大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
看到 intel向量化指令在矩阵乘应用中的评估_softee的专栏-CSDN博客 使用SIMD技术提高C++程序性能_章志强的专栏-CSDN博客中描述的效果而心动,然后咨询了下 Imageshop – 博客园 博主,我稍微看了下《simd for c++ developers》感觉SSE这些指令更像一种寄存器语言,乍一接触略不适应。然而我的疑问是:
1、如果对一个步骤我用了TBB/MKL/CILK这种易操作的并行指令,内部能否再用SSE指令,能否性能进一步提升?或者像OMP一样不适合嵌套并行?
答:以后测试就知道了。
2、这种向量化指令是否只对无依赖性流程可用?对dst(i)=src(i)+dst(i-1); 对类似这句是无法使用的?
感谢Imageshop – 博客园博主的回答:跟TBB一样可以用,只是需要优化技巧。
3、很多并行库只对原流程(串行下耗时较长)使用后性能提升明显,而对有的可并行流程(耗时原本就较短)的性能优化效果很弱甚至是反作用,SSE优化是不是也有这种问题?
依旧是Imageshop – 博客园博主的回答:SSE没有这种问题,对原耗时短的也有提速效果。
4、看 Intel® Intrinsics Guide 这里这么多指令,感觉不同的intel架构下支持的指令略有不同,而且学习这个要对不同类型有哪些支持的指令比较清楚。有的操作没有直接对应的指令,那么要学会转化围魏救赵一样去使用,就是要稍微有点优化技巧。
5、没找到别的章节 Basics of SIMD Programming ,只找到章节概要https://www.docsity.com/en/cell-programming-tutorial-lecture-notes-cisc-879/6776817/ ?另外可以看看youtube上的课程 https://www.youtube.com/watch?v=GwII1AJzKN4 !
6、SSE、SSE3等这些就是将汇编写的指令集包装成了C语言,然后供C/C++开发者方便调用而不用亲自去写汇编,同时可读性可维护性增强。
先查看自己支持的指令集如下图:
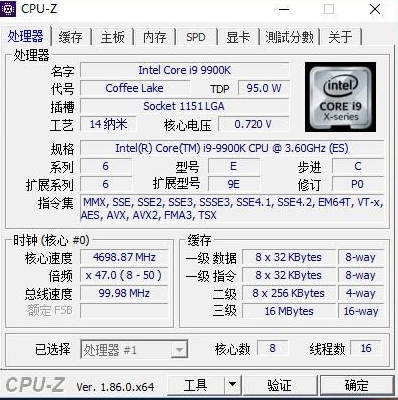
 然后根据资料
然后根据资料
一、《Write Fast Numerical Code》可以开始学习:
SSE只有integer和float两种寄存器数据类型,每种下面又分不同字节:
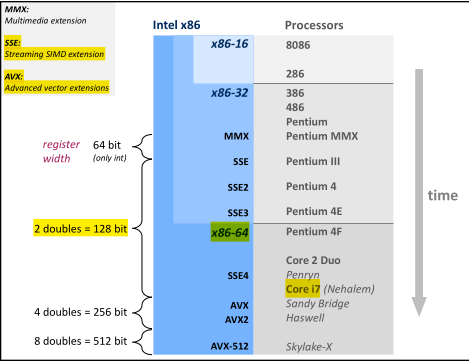
SSE的指令集模板是_mm_操作_数据类型这种形式,如下图:
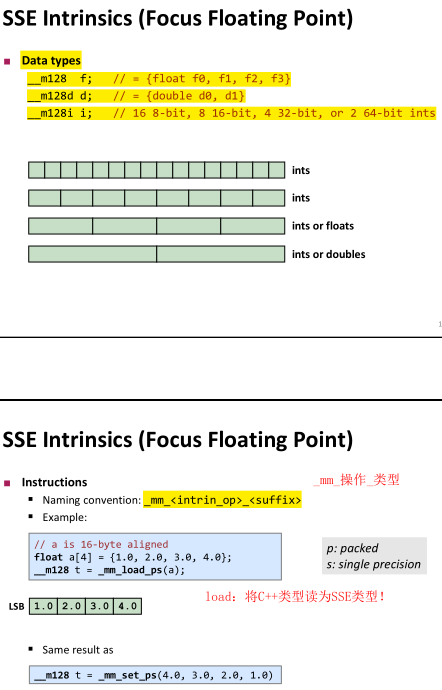
SSE有很多操作,比如存储、算术操作、逻辑等,先看第一个简单实例ubuntu:
#include <sys/time.h>
#include <xmmintrin.h>
#include <stdlib.h>
#include <cstdlib>
#include <iostream>
#include <random>
using namespace std;
void addindex(float *x, int n,float *y);
void addindex_vec(float *x, int n,float *y);
void addindex2_vec(float *x, int n,float *y);
int checkresults(float *cresult,float *sseresult,int nlength);
int main()
{
const int num=256000;
float x_para[num],y_parac[num],y_parasse1[num],y_parasse2[num];
// float *x_para = (float *)aligned_alloc(num, num * sizeof(float));
// float *y_parac = (float *)aligned_alloc(num, num * sizeof(float));
// float *y_parasse1 = (float *)aligned_alloc(num, num * sizeof(float));
// float *y_parasse2 = (float *)aligned_alloc(num, num * sizeof(float));
default_random_engine enginer;
uniform_real_distribution<float> tmp(0, 1);
