大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
最近做数据增广做的心累,想要看一看对抗攻击!这个博文会对四种经典算法进行剖析,分别是FGSM、BIM、PGD、Carlini and Wagner Attacks (C&W)。
对抗攻击和防御
首先我们简单来说一说对抗攻击和防御的目的。攻击就是对原始样本增加扰动生成对抗版本最大化损失函数,同时扰动尽可能地小,让人类肉眼无法察觉;防御问题是基于这种攻击方法训练一个更具鲁棒性的神经网络。数学表达如下:
攻击: max δ ∈ S L ( θ , x + δ , y ) \mathop {\max }\limits_{\delta \in S} L\left( {\theta ,x + \delta ,y} \right) δ∈SmaxL(θ,x+δ,y)
防御: min θ ρ ( θ ) , ρ ( θ ) = E ( x , y ) ∈ D [ max δ ∈ S L ( θ , x + δ , y ) ] \mathop {\min }\limits_\theta \rho \left( \theta \right),\rho \left( \theta \right) = {
{\rm E}_{\left( {x,y} \right) \in D}}[\mathop {\max }\limits_{\delta \in S} L\left( {\theta ,x + \delta ,y} \right)] θminρ(θ),ρ(θ)=E(x,y)∈D[δ∈SmaxL(θ,x+δ,y)]
下面将针对几篇论文开始讲解:
Explaining and harnessing adversarial examples
动机
首先这篇论文提到,在当前的研究中,对抗样本的原因产生的原因仍是一个谜。之前很多假设推测对抗样本的产生是因为深度神经网络的极度非线性,可能还结合了监督学习中正则化和模型均化不足等原因。但是本文的作者认为,这种非线性(Nonlinear)的推测解释没有必要,**高维空间的线性(Linear Behavior)足够产生对抗样本。**根据这个观点,作者设计了一种新的快速产生对抗样本的方法,并且使得对抗学习(Adversarial Training)更实用。
线性解释
首先定义原始样本为 x x x,添加扰动后的对抗样本为 x ~ = x + η \tilde x = x + \eta x~=x+η。当其中的扰动 η \eta η比较小时,对于一个良好的分类器,会将他们分为同一个类。我们定义一个阈值 ε \varepsilon ε,当 ∥ η ∥ ∞ < ε {\left\| \eta \right\|_\infty } < \varepsilon ∥η∥∞<ε时,不会影响分类器的性能。经过一层线性网络后,权重向量 ω T {\omega ^T} ωT和对抗样本 x ~ \tilde x x~的点积为: ω T x ~ = ω T ( x + η ) = ω T x + ω T η {\omega ^T}\tilde x = {\omega ^T}\left( {x + \eta } \right) = {\omega ^T}x + {\omega ^T}\eta ωTx~=ωT(x+η)=ωTx+ωTη
这样,对抗扰动就增加了 ω T η {\omega ^T}\eta ωTη,作者令 η \eta η= ε ⋅ s i g n ( ω ) \varepsilon \cdot {\mathop{\rm sign}\nolimits} \left( \omega \right) ε⋅sign(ω)从而将干扰最大化。我们假设权重向量 ω \omega ω有 n n n个维度以及平均值是 m m m。这样干扰就会变成了 ε n m \varepsilon nm εnm,由此看出,干扰会随着维度 n n n线性增长,一个样本中大量维度的无限小的干扰加在一起就可以对输出造成很大的变化。所以对抗样本的线性解释表明,对线性模型而言,如果其输入样本有足够大的维度,那么线性模型也容易受到对抗样本的攻击。
