大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
这篇博客主要介绍神经网络基础,单隐层前馈神经网络与反向传播算法。
神经网络故名思议是由人的神经系统启发而得来的一种模型。神经网络可以用来做分类和回归等任务,其具有很好的非线性拟合能力。接下来我们就来详细介绍一下但隐层前馈神经网络。
首先我们来看一下神经元的数学模型,如下图所示:
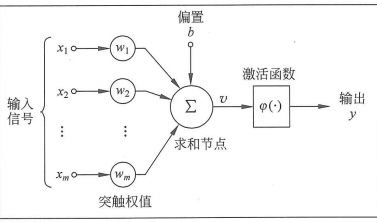

可以看到为输入信号,而神经元最终输出为,由此我们可以看到,单个神经元是多输入单输出的。但是从上图我们可以看到,有输入到输出中间还经历了一些步骤,这些步骤在神经网络中是非常关键的,因为正是有了中间这些步骤,一个神经网络才能够真正的具有了非线性拟合能力,这是为什么呢?接下来就给出解释。
从上图中输入首先遇到了权值做了一个加权求和的操作,并对加权求和的结果加入了偏置,得到了输出,如上图求和节点所示,具体数学公式如下所示:
到这一步还没有使得神经网络具有非线性拟合能力,因为正如我们所看到的,所有的操作对于输入来说都是线性的,使得神经网络具有非线性拟合能力的一步是下一步操作,如上图中激活函数处所示,我们将线性加权求和得到的输出输入到了一个叫做激活函数的东西里面,那么激活函数又是什么呢?实际上激活函数就是一个非线性的一个函数,如上图中就是激活函数,那么常用的激活函数有以下几种:
对于前两个激活函数,sigmoid激活函数将输入值压缩到了0到1之间,但其缺点是存在梯度消失的问题,如下图所示:
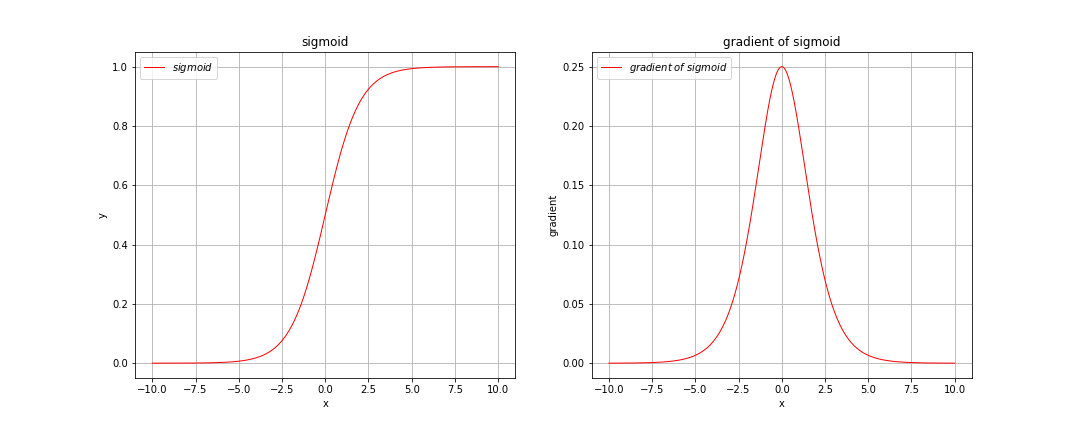
可以看到当sigmoid的输入很大或很小时,其梯度几乎趋近于0。
再来看tanh激活函数,如下图所示:
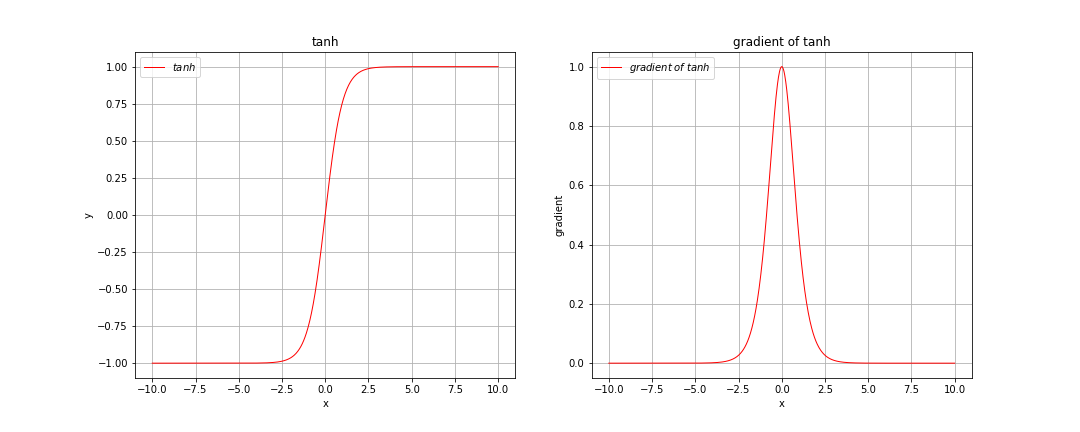
由上图可以看出,tanh激活函数和sigmoid激活函数非常相似,只不过tanh激活函数将输入值压缩到了-1到1之间,由其梯度图像可以看出,当输入很大或很小时梯度也是趋于0的。
最后让我们来看一下relu激活函数,如下图所示:
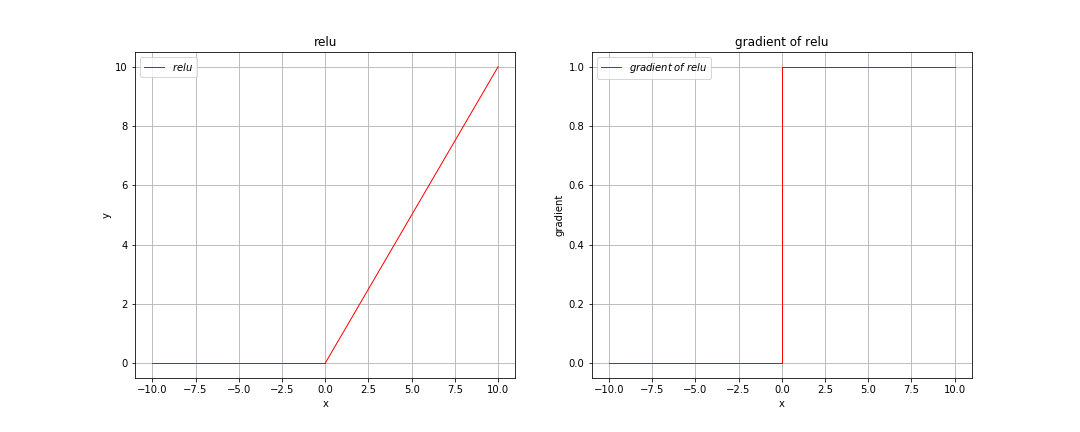
从上图中可以看出,relu激活函数在0到正无穷上会随着输入的增大而无限增大,在小于0的区间上其值全为0,但是我们还可以看到其梯度在0到正无穷上永远为1。
由于神经网络最后对于损失函数的优化也是使用梯度下降,因此在实际运用中,我们基本上会经常用relu激活函数,因为sigmoid激活函数以及tanh激活函数从上面的图像中已经可以看出,其存在梯度消失的问题,我们知道,当我们使用梯度下降去优化某个损失函数时,是需要求梯度的,但是如果输入过大(可能初始化权重过大,也可能特征过大)并且采取的是sigmoid或tanh激活函数,那么当我们在输入位置求取梯度时其梯度值趋近于0,而我们对于参数的更新量也趋近于0,因此最终会因为梯度消失的问题造成收敛过慢,因此我们会使用relu激活函数来加快收敛速度,但relu激活函数的精度不如sigmoid激活函数。
