大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
如何理解特征值和特征向量
此部分参考了马同学的文章:如何理解矩阵特征值和特征向量?
我们知道一个矩阵可以看做是线性变换又或者是某种运动,可以将一个向量进行旋转,平移等等操作,正常来说,对于一个向量 v v v,并对其乘上一个A会出现下图的情况:
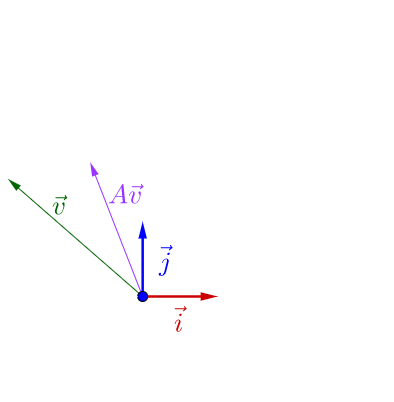

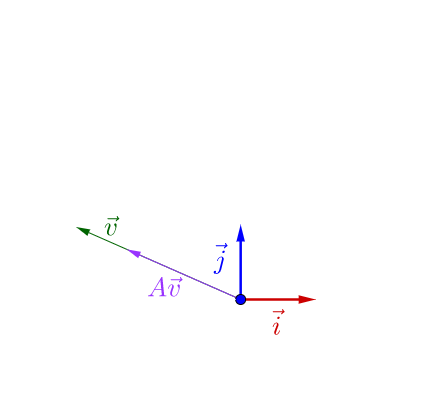
可以看到乘了A之后v发生了一些旋转。然而所有向量中存在一种稳定的向量,他不会发生旋转,平移,只会使得向量变长或变短,而这种稳定的向量正是矩阵的特征向量,即满足公式:
A v = λ v Av=\lambda v Av=λv
这里 λ \lambda λ决定了向量到底是伸长还是缩短
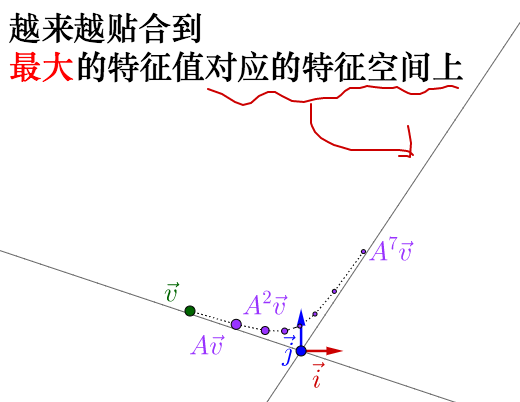
特征向量描述运动的方向
此外特征向量一个非常重要的特质是他描述了运动的方向,如果我们对一个向量持续地去乘以A会发生什么?我们发现,经过不断的运动,变换后的向量会收敛到特征值最大的特征向量上:
为什么会这样呢?不妨假设现在有一个n维向量v:
v = ( v 1 , v 2 , … , v n ) v =( v_{1} ,v_{2} ,\dotsc ,v_{n}) v=(v1,v2,…,vn)
于是我们不停地乘以W
W v = ( ∑ i = 1 n w 1 , i v i , ∑ i = 1 n W 2 , i v i , … , ∑ i = 1 n W n , i v i ) W 2 v = ( ∑ i , j = 1 n w 1 , j W j , i v i , … , ∑ i , j = 1 n W n , j W j , i v i ) \begin{aligned} Wv & =\left(\sum ^{n}_{i=1} w_{1,i} v_{i} ,\sum ^{n}_{i=1} W_{2,i} v_{i} ,\dotsc ,\sum ^{n}_{i=1} W_{n,i} v_{i}\right)\\ W^{2} v & =\left(\sum ^{n}_{i,j=1} w_{1,j} W_{j,i} v_{i} ,\dotsc ,\sum ^{n}_{i,j=1} W_{n,j} W_{j,i} v_{i}\right) \end{aligned} WvW2v=(i=1∑nw1,ivi,i=1∑nW2,ivi,…,i=1∑nWn,ivi)=(i,j=1∑nw1,jWj,ivi,…,i,j=1∑nWn,jWj,ivi)
好像除了变得很复杂以外,并没有看出什么东西,但是如果我们用一组特征向量u来表达向量v,因为特征向量是相互正交的基,因此向量v可以由特征向量u的线性组合表示:
v = α 1 u 1 + α 2 u 2 + ⋯ + α n u n v =\alpha _{1} u_{1} +\alpha _{2} u_{2} +\cdots +\alpha _{n} u_{n} v=α1u1+α2u2+⋯+αnun
接下来由于特征向量的稳定性,我们发现向量v的变化其实是这样的:
W v = μ 1 α 1 u 1 + μ 2 α 2 u 2 + ⋯ + μ n α n u n W 2 v = μ 1 2 α 1 u 1 + μ 2 2 α 2 u 2 + ⋯ + μ n 2 α n u n W k v = μ 1 k α 1 u 1 + μ 2 k α 2 u 2 + ⋯ + μ n k α n u n \begin{aligned} Wv & =\mu _{1} \alpha _{1} u_{1} +\mu _{2} \alpha _{2} u_{2} +\cdots +\mu _{n} \alpha _{n} u_{n}\\ W^{2} v & =\mu ^{2}_{1} \alpha _{1} u_{1} +\mu ^{2}_{2} \alpha _{2} u_{2} +\cdots +\mu ^{2}_{n} \alpha _{n} u_{n}\\ W^{k} v & =\mu ^{k}_{1} \alpha _{1} u_{1} +\mu ^{k}_{2} \alpha _{2} u_{2} +\cdots +\mu ^{k}_{n} \alpha _{n} u_{n} \end{aligned} WvW2vWkv=μ1α1u1+μ2α2u2+⋯+μnαnun=μ12α1u1+μ22α2u2+⋯+μn2αnun=μ1kα1u1+μ2kα2u2+⋯+μnkαnun
这个变化告诉我们,随着k趋于无穷,特征值最大的特征向量将会主宰其余的特征向量,从而v与特征值最大的u变成同一个方向!此外,通过这样的变换,我们甚至能够知道v的运动过程其实是由各个不同大小的特征值与特征向量控制的。
谱图理论
当矩阵变成了一副图的邻接矩阵的时候,事情就变得很有趣的。此时,这样的矩阵描述了一种在图上的类似于热力扩散的运动,diffusion。同样的,该矩阵的特征值刻画了这样的运动轨迹。
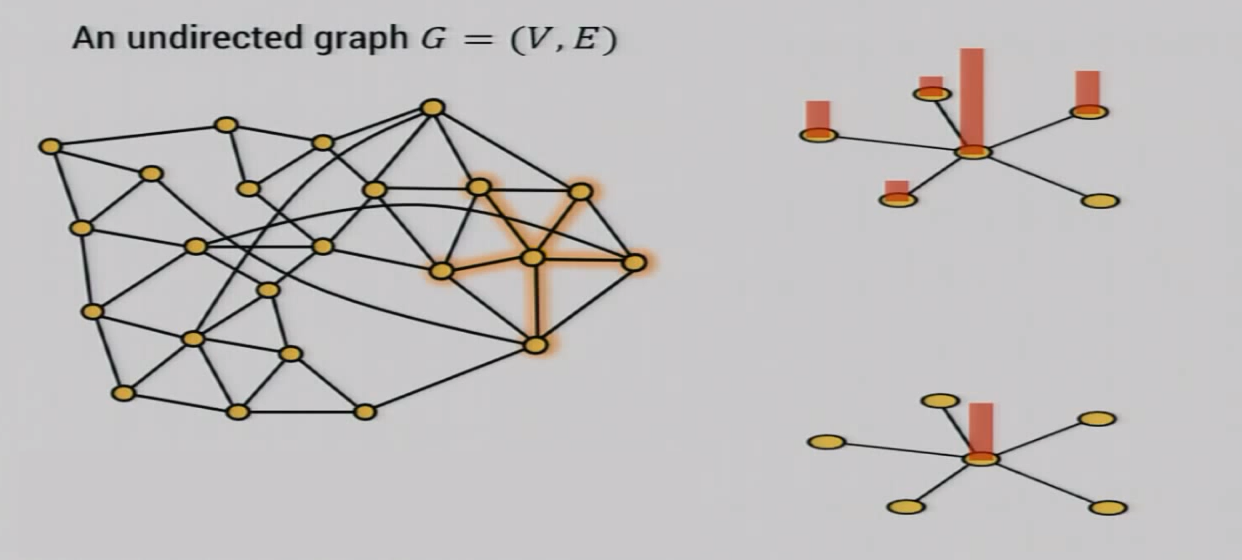
如果我们设W是一个实对称矩阵并且满足
- W i i = 0 W_{ii}=0 Wii=0
- W i j = 1 W_{ij}=1 Wij=1,i,j有边
- W i j = 0 W_{ij}=0 Wij=0,i,j没有边
并且我们定义一下图上每个结点的初始温度为 v = v 1 , v 2 , . . . , v n \mathbf{v}=v_1,v_2,…,v_n v=v1,v2,...,vn,于是经过“运动”后第i个结点的温度会变成下面这样:
( W v ) i = ∑ j : { i , j } ∈ E v j (W v)_{i}= \sum_{j :\{i, j\} \in E} v_{j} (Wv)i=j:{
i,j}∈E∑vj
我们发现他就是用所有邻居的温度的平均值来更新当前第i个结点的温度。可以预想的是,一直持续下去,所有结点的温度都会相等,而这个稳定的温度,显然是正比于特征值最大的特征向量(上一章的内容)。
Laplacian Matrix
为了更好研究,接下来我们引入一种性质更有趣的矩阵,叫做拉普拉斯矩阵,他的定义为 L = D − W L=D-W L=D−W

我们一般会对其标准化从而得到 L = I − D − 1 / 2 W D − 1 / 2 L=I-D^{-1/2}WD^{-1/2} L=I−D−1/2WD−1/2,假设A是标准化后的邻接矩阵 A = D − 1 / 2 W D − 1 / 2 A=D^{-1/2}WD^{-1/2} A=D−1/2WD−1/2,那么
- A i i = 0 A_{ii}=0 Aii=0
- A i j = 1 / d A_{ij}=1/d Aij=1/d,i,j有边
- A i j = 0 A_{ij}=0 Aij=0,i,j没有边
且
( A v ) i = 1 d ∑ j : { i , j } ∈ E v j (A v)_{i}= \frac{1}{d}\sum_{j :\{i, j\} \in E} v_{j} (Av)i=d1j:{
i,j}∈E∑vj
拉普拉斯矩阵,不同于邻接矩阵在描述运动的轨迹,laplace矩阵描述的是运动的位移或者变化量。可以对比一下以下两式:
( A v ) i = 1 d ∑ j : { i , j } ∈ E v j ( L v ) i = v i − 1 d ∑ j : { i , j } ∈ E v j (A v)_{i}=\frac{1}{d} \sum_{j :\{i, j\} \in E} v_{j} \\ (L v)_{i}=v_i-\frac{1}{d} \sum_{j :\{i, j\} \in E} v_{j} (Av)i=d1j:{
i,j}∈E∑vj(Lv)i=vi−d1j:{
i,j}∈E∑vj
显然我们得到是第i个结点的变化量,又因为这个乘积可以表示为:
L v = μ 1 α 1 u 1 + μ 2 α 2 u 2 + ⋯ + μ n α n u n L 2 v = μ 1 2 α 1 u 1 + μ 2 2 α 2 u 2 + ⋯ + μ n 2 α n u n L k v = μ 1 k α 1 u 1 + μ 2 k α 2 u 2 + ⋯ + μ n k α n u n \begin{aligned} Lv & =\mu _{1} \alpha _{1} u_{1} +\mu _{2} \alpha _{2} u_{2} +\cdots +\mu _{n} \alpha _{n} u_{n}\\ L^{2} v & =\mu ^{2}_{1} \alpha _{1} u_{1} +\mu ^{2}_{2} \alpha _{2} u_{2} +\cdots +\mu ^{2}_{n} \alpha _{n} u_{n}\\ L^{k} v & =\mu ^{k}_{1} \alpha _{1} u_{1} +\mu ^{k}_{2} \alpha _{2} u_{2} +\cdots +\mu ^{k}_{n} \alpha _{n} u_{n} \end{aligned} LvL2vLkv=μ1α1u1+μ2α2u2+⋯+μnαnun=μ12α1u1+μ22α2u2+⋯+μn2αnun=μ1kα1u1+μ2kα2u2+⋯+μnkαnun
于是,L的特征值描述了变化量的强度。事实上,这只是特征值的冰山一角,特征值描述的信息比你想象中更多,接来下,我们介绍一下,特征值与图的的另一种联系
Variational Characterization of Eigenvalues
定理: 设 M ∈ R n × n M\in \mathbb{R}^{n\times n} M∈Rn×n是对称矩阵,以及M的特征值 λ 1 ⩽ λ 2 ⩽ . . . λ n \displaystyle \lambda _{1} \leqslant \lambda _{2} \leqslant …\lambda _{n} λ1⩽λ2⩽...λn,于是
λ k = min k − dim V max x ∈ V − { 0 } x T M x x T x \lambda _{k} =\min_{k-\operatorname{dim} V}\max_{\mathbf{x} \in V-\{\mathbf{0} \}}\frac{\mathbf{x}^{T} M\mathbf{x}}{\mathbf{x}^{T}\mathbf{x}} λk=k−dimVminx∈V−{
0}maxxTxxTMx
其中 x T M x x T x \displaystyle \frac{\mathbf{x}^{T} M\mathbf{x}}{\mathbf{x}^{T}\mathbf{x}} xTxxTMx称为x在M中的Rayleigh quotient,并记为 R M ( x ) \displaystyle R_{M}(\mathbf{x}) RM(x).