非线性模型的线性对抗扰动
作者利用对抗样本的线性解释提出了一个快速产生对抗样本的方式,也即Fast Gradient Sign Method(FGSM)方法。假定模型参数值为 θ \theta θ,输入为 x x x,标签为 y y y,则模型的损失函数为 J ( θ , x , y ) J\left( {\theta ,x,y} \right) J(θ,x,y)。FGSM方法将保证无穷范数限制下( ∥ η ∥ ∞ < ε {\left\| \eta \right\|_\infty } < \varepsilon ∥η∥∞<ε)添加的扰动值为 η = ε s i g n ( ∇ x J ( θ , x , y ) ) \eta = \varepsilon sign\left( {
{\nabla _x}J\left( {\theta ,x,y} \right)} \right) η=εsign(∇xJ(θ,x,y))。
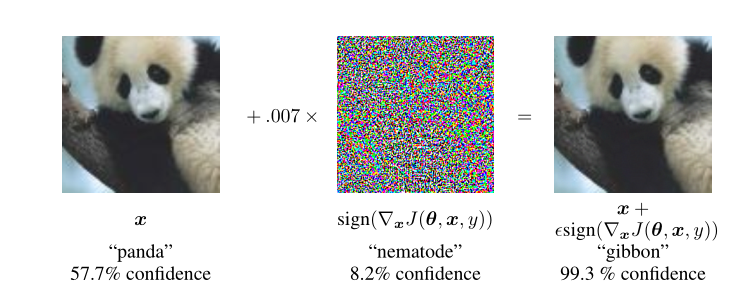

实验表明,FGSM这种简单的算法确实可以产生误分类的对抗样本,从而证明了作者假设的对抗样本的产生原因是由于模型的线性特性。同时,这种算法也可作为一种加速对抗训练的方法。
Logistics Regression模型上应用FGSM
在这个问题上很多人没有推导清楚,下面说一下自己的推导思路,从未理解在简单的设置中生成对抗样本:逻辑回归标签: y ∈ { − 1 , 1 } y \in \left\{ { – 1,1} \right\} y∈{
−1,1},预测函数为 P ( y = 1 ) = σ ( ω T x + b ) P\left( {y = 1} \right) = \sigma \left( {
{\omega ^T}x + b} \right) P(y=1)=σ(ωTx+b),其中 σ \sigma σ为sigmoid函数,则损失函数为 E x , y ∼ p d a t a τ ( − y ( ω T x + b ) ) {
{\rm E}_{x,y \sim {p_{data}}}}\tau \left( { – y\left( {
{\omega ^T}x + b} \right)} \right) Ex,y∼pdataτ(−y(ωTx+b))。其中 τ ( z ) = log ( 1 + exp ( z ) ) \tau \left( z \right) = \log \left( {1 + \exp \left( z \right)} \right) τ(z)=log(1+exp(z))。于是干扰计算如下: η = ∈ s i g n ( ∇ x J ( θ , x , y ) ) = ε s i g n ( ∇ x τ ( − y ( ω T x + b ) ) ) = ε s i g n [ e ( − y ( ω T x + b ) ) 1 + e ( − y ( ω T x + b ) ) ( − y ) ω T ] \eta = \in sign\left( {
{\nabla _x}J\left( {\theta ,x,y} \right)} \right) = \varepsilon sign\left( {
{\nabla _x}\tau \left( { – y\left( {
{\omega ^T}x + b} \right)} \right)} \right) = \varepsilon sign\left[ {
{
{
{e^{\left( { – y\left( {
{\omega ^T}x + b} \right)} \right)}}} \over {1 + {e^{\left( { – y\left( {
