大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
作者:张华 发表于:2016-04-05
版权声明:可以任意转载,转载时请务必以超链接形式标明文章原始出处和作者信息及本版权声明
( http://blog.csdn.net/quqi99 )
IP层叫分片,TCP/UDP层叫分段。网卡能做的事(TCP/UDP组包校验和分段,IP添加包头校验与分片)尽量往网卡做,网卡不能做的也尽量迟后分片(发送)或提前合并片(接收)来减少在网络栈中传输和处理的包数目,从而减少数据传输和上下文切换所需要的CPU计算时间。
发数据
- TSO(TCP分段,TCP Segmentation Offload)在TCP处做,UFO(UDP分片,UDP Fragmentation Offload)因为UDP不支持分段所以移到下层的IP层做分片。TSO是使得网络协议栈能够将大块buffer推送至网卡,然后网卡执行分片工作,这样减轻了CPU 的负荷,但TSO需要硬件来实现分片功能;
- GSO(Generic Segmentation Offload)比TSO更通用,基本思想就是尽可能的推迟数据分片直至发送到网卡驱动之前,如果硬件不支持TSO分段则由dev_hard_start_xmit中的dev_gso_segment先软件分段的segs赋值给skb->next(skb->next = segs), 如果网卡硬件支持分段则直接将GSO大帧(skb-next)传给网卡驱动(dev_hard_start_xmit中的ndo_start_xmit)(所以它传给virtio驱动的是GSO大帧),然后继续进行IP分片后再发往网卡。GSO自动检测网卡支持特性, 硬件不支持也可以使用GSO它更通用(TSO一定需要硬件支持)。当打开GSO时,GSO会在xmit那块做GSO分片时调用TCP/UDP的回调函数自动添加TCP/UDP头(不使用GSO的只有第一个分片有TCP/UDP头,后面接着的分片是没有的,这也是为什么在虚机里打开TSO/GSO时对于隧道会多出一块数据的原因),然后再调IP层回调函数为每个分片添加IP头。
1, 物理网卡不支持GSO时, 使用TSO时TCP分段在驱动处调用硬件做,不使用TSO时TCP分段在TCP协议处软件做。
2, 物理网卡不支持UFO时,使用GSO时在发送给驱动前一刻做,不使用GSO在IP层软件做。
3, 物理网卡不支持TSO时,使用GSO时在发送给驱动前一刻做,不使用GSO在TCP层软件做。
TSO与GSO的重要区别
1, TSO只有第一个分片有TCP头和IP头,接着的分段只有IP头。意味着第一个分段丢失,所有分段得重传。
2, GSO在分段时会调用TCP或UDP的回调函数(udp4_ufo_fragment)为每个分段都加上IP头,由于分段是通过mss设置的(mss由发送端设置),所以长度仍然可能超过mtu值,所以在IP层还得再分片(代码位于dev_hard_start_xmit)。
收数据
- LRO(Large Receive Offload),TSO是发,LRO是收。将多个TCP分段聚合成一个skb结构,以减小上层协议栈的skb的开销。skb的数据保存在skb->data中,分段的数据保存在skb_shared_info->frag_list中。
- GRO(Generic Receive Offloading),GSO是发,GRO是收。LRO使用发送方和目的地IP地址,IP封包ID,L4协议三者来区分段,对于从同一个SNAT域的两个机器发向同一目的IP的两个封包可能会存在相同的IP封包ID(因为不是全局分配的ID),这样会有所谓的卷绕的bug。GRO采用发送方和目的地IP地址,源/目的端口,L4协议三者来区分作为改进。所以对于后续的驱动都应该使用GRO的接口,而不是LRO。另外,GRO也支持多协议。
1, 物理网卡不支持GRO时, 使用LRO在驱动处合并了多个skb一次性通过网络栈,对CPU负荷的减轻是显然的。
2, 物理网卡不支持LRO时,使用GRO在从驱动接收数据那一刻合并了多个skb一次性通过网络栈,对CPU负荷的减轻是显然的。
