluate方法的输入参数和返回值的数据类型将作为SQL语句中UDF的函数签名Signature(定义UDF的输入与输出数据类型)。可以在UDF中实现多个
evaluate方法,在调用UDF时,MaxCompute会依据UDF调用的参数类型匹配正确的evaluate方法。编写Java UDF时可以使用Java Type或Java Writable Type
-
UDF初始化或结束代码:可选。可以通过
void setup(ExecutionContext ctx)和void close()分别实现UDF初始化和结束。void setup(ExecutionContext ctx)方法会在evaluate方法前调用且仅会调用一次,可以用来初始化一些计算所需要的资源或类的成员对象。void close()方法会在evaluate方法结束后调用,可以用来执行一些清理工作,例如关闭文件。
UDF代码示例如下。
-
使用Java Type类型
//将定义的Java类组织在org.alidata.odps.udf.examples包中。 package org.alidata.odps.udf.examples; //继承UDF类。 import com.aliyun.odps.udf.UDF; //自定义Java类。 public final class Lower extends UDF { //evaluate方法。其中:String标识输入参数的数据类型,return标识返回值。 public String evaluate(String s) { if (s == null) { return null; } return s.toLowerCase(); } } -
使用Java Writable Type类型
//将定义的Java类组织在com.aliyun.odps.udf.example包中。 package com.aliyun.odps.udf.example; //添加Java Writable Type类型必需的类。 import com.aliyun.odps.io.Text; //继承UDF类。 import com.aliyun.odps.udf.UDF; //自定义Java类。 public class MyConcat extends UDF { private Text ret = new Text(); //evaluate方法。其中:Text标识输入参数的数据类型,return标识返回值。 public Text evaluate(Text a, Text b) { if (a == null || b == null) { return null; } ret.clear(); ret.append(a.getBytes(), 0, a.getLength()); ret.append(b.getBytes(), 0, b.getLength()); return ret; } }
注意事项
在编写Java UDF时,您需要注意:
- 不同UDF JAR包中不建议存在类名相同但实现逻辑不一样的类。例如UDF1、UDF2分别对应资源JAR包udf1.jar、udf2.jar,两个JAR包里都包含名称为
com.aliyun.UserFunction.class的类但实现逻辑不一样,当同一条SQL语句中同时调用UDF1和UDF2时,MaxCompute会随机加载其中一个类,此时会导致UDF执行结果不符合预期甚至编译失败。 - Java UDF中输入或返回值的数据类型是对象,数据类型首字母必须大写,例如String。
- SQL中的NULL值通过Java中的NULL表示。Java Primitive Type无法表示SQL中的NULL值,不允许使用。
Java UDF使用示例
兼容Hive Java UDF示例
注意事项
使用兼容的Hive UDF时,您需要注意:
- 在MaxCompute上使用
add jar命令添加Hive UDF的资源时,您需要指定所有JAR包,MaxCompute无法自动将所有JAR包加入Classpath。 - 调用Hive UDF时,需要在SQL语句前添加
set odps.sql.hive.compatible=true;语句,与SQL语句一起提交执行。
Hive UDF代码示例
package com.aliyun.odps.compiler.hive;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import java.util.ArrayList;
import java.util.List;
import java.util.Objects;
public class Collect extends GenericUDF {
@Override
public ObjectInspector initialize(ObjectInspector[] objectInspectors) throws UDFArgumentException {
if (objectInspectors.length == 0) {
throw new UDFArgumentException("Collect: input args should >= 1");
}
for (int i = 1; i < objectInspectors.length; i++) {
if (objectInspectors[i] != objectInspectors[0]) {
throw new UDFArgumentException("Collect: input oi should be the same for all args");
}
}
return ObjectInspectorFactory.getStandardListObjectInspector(objectInspectors[0]);
}
@Override
public Object evaluate(DeferredObject[] deferredObjects) throws HiveException {
List<Object> objectList = new ArrayList<>(deferredObjects.length);
for (DeferredObject deferredObject : deferredObjects) {
