大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
1.Dubbo原理分析
这个框架/工具/产品在实现的时候,都考虑到了容灾,扩展,负载均衡,于是出现一个配置中心(ConfigServer)的东西来解决这些问题。
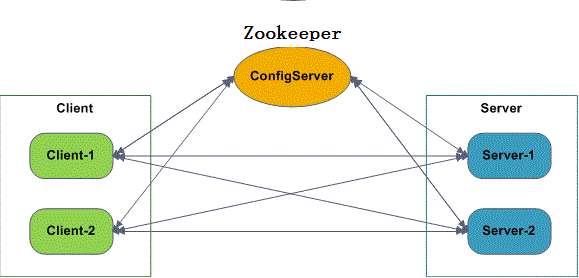

原理如下:
- ConfigServer
配置中心,
和每个Server/Client之间会作一个实时的心跳检测(
因为它们都是
建立的Socket长连接
)
,比如几秒钟检测一次。
收集每个Server提供的服务的信息,每个Client的信息,整理出一个服务列表,如:
| serviceName | serverAddressList | clientAddressList |
| UserService | 192.168.0.1,192.168.0.2,192.168.0.3,192.168.0.4 | 172.16.0.1,172.16.0.2 |
| ProductService | 192.168.0.3,192.168.0.4,192.168.0.5,192.168.0.6 | 172.16.0.2,172.16.0.3 |
| OrderService | 192.168.0.10,192.168.0.12,192.168.0.5,192.168.0.6 | 172.16.0.3,172.16.0.4 |
Server不可用,那么就
更新受影响的服务对应的
serverAddressList,即把这个Server从serverAddressList中踢出去
(从地址列表中删除)
,同时将
推送
serverAddressList
给这些受影响的服务的
clientAddressList里面的所有Client
。如:192.168.0.3挂了,那么UserService和ProductService的serverAddressList都要把192.168.0.3删除掉,同时把新的列表告诉对应的Client
172.16.0.1,172.16.0.2,
172.16.0.3
;
某
个Client挂了,那么
更新受影响的服务对应的clientAddressList
新加一个Server时,只需要启动Server,然后几秒钟内,Client就会使用上它提供的服务
- Client
调用服务的机器,每个Client启动时,主动与ConfigServer建立Socket长连接,并将自己的IP等相应信息发送给ConfigServer。
当前
哪几个Client在使用),Client拿到这些服务提供者信息后,与它们都建立连接,后面就可以直接调用服务了,当有多个服务提供者的时候,Client根据一定的规则来进行负载均衡,如轮询,随机,按权重等。
- Server
真正提供服务的机器,每个Server启动
时
,主动与ConfigServer建立Scoket长连接,并将自己的IP,提供的服务名称,端口等信息直接发送给ConfigServer,ConfigServer就会收集到每个Server提供的服务的信息。
ConfigServer挂了,那只影响
ConfigServer挂了以后服务提供者有变化,而Client还无法感知这一变化。
负载均衡:
Client调用服务时,可以根据规则在多个服务提供者之间轮流调用服务。
服务提供者-
容灾:某一个Server挂了,Client依然是可以正确的调用服务的,当前提是这个服务有至少2个服务提供者,Client能很快的感知到服务提供者的变化,并作出相应反应。
2.Zookeeper实现服务注册与发现
zookeeper的实际运用场景:
场景一:统一命名服务
有一组服务器向客户端提供某种服务,我们希望客户端每次请求服务端都可以找到服务端集群中某一台服务器,这样服务端就可以向客户端提供客户端所需的服务。对于这种场景,我们的程序中一定有一份这组服务器的列表,每次客户端请求时候,都是从这份列表里读取这份服务器列表。那么这份列表显然不能存储在一台单节点的服务器上,否则这个节点挂掉了,整个集群都会发生故障,我们希望这份列表时高可用的。
高可用的解决方案是:这份列表是分布式存储的,它是由存储这份列表的服务器共同管理的,如果存储列表里的某台服务器坏掉了,其他服务器马上可以替代坏掉的服务器,并且可以把坏掉的服务器从列表里删除掉,让故障服务器退出整个集群的运行,而这一切的操作又不会由故障的服务器来操作,而是集群里正常的服务器来完成。这是一种主动的分布式数据结构,能够在外部情况发生变化时候主动修改数据项状态的数据机构。Zookeeper框架提供了这种服务。这种服务名字就是:统一命名服务,它和JavaEE里的JNDI服务很像。
场景二:分布式锁服务
当分布式系统操作数据,例如:读取数据、分析数据、最后修改数据。在分布式系统里这些操作可能会分散到集群里不同的节点上,那么这时候就存在数据操作过程中一致性的问题,如果不一致,我们将会得到一个错误的运算结果,在单一进程的程序里,一致性的问题很好解决,但是到了分布式系统就比较困难,因为分布式系统里不同服务器的运算都是在独立的进程里,运算的中间结果和过程还要通过网络进行传递,那么想做到数据操作一致性要困难的多。Zookeeper提供了一个锁服务解决了这样的问题,能让我们在做分布式数据运算时候,保证数据操作的一致性。
