大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
前言
在面对一些简单的线性问题时。线性回归能够用一个直线较为精确地描述数据之间的关系。但对于复杂的非线性数据问题时。线性回归的效果就大大不如意了。对特征数据进行多项式变化,再使用线性回归的做法就能提高模型的拟合效果,这种方法就是多项式回归。
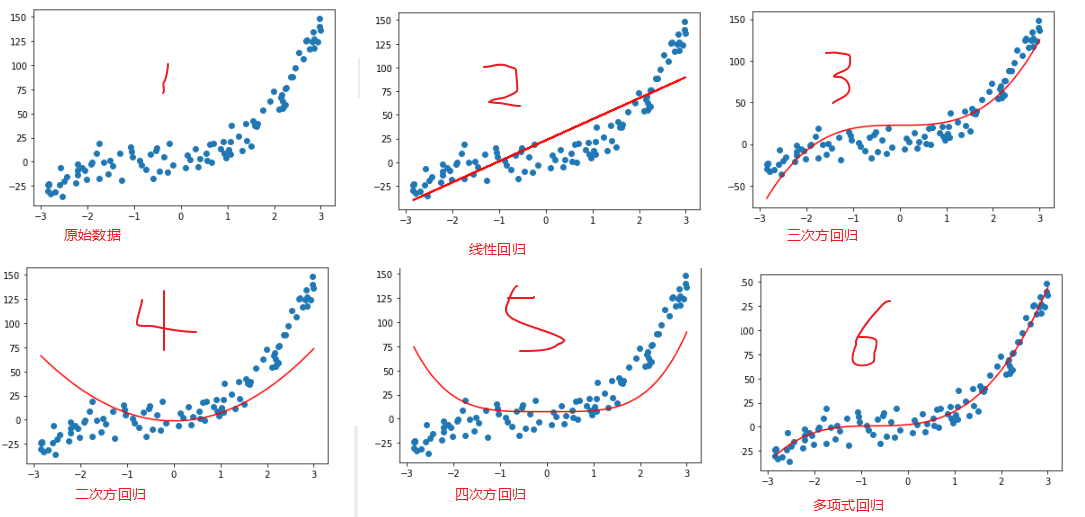

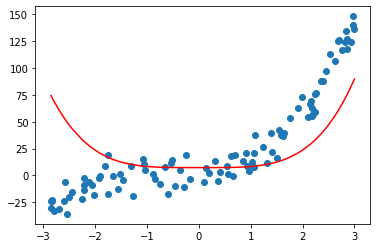
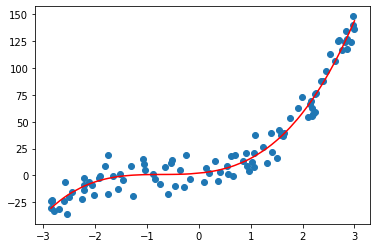
上面图中可以看到线性回归不能准确描述数据关系。无论一次方、二次方、三次方、四次方都不能单独完美拟合数据。在多项式中集成了一次方、二次方、三次方、四次方后使用线性回归就能完美拟合数据的非线性关系。
代码
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
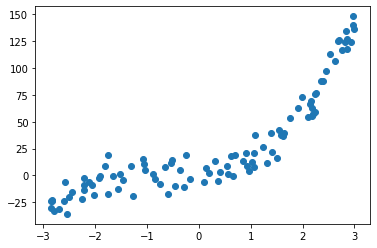
x = np.random.uniform(-3,3,size=100)
X = x.reshape(-1,1)
y = 3*x**3 + 6 * x**2 + 4* x + np.random.normal(0,10,100)
plt.scatter(x,y)
plt.show()
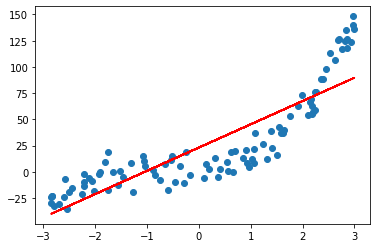
线性回归
lin_reg = LinearRegression()
lin_reg.fit(X,y)
y_predict = lin_reg.predict(X)
plt.scatter(x,y)
plt.plot(x,y_predict,color='r')
plt.show()
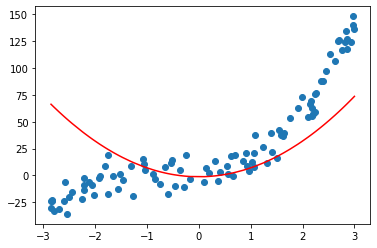
二次方
lin_reg2 = LinearRegression()
X2 = np.hstack([X**2])
lin_reg2.fit(X2,y)
y_predict2 = lin_reg2.predict(X2)
plt.scatter(x,y)
plt.plot(np.sort(x),y_predict2[np.argsort(x)],color='r')
plt.show()
三次方
X3 = np.hstack([X**3])
lin_reg3 = LinearRegression()
lin_reg3.fit(X3,y)
y_predict3 = lin_reg3.predict(X3)
plt.scatter(x,y)
plt.plot(np.sort(x),y_predict3[np.argsort(x)],color='r')
plt.show()
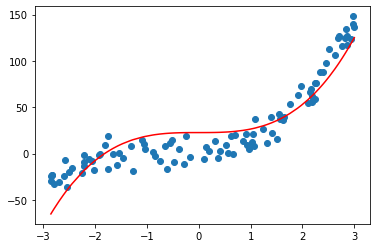
四次方
X4 = np.hstack([X**4])
lin_reg4 = LinearRegression()
lin_reg4.fit(X4,y)
y_predict4 = lin_reg4.predict(X4)
plt.scatter(x,y)
plt.plot(np.sort(x),y_predict4[np.argsort(x)],color='r')
plt.show()
多项式回归
X_mut = np.hstack([X,X**2,X**3,X**4])
lin_reg_mut = LinearRegression()
lin_reg_mut.fit(X_mut,y)
y_predict_mut = lin_reg_mut.predict(X_mut)
plt.scatter(x,y)
plt.plot(np.sort(x),y_predict_mut[np.argsort(x)],color='r')
plt.show()
sklearn中多项式回归 (LinearRegression)
多项式回归本质上是线性回归,线性回归损失函数:
l o s s = ω m i n 1 2 n s a m p l e s ∣ ∣ X ω − y ∣ ∣ 2 2 loss=\stackrel{\mathrm{min}}{\omega} \frac{1}{2n_{samples}}||X\omega-y||_2^2 loss=ωmin2nsamples1∣∣Xω−y∣∣22
