大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
引用:
<<自然语言处理入门>>
一、简介
clustering
,也称文档聚类或
document
clustering
)指的是对文档进行的聚类分
析,被广泛用于文本挖掘和信息检索领域。
最初文本聚类仅用于文本归档,后来人
们又挖掘
出了许多新用途,比如改善搜索结果、生成同义词,等等。
量有
代表性的文档作为样本
假设需要标注
则可以将这些生语料聚类为
个簇,
每个簇随机选取一篇即可。
利用每个簇内元素都是相似的这个性质,聚类甚至可以用于文本去重。
聚类的对象是抽象的向
量(一维数
据点)
如果能将文档表示为向量
,就可以对其应用聚类算法
这种表示过程称为特征提取,而
一旦
将文档表示为向量,剩下的算法就与文档无关
二、文本特征
1. 词袋模型
词袋模型( bag-of-words )是信息检索与自然语言处理中最常用的文档表示模型,它将文档想象
文档一:
人吃鱼, 美味好吃!
对这个文档进行分词和停用词过滤:
(停用词: ‘的’,’了’ 这类没有实际意义的词, 网上搜一搜中文停用词有很多)
人 吃 鱼 美味 好 吃
那么这个文档有6个共计5种词语, 可以得到一个词袋模型;
词袋模型一:
人
吃
鱼
美味
好
这些词语就是词袋模型的词表, 除了词表, 还有统计指标, 现在选用词频作为词袋模型一中的统计指标, 那么文档一用这个词袋模型表示如下:
(词袋模型还有其他的统计指标,下面再介绍)
文档一用词袋模型一表示:
人=1
吃=2
鱼=1
美味=1
好=1
再直接用词袋向量表示文档一:
[1,2,1,1,1]
个维度分别表示词袋模型的词表中的5个词语,顺序也是一 一对应的
文档二:人吃大鱼文档二分词:
人 吃 大 鱼文档二用词袋模型一表示:
人=1
吃=1
鱼=1美味=0好=0直接用词袋向量表示:
[1, 1, 1, 0, 0]
OOV,
不予考虑
也正因为这个原因
,词袋
模型损失了词序中蕴含的语义。
比如,对于词袋模型来讲,”人吃
“和”鱼吃人
“的词袋
是一样的。
2.词袋的统计指标
:词
频非零的话截取为1
,否则为0
): 基础公式= 文档中的词频/ 有该词出现的文档数
):
词语本身
是某
种向
量,
则可以将所有词语
的词向量
求和作为文档向量
gensim是一个nlp的特征提取框架,里面也有词袋模型的入门介绍,写的通俗易懂,有很多例子,可以对照着看:
三、聚类算法
一些聚类算法介绍和原理:
常用聚类算法综述 – 知乎
数据科学家必须了解的六大聚类算法:带你发现数据之美 | 机器之心下面的介绍也引用了
对于有标签的数据,我们进行有监督学习,常见的分类任务就是监督学习;而对于无标签的数据,我们希望发现无标签的数据中的潜在信息,这就是无监督学习。聚类,就是无监督学习的一种,它的概念是:将相似的对象归到同一个簇中,使得同一个簇内的数据对象的相似性尽可能大,同时不在同一个簇中的数据对象的差异性也尽可能地大。即聚类后同一类的数据尽可能聚集到一起,不同数据尽量分离。
1. 聚类算法的分类
聚类算法有很多种分法,体系也很大,这里举例几种分法:
基于划分的聚类:聚类目标是使得类内的点足够近,类间的点足够远,常见的如k-means及其衍生算法
基于密度的聚类:当邻近区域的密度超过某个阈值,则继续聚类,如DBSCAN; OPTICS
