大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
《Caffeine入门使用》 -> 《Caffeine基础源码解析》 -> 《Caffeine 驱逐算法》
一、概况
就一般的互联网行业中的应用而言,目前比较通用的并且也是普遍存在的一个应用工作过程,如下图所示:用户从浏览器发出请求-网络转发-应用服务业务处理-底层存储信息获取,然后逆向的返回给用户,形成页面给予用户相应信息。


随着业务的上升,用户量的增加,访问量也会随之增加,如果是计算型的服务,那么对于服务器的计算能力是一个考验,如果是IO型的服务,那么频繁的从文件系统、数据库等磁盘文件获取信息会造成比较大的延时且压力也比较大。因为我们的服务资源是有限的,并且技术革新也不是很迅速,那么我们如何利用有限的服务资源支撑更大的吞吐量呢?业界内很常见的一个普遍方案就是引进缓存,将计算结果、磁盘文件结果信息缓存于内存之中,那么上图中每个环节都可以从缓存中直接获取所需信息,减少应用服务器的压力,也就是通过减少磁盘读取、数据计算等方式来快速获取所需结果,提高相应速度。
当我们提到缓存的时候,第一时间就会想到Redis、memcached缓存中间件,他们支持分布式的缓存,还有一种是基于单机内存的缓存方式,例如最简单的java中的局部变量、java中的ConcurrentHashMap、谷歌发布的Guava cache组件以及本文讲解的Caffeine cache,他们将缓存信息存储于应用本身的内存之中,业务可以缓存组件的API去操作内存中的缓存数据。
简介
Caffeine是一款基于jdk8实现的缓存工具,在设计上参考了google的Guava cach组件,可以理解为是一个GuavaCache的加强版本,性能也是在其基础上有了提升。
Caffeine cache的作者是Ben manes,可以通过他的github:github.com/ben-manes来查看组件的源码 ,并且他还编写了ConcurrentLinkedHashMap工具类,也被用于缓存的底层数据结构,比如:这个类就是Guava cache的基础。我们知道Guava cache是基于LRU算法实现的一种缓存工具,LRU算法的缺点是短暂持续性冷数据流量会导致热数据的淘汰,造成数据的污染。而Caffeine cache采用了在LRU基础上的W-TinyLFU算法实现,有比较好的命中率。
优点
Caffeine淘汰算法:使用基于W-TinyLFU算法,实现几乎完美的命中率;
-
FIFO:实现简单,类似于队列,先进先出,因此缓存命中率不是很高。
-
LRU:最近最久未使用算法(Least Recently Used)如果一个数据在一段时间内没有被访问,那么我们认为后面被访问的概率也很小。当我们添加新数据的时候,会把新数据放到队尾(假设新数据最大概率被再次访问),当我们长度到达阈值需要淘汰数据的时候,会从队首进行淘汰。这种算法造成缓存污染的概率会大些,比如现在有一些较少数据突增流量,但是后面不在访问,那么此时已经将热数据淘汰出去了,而缓存的数据后面也几乎不被访问。
-
LFU:最近最少使用算法(Least Frequently Used)如果一个数据在一段时间内访问的频率很小,那么认为后面被访问的几率也很小,所以淘汰访问频率最少的数据;该算法可以处理LRU因为冷数据突增带来的缓存污染问题。存在的问题是数据访问模式如果改变,这种算法命中率会下降,并且需要额外的空间存储信息频率。
-
W-TinyLFU:记录了近期访问记录的频率信息,不满足的记录不会进入到缓存。使用Count-Min Sketch算法记录访问记录的频率信息。依靠衰减操作,来尽可能的支持数据访问模式的变化。
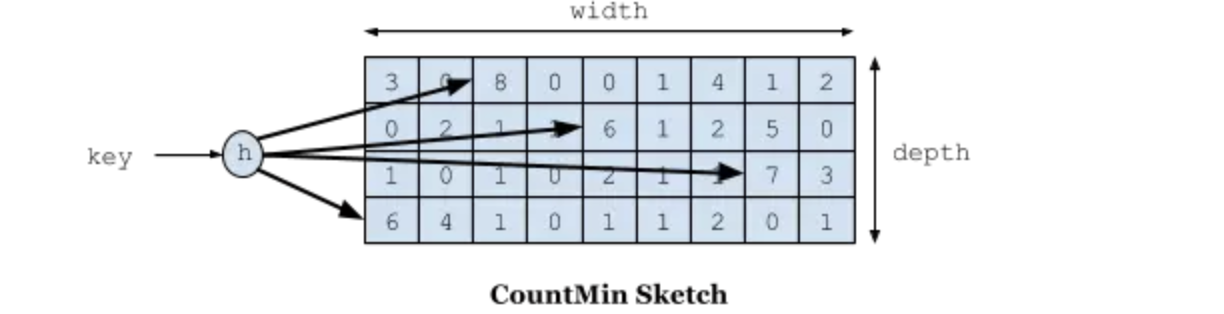

该算法和布隆过滤器有着相似的原理,通过多个哈希函数和位的标志来表示一个结果,可以通过结合布隆过滤器一起理解这个算法。一些常用的页面置换算法可参考文章《缓存算法》
适用场景
因为Caffeine cache是类似于Guava cache的一种内存缓存,所以适合单机的数据缓存;因为存储在内存的,没有持久化,因此适合一些短期或者启动以及结果信息的短暂缓存。当涉及到多机多服务的缓存时候,属于分布式缓存的范畴,可以使用Redis、memcached等分布式的缓存组件。
二、使用
因为是基于Guava cache实现的,因此二者的API大体是类似的,使用Guava cache的开发者可以很快熟练使用Caffeine cache。
坐标
目前Caffeine的最新版是2.8.5版本,本文使用的是2.8.0版本
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
<version>2.8.0</version>
</dependency>
缓存填充策略
缓存的填充方式有三种,手动、同步和异步,下面分别简单介绍下每种方式使用的API:
- 手动加载:手动控制缓存的增删改处理,主动增加、获取以及依据函数式更新缓存;底层使用ConcurrentHashMap进行节点存储,因此get()方法是安全的。批量查找可以使用getAllPresent()方法或者带填充默认值的getAll()方法。
/** * 手动填充测试 */
public void cacheTest(String k) {