for (size_t id = 0; id < num; ++id)
{
x_para[id]=tmp(enginer);
}
clock_t clockBegin,clockEnd;
double timeused;
clockBegin=clock();
addindex(x_para, num,y_parac);
clockEnd=clock();
timeused=(double)(clockEnd-clockBegin)/CLOCKS_PER_SEC;
cout<<"original C++ time:"<<1000*timeused<<" ms!"<<endl;
clockBegin=clock();
addindex_vec(x_para, num,y_parasse1);
clockEnd=clock();
timeused=(double)(clockEnd-clockBegin)/CLOCKS_PER_SEC;
cout<<"SSE version1 time:"<<1000*timeused<<" ms!"<<endl;
checkresults(y_parac,y_parasse1,num);
clockBegin=clock();
addindex2_vec(x_para, num,y_parasse2);
clockEnd=clock();
timeused=(double)(clockEnd-clockBegin)/CLOCKS_PER_SEC;
cout<<"SSE version2 time:"<<1000*timeused<<" ms!"<<endl;
checkresults(y_parac,y_parasse2,num);
return 0;
}
void addindex(float *x, int n,float *y) {
for (int i = 0; i < n; i++)
y[i] = x[i] + i;
}
void addindex_vec(float *x, int n,float *y) {
__m128 index, x_vec;
for (int i = 0; i < n; i+=4) {
x_vec = _mm_load_ps(x+i); // load 4 floats
index = _mm_set_ps(i+3, i+2, i+1, i); // create vector with indexes
x_vec = _mm_add_ps(x_vec, index); // add the two
_mm_store_ps(y+i, x_vec); // store back
}
}
void addindex2_vec(float *x, int n,float *y) {
__m128 x_vec, incr;
__m128 ind = _mm_set_ps(3, 2, 1, 0);
incr = _mm_set1_ps(4);
for (int i = 0; i < n; i+=4) {
x_vec = _mm_load_ps(x+i); // load 4 floats
x_vec = _mm_add_ps(x_vec, ind); // add the two
ind = _mm_add_ps(ind, incr); // update ind
_mm_store_ps(y+i, x_vec); // store back
}
}
int checkresults(float *cresult,float *sseresult,int nlength)
{
for (int i = 0; i < nlength/2; i++)
{
if(cresult[i]!=sseresult[i])
{
cout<<"Error:Two results do not match well!"<<endl;
return -1;
}
}
cout<<"SSE succeed !"<<endl;
return 0;
}问题1:为什么不用aligned_alloc 也可以?
我只知道如果用malloc初始化的数据是没有对齐的。
问题2:SSE耗时并没有少于C++的,为什么?
不过的确version2不用在loop内set了,耗时比version1少。这样看来,要十分清楚哪些指令expensive,这样才好用别的指令替代。
问题2我查了一下,不知道是不是别人说的“测试方式不太对,因为这种测试如果放到一个简单的环境里,CPU的缓冲机制不能达到最优状态,所以你的测试结果很可能不正确而且会差很远.如果把这个代码放到一个比较复杂的环境里,得出的结果可能会正确一些.” 这个原因?