层次聚类:这个下面会具体介绍到,包括合并的层次聚类,分裂的层次聚类,实际上可以看作是二叉树的生成和分裂过程。下面会介绍实际应用中常用的HDBSCAN
基于图的聚类: 通过建图来进行聚类,这是聚类算法中的大头,很多较新的聚类算法都有图聚类的思想。这篇文章会介绍以Chinese Whisper,谱聚类两大具有代表性的图聚类算法
基于GCN(图神经网络)的聚类:实际上这个本质上也是基于图的聚类,然而基于GCN的聚类算法会有深度学习中的训练的概念,而传统的聚类算法则是通过人工设定阈值来决定的,所以这里也分开列了一类, 这篇文章会介绍《Learning to Cluster Faces on Affinity Graph》、CDP两篇论文的思想
2.算法原理
这里就介绍我用过的比较典型的两个聚类算法:
基于划分的k-means算法;
基于密度的DBSCAN算法;
K-Means
这个可以说是最基础的聚类算法了,它的输入需要簇的个数k,这个k是用户指定的,也就是说需要提前确定类别,其算法流程是:
-
首先,我们选择一些类/组,并随机初始化它们各自的中心点。为了算出要使用的类的数量,最好快速查看一下数据,并尝试识别不同的组。中心点是与每个数据点向量长度相同的位置。
-
通过计算数据点与每个组中心之间的距离来对每个点进行分类,然后将该点归类于组中心与其最接近的组中。
-
根据这些分类点,我们利用组中所有向量的均值来重新计算组中心。
-
重复这些步骤来进行一定数量的迭代,或者直到组中心在每次迭代后的变化不大。你也可以选择随机初始化组中心几次,然后选择看起来提供了最佳结果的运行。
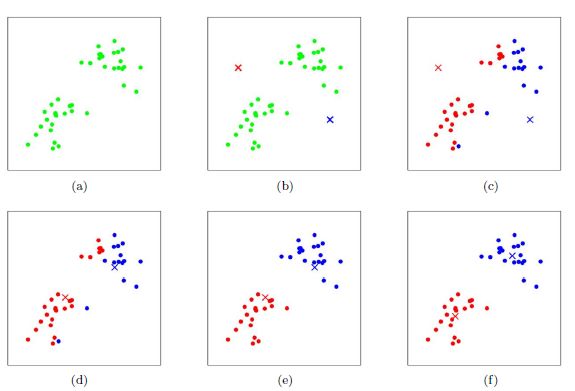

优点:
速度快
缺点:
首先,你必须选择有多少组/类。这并不总是仔细的,并且理想情况下,我们希望聚类算法能够帮我们解决分多少类的问题,因为它的目的是从数据中获得一些见解。K-means 也从随机选择的聚类中心开始,所以它可能在不同的算法中产生不同的聚类结果。因此,结果可能不可重复并缺乏一致性。其他聚类方法更加一致。
DBSCAN
基于密度的算法,要求聚类空间的一定区域所包含的对象的数目不小于某一给定阈值,先了解一些基本概念:
(1)Eps邻域:给定对象半径Eps内的邻域称为该对象的Eps邻域;
(2)核心对象(core point):如果对象的Eps邻域至少包含最小数目MinPts的对象,则称该对象为核心对象;
(3)直接密度可达(directly density-reachable):若某点p在点的q的Eps领域内,且q是一个核心对象,则p-q直接密度可达
(4)密度可达(density-reachable):如果存在一个对象链 p1, …,pi,.., pn,如果对于任意pi, pi-1都是直接密度可达的,则称pi到pi-1密度可达,实际上是直接密度可达的传播链
(5)密度相连(density-connected):如果从某个核心对象p出发,点q和点k都是密度可达的,则称点q和k是密度相连的。
(6)边界点(edge point):边界点不是核心对象,但落在某个核心对象的邻域内;
(7)噪音点(outlier point):既不是核心点,也不是边界点的任何点;
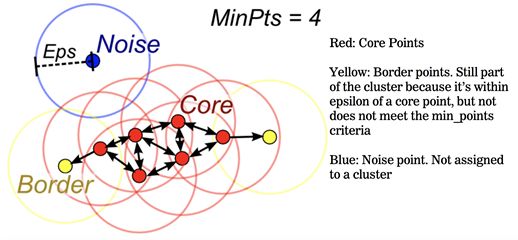