{\omega ^T}x + b} \right)} \right)}}}}\left( { – y} \right){\omega ^T}} \right] η=∈sign(∇xJ(θ,x,y))=εsign(∇xτ(−y(ωTx+b)))=εsign[1+e(−y(ωTx+b))e(−y(ωTx+b))(−y)ωT]其中 0 < [ e ( − y ( ω T x + b ) ) 1 + e ( − y ( ω T x + b ) ) ] < 1 0 < \left[ {
{
{
{e^{\left( { – y\left( {
{\omega ^T}x + b} \right)} \right)}}} \over {1 + {e^{\left( { – y\left( {
{\omega ^T}x + b} \right)} \right)}}}}} \right] < 1 0<[1+e(−y(ωTx+b))e(−y(ωTx+b))]<1,那么原式可以化简为 η = − y ε s i g n ( ω T ) \eta = – y\varepsilon sign\left( {
{\omega ^T}} \right) η=−yεsign(ωT)。我们将 y y y看作一个标签常数,由 ω T s i g n ( ω T ) = ∥ ω ∥ 1 {\omega ^T}sign\left( {
{\omega ^T}} \right){\rm{ = }}{\left\| \omega \right\|_{\rm{1}}} ωTsign(ωT)=∥ω∥1可得逻辑回归的对抗模型形式为: E x , y ∼ p d a t a τ ( y ( ε ∥ ω ∥ 1 − ω T x − b ) ) {
{\rm{E}}_{x,y \sim {p_{data}}}}\tau \left( {y\left( {\varepsilon {
{\left\| \omega \right\|}_1} – {\omega ^T}x – b} \right)} \right) Ex,y∼pdataτ(y(ε∥ω∥1−ωTx−b))
对抗样本泛化原因
为了解释为什么多个分类器将同一个类分配给敌对的例子,作者假设用当前方法训练的神经网
络都类似于在相同训练集上学习的线性分类器。分类器在训练集的不同子集上训练时能够学习大致相同的分类权重,这仅仅是因为机器学习算法具有泛化能力。但是基础分类权重的稳定性反过来又会导致对抗性例子的稳定性。
Adversarial machine learning at scale
动机
Goodfellow基于之前的FGSM攻击方法做出了一部分改进,作者鉴于之前的FGSM的成功率并不高(在imageNet上仅有63%−69%63%−69%)。Goodfellow做出了一些改进, 提出了BIM攻击算法。
模型定式
从原先的以增加原始类别标记的损失函数为目标变为了减少目标类别的损失函数为目标。 X a d v = X − ε s i g n ( ∇ X J ( X , y t arg e t ) ) {X^{adv}} = X – \varepsilon sign\left( {
{\nabla _X}J\left( {X,{y_{t\arg et}}} \right)} \right) Xadv=X−εsign(∇XJ(X,ytarget))其中 y t arg e t {y_{t\arg et}} ytarget为原始样本最不可能分的类别: y t arg e t = arg min y { p ( y ∣ x ) } {y_{t\arg et}} = \arg {\min _y}\left\{ {p\left( {y|x} \right)} \right\} ytarget=argminy{
p(y∣x)}。
此外,作者还提出了以迭代的方式来进行攻击。具体公式如下:
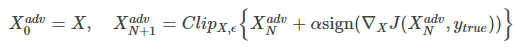
他们将该方法称为Basic Iterative Methods(BIM),后来Madry等人指出这实际上等价于无穷范数版本的Projected Gradient Descent(PGD),我们后文介绍PGD时会说一下两者的具体区别。
