大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
记一次SparkSql ETL 过程
需求说明
1)input:json日志
2)ETL:根据IP解析出 省份,城市
3)stat: 地区分布指标计算,
满足条件的才算,满足条件的赋值为1,不满足的赋值为0 (如下图)
将统计结果写入MySQL中。
(就比如说这个广告请求要满足 requestmode=1 和 processnode =3 这两个条件)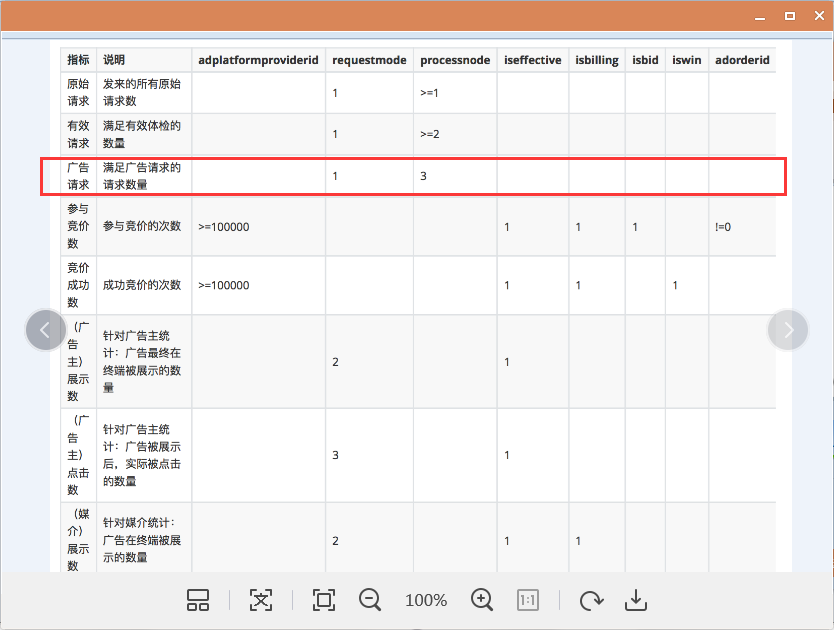

代码分析
val spark = SparkSession.builder().master("local[2]").appName("LogApp").getOrCreate()
import spark.implicits._
val inputDF = spark.read.json("inputdata/data-test.json")
inputDF.printSchema()
// ETL: 一定保留原有的数据 最完整 而且要落地 (理由:要是数据出错好重新计算)
val newDF = inputDF.withColumn("province", MyUDF.getProvince(inputDF.col("ip")))
.withColumn("city", MyUDF.getCity($"ip"))//自定义udf 函数
.write.format("parquet")
.mode(SaveMode.Overwrite)
.save("outparquet") // 最好保存parquet格式 (spark默认就是parquet + snappy)
// 计算 重新去读取etl之后的数据源
val parquetDF = spark.read.parquet("outparquet/xxx.snappy.parquet")
parquetDF.printSchema()
parquetDF.show(5)
parquetDF.createOrReplaceTempView("log")
//业务SQL
val areaSQL01 = "select province,city, " +
"sum(case when requestmode=1 and processnode >=1 then 1 else 0 end) origin_request," +
"sum(case when requestmode=1 and processnode >=2 then 1 else 0 end) valid_request," +
"sum(case when requestmode=1 and processnode =3 then 1 else 0 end) ad_request," +
"sum(case when adplatformproviderid>=100000 and iseffective=1 and isbilling=1 and isbid=1 and adorderid!=0 then 1 else 0 end) bid_cnt," +
"sum(case when adplatformproviderid>=100000 and iseffective=1 and isbilling=1 and iswin=1 then 1 else 0 end) bid_success_cnt," +
"sum(case when requestmode=2 and iseffective=1 then 1 else 0 end) ad_display_cnt," +
"sum(case when requestmode=3 and processnode=1 then 1 else 0 end) ad_click_cnt," +
"sum(case when requestmode=2 and iseffective=1 and isbilling=1 then 1 else 0 end) medium_display_cnt," +
"sum(case when requestmode=3 and iseffective=1 and isbilling=1 then 1 else 0 end) medium_click_cnt," +
"sum(case when adplatformproviderid>=100000 and iseffective=1 and isbilling=1 and iswin=1 and adorderid>20000 then 1*winprice/1000 else 0 end) ad_consumption," +
"sum(case when adplatformproviderid>=100000 and iseffective=1 and isbilling=1 and iswin=1 and adorderid>20000 then 1*adpayment/1000 else 0 end) ad_cost " +
"from log group by province,city"
spark.sql(areaSQL01).createOrReplaceTempView("area_tmp")
val areaSQL02 = "select province,city, " +
"origin_request," +
"valid_request," +
"ad_request," +
"bid_cnt," +
"bid_success_cnt," +
"bid_success_cnt/bid_cnt bid_success_rate," +
"ad_display_cnt," +
"ad_click_cnt," +
"ad_click_cnt/ad_display_cnt ad_click_rate," +
"ad_consumption," +
"ad_cost from area_tmp " +
"where bid_cnt!=0 and ad_display_cnt!=0"
// 写入MySQL (上一篇博客有介绍)
val config = ConfigFactory.load()
val url = config.getString("db.default.url")
val user = config.getString("db.default.user")
val password = config.getString("db.default.password")
spark.sql(areaSQL02)
.write.format("jdbc")
.option("url", url)
.option("dbtable", "sparksql_test")
.option("user", user)
.option("password", password)
.mode(SaveMode.Overwrite)
.save()
spark.stop()
自定义udf 函数代码
object MyUDF {
import org.apache.spark.sql.functions._
def getProvince = udf((ip:String)=>{
val cityInfo = IPUtil.getCityInfo(ip)
val splits = cityInfo.split("\\|")
var city = "未知"
if (splits.length == 5){
city = splits(2)
}
city
})
def getCity = udf((ip:String)=>{
val cityInfo = IPUtil.getCityInfo(ip)
val splits = cityInfo.split("\\|")
var city = "未知"
if (splits.length == 5){
city = splits(3)
}
city
})
}
调优
① ETL 落地过程中应该调用coalesce() 防止产生多个小文件
val newDF = inputDF.withColumn("province", MyUDF.getProvince(inputDF.col("ip")))
.withColumn("city", MyUDF.getCity($"ip"))
.coalesce(1)
.write.format("parquet").mode(SaveMode.Overwrite).save("outparquet")
② spark.conf.set(“spark.sql.shuffle.partitions”,“400”) 修改SparkSql shuffle task数量,默认是200

总结
ETL过程:
input:json
清洗 ==> ODS 大宽表 HDFS/Hive/SparkSQL
output: 列式存储 ORC/Parquet (列式存储) (为啥要用这两种? 因为ETL清洗出来的是全字段,我们不可能使用到全部字段,所以采用列式存储,用到几列就获取几列,这样就能减少I/O,性能大大提升)
Stat
==> 一个非常简单的SQL搞定
==> 复杂:多个SQL 或者 一个复杂SQL搞定
列式:ORC/Parquet
特点:把每一列的数据存放在一起
优点:减少IO 需要哪几列就直接获取哪几列
缺点:如果你还是要获取每一行中的所有列,那么性能比行式的差
行式:MySQL
一条记录有多个列 一行数据是存储在一起的
优点:
你每次查询都使用到所有的列
缺点:
大宽表有N多列,但是我们仅仅使用其中几列
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/223422.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