证明:
设 v 1 , . . . , v n \displaystyle \mathbf{v}_{1} ,…,\mathbf{v}_{n} v1,...,vn为相互正交的特征向量,考虑由向量 v 1 , . . . , v k \displaystyle \mathbf{v}_{1} ,…,\mathbf{v}_{k} v1,...,vk组成的k维张成空间。对任意该空间的向量都有 x = ∑ i = 1 k a i v i \displaystyle \mathbf{x} =\sum ^{k}_{i=1} a_{i}\mathbf{v}_{i} x=i=1∑kaivi,于是Rayleigh quotient的分子 x T M x \displaystyle \mathbf{x}^{T} M\mathbf{x} xTMx为
∑ i = 1 k ∑ j = 1 k a i a j v i T M v j = ∑ i = 1 k ∑ j = 1 k a i a j λ j v i T v j = ∑ i = 1 k λ i a i 2 ≤ λ k ⋅ ∑ i = 1 k a i 2 \sum ^{k}_{i=1}\sum ^{k}_{j=1} a_{i} a_{j}\mathbf{v}^{T}_{i} M\mathbf{v}_{j} =\sum ^{k}_{i=1}\sum ^{k}_{j=1} a_{i} a_{j} \lambda _{j}\mathbf{v}^{T}_{i}\mathbf{v}_{j} =\sum ^{k}_{i=1} \lambda _{i} a^{2}_{i} \leq \lambda _{k} \cdot \sum ^{k}_{i=1} a^{2}_{i} i=1∑kj=1∑kaiajviTMvj=i=1∑kj=1∑kaiajλjviTvj=i=1∑kλiai2≤λk⋅i=1∑kai2
该不等式是因为 λ k \displaystyle \lambda _{k} λk是1到k中最大的特征值。而其分母 x T x = ∑ i = 1 k ∑ j = 1 k a i a j v i T v j = ∑ i = 1 k a i 2 \displaystyle \mathbf{x}^{T}\mathbf{x} =\sum ^{k}_{i=1}\sum ^{k}_{j=1} a_{i} a_{j}\mathbf{v}^{T}_{i}\mathbf{v}_{j} =\sum ^{k}_{i=1} a^{2}_{i} xTx=i=1∑kj=1∑kaiajviTvj=i=1∑kai2,因此
x T M x x T x ⩽ λ k ⋅ ∑ i = 1 k a i 2 ∑ i = 1 k a i 2 = λ k \frac{\mathbf{x}^{T} M\mathbf{x}}{\mathbf{x}^{T}\mathbf{x}} \leqslant \frac{\lambda _{k} \cdot \sum ^{k}_{i=1} a^{2}_{i}}{\sum ^{k}_{i=1} a^{2}_{i}} =\lambda _{k} xTxxTMx⩽∑i=1kai2λk⋅∑i=1kai2=λk
这意味着 λ k \displaystyle \lambda _{k} λk恰好对应着在k个维度的时候的最大值(x不等于0),因此