接下来我们看一下单隐层前馈神经网络一般结构,如下图:
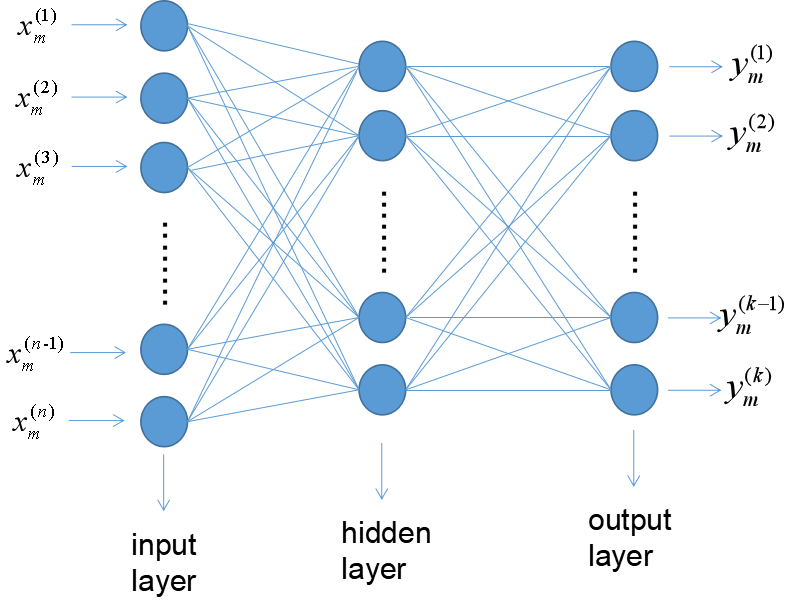
其中表示第m个样本的第n个特征,可以看到输入层神经元神经元个数应该和一个样本的特征数一样,而表示第m个样本的第k个输出,通常情况下,如果这是一个分类问题则,如果是回归问题则。
下面举一个结构比较简单的网络来说明但隐层前馈网络的工作机理,网络结构如下图:
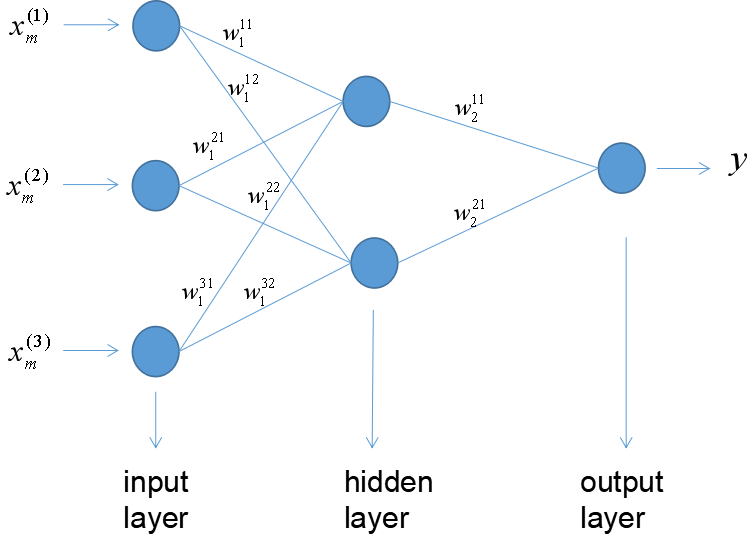
上图中表示第层第i个神经元和第层的第j个神经元链接权重。则隐层神经元输出计算公式如下:
其中表示第i隐层的第j个神经元的输出。而表示第i隐层神经元输出时所用的激活函数,表示第i隐层的第j个神经元的计算线性加权求和时所用的偏置,由于是但隐层神经网络,所以上述所说的第i隐层就可以直接理解为隐层即可。
而输出层神经元的输出计算公式如下:
当我们求得输出之后就能够计算输出与真实之之间的差距,我们称为损失,我们往往是送入一批数据,所以会求得一批损失,这里我们以回归问题为例求取均方误差:
其中为网络输出,而为样本真实标记。
当我们求得损失函数后,我们就可以对各个参数求偏导计算梯度,进而进行梯度下降来优化损失函数。
注意如果是回归问题最后输出层不进行激活函数的激活操作,因为如果采用sigmoid或tanh激活函数激活后输出永远在0到1区间内或-1到1区间内,而如果采取relu激活函数激活,则输出舍弃了负值的那一部分,这样可能永远都不能很好的拟合真实值;而如果是分类问题便可以使用激活函数,并且如果是分类问题,我们的输出层神经元个数同类别数目是一样的,并且我们首先需要将样本标记进行one_hot编码,使每个样本标记是一个概率分布,即某个类别的概率为1。我们网络输出之后需要进行一个softmax将网络输出转化为一个概率分布,而我们的损失是求取网络输出的概率分布和真实样本标记的交叉熵(交叉熵可以衡量两个概率分布之间的距离,我们希望真实的概率分布和网络输出的概率分布距离越小越好),同样我们往往是求取一批样本的交叉熵然后取均值作为损失函数,之后同回归问题一样对其进行梯度下降优化即可。
以下是本人用python以及tensorflow库编写的但隐层神经网络供大家参考:
# coding: utf-8
# In[1]:
import numpy as np
from numpy import random as rd
import matplotlib.pyplot as plt
import tensorflow as tf
# In[2]:
# 构造样本点
x = np.linspace(-5, 5, 100)