Cache<String, String> cache = Caffeine.newBuilder()
.maximumSize(100)
.expireAfterAccess(100L, TimeUnit.SECONDS)
.build();
cache.put("c1", "c1");
//获取缓存值,如果为空,返回null
log.info("cacheTest present: [{}] -> [{}]", k, cache.getIfPresent(k));
//获取返回值,如果为空,则运行后面表达式,存入该缓存
log.info("cacheTest default: [{}] -> [{}]", k, cache.get(k, this::buildLoader));
log.info("cacheTest present: [{}] -> [{}]", k, cache.getIfPresent(k));
//清除缓存
cache.invalidate(k);
log.info("cacheTest present: [{}] -> [{}]", k, cache.getIfPresent(k));
}
private String buildLoader(String k) {
return k + "+default";
}
- 同步加载:LoadingCache对象进行缓存的操作,使用CacheLoader进行缓存存储管理。批量查找可以使用getAll()方法。默认情况下,getAll()将会对缓存中没有值的key分别调用CacheLoader.load方法来构建缓存的值(build中的表达式)。我们可以重写CacheLoader.loadAll方法来提高getAll()的效率。
/** * 同步填充测试 */
public void loadingCacheTest(String k) {
//同步填充在build方法指定表达式
LoadingCache<String, String> loadingCache = Caffeine.newBuilder()
.maximumSize(100)
.expireAfterAccess(100L, TimeUnit.SECONDS)
.build(this::buildLoader);
loadingCache.put("c1", "c1");
log.info("loadingCacheTest get: [{}] -> [{}]", k, loadingCache.get(k));
//获取缓存值,如果为空,返回null
log.info("loadingCacheTest present: [{}] -> [{}]", k, loadingCache.getIfPresent(k));
//获取返回值,如果为空,则运行后面表达式,存入该缓存
log.info("loadingCacheTest default: [{}] -> [{}]", k, loadingCache.get(k, this::buildLoader));
log.info("loadingCacheTest present: [{}] -> [{}]", k, loadingCache.getIfPresent(k));
loadingCache.invalidate(k);
log.info("loadingCacheTest present: [{}] -> [{}]", k, loadingCache.getIfPresent(k));
}
private String buildLoader(String k) {
return k + "+default";
}
- 异步加载:
自动异步加载:
AsyncLoadingCache对象进行缓存管理,get()返回一个CompletableFuture对象,默认使用ForkJoinPool.commonPool()来执行异步线程,但是我们可以通过Caffeine.executor(Executor) 方法来替换线程池。
/** * 异步填充测试 */
public void asyncLoadingCacheTest(String k) throws ExecutionException, InterruptedException {
//异步加载使用Executor去调用方法并返回一个CompletableFuture。异步加载缓存使用了响应式编程模型。
//
//如果要以同步方式调用时,应提供CacheLoader。要以异步表示时,应该提供一个AsyncCacheLoader,并返回一个CompletableFuture。
AsyncLoadingCache<String, String> asyncLoadingCache = Caffeine.newBuilder()
.maximumSize(100)
.expireAfterAccess(100L, TimeUnit.SECONDS)
.buildAsync(s -> this.buildLoaderAsync("123").get());
log.info("asyncLoadingCacheTest get: [{}] -> [{}]", k, asyncLoadingCache.get(k).get());
//获取返回值,如果为空,则运行后面表达式,存入该缓存