objectList.add(deferredObject.get());
}
return objectList;
}
@Override
public String getDisplayString(String[] strings) {
return "Collect";
}
}
该UDF代码示例可以将任意类型、数量的参数打包成ARRAY输出。假设Hive UDF对应的JAR包名称为test.jar。
操作步骤
-
将Hive UDF代码示例通过Hive平台编译为JAR包,执行如下命令将Hive UDF JAR包添加为MaxCompute资源。
--添加资源。 add jar test.jar; -
执行如下命令注册UDF函数。
--注册函数。 create function hive_collect as 'com.aliyun.odps.compiler.hive.Collect' using 'test.jar';\ -
执行如下SQL语句调用新建的UDF函数。
--设置MaxCompute项目的模式为Hive兼容模式。 set odps.sql.hive.compatible=true; --调用UDF函数。 select hive_collect(4y, 5y, 6y);
复杂数据类型示例
UDF代码示例
如下代码中,定义了3个重载的evaluate方法。其中:
-
第一个用ARRAY作为参数,ARRAY对应java.util.List。
-
第二个用MAP作为参数,MAP对应java.util.Map。
-
第三个用STRUCT作为参数,STRUCT对应com.aliyun.odps.data.Struct。
com.aliyun.odps.data.Struct无法通过反射分析获取到field name和field type,需要辅助使用
@Resolve annotation,即如果您需要在UDF中使用STRUCT,要求在UDF class上也标注上@Resolve注解,该注解只会影响参数或返回值中包含com.aliyun.odps.data.Struct的重载。
import com.aliyun.odps.data.Struct;
import com.aliyun.odps.udf.UDF;
import com.aliyun.odps.udf.annotation.Resolve;
import java.util.List;
import java.util.Map;
@Resolve("struct<a:string>,string->string")
public class UdfArray extends UDF {
//接收两个参数,第一个参数对应ARRAY复杂数据类型,第二个参数对应要获取的元素的index,目的是要取出位于index位置的元素。
public String evaluate(List<String> vals, Long index) {
return vals.get(index.intValue());
}
//接收两个参数,第一个参数对应MAP复杂数据类型,第二个参数对应要取出的Key,目的是要取出Key对应的值。
public String evaluate(Map<String, String> map, String key) {
return map.get(key);
}
//接收两个参数,第一个参数对应STRUCT复杂数据类型,第二个参数为一个Key值,目的是要取出STRUCT中成员变量a对应的值,并在其后增加Key值以STRING格式返回。
public String evaluate(Struct struct, String key) {
return struct.getFieldValue("a") + key;
}
}
使用示例
select my_index(array('a', 'b', 'c'), 0); --返回a。
select my_index(map('key_a','val_a', 'key_b', 'val_b'), 'key_b'); --返回val_b。
select my_index(named_struct('a', 'hello'), 'world'); --返回hello world。
UDTF
UDTF概述
背景信息
UDTF为用户自定义表值函数,适用于一进多出业务场景。即其输入与输出是一对多的关系,读入一行数据,输出多个值可视为一张表。
使用限制
在select语句中使用UDTF时,不允许存在其他列或表达式。错误示例如下。
--查询语句中同时携带了UDTF和其他列。
select value, user_udtf(key) as mycol ...
UDTF不能嵌套使用。错误示例如下。
--user_udtf1嵌套了user_udtf2,不允许嵌套。
select user_udtf1(user_udtf2(key)) as mycol...;
不支持在同一个select子句中与group by、distribute by、sort by联用。错误示例如下。
--UDTF不能与group by联用。
select user_udtf(key) as mycol ... group by mycol;
Java UDTF
UDTF代码结构
代码中需要包含如下信息:
-
Java包(Package):可选。
-
继承UDTF类:必选。
必须携带的UDTF类为
com.aliyun.odps.udf.UDTF、com.aliyun.odps.udf.annotation.Resolve(对应@Resolve注解)和com.aliyun.odps.udf.UDFException(对应实现Java类的方法)。 -
自定义Java类:必选。
UDTF代码的组织单位,定义了实现业务需求的变量及方法。
-
@Resolve注解:必选。格式为
@Resolve(<signature>)。signature为函数签名,用于定义函数的输入参数和返回值的数据类型。UDTF无法通过反射分析获取函数签名,只能通过@Resolve注解方式获取函数签名,例如@Resolve("smallint->varchar(10)")。 -
实现Java类的方法:必选。
Java类实现包含如下4个方法,可以根据实际需要进行选择。
