大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
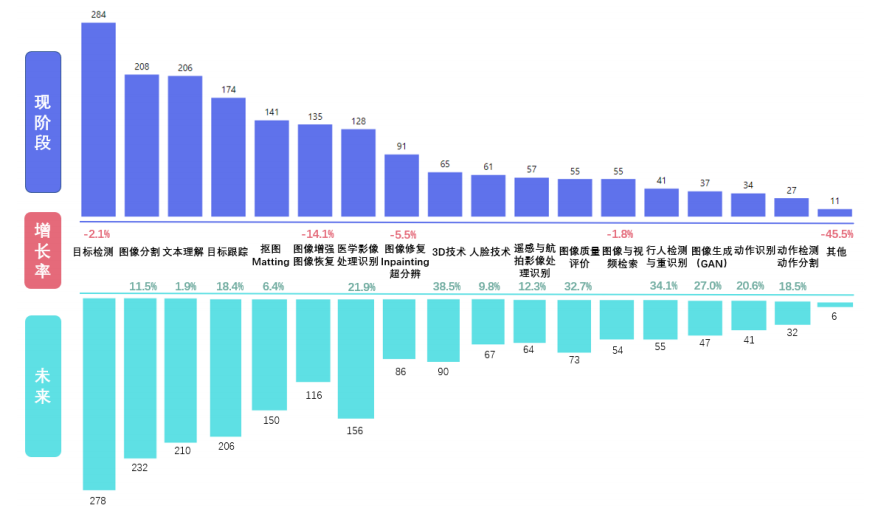

图1 2020年中国计算机视觉在职人员研究领域兴趣变化
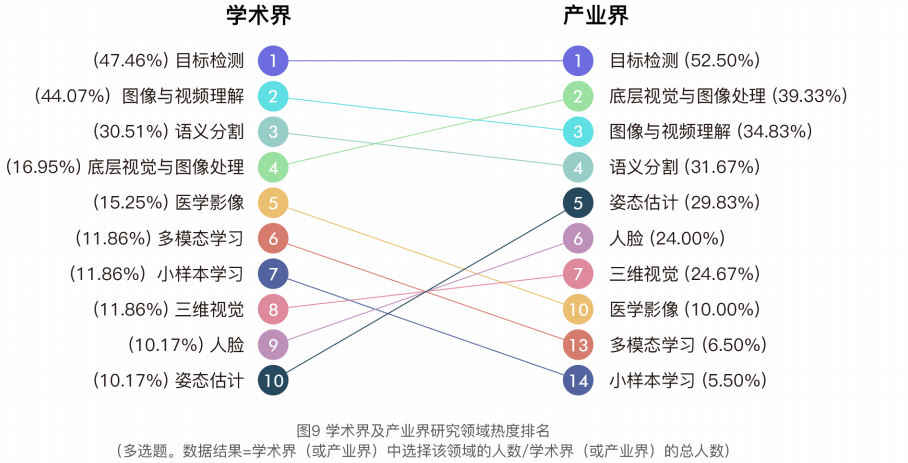
2021年中国计算机视觉在学术界和产业界各领域热度排名
1. 目标检测
常用算法:yolov3、v4、v5。
2.底层视觉与图像处理
潜在应用:由于外界环境影响,导致图像成像效果不尽人意,从而影响后续对视频图像的处理。
2.1图像超分辨率
超分辨率(Super Resolution,SR)是从给定的低分辨率(LR)图像中恢复高分辨率(HR)图像的过程,是计算机视觉的一个经典应用。
2.2图像压缩
图像压缩就是转换图像的过程,让图像占据更少的空间。很多图像如果直接存储的话或占据很大的空间,所以出现了不少编解码器,比如 JPEG 和 PNG,目的就是减少原始图像的大小。
2.3图像修复
修复指的是恢复图像损失的部分并且基于背景信息将它们重建的技术。它指的是在视觉输入的指定区域中填充缺失数据的过程。在数字世界中,它指的是应用复杂算法以替代图像数据中缺失或者损坏部分。
2.4图像去雨、去雾
雨水去除的方法试图从由雨水条纹和雨水累积(或雨水幕效应)退化的图像中恢复干净的背景场景。
图像去雾的目的是消除雾霾环境对图像质量的影响,增加图像的可视度,是图像处理和计算机视觉领域共同关切的前沿课题。
2.5图像去模糊去噪
图像的运动模糊就是一种典型的图像退化现象。图像运动模糊是指图像中的移动效果,通常会出现在长时间曝光或被拍摄物体移动太快的情况下,由于拍摄时相机与物体之间发生了相对位移,图像上就会出现运动模糊。
2.6低照度增强
在低照度环境下拍摄的图像通常能见度都很低,这些图像除了在视觉效果上降低了美感以外,还让计算机视觉的显示效果降质了。为了解决这个问题,本文提出了一种简单有效的低照度图像增强算法
3.视频理解
3.1视频分类(动作识别、场景识别)
视频分类是指给定一个视频片段,对其中包含的内容进行分类
3.2视频动作定位
视频动作定位是在视频中定位出正在执行动作的主体并识别出动作的问题。
4.图像分割、语义分割
4.1图像分割
图像分割是指根据颜色、空间纹理、几何形状等特征把图像划分成若干个互不相交的区域,使得这些特征在同一区域内表现出一致性或相似性,而在不同区域间表现出明显的不同。
4.2 语义分割
语义分割指的是将图像中的每一个像素关联到一个类别标签上的过程,这些标签可能包括一个人、一辆车、一朵花、一件家具等
5.姿态估计
人体关键点检测(Human Keypoints Detection)又称为人体姿态估计,是计算机视觉中一个相对基础的任务,是人体动作识别、行为分析、人机交互等的前置任务。一般情况下可以将人体关键点检测细分为单人/多人关键点检测、2D/3D关键点检测,同时有算法在完成关键点检测之后还会进行关键点的跟踪,也被称为人体姿态跟踪。
6.人脸
使用Arcface人脸识别模块,在五百亚洲人底库中精度可达99%+。
7.行人重识别