log.info("asyncLoadingCacheTest default: [{}] -> [{}]", k, asyncLoadingCache.get(k, this::buildLoader).get());
}
private CompletableFuture<String> buildLoaderAsync(String k) {
return CompletableFuture.supplyAsync(() -> k + "+buildLoaderAsync");
}
手动异步加载:
/** * 手动异步测试 */
public void asyncManualCacheTest(String k) throws ExecutionException, InterruptedException {
//异步加载使用Executor去调用方法并返回一个CompletableFuture。异步加载缓存使用了响应式编程模型。
//
//如果要以同步方式调用时,应提供CacheLoader。要以异步表示时,应该提供一个AsyncCacheLoader,并返回一个CompletableFuture。
AsyncCache<String, String> asyncCache = Caffeine.newBuilder()
.maximumSize(100)
.expireAfterAccess(100L, TimeUnit.SECONDS)
.buildAsync();
//获取返回值,如果为空,则运行后面表达式,存入该缓存
log.info("asyncManualCacheTest default: [{}] -> [{}]", k, asyncCache.get(k, this::buildLoader).get());
}
过期策略
Caffeine的缓存清除是惰性的,可能发生在读请求后或者写请求后,比如说有一条数据过期后,不会立即删除,可能在下一次读/写操作后触发删除(类比于redis的惰性删除)。如果读请求和写请求比较少,但想要尽快的删掉cache中过期的数据的话,可以通过增加定时器的方法,定时执行cache.cleanUp()方法(异步方法,可以等待执行),触发缓存清除操作。
- 基于大小过期:当缓存超出后,使用W-TinyLFU算法进行缓存淘汰处理
- 基于缓存条目过期
maximumSize()方法,参数是缓存中存储的最大缓存条目,当添加缓存时达到条目阈值后,将进行缓存淘汰操作
/** * 淘汰策略-size */
public void sizeTest() {
LoadingCache<String, String> loadingCache = Caffeine.newBuilder()
.maximumSize(1)
.build(this::buildLoader);
List<String> list = Lists.newArrayList("c1", "c2", "c3");
loadingCache.put(list.get(0), list.get(0));
log.info("weightTest get: [{}] -> [{}]", list.get(0), loadingCache.get(list.get(0)));
loadingCache.put(list.get(1), list.get(1));
log.info("weightTest get: [{}] -> [{}]", list.get(1), loadingCache.get(list.get(1)));
loadingCache.put(list.get(2), list.get(2));
log.info("weightTest get: [{}] -> [{}]", list.get(2), loadingCache.get(list.get(2)));
log.info("weightTest cache map:{}", loadingCache.getAll(list));
}
- 基于权重过期:权重大小不会决定缓存满时清楚的优先级
weigher()方法可以指定缓存所占比重,maximumWeight()方法指定最大的权重阈值,当添加缓存超过规定权重后,进行数据淘汰
/** * 淘汰策略-weight */
public void weightTest() {
LoadingCache<String, String> loadingCache = Caffeine.newBuilder()
.maximumWeight(10)
.weigher((key, value) -> 5)
.build(this::buildLoader);
List<String> list = Lists.newArrayList("c1", "c2", "c3");
loadingCache.put(list.get(0), list.get(0));
log.info("weightTest get: [{}] -> [{}]", list.get(0), loadingCache.get(list.get(0)));
loadingCache.put(list.get(1), list.get(1));
log.info("weightTest get: [{}] -> [{}]", list.get(1), loadingCache.get(list.get(1)));