λ k ≥ min k − dim V max x ∈ V − { 0 } x T M x x T x \lambda _{k} \geq \min_{k-\operatorname{dim} V}\max_{\mathbf{x} \in V-\{\mathbf{0} \}}\frac{\mathbf{x}^{T} M\mathbf{x}}{\mathbf{x}^{T}\mathbf{x}} λk≥k−dimVminx∈V−{
0}maxxTxxTMx
接下来我们将证明V里面一定存在向量使得Rayleigh quotient ⩾ λ k \displaystyle \geqslant \lambda _{k} ⩾λk,令S为 v k , . . . , v n \displaystyle \mathbf{v}_{k} ,…,\mathbf{v}_{n} vk,...,vn张成的空间,这里S的维度为n-k+1,那么在V和S中,一定存在一个共享的向量x(因为它们共享第k个特征向量),令该向量的表达为 x = ∑ i = k n a i v i \displaystyle \mathbf{x} =\sum ^{n}_{i=k} a_{i}\mathbf{v}_{i} x=i=k∑naivi,此时,因为 λ k \displaystyle \lambda _{k} λk是最小的特征值,因此
∑ i = k n λ i a i 2 ⩾ λ k ⋅ ∑ i = 1 k a i 2 \sum ^{n}_{i=k} \lambda _{i} a^{2}_{i} \geqslant \lambda _{k} \cdot \sum ^{k}_{i=1} a^{2}_{i} i=k∑nλiai2⩾λk⋅i=1∑kai2
于是
x T M x x T x ⩾ λ k ⋅ ∑ i = k n a i 2 ∑ i = k n a i 2 = λ k \frac{\mathbf{x}^{T} M\mathbf{x}}{\mathbf{x}^{T}\mathbf{x}} \geqslant \frac{\lambda _{k} \cdot \sum ^{n}_{i=k} a^{2}_{i}}{\sum ^{n}_{i=k} a^{2}_{i}} =\lambda _{k} xTxxTMx⩾∑i=knai2λk⋅∑i=knai2=λk
因此
λ k = min k − dim V max x ∈ V − { 0 } x T M x x T x \lambda _{k} =\min_{k-\operatorname{dim} V}\max_{\mathbf{x} \in V-\{\mathbf{0} \}}\frac{\mathbf{x}^{T} M\mathbf{x}}{\mathbf{x}^{T}\mathbf{x}} λk=k−dimVminx∈V−{
0}maxxTxxTMx
证毕。
