大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
文章目录
01 引言
在前面的博客,我们学习了Flink的内存管理了,有兴趣的同学可以参阅下:
- 《Flink教程(01)- Flink知识图谱》
- 《Flink教程(02)- Flink入门》
- 《Flink教程(03)- Flink环境搭建》
- 《Flink教程(04)- Flink入门案例》
- 《Flink教程(05)- Flink原理简单分析》
- 《Flink教程(06)- Flink批流一体API(Source示例)》
- 《Flink教程(07)- Flink批流一体API(Transformation示例)》
- 《Flink教程(08)- Flink批流一体API(Sink示例)》
- 《Flink教程(09)- Flink批流一体API(Connectors示例)》
- 《Flink教程(10)- Flink批流一体API(其它)》
- 《Flink教程(11)- Flink高级API(Window)》
- 《Flink教程(12)- Flink高级API(Time与Watermaker)》
- 《Flink教程(13)- Flink高级API(状态管理)》
- 《Flink教程(14)- Flink高级API(容错机制)》
- 《Flink教程(15)- Flink高级API(并行度)》
- 《Flink教程(16)- Flink Table与SQL》
- 《Flink教程(17)- Flink Table与SQL(案例与SQL算子)》
- 《Flink教程(18)- Flink阶段总结》
- 《Flink教程(19)- Flink高级特性(BroadcastState)》
- 《Flink教程(20)- Flink高级特性(双流Join)》
- 《Flink教程(21)- Flink高级特性(End-to-End Exactly-Once)》
- 《Flink教程(22)- Flink高级特性(异步IO)》
- 《Flink教程(23)- Flink高级特性(Streaming File Sink)》
- 《Flink教程(24)- Flink高级特性(File Sink)》
- 《Flink教程(25)- Flink高级特性(FlinkSQL整合Hive)》
- 《Flink教程(26)- Flink多语言开发》
- 《Flink教程(27)- Flink Metrics监控》
- 《Flink教程(28)- Flink性能优化》
- 《Flink教程(29)- Flink内存管理》
本文主要讲解Flink与Spark的区别。
02 Flink VS Spark
2.1 运行角色
Spark Streaming 运行时的角色(standalone 模式)主要有:
- Master:主要负责整体集群资源的管理和应用程序调度;
- Worker:负责单个节点的资源管理,driver 和 executor 的启动等;
- Driver:用户入口程序执行的地方,即 SparkContext 执行的地方,主要是 DAG 生成、stage 划分、task 生成及调度;
- Executor:负责执行 task,反馈执行状态和执行结果。
Flink 运行时的角色(standalone 模式)主要有:
- Jobmanager: 协调分布式执行,他们调度任务、协调 checkpoints、协调故障恢复等。至少有一个 JobManager。高可用情况下可以启动多个 JobManager,其中一个选举为 leader,其余为 standby;
- Taskmanager: 负责执行具体的 tasks、缓存、交换数据流,至少有一个 TaskManager;
- Slot: 每个 task slot 代表 TaskManager 的一个固定部分资源,Slot 的个数代表着 taskmanager 可并行执行的 task 数。
2.2 生态
Spark:


Flink:
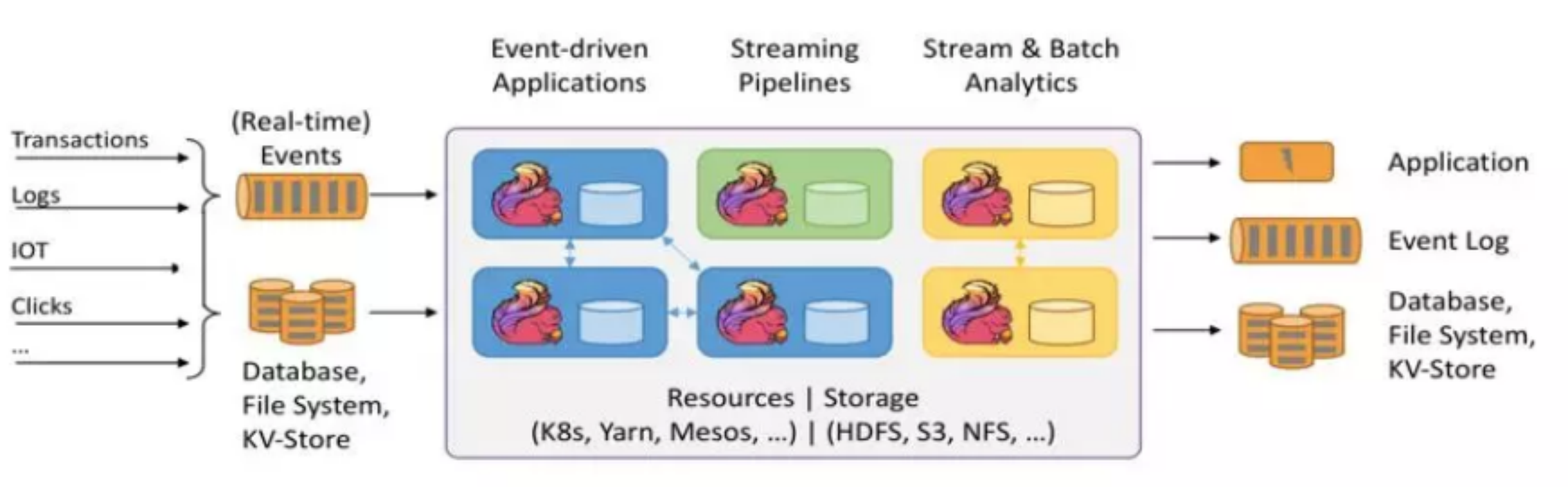
2.3 运行模型
Spark Streaming 是微批处理,运行的时候需要指定批处理的时间,每次运行 job 时处理一个批次的数据,流程如图所示:

Flink 是基于事件驱动的,事件可以理解为消息。事件驱动的应用程序是一种状态应用程序,它会从一个或者多个流中注入事件,通过触发计算更新状态,或外部动作对注入的事件作出反应。