看第二个例子
#include <sys/time.h>
#include <xmmintrin.h>
#include <stdlib.h>
#include <cstdlib>
#include <iostream>
#include <random>
using namespace std;
void lp(float *x, float *y, int n);
void lp_vec(float *x,float *y, int n) ;
int checkresults(float *cresult,float *sseresult,int nlength);
int main()
{
const int num=160000;
// float x_para[num],y_para[num];
float *x_para = (float *)aligned_alloc(num, num * sizeof(float));
float *y_parac = (float *)aligned_alloc(num, num * sizeof(float));
float *y_parasse = (float *)aligned_alloc(num, num * sizeof(float));
default_random_engine enginer;
uniform_real_distribution<float> tmp(0, 1);
for (size_t id = 0; id < num; ++id)
{
x_para[id]=tmp(enginer);
}
clock_t clockBegin,clockEnd;
double timeused;
clockBegin=clock();
lp(x_para, y_parac, num);
clockEnd=clock();
timeused=(double)(clockEnd-clockBegin)/CLOCKS_PER_SEC;
cout<<"original C++ time:"<<1000*timeused<<" ms!"<<endl;
clockBegin=clock();
lp_vec(x_para, y_parasse, num);
clockEnd=clock();
timeused=(double)(clockEnd-clockBegin)/CLOCKS_PER_SEC;
cout<<"SSE version1 time:"<<1000*timeused<<" ms!"<<endl;
checkresults(y_parac,y_parasse,num);
return 0;
}
void lp(float *x, float *y, int n) {
for (int i = 0; i < n/2; i++)
y[i] = (x[2*i] + x[2*i+1])/2;
}
// n a multiple of 8, x, y are 16-byte aligned
void lp_vec(float *x,float *y, int n) {
__m128 half, v1, v2, avg;
half = _mm_set1_ps(0.5); // set vector to all 0.5
for(int i = 0; i < n/8; i++) {
v1 = _mm_load_ps(x+i*8); // load first 4 floats
v2 = _mm_load_ps(x+4+i*8); // load next 4 floats
avg = _mm_hadd_ps(v1, v2); // add pairs of floats
avg = _mm_mul_ps(avg, half); // multiply with 0.5
_mm_store_ps(y+i*4, avg); // save result
}
}root@rootwd-Default-string:/home/jumper/xrt/parallel/studySSE/Release# ./studySSE
original C++ time:0.441 ms!
SSE version1 time:0.37 ms!
SSE succeed !
root@rootwd-Default-string:/home/jumper/xrt/parallel/studySSE/Release# ./studySSE
original C++ time:0.213 ms!
SSE version1 time:0.184 ms!
SSE succeed !
root@rootwd-Default-string:/home/jumper/xrt/parallel/studySSE/Release# ./studySSE
original C++ time:0.427 ms!
SSE version1 time:0.417 ms!
SSE succeed !
root@rootwd-Default-string:/home/jumper/xrt/parallel/studySSE/Release# ./studySSE
original C++ time:0.422 ms!
SSE version1 time:0.419 ms!
SSE succeed !
root@rootwd-Default-string:/home/jumper/xrt/parallel/studySSE/Release# ./studySSE
original C++ time:0.146 ms!
SSE version1 time:0.141 ms!
SSE succeed !
root@rootwd-Default-string:/home/jumper/xrt/parallel/studySSE/Release# ./studySSE
original C++ time:0.421 ms!
SSE version1 time:0.453 ms!
SSE succeed !
root@rootwd-Default-string:/home/jumper/xrt/parallel/studySSE/Release# ./studySSE
original C++ time:0.108 ms!
SSE version1 time:0.106 ms!
SSE succeed !
root@rootwd-Default-string:/home/jumper/xrt/parallel/studySSE/Release# ./studySSE
original C++ time:0.148 ms!
SSE version1 time:0.14 ms!