性能影响
对TCP来说,在CPU资源充足的情况下,TSO/GSO 能带来的效果不大,但是在CPU资源不足的情况下,其带来的改观还是很大的。
对UDP来说,其改进效果一般,改进效果不超过20%。所以在VxLAN环境中,其实是可以把GSO关闭,从而避免它带来的一些潜在问题。
Offloading 带来的潜在问题
分段offloading可能会带来潜在的问题,比如网络传输的延迟latency,因为packets的大小的增加,大大增加了driver queue的容量(capacity)。比如说,系统一方面在使用大的packet size传输大量的数据,同时在运行许多的交换式应用(interactive application)。因为交互式应用会定时发送许多小的packet,这时候可能会应为这些小的packets被淹没在大的packets之中,需要等待较长的时间才能被处理,这可能会带来不可接受的延迟。在网络上也能看到一些建议,在使用这些offloading技术时如果发现莫名的网络问题,建议先将这些技术关闭后再看看情况有没有改变。
# ethtool -K interface gso off
# ethtool -K interface tso off
VirtIO
在guest中有virtio前端驱动, 如针对网络的virtio-net,和其他驱动如virtio-pci等共同经过virt-queue的notify的trap中断到主机的hypervisor中执行host中面向guest前端驱动的api接口与后端驱动(virtio-backend driver)。guest内核的rx0与tx0两个队列与host的rx与tx两个队列通过socket共享内存交换数据。
下面是如何打开virtqueue的调试功能
echo -n “func virtqueue_add +flmpt” | sudo tee /sys/kernel/debug/dynamic_debug/control
sudo cat /sys/kernel/debug/dynamic_debug/control | grep virtio
这样能看到 virtqueue_add() 函数的信息:
drivers/virtio/virtio_ring.c:294 [virtio_ring]virtqueue_add =pmflt “Added buffer head %i to %p\012”
drivers/virtio/virtio_ring.c:236 [virtio_ring]virtqueue_add =pmflt “Can’t add buf len %i – avail = %i\012”
vxlan的实现
从guest出来的tcp数据到达host的vxlan driver时会调用vxlan_xmit, 它的主要逻辑是获取 vxlan dev,然后为 sk_buff 中的每一个skb调用vxlan_xmit_skb方法, vlan_xmit_skb除了计算 tos,ttl,df,src_port,dst_port,md,flags等以外,也调用skb_set_inner_protocol(skb, htons(ETH_P_TEB))设置GSO参数。最后调用udp_tunnel_xmit_skb将skb传给udp tunnel协议栈继续处理。
这样也就进了IP层的ip_finish_output_gso,如果硬件支持,则由硬件调用linux内核中的UDP GSO函数(当有GSO时,由 UDP协议栈提供UDP分片逻辑而不是IP分片逻辑,这使得每个分片都有完整的UDP包头,然后继续IP层的GSO分片。所以GSO本身是对UFO的优化);如果硬件不支持,则在进入device driver queue之前由linux内核调用UDP GSO分片函数,然后再一直往下到网卡。
static int ip_finish_output_gso(struct net *net, struct sock *sk,