行人重识别(Person Re-identification)又被称为行人再识别,如今被视为图像检索的一类关键子问题。它是利用计算机视觉算法对跨设备的行人图像或视频进行匹配,即给定一个查询图像,在不同监控设备的图像库检索出同一个行人.
8.目标跟踪
8.1单目标跟踪
对于单目标跟踪而言一般的解释都是在第一帧给出待跟踪的目标,在后续帧中,tracker能够自动找到目标并用bbox标出。
8.2多目标跟踪
多目标跟踪 ,即Multiple Object Tracking (MOT),主要任务中是给定一个图像序列,找到图像序列中运动的物体,并将不同帧的运动物体进行识别,也就是给定一个确定准确的id,当然这些物体可以是任意的,如行人、车辆、各种动物等等,而最多的研究是行人跟踪,由于人是一个非刚体的目标,且实际应用中行人检测跟踪更具有商业价值。 绝大多数MOT 算法无外乎这四个步骤:①检测 ②特征提取、运动
9.文本理解
文本理解目前主要有两个方面的工作,一个是传统的文本理解,它往往只需识别文档中的文本;而另一个场景文字理解,需要将照片或视频中的文字识别出来,它包含文本检测和文本识别两个步骤:首先是对存在文字区域的定位(Text Detection),即找到单词或文本行的边界框(bounding box);然后对定位的区域内容进行识别(Text Recognition),即预测边界框中每一个字符的类标签。将这两步合在一起就能达到最终目的:端到端的文本识别。
10.三维视觉
三维视觉作为一个学科来讲,是多学科的交叉融合。主要有计算机视觉、计算机图形学,还有人工智能。具体来讲,三维视觉涉及的研究内容,主要包括三维感知、位姿感知、三维建模、三维理解,甚至还有三维认知的方面。
11.医学图像
医学图像是反映人体内部结构的图像,是现代医疗诊断的主要依据之一。目前,医学图像处理任务主要集中在图像检测、图像分割、图像配准及图像融合四个方面。
医学图像数据具有可获得、质量高、体量大、标准统一等特点,使人工智能在其中的应用较为成熟。利用图像处理技术对图像进行分析和处理,实现对人体器官、软组织和病变体的位置检测、分割提取、三维重建和三维显示,可以对感兴趣区域(Region of Interest, ROI)进行定性甚至定量的分析,从而大大提高临床诊断的效率、准确性和可靠性,在医疗教学、手术规划、手术仿真及各种医学研究中也能起重要的辅助作用。
12. 多模态学习
模态:每一种信息的来源或者形式,都可以称为一种模态,例如:触觉,听觉,视觉,嗅觉;信息的媒介,有语音、视频、文字;传感器,如雷达、红外、加速度计。
多模态机器学习(MultiModal Machine Learning (MMML),旨在通过机器学习的方法实现处理和理解多源模态信息的能力。
13. 小样本学习
Few-shot learning (FSL) 在机器学习领域具有重大意义和挑战性,是否拥有从少量样本中学习和概括的能力,是将人工智能和人类智能进行区分的明显分界点,因为人类可以仅通过一个或几个示例就可以轻松地建立对新事物的认知,而机器学习算法通常需要成千上万个有监督样本来保证其泛化能力。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/234334.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