场景三:配置管理
在分布式系统里,我们会把一个服务应用分别部署到n台服务器上,这些服务器的配置文件是相同的(例如:我设计的分布式网站框架里,服务端就有4台服务器,4台服务器上的程序都是一样,配置文件都是一样),如果配置文件的配置选项发生变化,那么我们就得一个个去改这些配置文件,如果我们需要改的服务器比较少,这些操作还不是太麻烦,如果我们分布式的服务器特别多,比如某些大型互联网公司的hadoop集群有数千台服务器,那么更改配置选项就是一件麻烦而且危险的事情。
这时候zookeeper就可以派上用场了,我们可以把zookeeper当成一个高可用的配置存储器,把这样的事情交给zookeeper进行管理,我们将集群的配置文件拷贝到zookeeper的文件系统的某个节点上,然后用zookeeper监控所有分布式系统里配置文件的状态,一旦发现有配置文件发生了变化,每台服务器都会收到zookeeper的通知,让每台服务器同步zookeeper里的配置文件,zookeeper服务也会保证同步操作原子性,确保每个服务器的配置文件都能被正确的更新。
场景四:为分布式系统提供故障修复的功能
集群管理是很困难的,在分布式系统里加入了zookeeper服务,能让我们很容易的对集群进行管理。集群管理最麻烦的事情就是节点故障管理,zookeeper可以让集群选出一个健康的节点作为master,master节点会知道当前集群的每台服务器的运行状况,一旦某个节点发生故障,master会把这个情况通知给集群其他服务器,从而重新分配不同节点的计算任务。Zookeeper不仅可以发现故障,也会对有故障的服务器进行甄别,看故障服务器是什么样的故障,如果该故障可以修复,zookeeper可以自动修复或者告诉系统管理员错误的原因让管理员迅速定位问题,修复节点的故障。大家也许还会有个疑问,master故障了,那怎么办了?zookeeper也考虑到了这点,zookeeper内部有一个“选举领导者的算法”,master可以动态选择,当master故障时候,zookeeper能马上选出新的master对集群进行管理。
下面我要讲讲zookeeper的特点:
zookeeper是一个精简的文件系统。zookeeper这个文件系统是管理小文件的。
zookeeper提供了丰富的“构件”,这些构件可以实现很多协调数据结构和协议的操作。例如:分布式队列、分布式锁以及一组同级节点的“领导者选举”算法。
zookeeper是高可用的,它本身的稳定性是相当之好,分布式集群完全可以依赖zookeeper集群的管理,利用zookeeper避免分布式系统的单点故障的问题。
zookeeper采用了松耦合的交互模式。这点在zookeeper提供分布式锁上表现最为明显,zookeeper可以被用作一个约会机制,让参入的进程不在了解其他进程的(或网络)的情况下能够彼此发现并进行交互,参入的各方甚至不必同时存在,只要在zookeeper留下一条消息,在该进程结束后,另外一个进程还可以读取这条信息,从而解耦了各个节点之间的关系。
zookeeper为集群提供了一个共享存储库,集群可以从这里集中读写共享的信息,避免了每个节点的共享操作编程,减轻了分布式系统的开发难度。
zookeeper的设计采用的是观察者的设计模式,zookeeper主要是负责存储和管理大家关心的数据,然后接受观察者的注册,一旦这些数据的状态发生变化,Zookeeper 就将负责通知已经在 Zookeeper 上注册的那些观察者做出相应的反应,从而实现集群中类似 Master/Slave 管理模式。
由此可见zookeeper很利于分布式系统开发,它能让分布式系统更加健壮和高效。
前不久我参加了部门的hadoop兴趣小组,测试环境的hadoop、mapreduce、hive及hbase都是我来安装的,安装hbase时候安装要预先安装zookeeper,最早我是在四台服务器上都安装了zookeeper,但是同事说安装四台和安装三台是一回事,这是因为zookeeper要求半数以上的机器可用,zookeeper才能提供服务,所以3台的半数以上就是2台了,4台的半数以上也是两台,因此装了三台服务器完全可以达到4台服务器的效果,这个问题说明zookeeper进行安装的时候通常选择奇数台服务器。在学习hadoop的过程中,我感觉zookeeper是最难理解的一个子项目,原因倒不是它技术负责,而是它的应用方向很让我困惑,所以从zookeeper开始,也不讲具体技术实现,而从zookeeper的应用场景讲起,理解了zookeeper应用的领域,我想再学习zookeeper就会更加事半功倍。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/223420.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