SSE succeed !第二个例子 向量内相邻元素相加得到新的结果,但这个为什么SSE并没有快 ?而第三个例子却快呢?初始化问题? 看下面:
#include <sys/time.h>
#include <iostream>
#include <random>
//SSE
#include <xmmintrin.h>
//SSE2
//#include <emmintrin.h>
//SSE3 add -msse3
#include <pmmintrin.h>
using namespace std;
void lp(float *x,float *y,int n) {
for(int i = 0; i < n/2; i++) {
y[i]=(x[2*i]+x[2*i+1])/2;
}
}
void lp_SSE(float *x,float *y,int n) {
__m128 half,v1,v2,avg;
half=_mm_set1_ps(0.5);
for(int i = 0; i < n/8; i++) {
v1=_mm_load_ps(x+i*8);
v2=_mm_load_ps(x+4+i*8);
avg=_mm_hadd_ps(v1,v2);
avg=_mm_mul_ps(avg,half);
_mm_store_ps(y+i*4,avg);
}
}
int checkresults(float *cresult,float *sseresult,int nlength)
{
for (int i = 0; i < nlength; i++)
{
if(cresult[i]!=sseresult[i])
{
cout<<"Error:Two results do not match well!"<<endl;
return -1;
}
}
cout<<"SSE succeed !"<<endl;
return 0;
}
int main()
{
const int num=64000;//256000;
float x_para[num],y_para[num],x_parasse[num],y_parasse[num];
// float *x_para = (float *)aligned_alloc(num, num * sizeof(float));
// float *y_parac = (float *)aligned_alloc(num, num * sizeof(float));
// float *y_parasse1 = (float *)aligned_alloc(num, num * sizeof(float));
// float *y_parasse2 = (float *)aligned_alloc(num, num * sizeof(float));
default_random_engine enginer;
uniform_real_distribution<float> tmp(0, 1);
for (size_t id = 0; id < num; ++id)
{
x_para[id]=tmp(enginer);
y_para[id]=tmp(enginer);
x_parasse[id]=x_para[id];
y_parasse[id]=y_para[id];
}
clock_t clockBegin,clockEnd;
double timeused;
clockBegin=clock();
lp(x_para,y_para, num);
clockEnd=clock();
timeused=(double)(clockEnd-clockBegin)/CLOCKS_PER_SEC;
cout<<"original C++ time:"<<1000*timeused<<" ms!"<<endl;
clockBegin=clock();
lp_SSE(x_parasse,y_parasse, num);
clockEnd=clock();
timeused=(double)(clockEnd-clockBegin)/CLOCKS_PER_SEC;
cout<<"SSE version1 time:"<<1000*timeused<<" ms!"<<endl;
checkresults(y_para,y_parasse,num);
return 0;
}
而这个时间却快了?????为什么
root@rootwd-Default-string:/home/jumper/xrt/parallel/studySSE/Release# ./studySSE
original C++ time:0.039 ms!
SSE version1 time:0.024 ms!
SSE succeed !
root@rootwd-Default-string:/home/jumper/xrt/parallel/studySSE/Release# ./studySSE
original C++ time:0.067 ms!
SSE version1 time:0.034 ms!
SSE succeed !
root@rootwd-Default-string:/home/jumper/xrt/parallel/studySSE/Release# ./studySSE
original C++ time:0.081 ms!
SSE version1 time:0.051 ms!
SSE succeed !
root@rootwd-Default-string:/home/jumper/xrt/parallel/studySSE/Release# ./studySSE
original C++ time:0.066 ms!
SSE version1 time:0.034 ms!
SSE succeed !
root@rootwd-Default-string:/home/jumper/xrt/parallel/studySSE/Release# ./studySSE
original C++ time:0.075 ms!
SSE version1 time:0.037 ms!
SSE succeed !
root@rootwd-Default-string:/home/jumper/xrt/parallel/studySSE/Release# ./studySSE
original C++ time:0.017 ms!
SSE version1 time:0.014 ms!
SSE succeed !
root@rootwd-Default-string:/home/jumper/xrt/parallel/studySSE/Release# ./studySSE
original C++ time:0.067 ms!
SSE version1 time:0.044 ms!
SSE succeed !
root@rootwd-Default-string:/home/jumper/xrt/parallel/studySSE/Release# ./studySSE
original C++ time:0.02 ms!
SSE version1 time:0.014 ms!
SSE succeed !
root@rootwd-Default-string:/home/jumper/xrt/parallel/studySSE/Release# ./studySSE
original C++ time:0.068 ms!
SSE version1 time:0.037 ms!