log.info("weightTest cache map:{}", loadingCache.getAll(list));
}
- 基于时间过期
- expireAfterAccess():缓存访问后,一定时间失效;即最后一次访问或者写入开始时计时。
- expireAfterWrite():缓存写入后,一定时间失效;以写入缓存操作为准计时。
- expireAfter():自定义缓存策略,满足多样化的过期时间要求。
/** * 淘汰策略-time */
public void timeTest() {
//1.缓存访问后,一定时间后失效
LoadingCache<String, String> loadingCacheOne = Caffeine.newBuilder()
.expireAfterAccess(10L, TimeUnit.SECONDS)
.build(this::buildLoader);
//2.缓存写入后,一定时间后失效
LoadingCache<String, String> loadingCacheTwo = Caffeine.newBuilder()
.expireAfterWrite(10L, TimeUnit.SECONDS)
.build(this::buildLoader);
//3.自定义过期策略
LoadingCache<String, String> loadingCacheThree = Caffeine.newBuilder()
.expireAfter(new Expiry<Object, Object>() {
@Override
public long expireAfterCreate(@NonNull Object o, @NonNull Object o2, long l) {
return 0;
}
@Override
public long expireAfterUpdate(@NonNull Object o, @NonNull Object o2, long l, @NonNegative long l1) {
return 0;
}
@Override
public long expireAfterRead(@NonNull Object o, @NonNull Object o2, long l, @NonNegative long l1) {
return 0;
}
})
.build(this::buildLoader);
}
- 基于引用过期
| 引用名称 | 垃圾回收时机 | 用途 | 生存周期 |
|---|---|---|---|
| 强引用(Strong Reference) | 不回收 | 正常普遍的类别 | JVM停止运行 |
| 软引用(soft Reference) | 内存不足回收 | 缓存对象 | 内存不足时 |
| 弱引用(weak Reference) | 下一次GC回收 | 缓存对象 | GC之后 |
| 虚引用(Phantom Reference) | 随时回收,引用虚设 | 通知功能 | 随时回收 |
| 下面展示了API使用方式: |
/** * 淘汰策略-引用 */
public void referenceTest() {
//1.弱引用弱key方式,没有强引用时,回收
LoadingCache<String, String> loadingCacheOne = Caffeine.newBuilder()
.weakKeys()
.weakValues()
.build(this::buildLoader);
//2.软值引用,内存不足的时候回收
LoadingCache<String, String> loadingCacheTwo = Caffeine.newBuilder()
.softValues()
.build(this::buildLoader);
}
- Caffeine.weakKeys():使用弱引用存储key,当没有其他的强引用时,则会被垃圾回收器回收;
- Caffeine.weakValues():使用弱引用存储value,当没有其他的强引用时,则会被垃圾回收器回收;
- Caffeine.softValues():使用软引用存储key,当没有其他的强引用时,内存不足的时候会被回收;
注:Weak or soft values can not be combined with AsyncCache
手动删除
Caffeine中提供了手动进行缓存的删除,无需等待我们上面提到的被动的一些删除策略,使用方法如下:
cacheOne.invalidateAll();
cacheOne.invalidate(Object o);
cacheOne.invalidateAll(List);
事件监听
移除事件RemovalListener是一种缓存监听事件,当key被移除的时候就会触发这个方法,可以进行一些相关联的操作。RemovalListener可以获取到key、value和RemovalCause(删除的原因)。另外RemovalListener中操作是线程池异步执行的。
/** * 移除监听器 */
public void removeTest() throws InterruptedException {
Cache<String, String> cacheOne = Caffeine.newBuilder()