看看上图,红色点是所谓的核心对象,以它为圆心,Eps为半径去画圆,在圆内样本点数目大于MinPts的就是核心对象;被包含在核心对象的范围内,但是自身不是核心对象的点是样本点;即不被包含在核心对象内,自身也不是核心对象的点为噪音点,将被抛弃。
DBSCAN的核心思想是从某个核心点出发,不断向密度可达的区域扩张,从而得到一个包含核心点和边界点的最大化区域,区域中任意两点密度相连。
优点:
- 不需要指定簇的数目(不需要 k)
- 可以发现任意形状的聚类簇
- 对噪声不敏感
缺点:
- 需要设置半径Eps和MinPts, 空间聚类密度不均匀时难以设置参数,所以有一个问题就是,在数据集A上挑好的参数很可能到数据集B上就不能用了
- 随着数据量的增大,计算量显著增大,反正大规模数据集用DBSCAN很可能会崩的
两种算法适合的数据分布情况
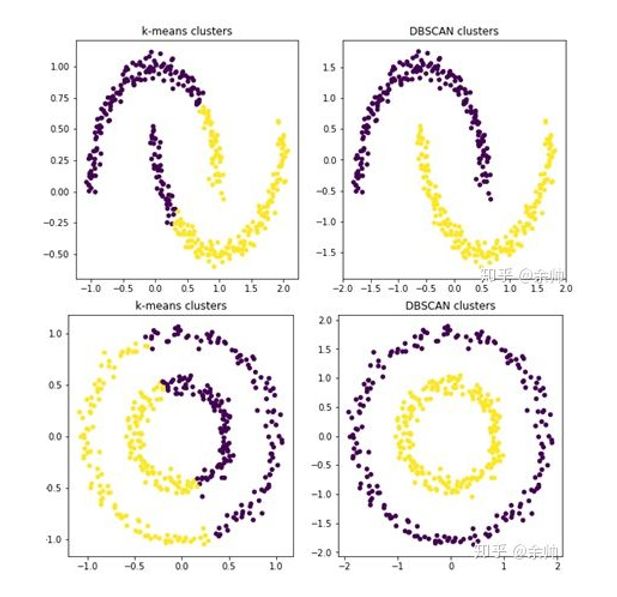
从这张图可以明显的看出,当数据分布不同时,适合的算法也不同,所以在选择算法前可以先把数据点打印出来看看分布情况。
在机器学习库scikit-learn中有多种聚类算法,也有各算法在不同的数据分布下呈现的聚类效果:
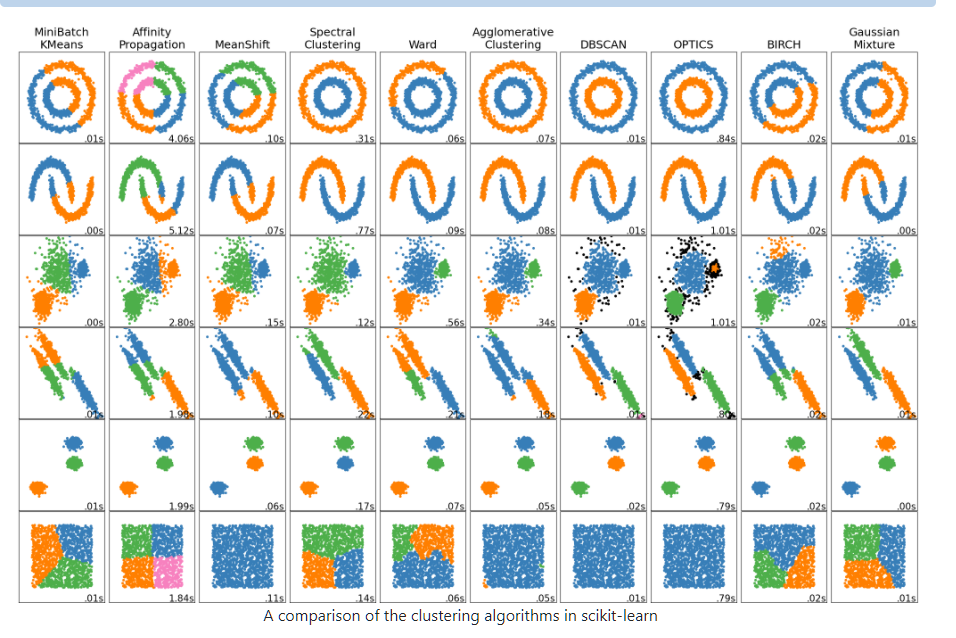
2.3. Clustering — scikit-learn 1.0.2 documentation
四、聚类实现
语言: python
分词:百度 Lac
特征提取、聚类算法: scikit-learn 库
(特征提取也可以用 gensim库)
简单实现
from LAC import LAC
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.cluster import KMeans
from sklearn.decomposition import PCA
# 1.加载数据
text_list = [
'很棒的一款男士香水,淡淡的香味很清爽,使用后感觉整个人心情都变好了!感谢老板送的香水小样,以后还会光顾的,很满意的一次购物!物流速度也很快,值得购买! ',
'回购很多次了,依旧品质如一,和风雨值得信赖,真的好用,包装也精美,很适合送礼,性价比很高!喜欢香水的朋友值得购买!支持店家!',
'节日礼物:很喜欢,还送了四瓶小的,之前买的固体香膏,都是木质的,香味不冲,作为给自己的礼物很理想\n留香时间:蛮持久的,合适',
'节日礼物:520送老公的礼物\n味道浓淡:了一段时间, 这款香味比较淡,淡淡的清香,不刺鼻,很好闻\n留香时间:持久留香,一天基本上都会有淡淡的清香,喜欢的朋友的朋友抓紧入手了 ',
'香水收到了 真的太棒了 包装也很高档 主要是味道太喜欢了 而且留香时间特别长 还有赠品 太给力了 ',
'香水很好,香味很喜欢,包装很好,有手提袋,送朋友也是不错的选择。买的气质灰,很不错的一次购物。 ',
'非常满意的一次购物,香水味道闻起来非常舒服,不刺鼻,和风雨正品,相信京东自营产品,用完之后还会来的,店家服务态度很好,么么哒 ',
'大品牌值得信赖!和风雨男士香水礼盒套装!100ml 大瓶装更划算!海洋靛淡香清新自然好闻!适合大众男士!留香时间比较久!味道淡淡的!适合各种场合!京东平台值得放心!满意的一次购物!值得推荐购买!物美价廉!点赞!!',
'眼就看这款式了 ,拿着好看 ?,刚开始是冲着这款香水颜值来的,本来还会担心味道刺鼻不好闻,没想到味道是我喜欢的淡淡的,?香味很好闻不刺鼻,闻着让人很放松,适合我们男士用,留香时间也很好,时间长了也可以闻到的,挺好。',