PolynomialFeatures:多项式特征函数
StandardScaler:标准变换
LinearRegression:线性回归
def PolynomialRegression(degree):
return Pipeline([
("poly", PolynomialFeatures(degree=degree)),
("std_scaler", StandardScaler()),
("lin_reg", LinearRegression())
])
poly_reg = PolynomialRegression(degree=20)
poly_reg.fit(X_train, y_train)
X_plot = np.linspace(-3, 3, 100).reshape(100, 1)
y_plot = poly_reg.predict(X_plot)
plt.scatter(x, y)
plt.plot(X_plot[:,0], y_plot, color='r')
plt.axis([-3, 3, 0, 6])
plt.show()
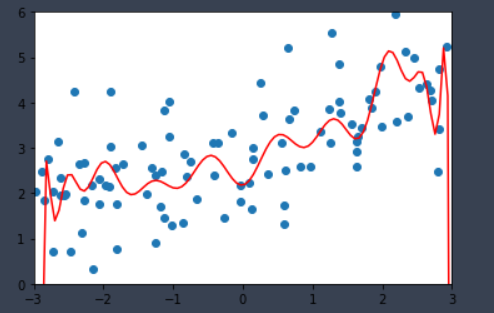
多项式回归弊端
多项式回归很容易过拟合,学习过多噪音,得到的模型过于复杂。解决办法之一就是对模型进行正则化,惩罚模型中的参数,参数越复杂,惩罚越重。根据在损失函数中加入惩罚项的不同,分为岭回归、Lasso回归、弹性网络( Elastic Net)。
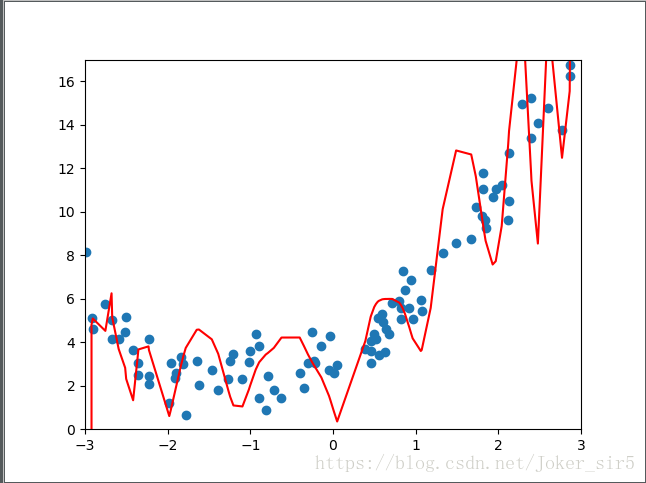
sklearn中岭回归 (Ridge)
岭回归损失函数:
l o s s = ω m i n 1 2 n s a m p l e s ∣ ∣ X ω − y ∣ ∣ 2 2 + α 2 ∣ ∣ ω ∣ ∣ 2 2 loss=\stackrel{\mathrm{min}}{\omega} \frac{1}{2n_{samples}}||X\omega-y||_2^2+\frac{\alpha}{2}||\omega||_2^2 loss=ωmin2nsamples1∣∣Xω−y∣∣22+2α∣∣ω∣∣22
岭回归不断使损失函数趋于最小,也使 w 参数向量也趋于最小
PolynomialFeatures:多项式特征函数
StandardScaler:标准变换
Ridge:岭回归
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import Ridge
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PolynomialFeatures
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression
def RidgeRegression(degree, alpha):
return Pipeline([
("poly", PolynomialFeatures(degree=degree)),
("std_scaler", StandardScaler()),
("ridge_reg", Ridge(alpha=alpha))
])
np.random.seed(42)
x = np.random.uniform(-3.0, 3.0, size=100)
X = x.reshape(-1, 1)
y = 0.5 * x + 3 + np.random.normal(0, 1, size=100)
plt.scatter(x, y)
plt.show()
from sklearn.model_selection import train_test_split
np.random.seed(666)
X_train, X_test, y_train, y_test = train_test_split(X, y)
def plot_model(model):
X_plot = np.linspace(-3, 3, 100).reshape(100, 1)
y_plot = model.predict(X_plot)
plt.scatter(x, y)