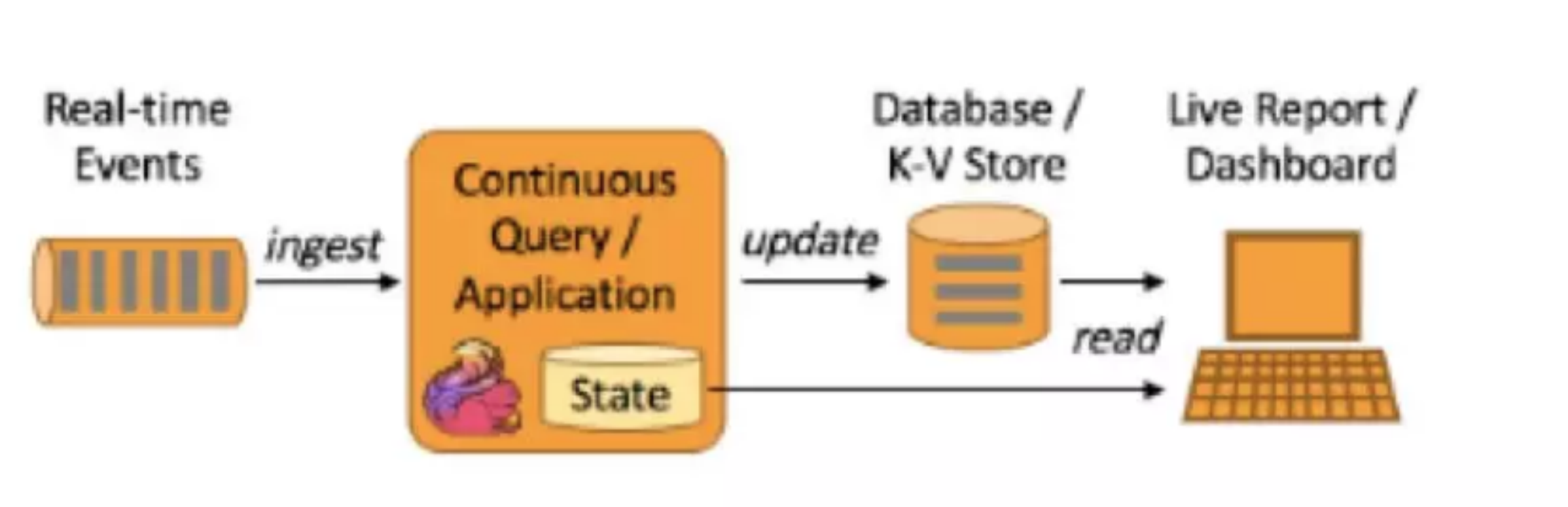
2.4 编程模型对比
编程模型对比,主要是对比 flink 和 Spark Streaming 两者在代码编写上的区别。
Spark Streaming 与 kafka 的结合主要是两种模型:
- 基于 receiver dstream;
- 基于 direct dstream。
以上两种模型编程近似,只是在 api 和内部数据获取有些区别,新版本的已经取消了基于 receiver 这种模式,企业中通常采用基于 direct Dstream 的模式。
val Array(brokers, topics) = args// 创建一个批处理时间是2s的context
val sparkConf = new SparkConf().setAppName("DirectKafkaWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(2))
// 使用broker和topic创建DirectStream
val topicsSet = topics.split(",").toSet
val kafkaParams = Map[String, String]("metadata.broker.list" -> brokers)
val messages = KafkaUtils.createDirectStream[String, String]( ssc, LocationStrategies.PreferConsistent, ConsumerStrategies.Subscribe[String, String](topicsSet, kafkaParams))
// Get the lines, split them into words, count the words and print
val lines = messages.map(_.value)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1L)).reduceByKey(_ + _)
wordCounts.print() // 启动流
ssc.start()
ssc.awaitTermination()
通过以上代码我们可以 get 到:
- 设置批处理时间
- 创建数据流
- 编写transform
- 编写action
- 启动执行
接下来看 flink 与 kafka 结合是如何编写代码的。Flink 与 kafka 结合是事件驱动,大家可能对此会有疑问,消费 kafka 的数据调用 poll 的时候是批量获取数据的(可以设置批处理大小和超时时间),这就不能叫做事件触发了。而实际上,flink 内部对 poll 出来的数据进行了整理,然后逐条 emit,形成了事件触发的机制。
下面的代码是 flink 整合 kafka 作为 data source 和 data sink:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.getConfig().disableSysoutLogging();
env.getConfig().setRestartStrategy(RestartStrategies.fixedDelayRestart(4, 10000));
// create a checkpoint every 5 seconds
env.enableCheckpointing(5000);
// make parameters available in the web interface
env.getConfig().setGlobalJobParameters(parameterTool);
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
// ExecutionConfig.GlobalJobParameters
env.getConfig().setGlobalJobParameters(null);
DataStream<KafkaEvent> input = env
.addSource(new FlinkKafkaConsumer010<>(