'已经收到了,满满一大瓶子,估计可以用很久了。惊喜是没想到外包装盒子的质感那么好!!!绝对好评,瓶子也非常好看,拿起来特别有质感。稍微喷了一下,问起来有水果的味道,不会刺鼻,而是很清新的味道,像是在果园里一样,很喜欢的味道,暂时不知道留香时间,等明天白天试用一下,再来评价吧。'
]
# 2.加载停用词
stopword_path = "./data/stop_words.txt"
with open(stopword_path, 'r', encoding='utf-8') as f:
stop_words= [line.strip() for line in f]
print("停用词:\n")
for i in range(len(stop_words)):
if i%200 == 0:
print(stop_words[i])
# 3.分词
lac = LAC(mode='lac')
corpus = []
for text in text_list :
line = text.strip()
lac_result = lac.run(line)
corpus.append(' '.join(lac_result[0]))
print(corpus)
# 4.特征提取
# 4.1 文本转换成词袋模型(词频作为统计指标) 加载停用词,添加词语进词袋时会过滤停用词
countVectorizer = CountVectorizer(stop_words=stop_words,analyzer="word")
count_v = countVectorizer.fit_transform(corpus)
# 词袋中的词语
print(countVectorizer.get_feature_names_out())
# 词频向量
print(count_v.toarray())
# 4.2 词频统计指标转换 tf-idf统计指标 (不是必须的,用哪种指标根据具体业务来看)
tfidfTransformer = TfidfTransformer()
tfidf = tfidfTransformer.fit_transform(count_v)
print(tfidf.toarray())
# 4.3 对词频向量进行降维 (不是必须的步骤, 因为下面使用 DBSCAN算法,它不适合太高维度计算所有进行降维)
# 主成分分析方法降维, 降成2维
pca = PCA(n_components=2)
pca_weights = pca.fit_transform(tfidf.toarray())
print(pca_weights )
# 5.聚类计算 (这里用dbscan算法)
clf = DBSCAN(eps=0.16, min_samples=2)
y = clf.fit_predict(pca_weights)
# 每个文本对应的簇的编号 (-1 在dbscan中属于噪音簇,里面都是噪音点)
print(y)
# 6.打印
result = {}
for text_idx, label_idx in enumerate(y):
key = "cluster_{}".format(label_idx)
if key not in result:
result[key] = [text_idx]
else:
result[key].append(text_idx)
for clu_k, clu_v in result.items():
print("\n","~"*170)
print(k)
print(v)
for i in v:
print(text_list[i], "\n===============================>")
停用词:
′
38
⑨
乘机
共总
呜
就是
按期
照
蛮
难怪
分词:
[‘很 棒 的 一款 男士 香水 , 淡淡的 香味 很 清爽 , 使用 后 感觉 整个 人心情 都 变 好 了 ! 感谢 老板 送 的 香水 小样 , 以后 还会 光顾 的 , 很满意 的 一次 购物 ! 物流 速度 也 很快 , 值得 购买 !’,
‘回购 很多次 了 , 依旧 品质 如 一 , 和 风雨 值得 信赖 , 真的 好 用 , 包装 也 精美 , 很 适合 送礼 , 性价比 很高 ! 喜欢 香水 的 朋友 值得 购买 ! 支持 店家 !’,
‘节日 礼物 : 很喜欢 , 还 送 了 四瓶 小 的 , 之前 买 的 固体 香膏 , 都是 木质 的 , 香味 不 冲 , 作为 给 自己 的 礼物 很 理想 \n留香 时间 : 蛮 持久 的 , 合适’,
…………
]
词表:
[‘100ml’ ‘520’ ‘一大’ ‘一款’ ‘一段时间’ ‘不知道’ ‘不错’ ‘么么’ ‘产品’ ‘京东’ ‘人心情’ ‘估计’ ‘依旧’
‘信赖’ ‘值得’ ‘光顾’ ‘入手’ ‘再来’ ‘冲着’ ‘划算’ ‘刺鼻’ ‘刺鼻不好闻’ ‘包装’ ‘合适’ ‘味道’ ‘品牌’ ‘品质’
‘喜欢’ ‘四瓶’ ‘回购’ ‘固体’ ‘场合’ ‘外包装’ ‘大众’ ‘大瓶装’ ‘套装’ ‘好看’ ‘好评’ ‘好闻’ ‘小样’ ‘平台’
‘店家’ ‘很不错’ ‘很久’ ‘很喜欢’ ‘很多次’ ‘很好’ ‘很好闻’ ‘很快’ ‘很满意’ ‘很高’ ‘性价比’ ‘惊喜’ ‘感觉’
‘感谢’ ‘我喜欢’ ‘手提袋’ ‘抓紧’ ‘担心’ ‘拿着’ ‘拿起来’ ‘持久’ ‘挺好’ ‘推荐’ ‘支持’ ‘收到’ ‘放心’ ‘放松’
‘时间’ ‘明天’ ‘暂时’ ‘朋友’ ‘服务态度’ ‘木质’ ‘本来’ ‘果园’ ‘正品’ ‘气质’ ‘水果’ ‘没想到’ ‘浓淡’ ‘海洋’
‘淡淡的’ ‘清新’ ‘清爽’ ‘清香’ ‘满意’ ‘满满’ ‘点赞’ ‘物流’ ‘物美价廉’ ‘特别’ ‘理想’ ‘瓶子’ ‘用完’ ‘男士’
‘留香’ ‘白天’ ‘盒子’ ‘真的’ ‘礼物’ ‘礼盒’ ‘稍微’ ‘精美’ ‘老公’ ‘老板’ ‘自然’ ‘自营’ ‘舒服’ ‘节日’
‘评价’ ‘试用’ ‘质感’ ‘购买’ ‘购物’ ‘赠品’ ‘还会’ ‘这款’ ‘这款式’ ‘送礼’ ‘适合’ ‘选择’ ‘速度’ ‘那么好’
‘都会’ ‘都是’ ‘问起来’ ‘闻到’ ‘靛淡香’ ‘颜值’ ‘风雨’ ‘香味’ ‘香水’ ‘香膏’ ‘高档’]
词频向量:
[[0 0 0 … 2 0 0]
[0 0 0 … 1 0 0]
[0 0 0 … 0 1 0]
…
[1 0 0 … 1 0 0]
[0 0 0 … 1 0 0]
[0 0 1 … 0 0 0]]
tf-idf向量:[[0. 0. 0. … 0.24081175 0. 0. ]
[0. 0. 0. … 0.11844613 0. 0. ]
[0. 0. 0. … 0. 0.27931155 0. ]