这个定理非常神奇且重要,他告诉我们,当x的取值在一个由K个特征向量张成的子空间中, x T M x x T x \displaystyle \frac{\mathbf{x}^{T} M\mathbf{x}}{\mathbf{x}^{T}\mathbf{x}} xTxxTMx的最大值恰好等于特征值。而如果你看过谱聚类(详细可看图卷积神经网络(Graph Convolutional Network, GCN)),当M等于标准化的laplace矩阵L时,即 L = I − 1 d A \displaystyle L=I-\frac{1}{d} A L=I−d1A,你会知道如果设 x ∈ { 0 , 1 } V \displaystyle x\in \{0,1\}^{V} x∈{
0,1}V,(用1表示A类结点,用0表示B类结点),那么这A,B两类结点把他切割开,于是 x T M x \displaystyle \mathbf{x}^{T} M\mathbf{x} xTMx就表示切割开A,B图所经过的边数,因为
x T L x = 1 d ∑ { u , v } ∈ E ( x u − x v ) 2 \mathbf{x}^{T} L\mathbf{x} =\frac{1}{d}\sum _{\{u,v\}\in E}( x_{u} -x_{v})^{2} xTLx=d1{
u,v}∈E∑(xu−xv)2
于是:
λ k = min S k − dimensional subspace of R n max x ∈ S − { 0 } ∑ { u , v } ∈ E ( x u − x v ) 2 d ∑ v x v 2 \lambda _{k} =\min_{Sk-\text{ dimensional subspace of }\mathbb{R}^{n}}\max_{\mathbf{x} \in S-\{\mathbf{0} \}}\frac{\sum _{\{u,v\}\in E}( x_{u} -x_{v})^{2}}{d\sum _{v} x^{2}_{v}} λk=Sk− dimensional subspace of Rnminx∈S−{
0}maxd∑vxv2∑{
u,v}∈E(xu−xv)2
那么如果 λ k \displaystyle \lambda _{k} λk等于0,想象一下,切割的边为0个是什么场景,显然就是一个独立的连通区域才能使得切割的边数量为0。在公式中,意味着,存在在所有k维的S空间中最小的x的最大值,使得 x ∈ S \displaystyle \mathbf{x} \in S x∈S,只要 { u , v } ∈ E \displaystyle \{u,v\}\in E {
u,v}∈E都有 x u = x v \displaystyle x_{u} =x_{v} xu=xv,这意味着他们都属于同一类别,也就是说,他们都在一个连通区域内,在这个区域内,所有结点的 x v \displaystyle x_{v} xv都相等。因此,laplace矩阵特征值为0的个数就是连通区域的个数。
此外,在真实场景中可能不存在特征值为0的孤岛(因为每个人或多或少都会跟人有联系),但是当特征值很小的时候,也能反应出某种“孤岛”,或者称为,bottleneck,这种bottleneck显然是由第二小的特征值决定的(因为特征值为0就是真正孤岛,但第二小就是有一点点边,但还是连通的),因此,很多发现社交社群的算法都会或多或少利用利用这一点,因为不同的社群肯定是内部大量边,但是社群之间的边很少,从而形成bottlenect。