plt.plot(X_plot[:,0], y_plot, color='r')
plt.axis([-3, 3, 0, 6])
plt.show()
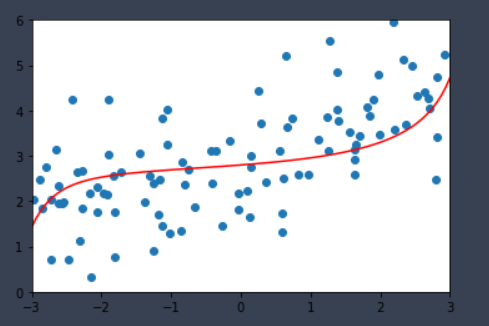
ridge3_reg = RidgeRegression(20, 100)
ridge3_reg.fit(X_train, y_train)
plot_model(ridge3_reg)
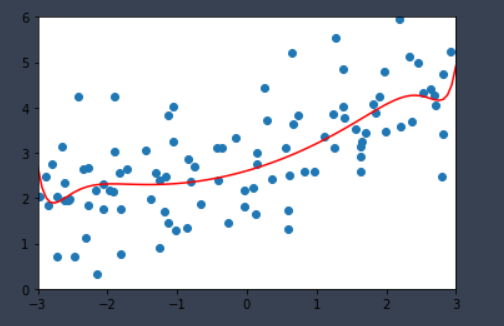
sklearn中Lasso回归 (Lasso)
Lasso回归损失函数:
l o s s = ω m i n 1 2 n s a m p l e s ∣ ∣ X ω − y ∣ ∣ 2 2 + α ∣ ∣ ω ∣ ∣ 1 loss=\stackrel{\mathrm{min}}{\omega} \frac{1}{2n_{samples}}||X\omega-y||_2^2+\alpha||\omega||_1 loss=ωmin2nsamples1∣∣Xω−y∣∣22+α∣∣ω∣∣1
Lasso回归不断使损失函数趋于最小,也使 w 参数向量中个别项变成0,固有特征选择的作用
PolynomialFeatures:多项式特征函数
StandardScaler:标准变换
Lasso:Lasso回归
from sklearn.linear_model import Lasso
def LassoRegression(degree, alpha):
return Pipeline([
("poly", PolynomialFeatures(degree=degree)),
("std_scaler", StandardScaler()),
("lasso_reg", Lasso(alpha=alpha))
])
lasso1_reg = LassoRegression(20, 0.01)
lasso1_reg.fit(X_train, y_train)
plot_model(lasso1_reg)
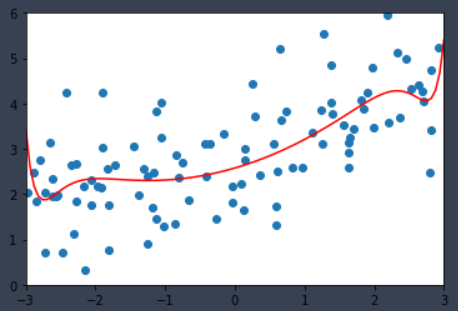
sklearn中弹性网络( Elastic Net)
Elastic Net回归损失函数:
ω m i n 1 2 n s a m p l e s ∣ ∣ X ω − y ∣ ∣ 2 2 + α ρ ∣ ∣ ω ∣ ∣ 1 + α ( 1 − ρ ) 2 ∣ ∣ ω ∣ ∣ 2 2 \stackrel{\mathrm{min}}{\omega} \frac{1}{2n_{samples}}||X\omega-y||_2^2+\alpha\rho||\omega||_1+\frac{\alpha(1-\rho)}{2}||\omega||_2^2 ωmin2nsamples1∣∣Xω−y∣∣22+αρ∣∣ω∣∣1+2α(1−ρ)∣∣ω∣∣22
Elastic Net 兼顾岭回归和Lasso回归的特性,通过调整参数 p,来调整占比
PolynomialFeatures:多项式特征函数
StandardScaler:标准变换
ElasticNet:Elastic Net回归
from sklearn.linear_model import ElasticNet
def ElasticNetRegression(degree, alpha,ration):
return Pipeline([
("poly", PolynomialFeatures(degree=degree)),
("std_scaler", StandardScaler()),
("elasticNet_reg", ElasticNet(alpha=alpha,l1_ratio=ration))
])
elasticNet_reg = ElasticNetRegression(20, 0.01,0.5)
elasticNet_reg.fit(X_train, y_train)
plot_model(elasticNet_reg)
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/230815.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