SSE succeed !比较指令有很多:
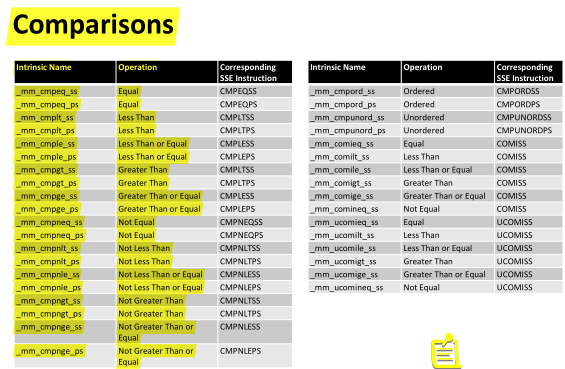
看第三个例子 是使用比较指令的例子:
#include <xmmintrin.h>
#include <sys/time.h>
#include <iostream>
#include <random>
using namespace std;
void fcond(float *x, size_t n) {
int i;
for(i = 0; i < n; i++) {
if(x[i] > 0.5)
x[i] += 1.;
else x[i] -= 1.;
}
}
void fcondvec(float *x, size_t n) {
int i;
__m128 vt, vmask, vp, vm, vr, ones, mones, thresholds;
ones= _mm_set1_ps(1.);
mones= _mm_set1_ps(-1.);
thresholds = _mm_set1_ps(0.5);
for(i = 0; i < n; i+=4) {
vt= _mm_load_ps(x+i);
vmask = _mm_cmpgt_ps(vt, thresholds);
vp= _mm_and_ps(vmask, ones);
vm= _mm_andnot_ps(vmask, mones);
vr= _mm_add_ps(vt, _mm_or_ps(vp, vm));
_mm_store_ps(x+i, vr);
}
}
int checkresults(float *cresult,float *sseresult,int nlength)
{
for (int i = 0; i < nlength; i++)
{
if(cresult[i]!=sseresult[i])
{
cout<<"Error:Two results do not match well!"<<endl;
return -1;
}
}
cout<<"SSE succeed !"<<endl;
return 0;
}
int main()
{
const int num=256000;//1600;//
float x_para[num],y_parac[num],y_parasse1[num],y_parasse2[num];
// float *x_para = (float *)aligned_alloc(num, num * sizeof(float));
// float *y_parac = (float *)aligned_alloc(num, num * sizeof(float));
// float *y_parasse1 = (float *)aligned_alloc(num, num * sizeof(float));
// float *y_parasse2 = (float *)aligned_alloc(num, num * sizeof(float));
default_random_engine enginer;
uniform_real_distribution<float> tmp(0, 1);
for (size_t id = 0; id < num; ++id)
{
x_para[id]=tmp(enginer);
y_parasse1[id]=x_para[id];
}
clock_t clockBegin,clockEnd;
double timeused;
clockBegin=clock();
fcond(x_para, num);
clockEnd=clock();
timeused=(double)(clockEnd-clockBegin)/CLOCKS_PER_SEC;
cout<<"original C++ time:"<<1000*timeused<<" ms!"<<endl;
clockBegin=clock();
fcondvec(y_parasse1, num);
clockEnd=clock();
timeused=(double)(clockEnd-clockBegin)/CLOCKS_PER_SEC;
cout<<"SSE version1 time:"<<1000*timeused<<" ms!"<<endl;
checkresults(x_para,y_parasse1,num);
return 0;
}root@rootwd-Default-string:/home/jumper/xrt/parallel/studySSE/Release# ./studySSE
original C++ time:1.044 ms!
SSE version1 time:0.128 ms!
SSE succeed !
root@rootwd-Default-string:/home/jumper/xrt/parallel/studySSE/Release# ./studySSE
original C++ time:1.333 ms!
SSE version1 time:0.08 ms!
SSE succeed !
root@rootwd-Default-string:/home/jumper/xrt/parallel/studySSE/Release# ./studySSE
original C++ time:1.455 ms!
SSE version1 time:0.101 ms!
SSE succeed !
root@rootwd-Default-string:/home/jumper/xrt/parallel/studySSE/Release# ./studySSE
original C++ time:1.45 ms!
SSE version1 time:0.088 ms!
SSE succeed !
root@rootwd-Default-string:/home/jumper/xrt/parallel/studySSE/Release# ./studySSE
original C++ time:3.807 ms!
SSE version1 time:0.209 ms!