struct sk_buff *skb, unsigned int mtu){
…
#调用回调函数, 对于UDP则是调用UDP的gso_segment回调函数进行UDP GSO分段
segs = skb_gso_segment(skb, features & ~NETIF_F_GSO_MASK);
…
do {
struct sk_buff *nskb = segs->next;
int err;
segs->next = NULL;
#有必要则IP分片,因为UDP GSO是按照MSS进行,MSS还是有可能超过IP分段所使用的host物理网卡MTU
err = ip_fragment(net, sk, segs, mtu, ip_finish_output2);
if (err && ret == 0)
ret = err;
segs = nskb;
} while (segs);
这里是udp_offload.c中定义的回调函数:
static const struct net_offload udpv4_offload = {
.callbacks = {
.gso_segment = udp4_ufo_fragment,
…
},
};
可见,在整个过程中,有客户机上TCP协议层设置的skb_shinfo(skb)->gso_size始终保持不变为MSS,因此,在网卡中最终所做的针对UDP GSO数据报的GSO分片所依据的分片的长度还是根据skb_shinfo(skb)->gso_size的值即TCP MSS,所以vxlan协议有一个问题,即host的IP分片是根据geuest中TCP连接的MSS来进行的。
从geust到host的包流向
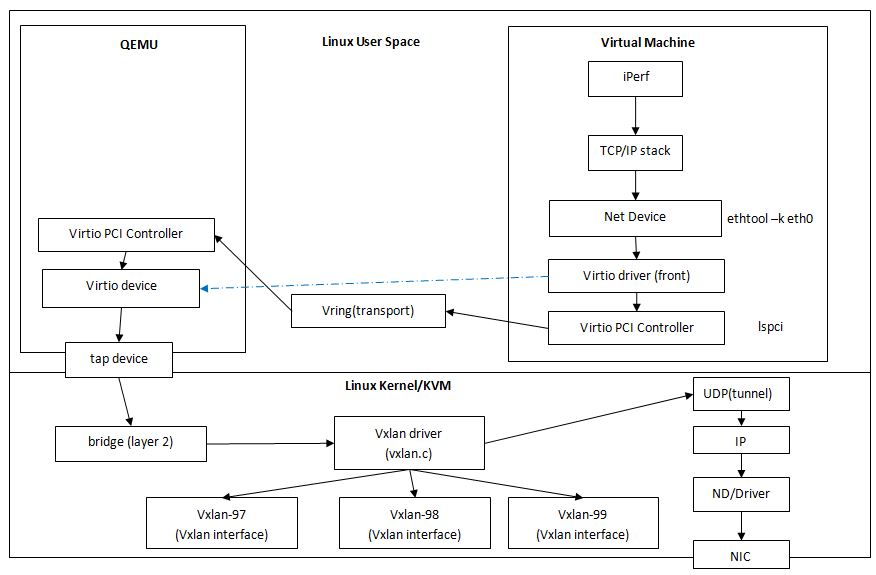

1, netif_needs_gso先判断网卡是否支持GSO(guest里的virtio nic肯定支持),if(unlikely(foo))认为foo通常为0, 所以如果网卡支持TSO时dev_gso_segment将返回0(skb->next==NULL),也就是说,当guest网卡的GSO特性打开时,guest会直接将没有分段的GSO大帧传递到virtio-net driver中。
int dev_hard_start_xmit(struct sk_buff *skb, struct net_device *dev,
struct netdev_queue *txq)
{
…
if (netif_needs_gso(skb, features)) {
if (unlikely(dev_gso_segment(skb, features)))
goto out_kfree_skb;
if (skb->next)
goto gso;
}
gso:
do {
struct sk_buff *nskb = skb->next;
skb->next = nskb->next;
…
rc = ops->ndo_start_xmit(nskb, dev);
…
} while (skb->next);
static int dev_gso_segment(struct sk_buff *skb, netdev_features_t features)
{
struct sk_buff *segs;
segs = skb_gso_segment(skb, features);
/* Verifying header integrity only. */
if (!segs)
return 0;
skb->next = segs;
DEV_GSO_CB(skb)->destructor = skb->destructor;
skb->destructor = dev_gso_skb_destructor;
return 0;
}
2, virtio_net.c中的如下代码定义了virtio-net driver的xmit函数为start_xmit,它会直接将这个GSO大帧通过vring(<=64K)传给host上的virtio backend driver.