接口定义 描述 public void setup(ExecutionContext ctx) throws UDFException初始化方法,在UDTF处理输入的数据前,MaxCompute会调用用户自定义的初始化行为。在每个Worker内 setup会被先调用一次。public void process(Object[] args) throws UDFExceptionSQL中每一条记录都会对应调用一次 process,process的参数为SQL语句中指定的UDTF输入参数。输入参数以Object[]的形式传入,输出结果通过forward函数输出。您需要在process函数内自行调用forward,以决定输出数据。public void close() throws UDFExceptionUDTF的结束方法。只会被调用一次,即在处理完最后一条记录之后被调用。 public void forward(Object …o) throws UDFException调用 forward方法输出数据,每调用一次forward代表输出一条记录。在SQL查询语句中调用UDTF时,可以通过as子句将forward输出的结果进行重命名。
UDTF代码示例如下。
//将定义的Java类组织在org.alidata.odps.udtf.examples包中。
package org.alidata.odps.udtf.examples;
//继承UDTF类。
import com.aliyun.odps.udf.UDTF;
import com.aliyun.odps.udf.UDTFCollector;
import com.aliyun.odps.udf.annotation.Resolve;
import com.aliyun.odps.udf.UDFException;
//自定义Java类。
//@Resolve注解。
@Resolve("string,bigint->string,bigint")
public class MyUDTF extends UDTF {
//实现Java类的方法。
@Override
public void process(Object[] args) throws UDFException {
String a = (String) args[0];
Long b = (Long) args[1];
for (String t: a.split("\\s+")) {
forward(t, b);
}
}
}
@Resolve注解
@Resolve注解格式如下。
@Resolve(<signature>)
signature为函数签名字符串,用于标识输入参数和返回值的数据类型。执行UDTF时,UDTF函数的输入参数和返回值类型要与函数签名指定的类型一致。查询语义解析阶段会检查不符合函数签名定义的用法,检查到类型不匹配时会报错。具体格式如下。
'arg_type_list -> type_list'
其中:
-
type_list:表示返回值的数据类型。UDTF可以返回多列。支持的数据类型为:BIGINT、STRING、DOUBLE、BOOLEAN、DATETIME、DECIMAL、FLOAT、BINARY、DATE、DECIMAL(precision,scale)、复杂数据类型(ARRAY、MAP、STRUCT)或复杂数据类型嵌套。 -
arg_type_list:表示输入参数的数据类型。输入参数可以为多个,用英文逗号(,)分隔。支持的数据类型为BIGINT、STRING、DOUBLE、BOOLEAN、DATETIME、DECIMAL、FLOAT、BINARY、DATE、DECIMAL(precision,scale)、CHAR、VARCHAR、复杂数据类型(ARRAY、MAP、STRUCT)或复杂数据类型嵌套。arg_type_list还支持星号(*)或为空(‘’):- 当
arg_type_list为星号(*)时,表示输入参数为任意个数。 - 当
arg_type_list为空(‘’)时,表示无输入参数。
- 当
合法@Resolve注解示例如下。
| @Resolve注解示例 | 说明 |
|---|---|
@Resolve('bigint,boolean->string,datetime') |
输入参数类型为BIGINT、BOOLEAN,返回值类型为STRING、DATETIME。 |
@Resolve('*->string, datetime') |
输入任意个参数,返回值类型为STRING、DATETIME。 |
@Resolve('->double, bigint, string') |
无输入参数,返回值类型为DOUBLE、BIGINT、STRING。 |
@Resolve("array<string>,struct<a1:bigint,b1:string>,string->map<string,bigint>,struct<b1:bigint>") |
输入参数类型为ARRAY、STRUCT、MAP,返回值类型为MAP、STRUCT。 |
使用示例
UDTF查询示例如下:
select user_udtf(col0, col1) as (c0, c1) from my_table;
Java UDTF读取MaxCompute资源示例
UDTF代码示例
package com.aliyun.odps.examples.udf;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.util.Iterator;
import com.aliyun.odps.udf.ExecutionContext;
import com.aliyun.odps.udf.UDFException;
import com.aliyun.odps.udf.UDTF;
import com.aliyun.odps.udf.annotation.Resolve;
/** * project: example_project * table: wc_in2 * partitions: p2=1,p1=2 * columns: colc,colb */
@Resolve("string,string->string,bigint,string")
public class UDTFResource extends UDTF {
ExecutionContext ctx;