.maximumSize(1)
.removalListener(
(o, o2, removalCause) ->
System.out.println(o + " is " + "remove" + " reason is " + removalCause.name()))
.build();
}
外部存储
CacheWriter是实现Caffeine cache的实现外部资源操作的一种方式,所有缓存的读写可以通过CacheWriter进行传递,比如我们可以通过CacheWriter的实现方法进行第三方外部资源的操作。一方面这个组件可以代替上面提到的RemovalListener移除事件监听,不同之处在于这个是同步执行的,且是一个原子操作,写入缓存完成之前会阻塞后续更新缓存的操作,但是读缓存不会阻塞;另一方面,可以当作是维持和外部资源的一个纽带,进行外部资源关联使用。
/** * writer */
public void writerTest() {
Cache<String, String> cacheOne = Caffeine.newBuilder()
.maximumSize(1)
.writer(new CacheWriter<Object, Object>() {
@Override
public void write(@NonNull Object o, @NonNull Object o2) {
System.out.printf("key: %s is write , value: %s", o, o2);
}
@Override
public void delete(@NonNull Object o, @Nullable Object o2, @NonNull RemovalCause removalCause) {
System.out.printf("key: %s is delete , value: %s , reason is %s", o, o2, removalCause.name());
}
})
.build();
cacheOne.put("k1", "v1");
System.out.printf("key: %s , value: %s", "k1", cacheOne.getIfPresent("k1"));
cacheOne.put("k2", "v2");
System.out.printf("key: %s , value: %s", "k1", cacheOne.getAllPresent(Lists.newArrayList("k1", "k2")));
}
Springboot集成
spring从3的版本开始支持Cache的处理,使用方式也是按照传统方向提供两种,基于注解和基于xml配置文件的方式,其操作纬度为方法或类,比如将注解@Cacheable按要求配置到一个方法上,会构造出一个k-v的缓存信息,k是入参相关,value就是方法的返回值,当请求到这个方法上,先去缓存获取,有则直接返回,无则执行流程然后返回且存入缓存。还有一些其他的注解,例如:@CachePut、@CacheEvict等。
Springboot中的spring cache是可以直接整合Caffeine cache的,配置的步骤大概就是:
- 声明spring对cache的支持
- 方法配置缓存使用
注解方式
yml文件配置:
spring:
cache:
type: caffeine
cache-names:
- caffeineTestOne
- caffeineTestTwo
caffeine:
spec: maximumSize=500
在启动类加注解:@EnableCaching,表示开始缓存功能
@EnableCaching
@EnableOpenApi
@SpringBootApplication
@ComponentScan(basePackages = "com.ldy")
public class DemoApplication {
public static void main(String[] args) {
SpringApplication.run(DemoApplication.class, args);
}
}
在想要缓存的方法和参数上使用注解:@Cacheable(value = “caffeineTestOne”)(value指定了caffeine)
@Cacheable(value = "caffeineTestOne")
public String getKey(String key) {
log.info("本次从逻辑获取 key=[{}]", key);
return key;
}
执行第一次显示日志,表示从逻辑中获取,后面的同参数请求就没日志打印了,表示走的是Caffeine缓存。
配置文件的方式比较死板,这里不做演示,感兴趣的可以自己在本地尝试下。
三、参考文档
[1]:源码 github.com/ben-manes
[2]:https://tech.meituan.com/2017/03/17/cache-about.html
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/226764.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...