另外之前之前的对抗训练并没有考虑到大规模样本下的复杂模型,因此作者提出了一个新的对抗训练方式来应对批量训练,使用一个可以独立控制每批次对抗案例的数量和相关权重的损失函数:
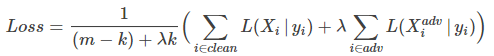
具体的算法流程如下:

实验效果
对抗训练增加了对于这些对抗攻击的鲁棒性(这应该是显而易见的)。但作者同时也指出了对抗训练略微减少了泛化精度,并且对于此给出的解释是:对抗训练起到了一定的正则化的作用。在过拟合的模型上,对抗训练能够降低测试误差;而在像ImageNet这些训练误差就很高的数据集上(欠拟合),对抗训练反而增大了训练误差,扩大了训练误差和测试误差的差距。
作者还做了有关模型大小和鲁棒性的关系,作者指出对于没有对抗训练的模型,太大的模型或者太小的模型都会导致鲁棒性很差,而对于对抗训练的模型,由于条件限制,目前的模型越大,鲁棒性显得越好。
作者实验还表明了FGSM的可转移性比BIM的可转移性强很多,这很可能是因为BIM生成的对抗样本太过针对性,因此减少了对抗攻击的泛化能力。这也许为黑箱攻击提供了一些鲁棒性。
Towards deep learning models resistant to adversarial attacks
论文动机
作者认为对抗攻击问题可以概括为Min-max问题,于是本文提出了对抗机器学习领域里面鼎鼎大名的Min-max最优化框架,通过这个框架可以将目前对抗手段和防御手段统一囊括进来。然后作者尝试去解决该min-max的问题。作者在本文中比较侧重如何进行防御,防御梯度攻击,产生更加鲁棒的防御模型。
模型定式
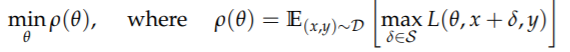
这个式子是一个进攻防御的Min-Max框架问题。对于攻击来说就是内部最大化,对于防御问题来说就是外部最小化。
内部最大化:里层的损失函数最大化的意思就是说原始样本加扰动后,和原始标签的损失差距越来越大,从而导致标签所得到的分数越来越小,这里指的是五目标攻击。
外部最小化:防御目的是为了让模型在遇到对抗样本的情况下,整个数据分布上的损失的期望还是最小。这个可以通过先解决内层训练找到所有训练样本的对抗样本,然后用对抗样本替换原样本进行retrain 来完成。
接下来作者介绍了PGD攻击
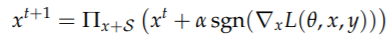
作者认为PGD算是非常强的first-order攻击,基本能防御PGD的网络,就可以防御其他任何one-order攻击。
实验结果
作者验证了防御模型的模型capacity,可以看到,随着模型的capacity变大,不仅在原始数据集上表现会变好(虽然有限),而且对于(one-step)对抗样本的抵抗能力也会增强。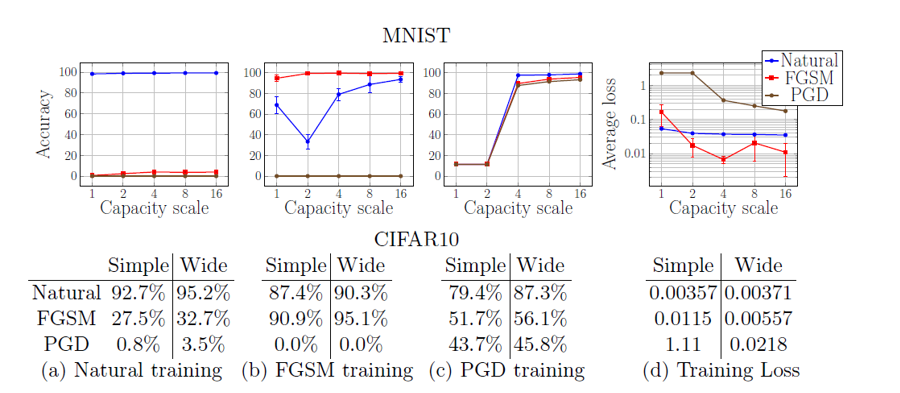
作者认为:通过PGD方法找到的对抗样本进行训练使得在这些对抗样本上神经网络的loss很小,那么这个神经网络也就可以抵抗其他的对抗样本
PGD和BIM的区别
链接:https://www.zhihu.com/question/277310171/answer/737065649
Their PGD attack consists of initializing the search for an adversarial example at a random point within the allowed norm ball, then running several iterations of the basic iterative method (Kurakin et al., 2017b) to find an adversarial example. The noisy initial point creates a stronger attack than other previous iterative methods such as BIM (Kurakin et al., 2017a), and performing adversarial training with this stronger attack makes their defense more successful (Madry et al., 2017)
