大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
功能
读取excel文件,并进行操作
方法
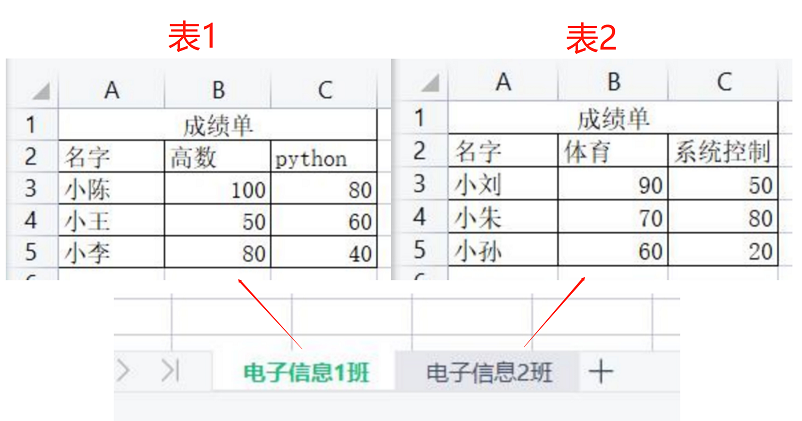
示例文件
本文用到的示例文件为一个excel表格,含有名为“电子信息1班”和“电子信息2班”两个Sheet。其内容均为成绩单。

模块读取
>>> from openpyxl import load_workbook
导入excel表格
使用load_workbook('表名.xlsx')导入excel表格:
>>> wb = load_workbook("电信成绩单.xlsx")
>>> wb
<openpyxl.workbook.workbook.Workbook at 0x1ad7ad45ac8>
经过测试发现,active默认首先展示的似乎是,保存excel的时候最后点开的那个Sheet,而非默认展示表格里的第一个Sheet。因此,这里我们显示的是第二个Sheet“电子信息2班”:
>>> ws = wb.active
>>> ws
<Worksheet "电子信息2班">
既然如此,就用第二个sheet作为示例吧!
获取Sheet
- 使用
get_sheet_by_name('表名')获取指定的表:
>>> wb.get_sheet_by_name('电子信息1班')
<Worksheet "电子信息1班">
- 使用
get_sheet_names()直接获取全部表名,输出为list形式:
>>> sheet_name = wb.get_sheet_names()
>>> sheet_name
['电子信息1班', '电子信息2班']
查看行与列
- 查看最大行数:
>>> row_num = ws.max_row
>>> row_num
5
- 查看最大列数:
>>> col_num = ws.max_column
>>> col_num
3
查看单元格
- 查看A1单元格的内容:
>>> a1 = ws['A1'].value
>>> a1
'成绩单'
查看A1单元格显示的是“成绩单”,但是A1B1C1被我合并为了一个单元格,是否查看B1C1同样也是返回“成绩单”呢?
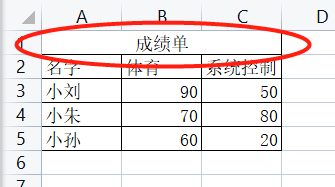
然而,查看B1、C1,显示的为None。看来,合并后的单元格只能默认使用其第一个小单元格地址来查询。
>>> b1 = ws['B1'].value
>>> print(b1)
None
>>> c1 = ws['C1'].value
>>> print(c1)
None
- 查看第二行第一列的内容:
>>> b = ws.cell(row = 2,column = 1).value
>>> b
'名字'
批量访问数据
>>> ws.rows
<generator object Worksheet._cells_by_row at 0x000001CDD21BD3B8>
>>> ws.columns
<generator object Worksheet._cells_by_col at 0x000001CDD21BD048>
- 按行访问数据:
>>> lst = []
>>> for row in ws.rows:
>>> for col in row:
>>> lst.append(col.value)
>>> print(lst)
['成绩单', None, None, '名字', '体育', '系统控制', '小刘', 90, 50, '小朱', 70, 80, '小孙', 60, 20]
- 按列访问数据:
>>> lst = []
>>> for col in ws.columns:
>>> for row in col:
>>> lst.append(row.value)
>>> print(lst)
['成绩单', '名字', '小刘', '小朱', '小孙', None, '体育', 90, 70, 60, None, '系统控制', 50, 80, 20]
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/230758.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