# 对x做了个升维,样本变成了[x, x**2, x**3]
x = np.concatenate([x.reshape(-1, 1), np.power(x.reshape(-1, 1), 2),
np.power(x.reshape(-1, 1), 3)], axis=1)
y = (np.sin(x[:, 0]) + rd.uniform(-0.2, 0.2, 100)).reshape(-1, 1)
# unit_count_of_hidden_layer是指定隐层神经元个数的,max_train_step表示训练多少次,
# learning_rate表示梯度下降的学习率
unit_count_of_hidden_layer = 10
max_train_step = 2000
learning_rate = 0.1
# In[3]:
def add_layer(layer_number, input_value, unit_count, activation_function):
# 用来添加隐层和输出层
# input_value是隐层的输入
# unit_count是隐层的神经元个数
# activation_function指定激活函数:tf.nn.relu或tf.nn.sigmoid或tf.nn.tanh
with tf.variable_scope("layer_%d" % layer_number, reuse=tf.AUTO_REUSE):
weight = tf.get_variable(shape=[input_value.shape[-1], unit_count],
dtype=tf.float32, initializer=tf.random_normal_initializer(mean=1, stddev=1),
name="weights", trainable=True)
bias = tf.get_variable(shape=[1, unit_count], dtype=tf.float32, initializer=tf.constant_initializer(0),
name="bias", trainable=True)
matmul_add_bias_result = tf.add(tf.matmul(input_value, weight), bias, name="matmul_add_bias")
output = matmul_add_bias_result
if activation_function:
output = activation_function(matmul_add_bias_result)
return output
def demo():