PGD和BIM都是迭代的FGSM。 两者的区别简单来说就是PGD增加迭代轮数,并且增加了一层随机化处理。
效果来看PGF要比BIM好不少。
Towards evaluating the robustness of neural networks
主要思想
作者将求取对抗样本的过程,转化为一个最优化的问题,即最小化:
D ( x , x + δ ) D\left( {x,x + \delta } \right) D(x,x+δ)
在下面两个等式约束的条件下:
C ( x + δ ) = t C\left( {x + \delta } \right) = t C(x+δ)=t
x + δ ∈ [ 0 , 1 ] n x + \delta \in {\left[ {0,1} \right]^n} x+δ∈[0,1]n
作者将上式子继续转化,原目标函数最终被转化为一个具有box约束的最小化问题:
在 x + δ ∈ [ 0 , 1 ] n x + \delta \in {\left[ {0,1} \right]^n} x+δ∈[0,1]n条件下,最小化: ∥ δ ∥ p + c ⋅ f ( x + δ ) {\left\| \delta \right\|_p} + c \cdot f\left( {x + \delta } \right) ∥δ∥p+c⋅f(x+δ)
本文中还提出了七种 f ( ) f\left( \right) f()的表达形式,如下所示: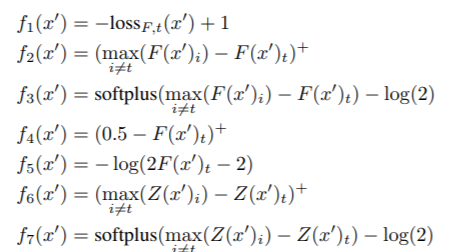
LmNzZG4ubmV0L3FxXzM4NTU2OTg0,size_16,color_FFFFFF,t_70)
作者对于Box约束问题,也提出了三种解决方式。
Projected gradient descent:每实施一步梯度下降,就把计算的结果限制在box内,该方法的缺点就是每次传入下一步的结果都不是真实值。
Clipped gradient descent:并没有真正地裁减,而是直接把约束加入到目标函数中。
f ( x + δ ) → f ( min ( max ( x + δ , 0 ) , 1 ) ) f\left( {x + \delta } \right) \to f\left( {\min \left( {\max \left( {x + \delta ,0} \right),1} \right)} \right) f(x+δ)→f(min(max(x+δ,0),1))
Change of variables:通过引入变量使满足box约束,其方法为:
δ i = 1 2 ( tanh ( ω i ) + 1 ) − x i {\delta _i} = {1 \over 2}\left( {\tanh \left( {
{\omega _i}} \right) + 1} \right) – {x_i} δi=21(tanh(ωi)+1)−xi
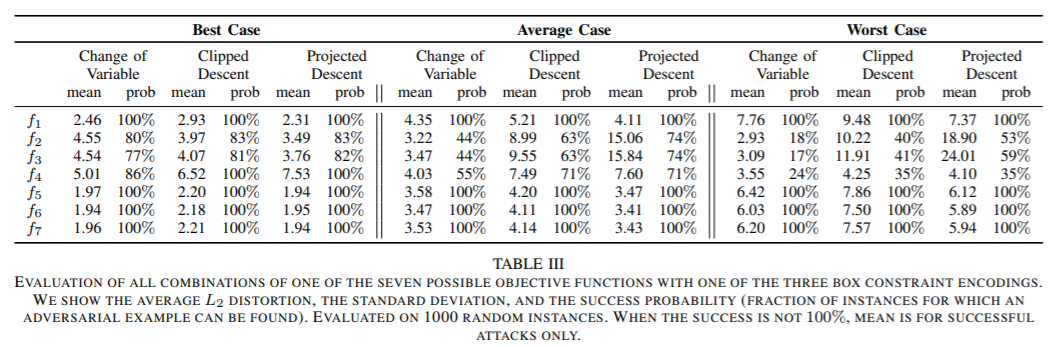
实验结果
Best Case: target label是最容易攻击的label
Worst Case:target label是最难攻击的label
Average Case:target label是随机挑选的label
可以发现Projected Descent在处理box约束是优于其他两种策略,
但Change of Variable寻求的扰动一般都是较小的
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/230956.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