static const struct net_device_ops virtnet_netdev = {
…
.ndo_start_xmit = start_xmit,
3, 然后host上的tap和bridge都会原封不动动转发这个GSO大帧(payload, inner-tcp, inner-ip, inner-ethernet)。
4, host上的vxlan driver在原GSO大帧上添加vxlan帧头,从(payload, inner-tcp, inner-ip, inner-ethernet)变成(payload, inner-tcp, inner-ip, inner-ethernet, vxlan)。
5, 如果host不支持GSO,那么在host的IP层直接对外层的UDP分片,注意:只有第1个分片有UDP头,接下来的分片没有UDP头。
分片1: payload, inner-tcp, inner-ip, inner-ethernet, vxlan,outer-udp, outer-ip
分片2: payload, inner-tcp, inner-ip, inner-ethernet, vxlan,outer-ip
6, 如果host支持GSO,在host的dev_hard_start_xmit处(代码回到第1步),如果物理网卡支持TSO直接将大帧(payload, inner-tcp, inner-ip, inner-ethernet, vxlan)将给物理网卡的TSO去硬件分片。如果物理网卡不支持TSO将调用skb_gso_segment软件执行GSO。GSO由于会调用UDP的回调函数,但vxlan没有GSO回调函数,所以这里的GSO分片应该每一个分片都有UDP头部,但是只有第一个分片有vxlan头部。
分片1: payload, inner-tcp, inner-ip, inner-ethernet, vxlan,outer-udp, outer-ip
分片2: payload, inner-tcp, inner-ip, inner-ethernet,outer-udp, outer-ip
7, 但是host的物理网卡是根据mss(由sender确定,也就是guest设定,而不是由mtu设定)发给远端的。host打开GSO增加outer-udp时可能会造成包大于mss值从而继续在添加outer-ip时做ip分片。所以redhat的最佳实践要求关闭host机上的GSO特性。
从host到guest的包流向
4194304
hua@node1:~$ cat /proc/sys/net/ipv4/ipfrag_low_thresh
3145728
hua@node1:~$ cat /proc/sys/net/ipv4/ipfrag_time
30
IP分段ID,L4协议>五元组来区分,由于SNAT在IP分段ID相同的话会出现来自NAT路由器背后不同机器上的分段的五元组相同的情况。所以后来GRO在TSO的基础上将这个五元组改为:<发送方和接收方IP、
TOS/协议字段,L4协议>.
net.bridge.bridge-nf-call-ip6tables = 0
net.bridge.bridge-nf-call-iptables = 0
VMware STT隧道
解决办法
1, 若用隧道guest中设置mtu
2, echo 0 > /proc/sys/net/bridge/bridge-nf-call-iptable (可选,如果有Linux Bridge的话)
3, 关闭host上的GSO, TSO, GRO (如果为使用conntract特性没有关闭bridge-nf-call-iptable的话)
4, 重点关注host机上物理网卡与Linux bridge上的mtu,其他的虚拟网卡的mtu可以默认设置很大如65000 (可选)
5, 也可以试试关闭tx与rx两个offload特性,sudo ethtool –offload eth0 rx off tx off sg off tso off, 注意:在tx与rx打开时,chksum是在硬件网卡处做的,tcpdump的输出“cksum 0x0a2b (incorrect -> xxx”应该是正常的。
juju run --application nova-compute 'for x in `ip netns | cut -f1 -d" "`; do ip netns exec $x bash -c "ip link list | sed -e \"s/2: \(.*\)@if.*/\1/;t;d\" | while read x; do ethtool --offload \$x rx off tx off sg off tso off; done"; done'
参考
[1] http://www.pagefault.info/?p=159
[2] https://kris.io/2015/10/01/kvm-network-performance-tso-and-gso-turn-it-off/
[3] http://www.cnblogs.com/sammyliu/p/5227121.html
[4] https://patchwork.ozlabs.org/patch/415791/
[5] http://www.ibm.com/developerworks/cn/linux/l-virtio/
[6] http://www.cnblogs.com/sammyliu/p/5228581.html
[7] http://royluo.org/2014/08/09/virtio-netdev-send/
[8] https://markmc.fedorapeople.org/virtio-code-review/VirtioCodeReview.pdf
[9] http://blog.csdn.net/majieyue/article/details/7929398
[10] https://ask.openstack.org/en/question/58607/poor-network-connection-issue-with-windows-instance/
[11] https://sokratisg.net/2012/04/01/udp-tcp-checksum-errors-from-tcpdump-nic-hardware-offloading/
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/230966.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