x_placeholder = tf.placeholder(shape=[100, x.shape[-1]], dtype=tf.float32, name="x_input")
y_placeholder = tf.placeholder(shape=[100, 1], dtype=tf.float32, name="y_input")
hidden_layer_output = add_layer(1, x_placeholder, unit_count_of_hidden_layer, tf.nn.sigmoid)
y_output = add_layer(2, hidden_layer_output, 1, None)
loss = tf.reduce_mean(tf.square(y_output - y_placeholder))
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)
train_op = optimizer.minimize(loss)
init_op = tf.global_variables_initializer()
with tf.Session(config=tf.ConfigProto(allow_soft_placement=True)) as sess:
sess.run(init_op)
for i in range(1, 1 + max_train_step):
_, loss_, y_output_ = sess.run(fetches=[train_op, loss, y_output],
feed_dict={x_placeholder: x, y_placeholder: y})
if i % int(0.1 * max_train_step) == 0:
print("第%d次迭代损失:%f" % (i, loss_))
return y_output_
# In[4]:
y_predict = demo()
# In[5]:
# 画图
fig = plt.figure(figsize=(8, 6))
ax = plt.subplot(1, 1, 1)
ax.scatter(x[:, 0], y, color="r", label="samples")
ax.plot(x[:, 0], y_predict, linewidth=1, label="predict", color="b")
ax.set_xlabel("x")
ax.set_ylabel("y")
ax.legend(loc="upper right")
plt.show()
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/227999.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