parameterTool.getRequired("input-topic"), new KafkaEventSchema(),
parameterTool.getProperties())
.assignTimestampsAndWatermarks(new CustomWatermarkExtractor()))
.setParallelism(1).rebalance()
.keyBy("word")
.map(new RollingAdditionMapper()).setParallelism(0);
input.addSink(new FlinkKafkaProducer010<>(parameterTool.getRequired("output-topic"), new KafkaEventSchema(),
parameterTool.getProperties()));
env.execute("Kafka 0.10 Example");
从 Flink 与 kafka 结合的代码可以 get 到:
- 注册数据 source
- 编写运行逻辑
- 注册数据 sink
- 调用 env.execute
相比于 Spark Streaming 少了设置批处理时间,还有一个显著的区别是 flink 的所有算子都是 lazy 形式的,调用 env.execute 会构建 jobgraph。client 端负责 Jobgraph 生成并提交它到集群运行;而 Spark Streaming的操作算子分 action 和 transform,其中仅有 transform 是 lazy 形式,而且 DGA 生成、stage 划分、任务调度是在 driver 端进行的,在 client 模式下 driver 运行于客户端处。
2.5 任务调度原理
Spark Streaming 任务如上文提到的是基于微批处理的,实际上每个批次都是一个 Spark Core 的任务。对于编码完成的 Spark Core 任务在生成到最终执行结束主要包括以下几个部分:
- 构建 DGA 图;
- 划分 stage;
- 生成 taskset;
- 调度 task。
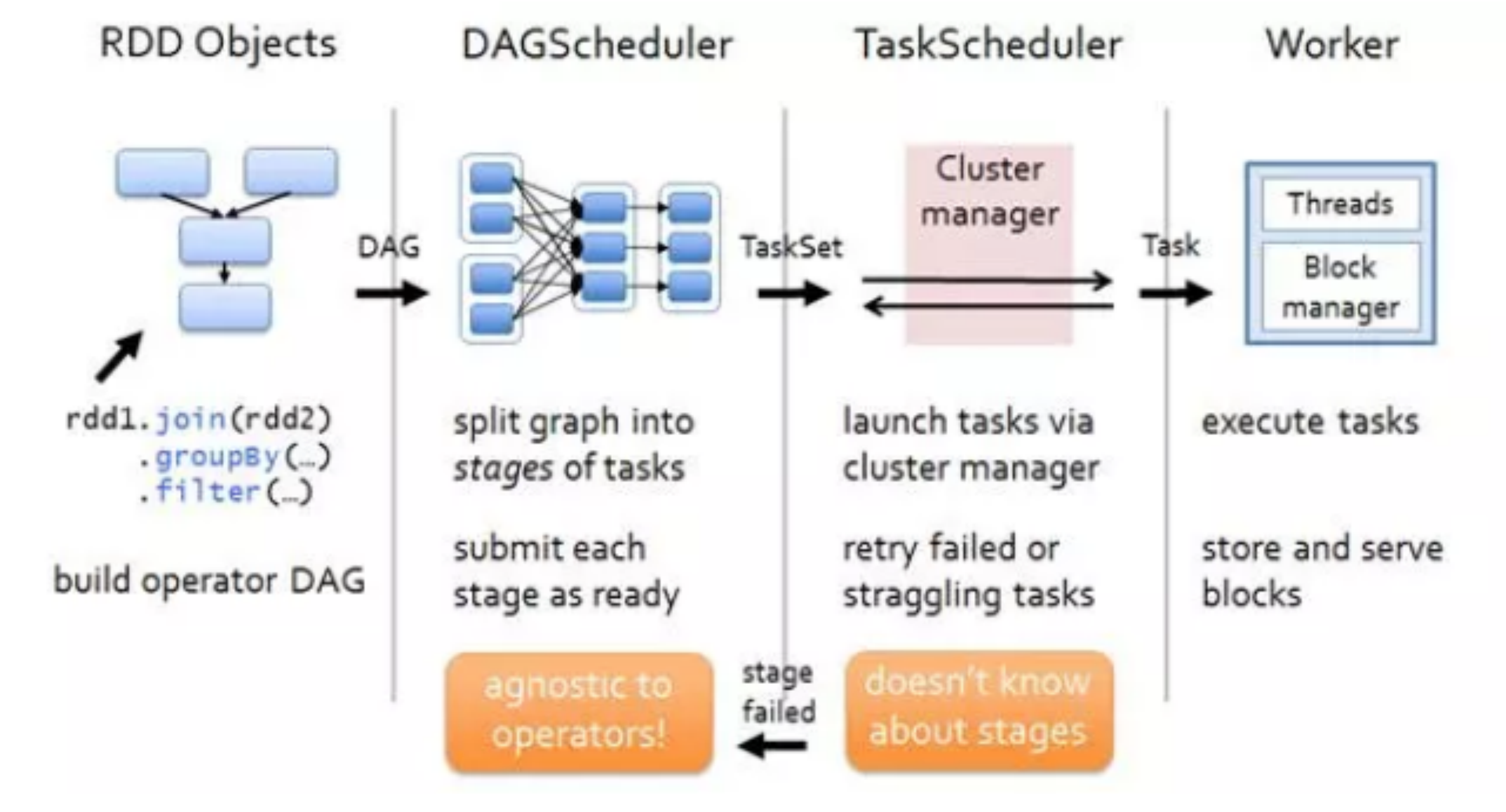
对于 job 的调度执行有 fifo 和 fair 两种模式,Task 是根据数据本地性调度执行的。 假设每个 Spark Streaming 任务消费的 kafka topic 有四个分区,中间有一个 transform操作(如 map)和一个 reduce 操作,如图所示:
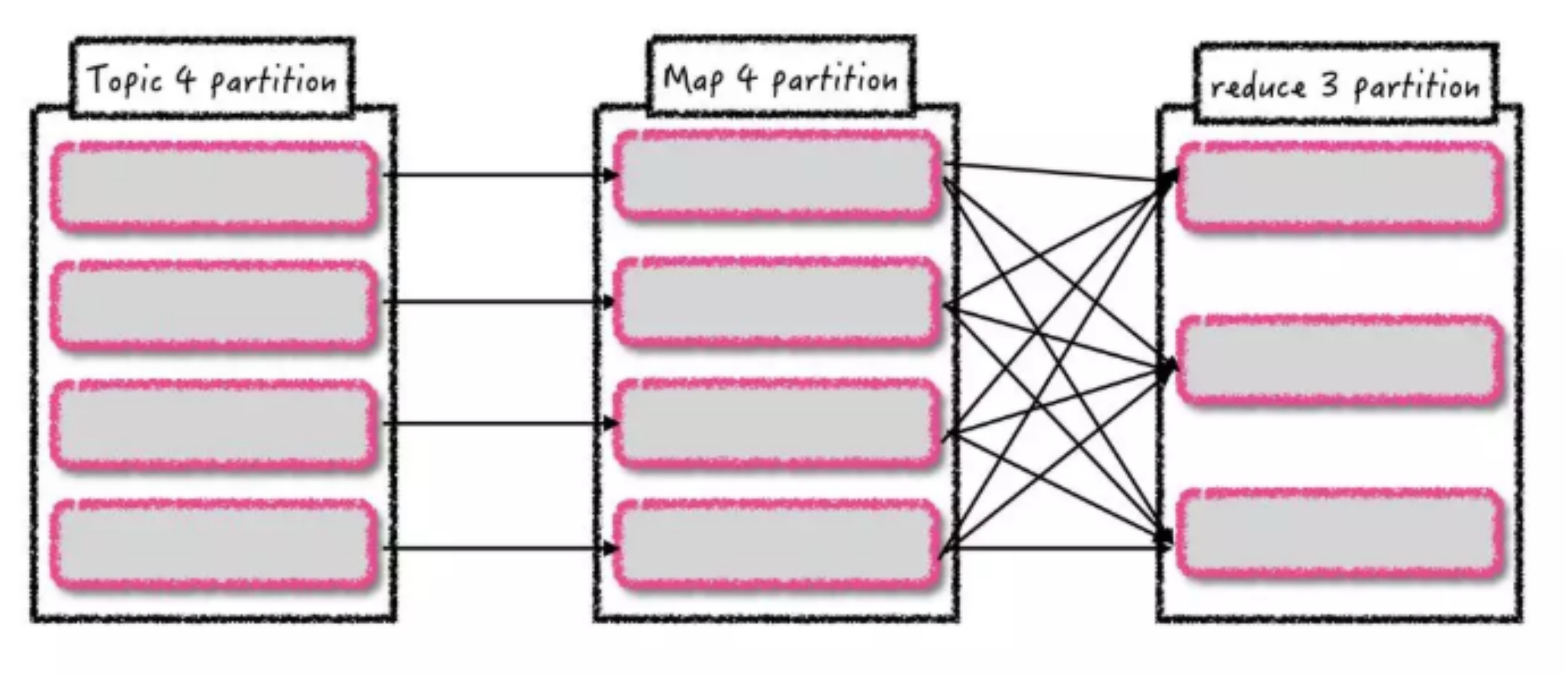
假设有两个 executor,其中每个 executor 三个核,那么每个批次相应的 task 运行位置是固定的吗?是否能预测? 由于数据本地性和调度不确定性,每个批次对应 kafka 分区生成的 task 运行位置并不是固定的。
对于 flink 的流任务客户端首先会生成 StreamGraph,接着生成 JobGraph,然后将 jobGraph 提交给 Jobmanager 由它完成 jobGraph 到 ExecutionGraph 的转变,最后由 jobManager 调度执行。
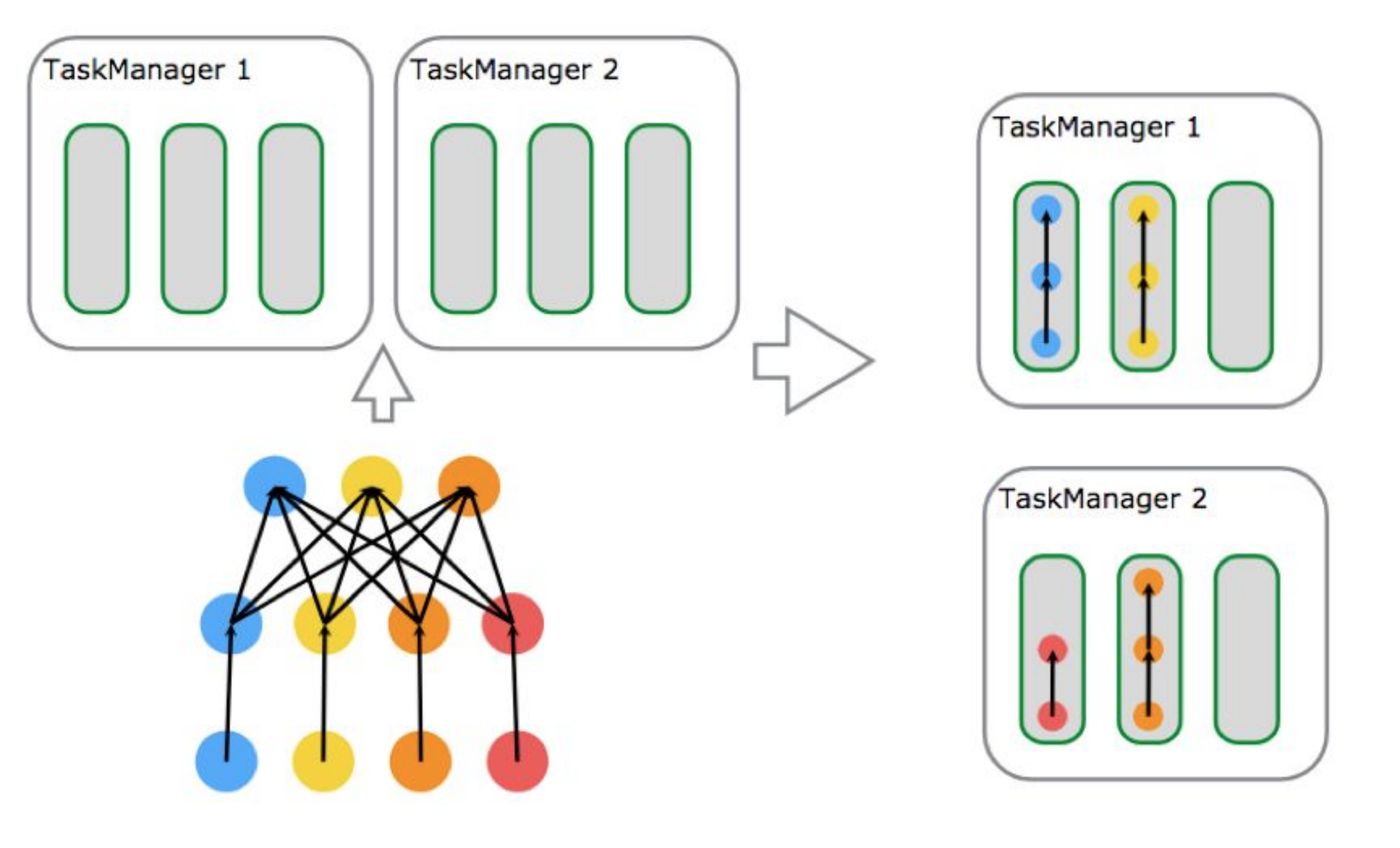
如图所示有一个由 data source、MapFunction和 ReduceFunction 组成的程序,data source 和 MapFunction 的并发度都为 4,而 ReduceFunction 的并发度为 3。一个数据流由 Source-Map-Reduce 的顺序组成,在具有 2 个TaskManager、每个 TaskManager 都有 3 个 Task Slot 的集群上运行。
可以看出 flink 的拓扑生成提交执行之后,除非故障,否则拓扑部件执行位置不变,并行度由每一个算子并行度决定,类似于 storm。而 spark Streaming 是每个批次都会根据数据本地性和资源情况进行调度,无固定的执行拓扑结构。 flink 是数据在拓扑结构里流动执行,而 Spark Streaming 则是对数据缓存批次并行处理。
2.6 时间机制对比
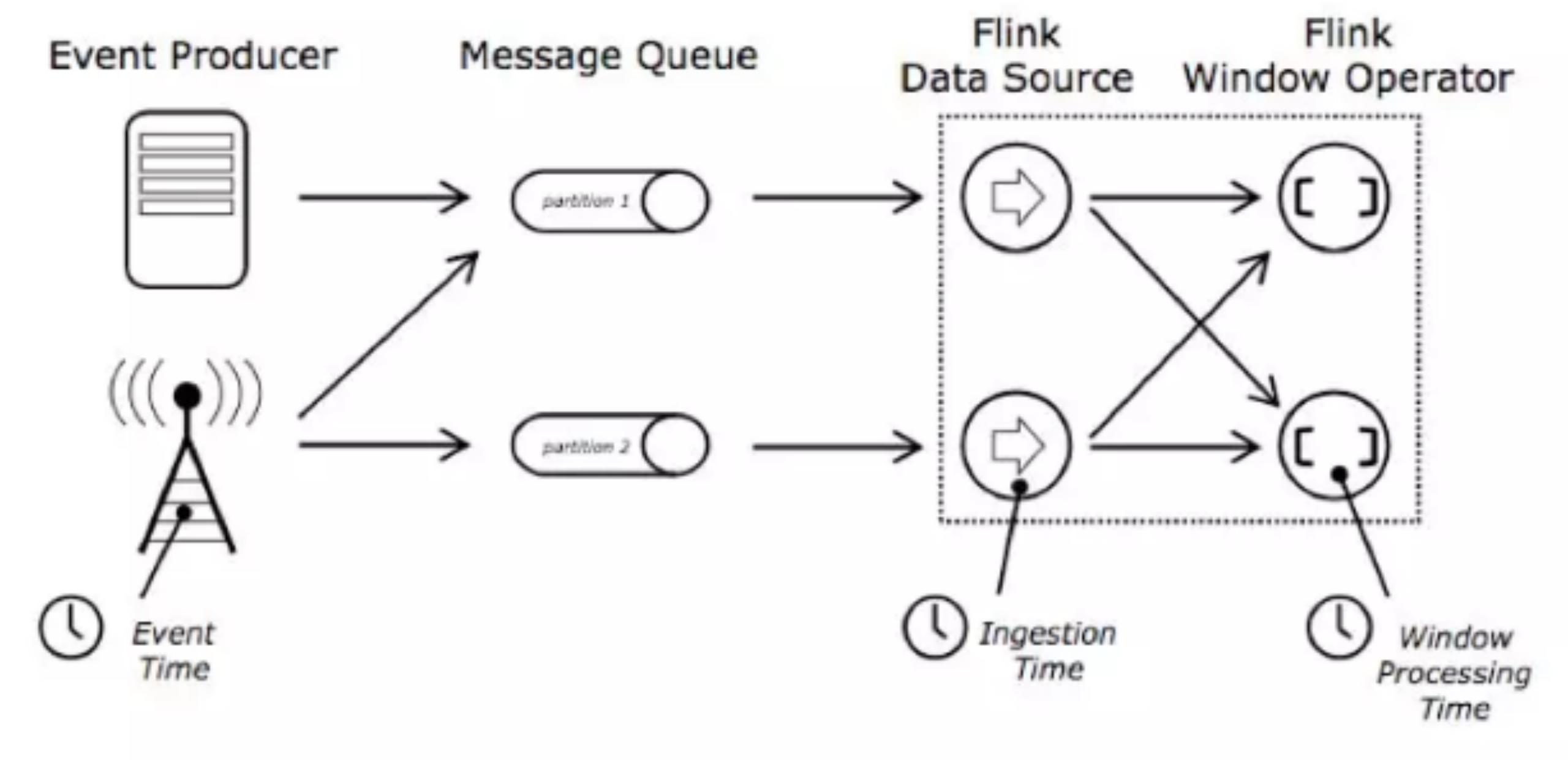
流处理的时间:流处理程序在时间概念上总共有三个时间概念:
-
处理时间:处理时间是指每台机器的系统时间,当流程序采用处理时间时将使用运行各个运算符实例的机器时间。处理时间是最简单的时间概念,不需要流和机器之间的协调,它能提供最好的性能和最低延迟。然而在分布式和异步环境中,处理时间不能提供消息事件的时序性保证,因为它受到消息传输延迟,消息在算子之间流动的速度等方面制约。
-
事件时间:事件时间是指事件在其设备上发生的时间,这个时间在事件进入 flink 之前已经嵌入事件,然后 flink 可以提取该时间。基于事件时间进行处理的流程序可以保证事件在处理的时候的顺序性,但是基于事件时间的应用程序必须要结合 watermark 机制。基于事件时间的处理往往有一定的滞后性,因为它需要等待后续事件和处理无序事件,对于时间敏感的应用使用的时候要慎重考虑。
-
注入时间:注入时间是事件注入到 flink 的时间。事件在 source 算子处获取 source 的当前时间作为事件注入时间,后续的基于时间的处理算子会使用该时间处理数据。
相比于事件时间,注入时间不能够处理无序事件或者滞后事件,但是应用程序无序指定如何生成 watermark。在内部注入时间程序的处理和事件时间类似,但是时间戳分配和 watermark 生成都是自动的。
Spark 时间机制:Spark Streaming 只支持处理时间,Structured streaming 支持处理时间和事件时间,同时支持 watermark 机制处理滞后数据。
Flink 时间机制:flink 支持三种时间机制:事件时间,注入时间,处理时间,同时支持 watermark 机制处理滞后数据。
2.7 kafka 动态分区检测
2.7.1 Spark Streaming
Spark Streaming:对于有实时处理业务需求的企业,随着业务增长数据量也会同步增长,将导致原有的 kafka 分区数不满足数据写入所需的并发度,需要扩展 kafka 的分区或者增加 kafka 的 topic,这时就要求实时处理程序,如 SparkStreaming、flink 能检测到 kafka 新增的 topic 、分区及消费新增分区的数据。
接下来结合源码分析,Spark Streaming 和 flink 在 kafka 新增 topic 或 partition 时能否动态发现新增分区并消费处理新增分区的数据。 Spark Streaming 与 kafka 结合有两个区别比较大的版本,如图所示是官网给出的对比数据:
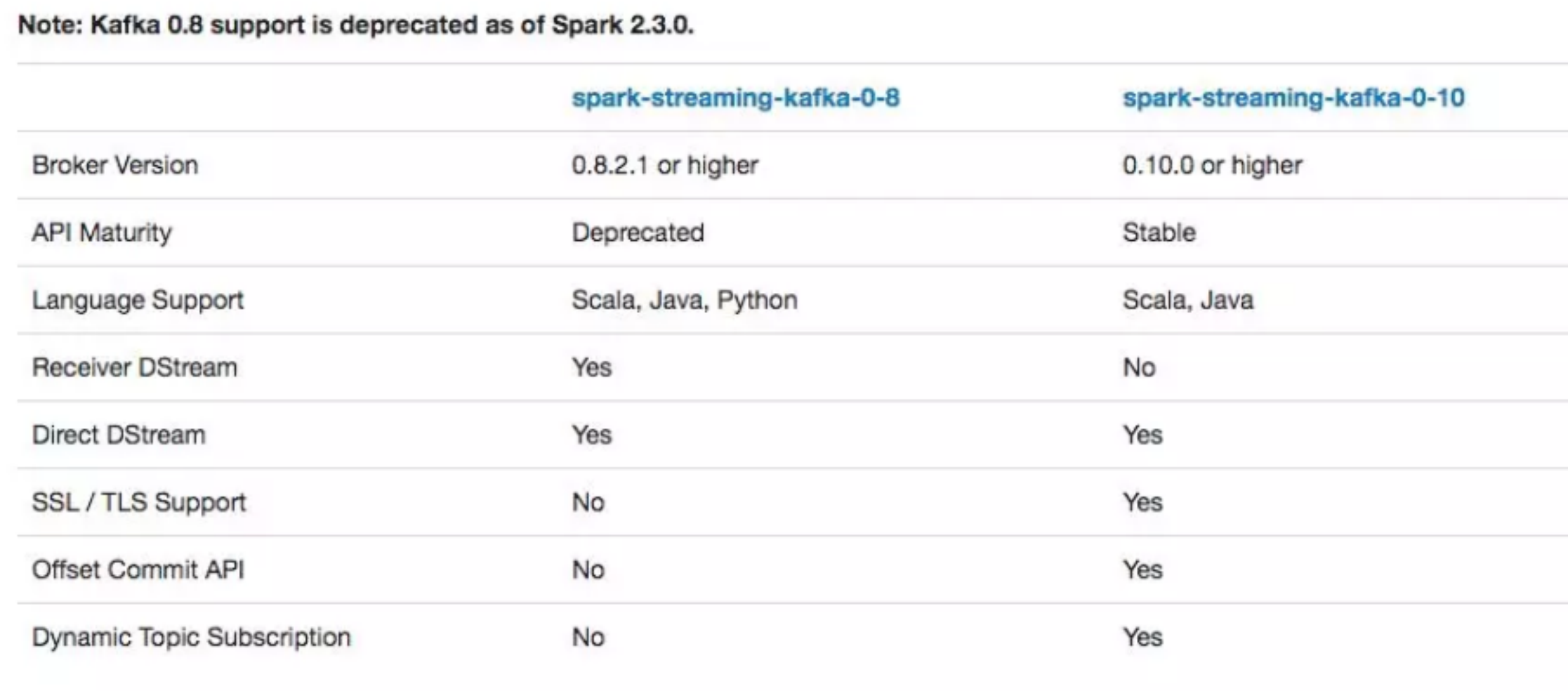
其中确认的是 Spark Streaming 与 kafka 0.8 版本结合不支持动态分区检测,与 0.10 版本结合支持,接着通过源码分析。
Spark Streaming 与 kafka 0.8 版本结合(源码分析只针对是否分区检测),入口是 DirectKafkaInputDStream 的 compute:
// 改行代码会计算这个job,要消费的每个kafka分区的最大偏移
override def compute(validTime: Time): Option[KafkaRDD[K, V, U, T, R]] = {
// 构建KafkaRDD,用指定的分区数和要消费的offset范围
val untilOffsets = clamp(latestLeaderOffsets(maxRetries))
val rdd = KafkaRDD[K, V, U, T, R](
// Report the record number and metadata of this batch interval to InputInfoTracker.
context.sparkContext, kafkaParams, currentOffsets, untilOffsets, messageHandler)
val offsetRanges = currentOffsets.map {
case (tp, fo) =>
val uo = untilOffsets(tp)
OffsetRange(tp.topic, tp.partition, fo, uo.offset)
}
val description = offsetRanges.filter {
offsetRange =>
// Don't display empty ranges.