long fileResourceLineCount;
long tableResource1RecordCount;
long tableResource2RecordCount;
@Override
public void setup(ExecutionContext ctx) throws UDFException {
this.ctx = ctx;
try {
InputStream in = ctx.readResourceFileAsStream("file_resource.txt");
BufferedReader br = new BufferedReader(new InputStreamReader(in));
String line;
fileResourceLineCount = 0;
while ((line = br.readLine()) != null) {
fileResourceLineCount++;
}
br.close();
Iterator<Object[]> iterator = ctx.readResourceTable("table_resource1").iterator();
tableResource1RecordCount = 0;
while (iterator.hasNext()) {
tableResource1RecordCount++;
iterator.next();
}
iterator = ctx.readResourceTable("table_resource2").iterator();
tableResource2RecordCount = 0;
while (iterator.hasNext()) {
tableResource2RecordCount++;
iterator.next();
}
} catch (IOException e) {
throw new UDFException(e);
}
}
@Override
public void process(Object[] args) throws UDFException {
String a = (String) args[0];
long b = args[1] == null ? 0 : ((String) args[1]).length();
forward(a, b, "fileResourceLineCount=" + fileResourceLineCount + "|tableResource1RecordCount="
+ tableResource1RecordCount + "|tableResource2RecordCount=" + tableResource2RecordCount);
}
}
SQL代码示例如下。
select my_udtf("10","20") as (a, b, fileResourceLineCount);
UDAF
UDAF概述
UDAF为用户自定义聚合函数,适用于多进一出业务场景。即其输入与输出是多对一的关系,将多条输入记录聚合成一个输出值。
Java UDAF
UDAF代码结构
代码中需要包含如下信息:
-
Java包(Package):可选。
-
继承UDAF类:必选。
必需携带的UDAF类为
import com.aliyun.odps.udf.Aggregator和com.aliyun.odps.udf.annotation.Resolve(对应@Resolve注解)。com.aliyun.odps.udf.UDFException(可选,对应实现Java类初始化和结束的方法)。 -
@Resolve注解:必选。格式为
@Resolve(<signature>)。signature为函数签名,用于定义函数的输入参数和返回值的数据类型。UDAF无法通过反射分析获取函数签名,只能通过@Resolve注解方式获取函数签名,例如@Resolve("smallint->varchar(10)")。 -
自定义Java类:必选。
UDAF代码的组织单位,定义了实现业务需求的变量及方法。
-
实现Java类的方法:必选。
实现Java类需要继承
com.aliyun.odps.udf.Aggregator类并实现如下方法。import com.aliyun.odps.udf.ContextFunction; import com.aliyun.odps.udf.ExecutionContext; import com.aliyun.odps.udf.UDFException; public abstract class Aggregator implements ContextFunction { //初始化方法。 @Override public void setup(ExecutionContext ctx) throws UDFException { } //结束方法。 @Override public void close() throws UDFException { } //创建聚合Buffer。 abstract public Writable newBuffer(); //iterate方法。 //buffer为聚合buffer,是指一个阶段性的汇总数据,即在不同的Map任务中,group by后得出的数据(可理解为一个集合),每行执行一次。 //Writable[]表示一行数据,在代码中指代传入的列。例如writable[0]表示第一列,writable[1]表示第二列。 //args为SQL中调用UDAF时指定的参数,不能为NULL,但是args里面的元素可以为NULL,代表对应的输入数据是NULL。 abstract public void iterate(Writable buffer, Writable[] args) throws UDFException; //terminate方法。 abstract public Writable terminate(Writable buffer) throws UDFException; //merge方法。 abstract public void merge(Writable buffer, Writable partial) throws UDFException; }其中:
iterate、merge和terminate是最重要的三个方法,UDAF的主要逻辑依赖于这三个方法的实现。此外,还需要您实现自定义的Writable buffer。Writable buffer将内存中的对象转换成字节序列(或其他数据传输协议)以便于储存到磁盘(持久化)和网络传输。因为MaxCompute使用分布式计算的方式来处理聚合函数,因此需要知道如何序列化和反序列化数据,以便于数据在不同的设备之间进行传输。
UDAF代码示例如下。
//将定义的Java类组织在org.alidata.odps.udaf.examples包中。
package org.alidata.odps.udaf.examples;
//继承UDAF类。
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import com.aliyun.odps.io.DoubleWritable;
import com.aliyun.odps.io.Writable;
import com.aliyun.odps.udf.Aggregator;
import com.aliyun.odps.udf.UDFException;
import com.aliyun.odps.udf.annotation.Resolve;
//自定义Java类。
//@Resolve注解。
@Resolve("double->double")
public class AggrAvg extends Aggregator {
//实现Java类的方法。
private static class AvgBuffer implements Writable {
private double sum = 0;
private long count = 0;
@Override
public void write(DataOutput out) throws IOException {
out.writeDouble(sum);
out.writeLong(count);
}
@Override
public void readFields(DataInput in) throws IOException {
sum = in.readDouble();
count = in.readLong();
}
}
private DoubleWritable ret = new DoubleWritable();
@Override
public Writable newBuffer() {
return new AvgBuffer();
}
@Override
public void iterate(Writable buffer, Writable[] args) throws UDFException {
DoubleWritable arg = (DoubleWritable) args[0];
AvgBuffer buf = (AvgBuffer) buffer;
if (arg != null) {
buf.count += 1;
buf.sum += arg.get();
}
}
@Override
public Writable terminate(Writable buffer) throws UDFException {
AvgBuffer buf = (AvgBuffer) buffer;
if (buf.count == 0) {
ret.set(0);
} else {
ret.set(buf.sum / buf.count);
}
return ret;
}
@Override
public void merge(Writable buffer, Writable partial) throws UDFException {
AvgBuffer buf = (AvgBuffer) buffer;
AvgBuffer p = (AvgBuffer) partial;
buf.sum += p.sum;
buf.count += p.count;
}
}
@Resolve注解
@Resolve注解格式如下。
@Resolve(<signature>)
signature为字符串,用于标识输入参数和返回值的数据类型。执行UDAF时,UDAF函数的输入参数和返回值类型要与函数签名指定的类型一致。查询语义解析阶段会检查不符合函数签名定义的用法,检查到类型不匹配时会报错。具体格式如下。
'arg_type_list -> type'
其中:
-
arg_type_list:表示输入参数的数据类型。输入参数可以为多个,用英文逗号(,)分隔。支持的数据类型为BIGINT、STRING、DOUBLE、BOOLEAN、DATETIME、DECIMAL、FLOAT、BINARY、DATE、DECIMAL(precision,scale)、CHAR、VARCHAR、复杂数据类型(ARRAY、MAP、STRUCT)或复杂数据类型嵌套。arg_type_list还支持星号(*)或为空(‘’):- 当
arg_type_list为星号(*)时,表示输入参数为任意个数。 - 当
arg_type_list为空(‘’)时,表示无输入参数。
- 当
-
type:表示返回值的数据类型。UDAF只返回一列。支持的数据类型为:BIGINT、STRING、DOUBLE、BOOLEAN、DATETIME、DECIMAL、FLOAT、BINARY、DATE、DECIMAL(precision,scale)、复杂数据类型(ARRAY、MAP、STRUCT)或复杂数据类型嵌套。
合法@Resolve注解示例如下。
| @Resolve注解示例 | 说明 |
|---|---|
@Resolve('bigint,double->string') |
输入参数类型为BIGINT、DOUBLE,返回值类型为STRING。 |
@Resolve('*->string') |
输入任意个参数,返回值类型为STRING。 |
@Resolve('->double') |
无输入参数,返回值类型为DOUBLE。 |
@Resolve('array<bigint>->struct<x:string, y:int>') |
输入参数类型为ARRAY,返回值类型为STRUCT<x:STRING, y:INT>。 |
使用示例
以通过MaxCompute Studio开发计算平均值的UDAF函数AggrAvg为例,实现逻辑如下。