…
[0.17574509 0. 0. … 0.08566852 0. 0. ]
[0. 0. 0. … 0.1085617 0. 0. ]
[0. 0. 0.16490414 … 0. 0. 0. ]]
降维向量:
[[-0.35019103 -0.30756176]
[-0.43477489 -0.07872165]
[ 0.60278175 -0.40872156]
[ 0.51410352 -0.2923817 ]
[ 0.08085472 0.44735251]
[-0.02422909 -0.13374843]
[-0.28690644 0.03996021]
[-0.44522117 -0.11336332]
[ 0.11428046 0.1558558 ]
[ 0.22930217 0.69132989]]
每个文本对应的簇:
[-1 0 1 1 -1 -1 -1 0 -1 -1]
打印:
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
cluster_-1
[0, 4, 5, 6, 8, 9]
很棒的一款男士香水,淡淡的香味很清爽,使用后感觉整个人心情都变好了!感谢老板送的香水小样,以后还会光顾的,很满意的一次购物!物流速度也很快,值得购买!
===============================>
香水收到了 真的太棒了 包装也很高档 主要是味道太喜欢了 而且留香时间特别长 还有赠品 太给力了
===============================>
香水很好,香味很喜欢,包装很好,有手提袋,送朋友也是不错的选择。买的气质灰,很不错的一次购物。
===============================>
非常满意的一次购物,香水味道闻起来非常舒服,不刺鼻,和风雨正品,相信京东自营产品,用完之后还会来的,店家服务态度很好,么么哒
===============================>
眼就看这款式了 ,拿着好看 ?,刚开始是冲着这款香水颜值来的,本来还会担心味道刺鼻不好闻,没想到味道是我喜欢的淡淡的,?香味很好闻不刺鼻,闻着让人很放松,适合我们男士用,留香时间也很好,时间长了也可以闻到的,挺好。
===============================>
已经收到了,满满一大瓶子,估计可以用很久了。惊喜是没想到外包装盒子的质感那么好!!!绝对好评,瓶子也非常好看,拿起来特别有质感。稍微喷了一下,问起来有水果的味道,不会刺鼻,而是很清新的味道,像是在果园里一样,很喜欢的味道,暂时不知道留香时间,等明天白天试用一下,再来评价吧。
===============================>~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
cluster_0
[1, 7]
回购很多次了,依旧品质如一,和风雨值得信赖,真的好用,包装也精美,很适合送礼,性价比很高!喜欢香水的朋友值得购买!支持店家!
===============================>
大品牌值得信赖!和风雨男士香水礼盒套装!100ml 大瓶装更划算!海洋靛淡香清新自然好闻!适合大众男士!留香时间比较久!味道淡淡的!适合各种场合!京东平台值得放心!满意的一次购物!值得推荐购买!物美价廉!点赞!!