offsetRange.fromOffset != offsetRange.untilOffset
}.map {
offsetRange =>
// Copy offsetRanges to immutable.List to prevent from being modified by the user
s"topic: ${offsetRange.topic}\tpartition: ${offsetRange.partition}\t" +
s"offsets: ${offsetRange.fromOffset} to ${offsetRange.untilOffset}"
}.mkString("\n")
val metadata = Map("offsets" -> offsetRanges.toList,
StreamInputInfo.METADATA_KEY_DESCRIPTION -> description)
val inputInfo = StreamInputInfo(id, rdd.count, metadata)
ssc.scheduler.inputInfoTracker.reportInfo(validTime, inputInfo)
currentOffsets = untilOffsets.map(kv => kv._1 -> kv._2.offset)
Some(rdd)
}
第一行就是计算得到该批次生成 KafkaRDD 每个分区要消费的最大 offset。 接着看 latestLeaderOffsets(maxRetries):
// 可以看到的是用来指定获取最大偏移分区的列表还是只有currentOffsets,没有发现关于新增的分区的内容。
@tailrec protected final def latestLeaderOffsets(retries: Int): Map[TopicAndPartition, LeaderOffset] = {
val o = kc.getLatestLeaderOffsets(currentOffsets.keySet)
// Either.fold would confuse @tailrec, do it manually
if (o.isLeft) {
val err = o.left.get.toString
if (retries <= 0) {
throw new SparkException(err)
} else {
logError(err)
Thread.sleep(kc.config.refreshLeaderBackoffMs)
latestLeaderOffsets(retries - 1)
}
} else {
o.right.get
}
}
其中 protected var currentOffsets = fromOffsets,这个仅仅是在构建 DirectKafkaInputDStream 的时候初始化,并在 compute 里面更新:
currentOffsets = untilOffsets.map(kv => kv._1 -> kv._2.offset)
中间没有检测 kafka 新增 topic 或者分区的代码,所以可以确认 Spark Streaming 与 kafka 0.8 的版本结合不支持动态分区检测。
Spark Streaming 与 kafka 0.10 版本结合:入口同样是 DirectKafkaInputDStream 的 compute 方法,捡主要的部分说,Compute 里第一行也是计算当前 job 生成 kafkardd 要消费的每个分区的最大 offset:
// 获取当前生成job,要用到的KafkaRDD每个分区最大消费偏移值
val untilOffsets = clamp(latestOffsets())
具体检测 kafka 新增 topic 或者分区的代码在 latestOffsets()
/** * Returns the latest (highest) available offsets, taking new partitions into account. */
protected def latestOffsets(): Map[TopicPartition, Long] = {
val c = consumer
paranoidPoll(c) // 获取所有的分区信息
// make sure new partitions are reflected in currentOffsets
val parts = c.assignment().asScala
// 做差获取新增的分区信息
val newPartitions = parts.diff(currentOffsets.keySet)
// position for new partitions determined by auto.offset.reset if no commit
// 新分区消费位置,没有记录的化是由auto.offset.reset决定
currentOffsets = currentOffsets ++ newPartitions.map(tp => tp -> c.position(tp)).toMap
// don't want to consume messages, so pause
c.pause(newPartitions.asJava) // find latest available offsets
c.seekToEnd(currentOffsets.keySet.asJava)
parts.map(tp => tp -> c.position(tp)).toMap
}