SSE succeed !从后几个例子看出,哪怕耗时很小的函数,用SSE也可以有性能提升。
 看上图这个使用shuffle的加载方式竟然需要7步!太麻烦了。
看上图这个使用shuffle的加载方式竟然需要7步!太麻烦了。
下面这个指令是这样理解吧:
e=_mm_shuffle_ps(a, b, _MM_SHUFFLE(a_id2,a_id1,b_id2,b_id1)); 然后得到:e:[ a[a_id1], a[a_id2], b[b_id1], b[b_id2] ] 这样的结果 ,对吗?!但所谓加载数据不用上面那么麻烦使用多次Shuffle,而可以直接使用_mm_load_ps()和_mm_set_ps()!!! 对数据的加载是这样,相应的对数据的存储也是如此!!!
 这个是不是说_mm_load_ps()这种加载会默认使用对齐方式?!哪怕数据是原本不对齐的,这样加载后也是默认对齐了?! 所以Example中就不建议使用align后再load,因为重复了??而_mm_set_ps这种实际是使用shuffle那种需要7个步骤的笨方式,所以这句的开销实际比load大?!是这样理解吗?应该是吧。
这个是不是说_mm_load_ps()这种加载会默认使用对齐方式?!哪怕数据是原本不对齐的,这样加载后也是默认对齐了?! 所以Example中就不建议使用align后再load,因为重复了??而_mm_set_ps这种实际是使用shuffle那种需要7个步骤的笨方式,所以这句的开销实际比load大?!是这样理解吗?应该是吧。
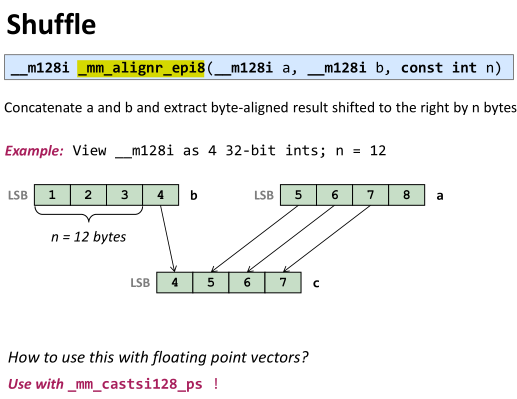
第四个例子:很奇怪,为什么加了 tmmintrin.h以及 -msse3 这个移位函数还是不行??
#include <stdio.h>
#include <xmmintrin.h>
#include <tmmintrin.h> //_mm_alignr_epi8 ///usr/local/lib/gcc/x86_64-pc-linux-gnu/9.1.0/include
using namespace std;
int main () {
float aorigi[4]={1.0,2.0,3.0,4.0};
float borigi[4]={5.0,6.0,7.0,8.0};
__m128 atmp=_mm_load_ps(aorigi);
__m128 btmp=_mm_load_ps(borigi);
__m128i a, b;
a=_mm_castps_si128(atmp);
b=_mm_castps_si128(btmp);
// A right align value of four should remove the lowest 4 bytes of "b"
__m128i res = _mm_alignr_epi8( a, b, 4);
return 0;
}
查了一下好像是默认的不是这个形参?有人跑起来了吗?
 之前那个例子这里又出了一种写法,感觉SIMD就是有很多方式实现一种功能,所以操作者就要很清楚哪种方式最适合,也就是哪些指令开销最小,throughout最大从而使性能最大。这是需要比较测试、长期积累的经验。
之前那个例子这里又出了一种写法,感觉SIMD就是有很多方式实现一种功能,所以操作者就要很清楚哪种方式最适合,也就是哪些指令开销最小,throughout最大从而使性能最大。这是需要比较测试、长期积累的经验。
 不知道是否这样翻译。
不知道是否这样翻译。
 还有就是这个老建议,无论在哪里都尽量按行访问。还有就是尽量让loop停止条件简单,而且在循环时停止条件始终是固定的,这样最好;
还有就是这个老建议,无论在哪里都尽量按行访问。还有就是尽量让loop停止条件简单,而且在循环时停止条件始终是固定的,这样最好;
还建议少用打破循环的指令如break、goto等;
循环每次之间尽量无依赖,比如read-after-write操作,这样会让并行/矢量操作正确性受影响;
少用指针;
直接使用数组下标作为循环计数,而不要另外搞个单独的计数器;
循环次数尽量是已知的。循环的步长尽量是1即每次+=1
至此《write fast code》基本看完了。
二、OpenMP
之前搞并行时其实就已经测试过了OpenMP,但并没有任何加速效果!
今天却看到了openmp-simd相关内容User-Mandated or SIMD Vectorization
如果自定义的整个函数都想自动矢量化,那么要遵循以下的这些条件:

发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/230802.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