关于这个bottleneck的一个应用就是图像分割,Normalized Cuts and Image Segmentation,
比如说一图图片:
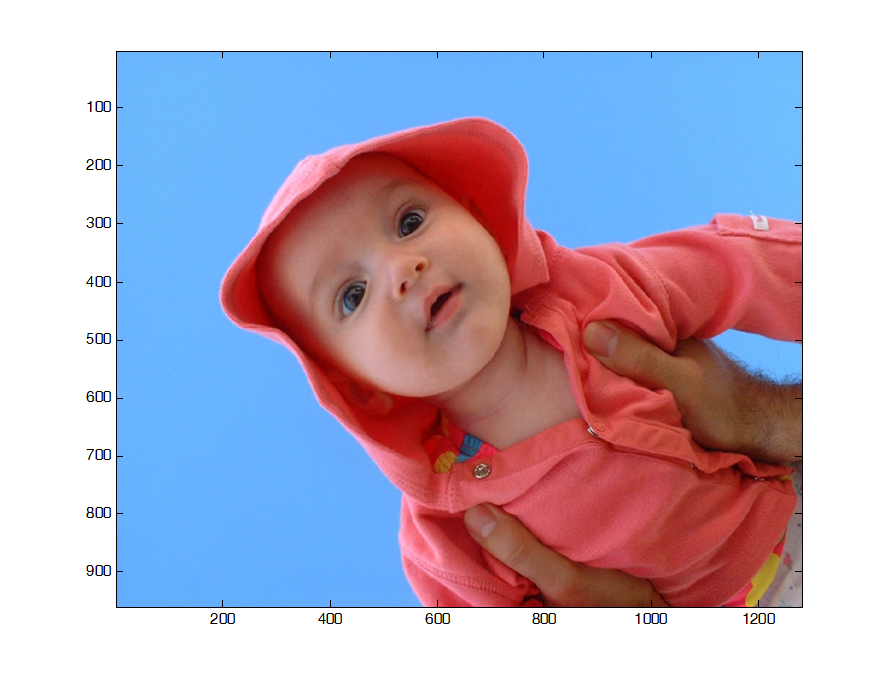
我们希望把婴儿分割出来,于是我们假设像素之间形成一个图,像素之间的相似性是边的权重,
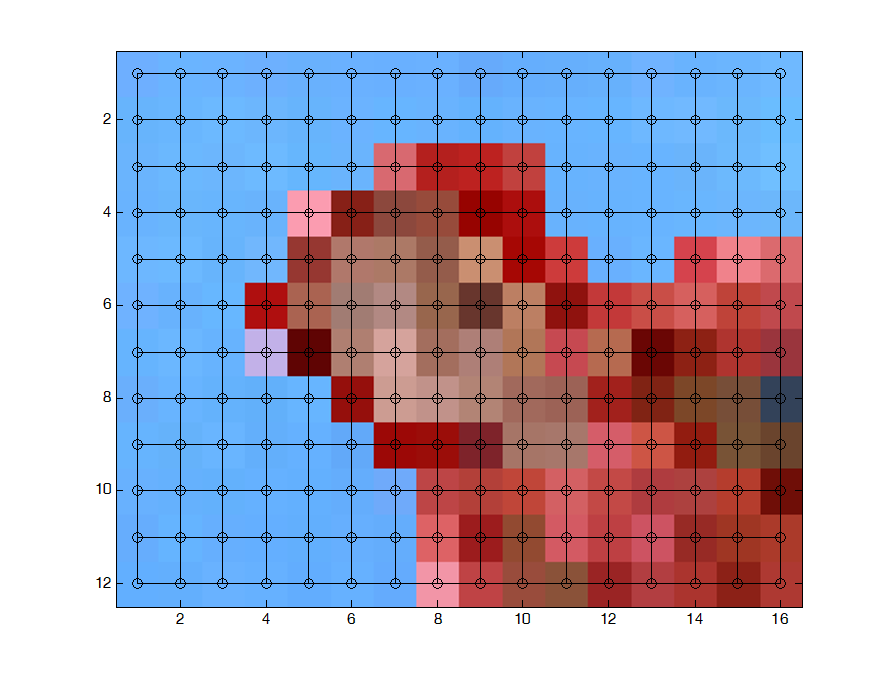
然后我们计算相似性
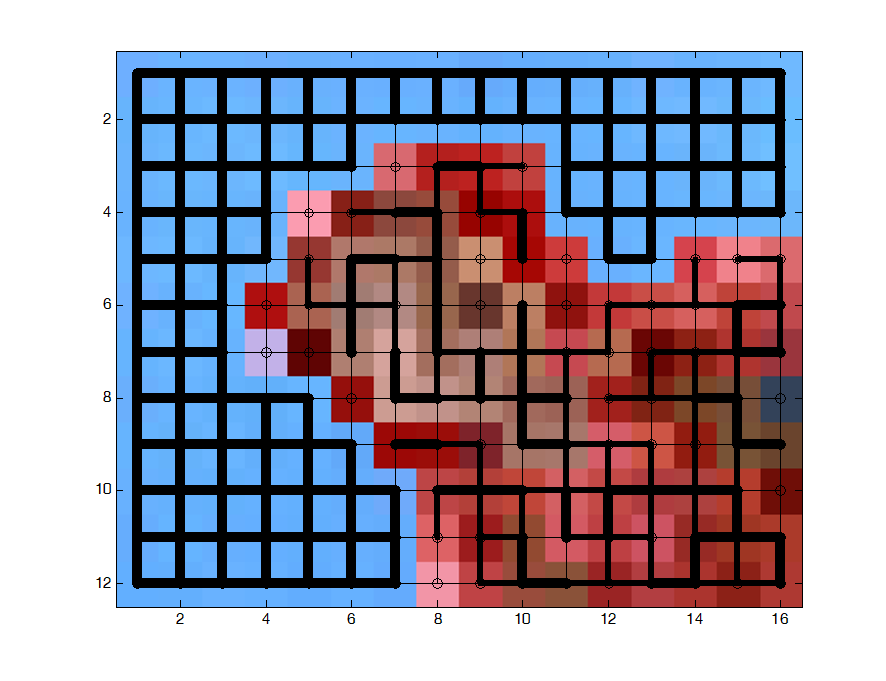
最后我们发现,第二个特征向量恰好就是对应着这个切分区域
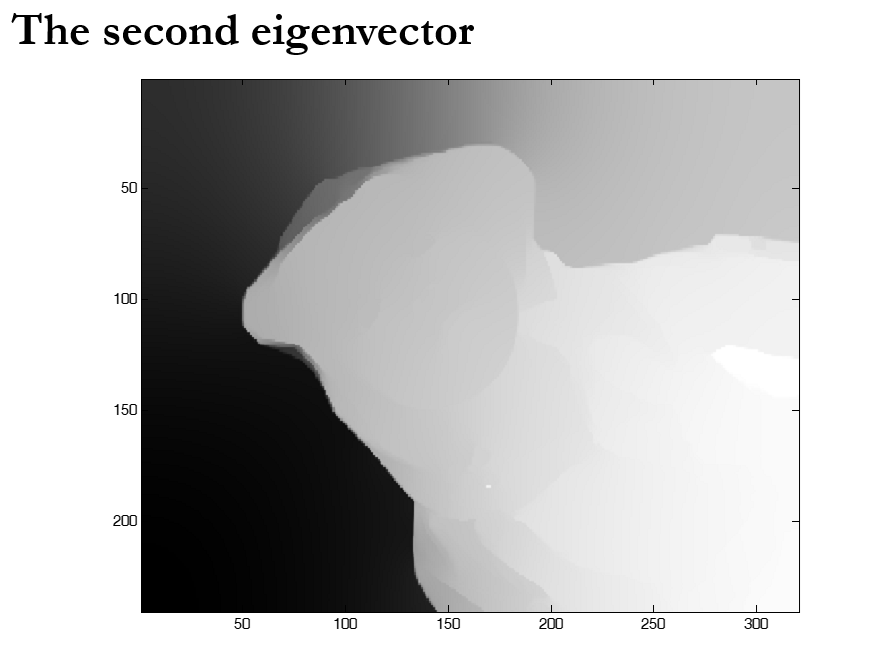
我们可以总结一下laplace矩阵的性质:
定理: 设G为无向图,A为G的邻接矩阵,令 L = I − 1 d A \displaystyle L=I-\frac{1}{d} A L=I−d1A为图G的标准化的laplace矩阵。设 λ 1 ⩽ λ 2 ⩽ . . . λ n \displaystyle \lambda _{1} \leqslant \lambda _{2} \leqslant …\lambda _{n} λ1⩽λ2⩽...λn,为L的特征值,大小按照递增排列,则:
- λ 1 = 0 \displaystyle \lambda _{1} =0 λ1=0 且 λ n ⩽ 2 \displaystyle \lambda _{n} \leqslant 2 λn⩽2
- λ k = 0 \displaystyle \lambda _{k} =0 λk=0 当且仅当G至少k个连通区域(这意味着特征值为0的数量对应着连通区域的数量)。
- λ n = 2 \displaystyle \lambda _{n} =2 λn=2 当且仅当至少有一个连通域是二分图。
显然,当k=1时,满足
λ 1 = min x ∈ R n − { 0 } ∑ { u , v } ∈ E ( x u − x v ) 2 d ∑ v x v 2 \lambda _{1} =\min_{\mathbf{x} \in R^{n} -\{\mathbf{0} \}}\frac{\sum _{\{u,v\}\in E}( x_{u} -x_{v})^{2}}{d\sum _{v} x^{2}_{v}} λ1=x∈Rn−{
0}mind∑vxv2∑{
u,v}∈E(xu−xv)2
首先,显然 λ 1 ⩾ 0 \displaystyle \lambda _{1} \geqslant 0 λ1⩾0,因为他们都是平方,其次,如果x是全1向量时等于0,从而最小值就是0,于是 λ 1 = 0 \displaystyle \lambda _{1} =0 λ1=0。
而当k=n时,
λ n = max x ∈ R n − { 0 } ∑ { u , v } ∈ E ( x u − x v ) 2 d ∑ v x v 2 \lambda _{n} =\max_{\mathbf{x} \in R^{n} -\{\mathbf{0} \}}\frac{\sum _{\{u,v\}\in E}( x_{u} -x_{v})^{2}}{d\sum _{v} x^{2}_{v}} λn=x∈Rn−{
0}maxd∑vxv2∑{