该方法内有获取 kafka 新增分区,并将其更新到 currentOffsets 的过程,所以可以验证 Spark Streaming 与 kafka 0.10 版本结合支持动态分区检测。
2.7.2 Flink
入口类是 FlinkKafkaConsumerBase,该类是所有 flink 的 kafka 消费者的父类。
在 FlinkKafkaConsumerBase 的 run 方法中,创建了 kafkaFetcher,实际上就是消费者:
this.kafkaFetcher = createFetcher(
sourceContext,
subscribedPartitionsToStartOffsets,
periodicWatermarkAssigner,
punctuatedWatermarkAssigner,
(StreamingRuntimeContext) getRuntimeContext(),
offsetCommitMode,
getRuntimeContext().getMetricGroup().addGroup(KAFKA_CONSUMER_METRICS_GROUP),
useMetrics);
接是创建了一个线程,该线程会定期检测 kafka 新增分区,然后将其添加到 kafkaFetcher 里。
if (discoveryIntervalMillis != PARTITION_DISCOVERY_DISABLED) {
final AtomicReference<Exception> discoveryLoopErrorRef = new AtomicReference<>();
this.discoveryLoopThread = new Thread(new Runnable() {
@Override
public void run() {
try {
// --------------------- partition discovery loop ---------------------
List<KafkaTopicPartition> discoveredPartitions;
// throughout the loop, we always eagerly check if we are still running before
// performing the next operation, so that we can escape the loop as soon as possible
while (running) {
if (LOG.isDebugEnabled()) {
LOG.debug("Consumer subtask {} is trying to discover new partitions ...", getRuntimeContext().getIndexOfThisSubtask());
}
try {
discoveredPartitions = partitionDiscoverer.discoverPartitions();
} catch (AbstractPartitionDiscoverer.WakeupException | AbstractPartitionDiscoverer.ClosedException e) {
// the partition discoverer may have been closed or woken up before or during the discovery;
// this would only happen if the consumer was canceled; simply escape the loop
break;
}
// no need to add the discovered partitions if we were closed during the meantime
if (running && !discoveredPartitions.isEmpty()) {
kafkaFetcher.addDiscoveredPartitions(discoveredPartitions);
}
// do not waste any time sleeping if we're not running anymore
if (running && discoveryIntervalMillis != 0) {
try {
Thread.sleep(discoveryIntervalMillis);
} catch (InterruptedException iex) {
// may be interrupted if the consumer was canceled midway; simply escape the loop
break;
}
}
}
} catch (Exception e) {
discoveryLoopErrorRef.set(e);
} finally {
// calling cancel will also let the fetcher loop escape
// (if not running, cancel() was already called)
if (running) {
cancel();
}
}
}
}, "Kafka Partition Discovery for " + getRuntimeContext().getTaskNameWithSubtasks());
}
discoveryLoopThread.start();
kafkaFetcher.runFetchLoop();