===============================>~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
cluster_1
[2, 3]
节日礼物:很喜欢,还送了四瓶小的,之前买的固体香膏,都是木质的,香味不冲,作为给自己的礼物很理想
留香时间:蛮持久的,合适
===============================>
节日礼物:520送老公的礼物
味道浓淡:了一段时间, 这款香味比较淡,淡淡的清香,不刺鼻,很好闻
留香时间:持久留香,一天基本上都会有淡淡的清香,喜欢的朋友的朋友抓紧入手了
===============================>
聚类效果自己调整dbscan的参数: eps=0.16, min_samples=2
工具类:
__init__.py:
import os
CURRENT_PATH = os.path.abspath(__file__)
PROJECT_PATH = os.path.dirname(os.path.dirname(os.path.dirname(CURRENT_PATH)))
STOPWORDS = os.path.join(PROJECT_PATH, "config", "stop_words.txt")
print(STOPWORDS)cluster.py:
class Cluster():
def __init__(self, documents, centroid=None):
self.documents = documents
self.centroid = centroid
def add_document(self, doc):
self.documents.append(doc)
def set_centroid(self, centroid):
self.centroid = centroid
def get_documents_id(self):
return [d.id for d in self.documents]
def __str__(self):
return str([d.id for d in self.documents])
document.py
class Document():
def __init__(self,id,feature_vector):
self.id = id
self.feature_vector = feature_vector
cluster_analyzer.py
from LAC import LAC
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.cluster import DBSCAN
from models.text_cluster import STOPWORDS
from sklearn.decomposition import PCA
from models.text_cluster.document import Document
from models.text_cluster.cluster import Cluster
class ClusterAnalyzer():
def __init__(self, stopwords_path=STOPWORDS):
self.stopwords = self._load_stopwords(stopwords_path)
self.lac = LAC(mode='lac')
self.tfidfVectorizer = TfidfVectorizer(stop_words=self.stopwords, analyzer="word")
self.pca = PCA(n_components=2)
def _load_stopwords(self, stopwords=None):
"""
加载停用词
:param stopwords:
:return:
"""
if stopwords:
with open(stopwords, 'r', encoding='utf-8') as f:
return [line.strip() for line in f]
else:
return []
def _preprocess_data(self, text_list):
# 1.1 文本分词
corpus = []
for text_tup in text_list:
line = text_tup[1].strip()
lac_result = self.lac.run(line)
words = lac_result[0]
corpus.append(' '.join(words))
# 1.2 文本向量化
tfidf = self.tfidfVectorizer.fit_transform(corpus)
weights = tfidf.toarray()
# 1.3 向量降维
pca_weights = self.pca.fit_transform(weights)
# 1.4 生成文档对象
doc_list = list(
map(lambda t: Document(t[0][0], t[1]),
list(zip(text_list, pca_weights))))
return doc_list
def dbscan(self, text_list, eps=0.16, min_samples=2):
'''
text_list [text,...] or [(text_id,text,),...]
'''
# 文档添加索引
if isinstance(text_list[0], str):
text_list = list(enumerate(text_list))
elif not isinstance(text_list[0], tuple):
raise
# 1. 文档对象转换
doc_list = self._preprocess_data(text_list)
# 2. 聚类
# 2.1 聚类计算
clf = DBSCAN(eps=eps, min_samples=min_samples)
y = clf.fit_predict([doc.feature_vector for doc in doc_list])
# 2.2 生成 簇对象
cluster_dict = {}
for text_idx, label_idx in enumerate(y):
key = label_idx
if key not in cluster_dict:
cluster_dict[key] = Cluster([doc_list[text_idx]])
else:
cluster_dict[key].add_document(doc_list[text_idx])
# 2.3 指定簇中心 dbscan没有簇中心
# centers = self.clf.cluster_centers_
# for i in centers:
# cluster_dict.get(i).set_centroid(centers[i])
# 3 返回数据
return self._to_result(cluster_dict)
def _to_result(self,cluster_dict):
result = {}
for k, cluster in cluster_dict.items():
key = "cluster_{}".format(k)
result[key] = cluster.get_documents_id()
return result
其他工具类
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/223415.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