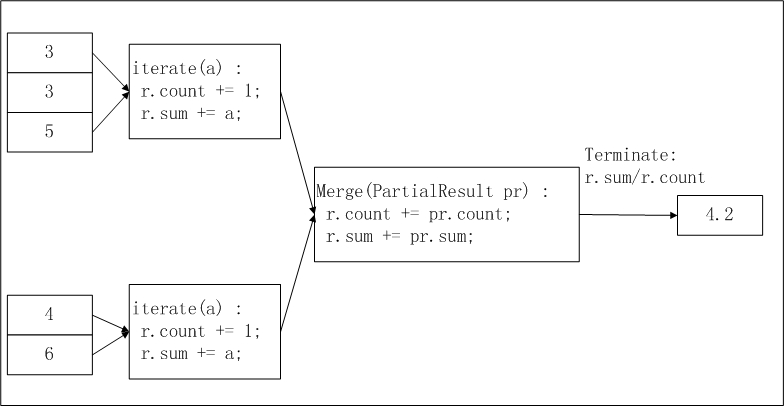
-
输入数据分片:MaxCompute会按照MapReduce处理流程对输入数据按照一定的大小进行分片,每片的大小适合一个Worker在适当的时间内完成。
分片大小需要您通过
odps.stage.mapper.split.size参数进行配置。 -
计算平均值第一阶段:每个Worker统计分片内数据的个数及汇总值。您可以将每个分片内的数据个数及汇总值视为一个中间结果。
-
计算平均值第二阶段:汇总第一阶段中每个分片内的信息。
-
最终输出:
r.sum/r.count即是所有输入数据的平均值。
代码嵌入式UDF
功能介绍
代码嵌入式UDF支持将Java或Python代码嵌入SQL脚本。Janino-compiler编译器会识别并提取嵌入的代码,完成代码编译(Java)、动态生成资源和创建临时函数操作。
代码嵌入式UDF允许您将SQL脚本和第三方代码放入同一个源码文件,减少使用UDT或UDF的操作步骤,方便日常开发。
使用限制
嵌入式Java代码使用Janino-compiler编译器进行编译,且支持的Java语法只是标准Java JDK的一个子集。嵌入式Java代码使用限制包含但不限于以下内容:
- 不支持Lambda表达式。
- 不支持Catch多种Exception类型。例如
catch(Exception1 | Exception2 e)。 - 不支持自动推导泛型。例如
Map map = new HashMap<>();。 - 类型参数的推导会被忽略,必须显示Cast。例如
(String) myMap.get(key)。 - Assert会强制开启,不受JVM的**-ea**参数控制。
- 不支持Java 8以上(不包含Java 8)版本的语言功能。
UDT引用嵌入式代码
SELECT
s,
com.mypackage.Foo.extractNumber(s)
FROM VALUES ('abc123def'),('apple') AS t(s);
#CODE ('lang'='JAVA')
package com.mypackage;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Foo {
final static Pattern compile = Pattern.compile(".*?([0-9]+).*");
public static String extractNumber(String input) {
final Matcher m = compile.matcher(input);
if (m.find()) {
return m.group(1);
}
return null;
}
}
#END CODE;
#CODE和#END CODE:表示嵌入式代码的开始和结束位置。位于脚本末尾的嵌入式代码块作用域为整个脚本。‘lang’=’JAVA’:表示嵌入式代码为Java代码。还支持PYTHON。- 在SQL脚本里可以使用UDT语法直接调用
Foo.extractNumber。
Java代码嵌入式UDF
CREATE TEMPORARY FUNCTION foo AS 'com.mypackage.Reverse' USING
#CODE ('lang'='JAVA')
package com.mypackage;
import com.aliyun.odps.udf.UDF;
public class Reverse extends UDF {
public String evaluate(String input) {
if (input == null) return null;
StringBuilder ret = new StringBuilder();
for (int i = input.toCharArray().length - 1; i >= 0; i--) {
ret.append(input.toCharArray()[i]);
}
return ret.toString();
}
}
#END CODE;
SELECT foo('abdc');
- 嵌入式代码块可以置于
USING后或脚本末尾,置于USING后的代码块作用域仅为CREATE TEMPORARY FUNCTION语句。 CREATE TEMPORARY FUNCTION创建的函数为临时函数,仅在本次执行生效,不会存入MaxCompute的Meta系统。
Java代码嵌入式UDTF
CREATE TEMPORARY FUNCTION foo AS 'com.mypackage.Reverse' USING
#CODE ('lang'='JAVA', 'filename'='embedded.jar')
package com.mypackage;
import com.aliyun.odps.udf.UDTF;
import com.aliyun.odps.udf.UDFException;
import com.aliyun.odps.udf.annotation.Resolve;
@Resolve({
"string->string,string"})
public class Reverse extends UDTF {
@Override
public void process(Object[] objects) throws UDFException {
String str = (String) objects[0];
String[] split = str.split(",");
forward(split[0], split[1]);
}
}
#END CODE;
SELECT foo('ab,dc') AS (a,b);
由于@Resolve返回值要求为string[],但Janino-compiler编译器无法将"string->string,string"识别为string[],@Resolve注解的参数需要加大括号({}),为嵌入式代码特有内容。用普通方式创建Java UDTF时可省略大括号({})。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/234503.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