u,v}∈E(xu−xv)2
首先我们观察到:
2 x T x − x T L x = 1 d ∑ { u , v } ∈ E ( x u + x v ) 2 \begin{array}{ l } 2\mathbf{x}^{T}\mathbf{x} -\mathbf{x}^{T} L\mathbf{x} =\frac{1}{d}\sum _{\{u,v\}\in E}( x_{u} +x_{v})^{2} \end{array} 2xTx−xTLx=d1∑{
u,v}∈E(xu+xv)2
注意括号里面是加号,不是减号,于是 x T L x = 2 ∑ v x v 2 − 1 d ∑ { u , v } ∈ E ( x u + x v ) 2 \displaystyle \mathbf{x}^{T} L\mathbf{x} =2\sum _{v} x^{2}_{v} -\frac{1}{d}\sum _{\{u,v\}\in E}( x_{u} +x_{v})^{2} xTLx=2v∑xv2−d1{
u,v}∈E∑(xu+xv)2
λ n = 2 − min x ∈ R n − { 0 } ∑ { u , v } ∈ E ( x u + x v ) 2 d ∑ v x v 2 \lambda _{n} =2-\min_{\mathbf{x} \in \mathbb{R}^{n} -\{\mathbf{0} \}}\frac{\sum _{\{u,v\}\in E}( x_{u} +x_{v})^{2}}{d\sum _{v} x^{2}_{v}} λn=2−x∈Rn−{
0}mind∑vxv2∑{
u,v}∈E(xu+xv)2
显然 λ n ⩽ 2 \displaystyle \lambda _{n} \leqslant 2 λn⩽2,等号成立的条件为,存在非零的x,使得 ∑ { u , v } ∈ E ( x u + x v ) 2 = 0 \displaystyle \sum _{\{u,v\}\in E}( x_{u} +x_{v})^{2} =0 {
u,v}∈E∑(xu+xv)2=0,这意味着, x u = − x v , ∀ { u , v } ∈ E \displaystyle x_{u} =-x_{v} ,\forall \{u,v\}\in E xu=−xv,∀{
u,v}∈E. 而这正是一个二分图因为所有的边, x u \displaystyle x_{u} xu和 x v \displaystyle x_{v} xv都不一样,也就是他们所属的类别都不同,而同类别之间的边又不存在,这就是一个二分图了。
参考资料
Lecture Notes on Graph Partitioning , Expanders and Spectral Methods
The Unreasonable Effectiveness of Spectral Graph Theory
Spectral graph theory and its applications
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/234365.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