上面,就是 flink 动态发现 kafka 新增分区的过程。不过与 Spark 无需做任何配置不同的是,flink 动态发现 kafka 新增分区,这个功能时需要被开启的。也很简单,需要将 flink.partition-discovery.interval-millis 该属性设置为大于 0 即可。
2.8 容错机制及处理语义
抛出一个问题:实时处理的时候,如何保证数据仅一次处理语义?
2.8.1 Spark Streaming 保证仅一次处理
对于 Spark Streaming 任务,我们可以设置 checkpoint,然后假如发生故障并重启,我们可以从上次 checkpoint 之处恢复,但是这个行为只能使得数据不丢失,可能会重复处理,不能做到恰一次处理语义。
对于 Spark Streaming 与 kafka 结合的 direct Stream 可以自己维护 offset 到 zookeeper、kafka 或任何其它外部系统,每次提交完结果之后再提交 offset,这样故障恢复重启可以利用上次提交的 offset 恢复,保证数据不丢失。但是假如故障发生在提交结果之后、提交 offset 之前会导致数据多次处理,这个时候我们需要保证处理结果多次输出不影响正常的业务。
由此可以分析,假设要保证数据恰一次处理语义,那么结果输出和 offset 提交必须在一个事务内完成。在这里有以下两种做法:
- repartition(1) : Spark Streaming 输出的 action 变成仅一个 partition,这样可以利用事务去做:
rdd.repartition(1).foreachPartition(partition=>{
// 开启事务
partition.foreach(each=>{
//提交数据
}) // 提交事务
})
})
将结果和 offset 一起提交: 也就是结果数据包含 offset。这样提交结果和提交 offset 就是一个操作完成,不会数据丢失,也不会重复处理。故障恢复的时候可以利用上次提交结果带的 offset。
2.8.2 Flink 与 kafka 0.11 保证仅一次处理
若要 sink 支持仅一次语义,必须以事务的方式写数据到 Kafka,这样当提交事务时两次 checkpoint 间的所有写入操作作为一个事务被提交。这确保了出现故障或崩溃时这些写入操作能够被回滚。
在一个分布式且含有多个并发执行 sink 的应用中,仅仅执行单次提交或回滚是不够的,因为所有组件都必须对这些提交或回滚达成共识,这样才能保证得到一致性的结果。Flink 使用两阶段提交协议以及预提交(pre-commit)阶段来解决这个问题。
本例中的 Flink 应用如图 11 所示包含以下组件:
- 一个source,从Kafka中读取数据(即KafkaConsumer)
- 一个时间窗口化的聚会操作
- 一个sink,将结果写回到Kafka(即KafkaProducer)
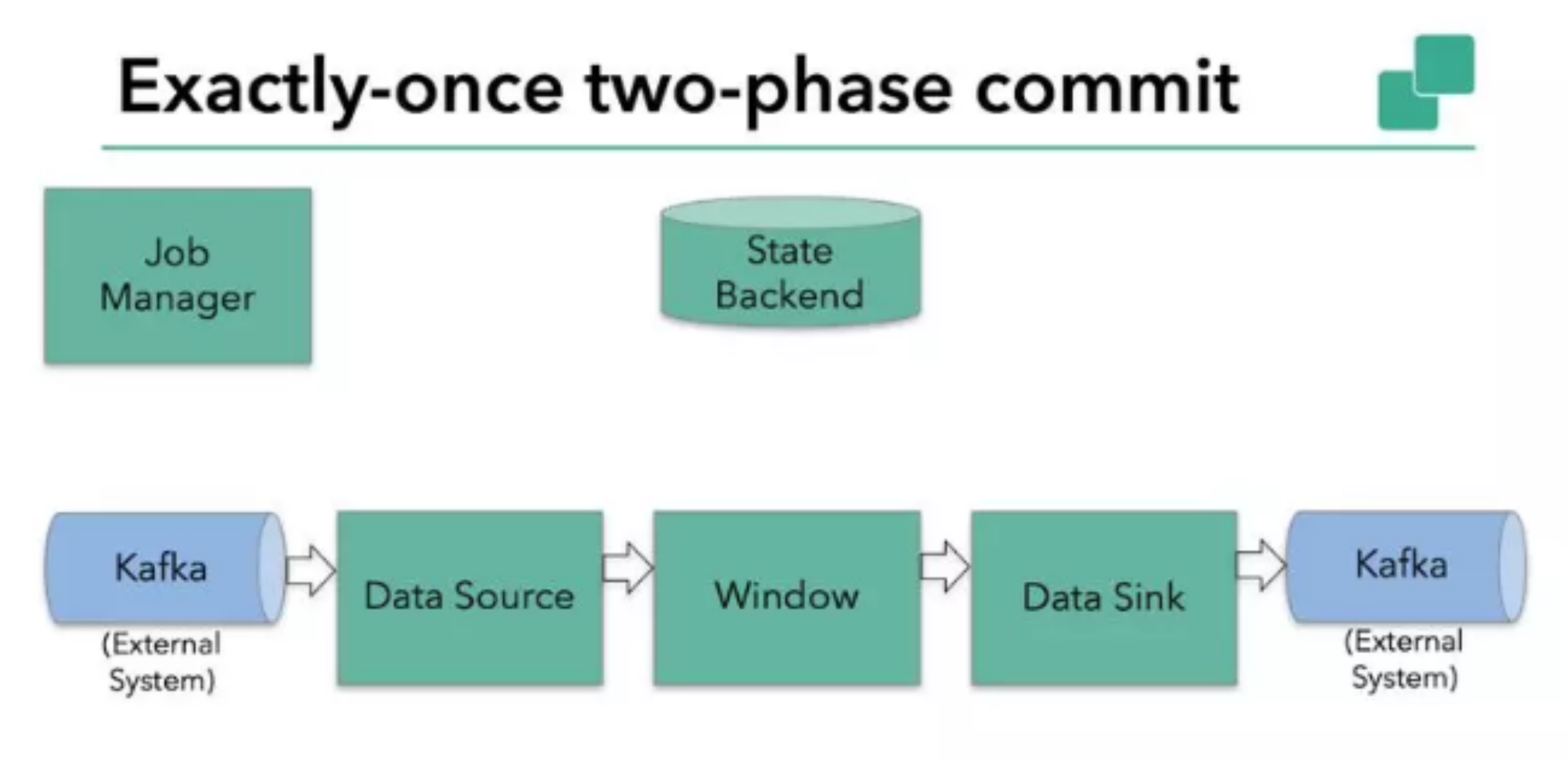
下面详细讲解 flink 的两段提交思路:
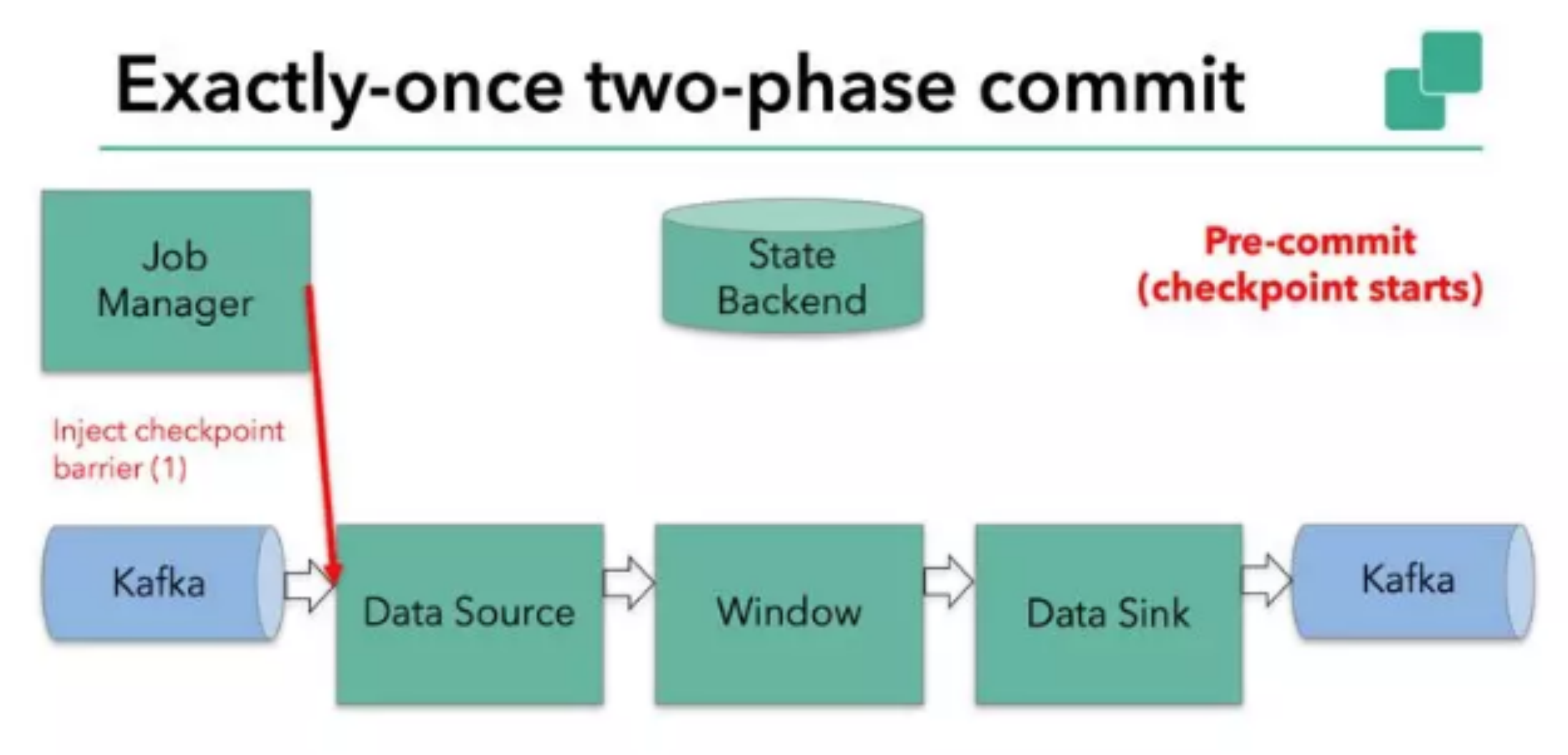
如图所示,Flink checkpointing 开始时便进入到 pre-commit 阶段。具体来说,一旦 checkpoint 开始,Flink 的 JobManager 向输入流中写入一个 checkpoint barrier ,将流中所有消息分割成属于本次 checkpoint 的消息以及属于下次 checkpoint 的,barrier 也会在操作算子间流转。对于每个 operator 来说,该 barrier 会触发 operator 状态后端为该 operator 状态打快照。data source 保存了 Kafka 的 offset,之后把 checkpoint barrier 传递到后续的 operator。
这种方式仅适用于 operator 仅有它的内部状态。内部状态是指 Flink state backends 保存和管理的内容(如第二个 operator 中 window 聚合算出来的 sum)。
当一个进程仅有它的内部状态的时候,除了在 checkpoint 之前将需要将数据更改写入到 state backend,不需要在预提交阶段做其他的动作。在 checkpoint 成功的时候,Flink 会正确的提交这些写入,在 checkpoint 失败的时候会终止提交,过程可见图。
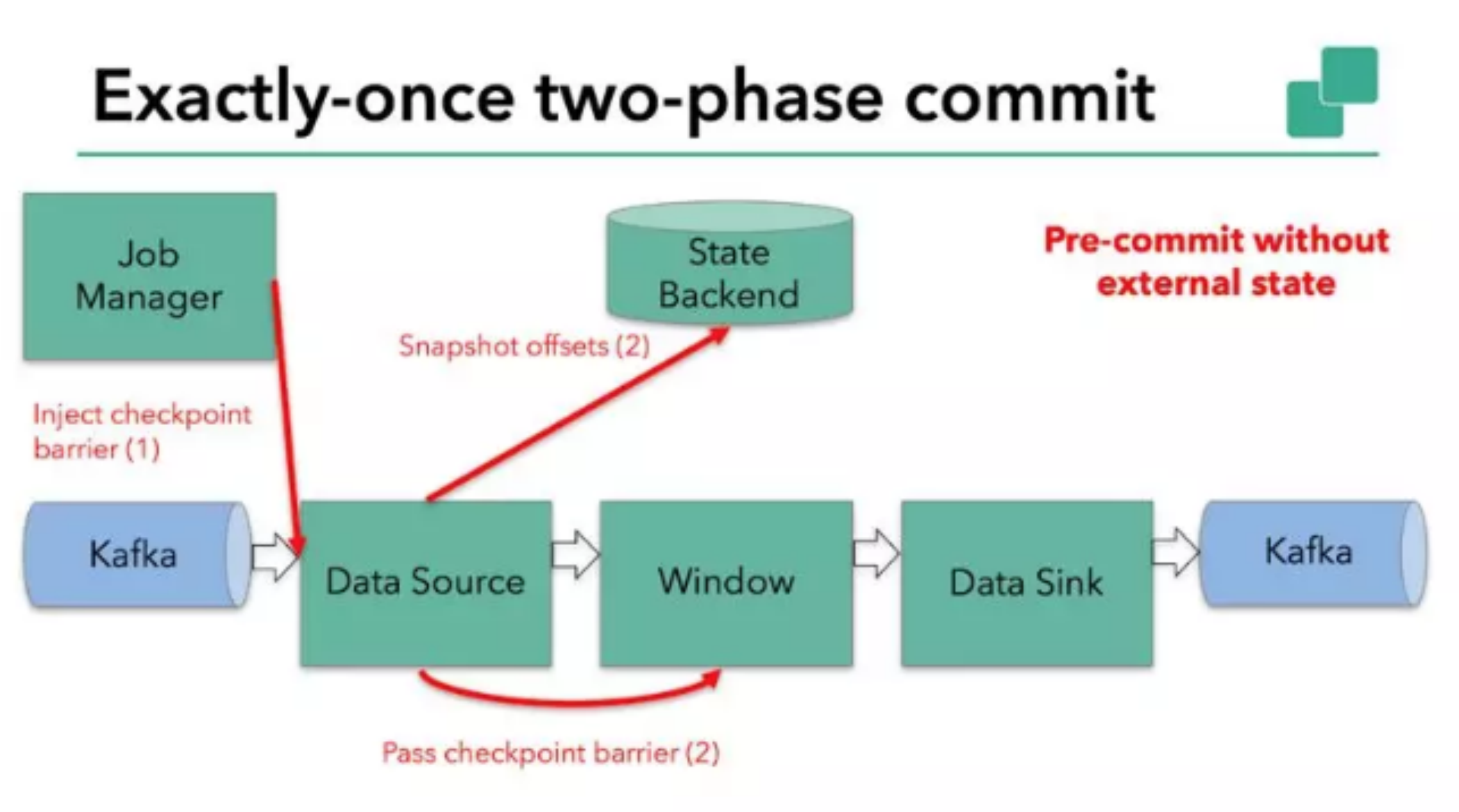
当结合外部系统的时候,外部系统必须要支持可与两阶段提交协议捆绑使用的事务。显然本例中的 sink 由于引入了 kafka sink,因此在预提交阶段 data sink 必须预提交外部事务。如下图:
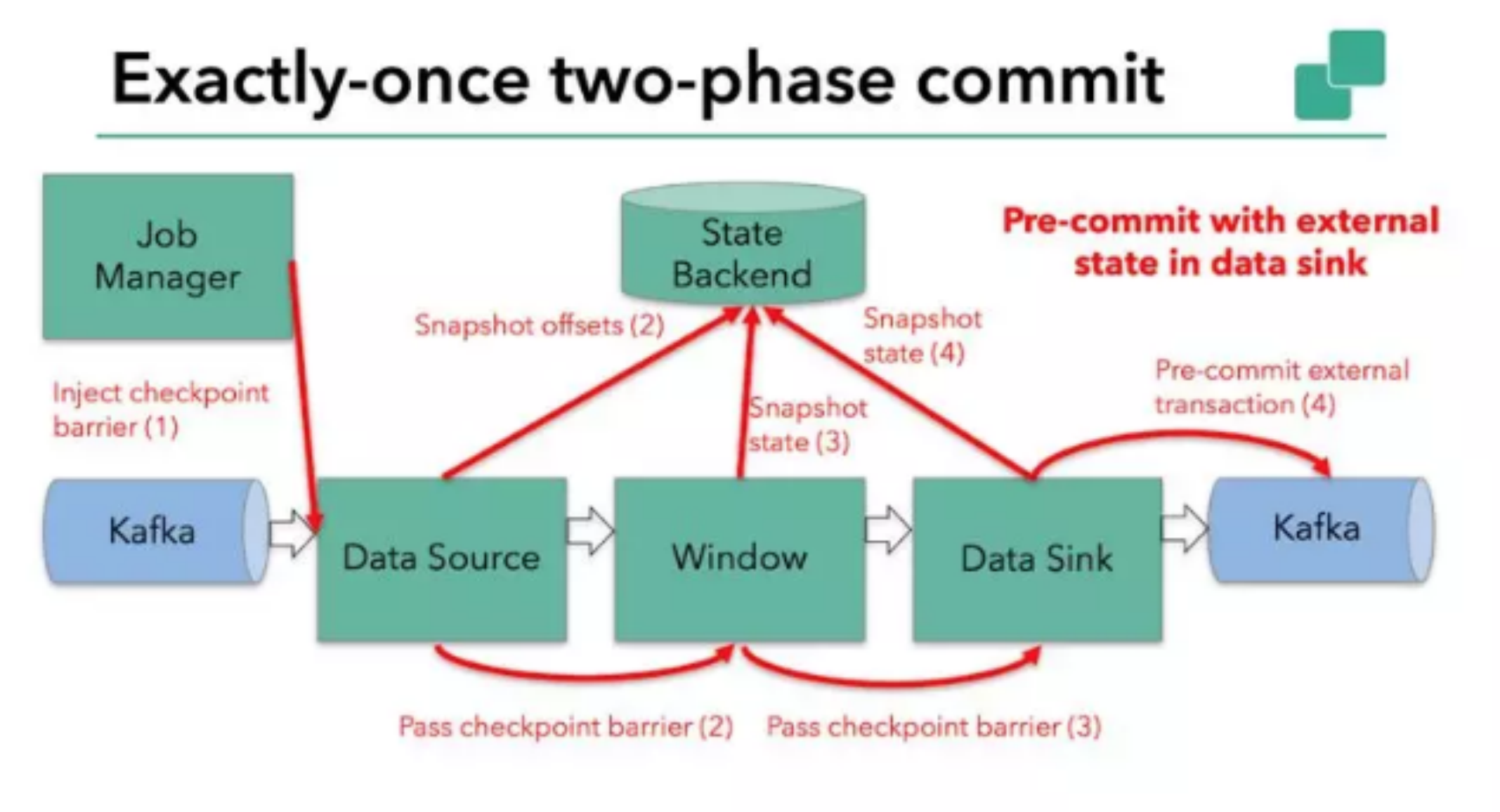
当 barrier 在所有的算子中传递一遍,并且触发的快照写入完成,预提交阶段完成。所有的触发状态快照都被视为 checkpoint 的一部分,也可以说 checkpoint 是整个应用程序的状态快照,包括预提交外部状态。出现故障可以从 checkpoint 恢复。下一步就是通知所有的操作算子 checkpoint 成功。该阶段 jobmanager 会为每个 operator 发起 checkpoint 已完成的回调逻辑。
本例中 data source 和窗口操作无外部状态,因此该阶段,这两个算子无需执行任何逻辑,但是 data sink 是有外部状态的,因此,此时我们必须提交外部事务,如下图: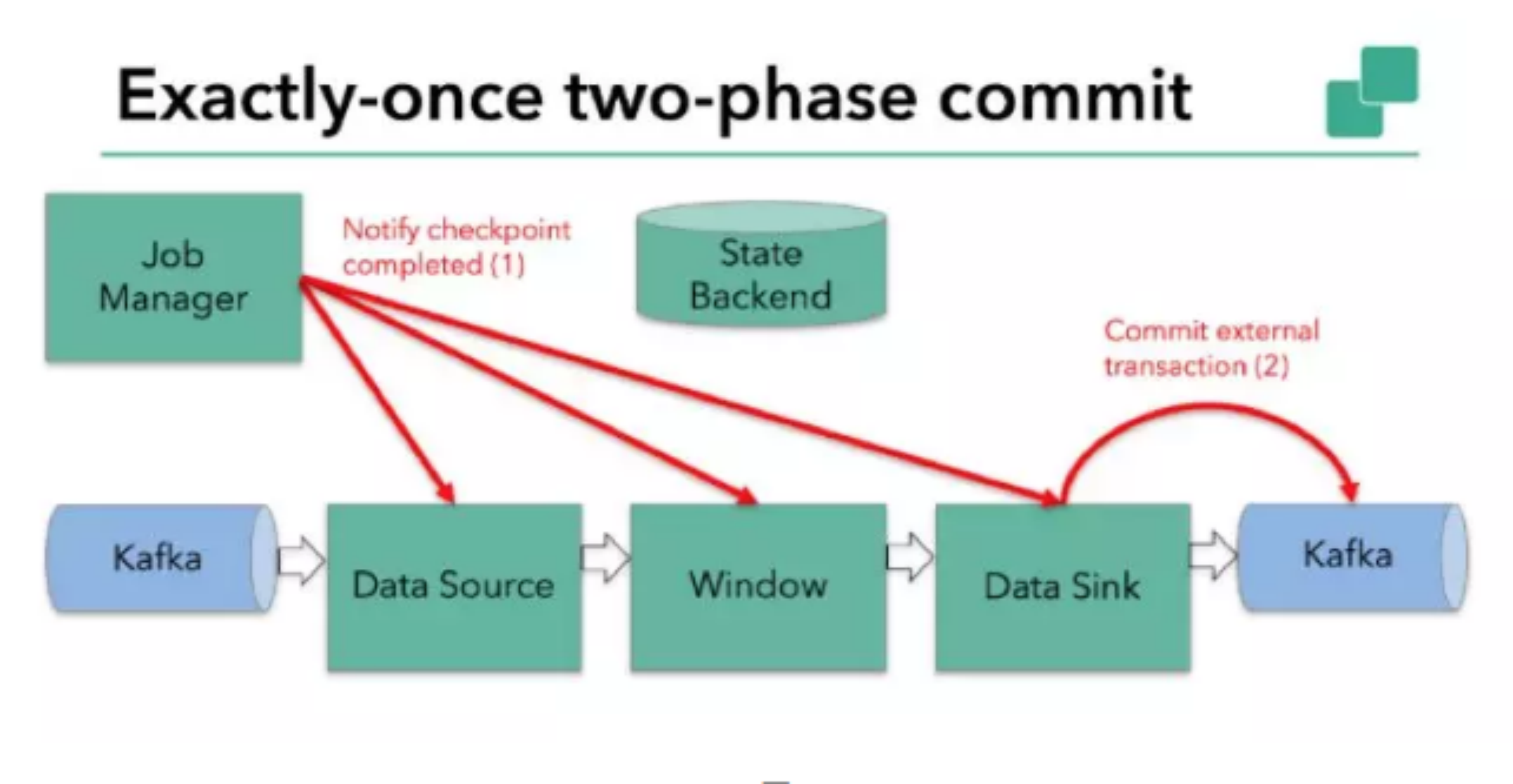
以上就是 flink 实现恰一次处理的基本逻辑。
2.9 Back pressure背压/反压
消费者消费的速度低于生产者生产的速度,为了使应用正常,消费者会反馈给生产者来调节生产者生产的速度,以使得消费者需要多少,生产者生产多少。
- back pressure 后面一律称为背压。
2.9.1 Spark Streaming 的背压
Spark Streaming 跟 kafka 结合是存在背压机制的,目标是根据当前 job 的处理情况来调节后续批次的获取 kafka 消息的条数。为了达到这个目的,Spark Streaming 在原有的架构上加入了一个 RateController,利用的算法是 PID,需要的反馈数据是任务处理的结束时间、调度时间、处理时间、消息条数,这些数据是通过 SparkListener 体系获得,然后通过 PIDRateEsimator 的 compute 计算得到一个速率,进而可以计算得到一个 offset,然后跟限速设置最大消费条数比较得到一个最终要消费的消息最大 offset。
PIDRateEsimator 的 compute 方法如下:
def compute(time: Long, // in milliseconds
numElements: Long,
processingDelay: Long, // in milliseconds
schedulingDelay: Long // in milliseconds
): Option[Double] = {
logTrace(s"\ntime = $time, # records = $numElements, " +
s"processing time = $processingDelay, scheduling delay = $schedulingDelay")
this.synchronized {
if (time > latestTime && numElements > 0 && processingDelay > 0) {
val delaySinceUpdate = (time - latestTime).toDouble / 1000
val processingRate = numElements.toDouble / processingDelay * 1000
val error = latestRate - processingRate
val historicalError = schedulingDelay.toDouble * processingRate / batchIntervalMillis
// in elements/(second ^ 2)
val dError = (error - latestError) / delaySinceUpdate
val newRate = (latestRate - proportional * error -
integral * historicalError -
derivative * dError).max(minRate)
logTrace(s""" | latestRate = $latestRate, error = $error
| latestError = $latestError, historicalError = $historicalError
| delaySinceUpdate = $delaySinceUpdate, dError = $dError
""".stripMargin)
latestTime = time
if (firstRun) {
latestRate = processingRate
latestError = 0D
firstRun = false
logTrace("First run, rate estimation skipped")
None
} else {
latestRate = newRate
latestError = error
logTrace(s"New rate = $newRate")
Some(newRate)
}
} else {
logTrace("Rate estimation skipped")
None
}
}
}
2.9.2 Flink 的背压
与 Spark Streaming 的背压不同的是,Flink 1.5 之后实现了自己托管的 credit – based 流控机制,在应用层模拟 TCP 的流控机制,就是每一次 ResultSubPartition 向 InputChannel 发送消息的时候都会发送一个 backlog size 告诉下游准备发送多少消息,下游就会去计算有多少的 Buffer 去接收消息,算完之后如果有充足的 Buffer 就会返还给上游一个 Credit 告知他可以发送消息
jobmanager 针对每一个 task 每 50ms 触发 100 次 Thread.getStackTrace() 调用,求出阻塞的占比。过程如图 所示:
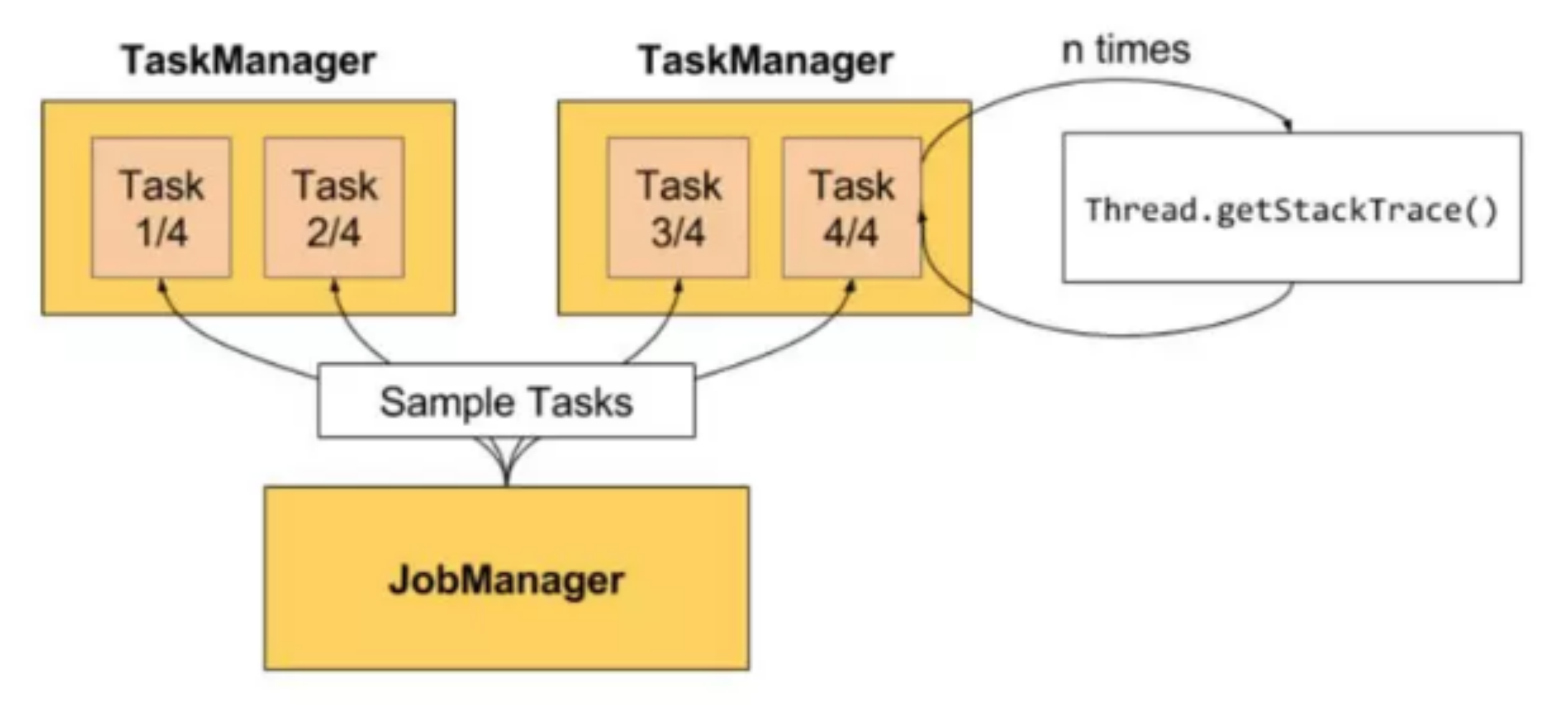
阻塞占比在 web 上划分了三个等级:
- OK: 0 <= Ratio <= 0.10,表示状态良好;
- LOW: 0.10 < Ratio <= 0.5,表示有待观察;
- HIGH: 0.5 < Ratio <= 1,表示要处理了。
例如,0.01,代表着100次中有一次阻塞在内部调用
03 文末
本文主要讲解了Flink与Spark的对比,谢谢大家的阅读,本文完!
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/234446.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
