大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
networkx简介:
官方文档:https://www.osgeo.cn/networkx/reference/classes/graph.html#
networkx是Python的一个包,用于构建和操作复杂的图结构,提供分析图的算法。图是由顶点、边和可选的属性构成的数据结构,顶点表示数据,边是由两个顶点唯一确定的,表示两个顶点之间的关系。顶点和边也可以拥有更多的属性,以存储更多的信息。
对于networkx创建的无向图,允许一条边的两个顶点是相同的,即允许出现自循环,但是不允许两个顶点之间存在多条边,即出现平行边。边和顶点都可以有自定义的属性,属性称作边和顶点的数据,每一个属性都是一个Key:Value对。
networkx工具作用:
利用networkx可以以标准化和非标准化的数据格式存储网络、生成多种随机网络和经典网络、分析网络结构、建立网络模型、设计新的网络算法、进行网络绘制等
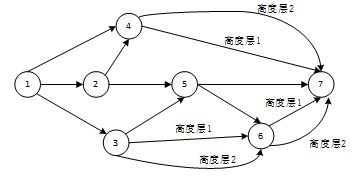

如上图:图是用点和线来刻画离散事物集合中的每对事物间以某种方式相联系的数学模型。网络作为图的一个重要领域,包含的概念与定义更多,如有向图网络(Directed Graphs and Networks)、无向图网络(Undirected ~)等概念
模块加载
pip install networkx
import networkx as nx
图分类
Graph:指无向图(undirected Graph),即忽略了两节点间边的方向。
DiGraph:指有向图(directed Graph),即考虑了边的有向性。
MultiGraph:指多重无向图,即两个结点之间的边数多于一条,又允许顶点通过同一条边和自己关联。
MultiDiGraph:多重图的有向版本。
创建图对象方式:
G = nx.Graph() # 创建无向图
G = nx.DiGraph() # 创建有向图
G = nx.MultiGraph() # 创建多重无向图
G = nx.MultiDigraph() # 创建多重有向图
在创建了相关对象后,并不会有图像出现。一是因为这只是一个空对象,并没有具体实际的数据(有点类似C#中类的概念);二是因为Networkx库设计的初衷也并非为了绘制网络图,创建了对象后不会自动绘制其图像,通常需要借助matplotlib库加以实现。下面举例说明图的生成过程。
图属性
G=nx.Graph(date="10.11",name="有向图")#创建空图,无向图
print(G.graph)
#结果:{'name': '有向图', 'date': '10.11'}
结点
图中每个结点都有一个ID属性,用于唯一标识一个结点,ID属性可以是整型或字符类型,除了ID属性外,还可以自定义其他属性。
1、增加结点:
g.add_node(1)
g.add_nodes_from([2,3,4])
g.nodes()
#NodeView((1, 2,3,4))
g.add_node(1,name='n1',weight=1)#增加结点,同时设置结点其他属性
2、查看结点属性
G=nx.Graph()#创建空图,无向图
G.add_node(1,weight=0.2,name="yy") #添加一条边,并设置边权重
G.add_nodes_from([2,3,4,5])
print(G._node) #通过_node查看结点属性
print(G.nodes()) #显示所有结点,不显示属性
print(G.nodes(data=True),type(G.nodes(data=True))) #返回整体data参数设置为true,那么返回的是NodeDataView对象
print(G.node[1]["weight"]) #根据结点ID,查看结点其他属性
print(list(G.nodes(data=True))) #以特定条件来查看结点属性(如果列表格式)
##结果:
{1: {'weight': 0.2, 'name': 'yy'}, 2: {}, 3: {}, 4: {}, 5: {}}
[1, 2, 3, 4, 5]
[(1, {'weight': 0.2, 'name': 'yy'}), (2, {}), (3, {}), (4, {}), (5, {})] <class 'networkx.classes.reportviews.NodeDataView'>
0.2
[(1, {'weight': 0.2, 'name': 'yy'}), (2, {}), (3, {}), (4, {}), (5, {})]
3、删除结点:
ID可以唯一标识一个结点,所以通过结点ID删除结点
G.remove_node(node_ID)
G.remove_nodes_from(nodes_list)
4、更新结点:
G.node[1].update({"name":"xx"})
print(G.nodes(data=True))
G.node[1]["name"]="hh"
print(G.nodes(data=True))
#结果:[(1, {'name': 'xx', 'weight': 0.2}), (2, {}), (3, {}), (4, {}), (5, {})]
[(1, {'name': 'hh', 'weight': 0.2}), (2, {}), (3, {}), (4, {}), (5, {})]
5、删除结点属性:
del G.node[1]["name"]
print(G.nodes(data=True))
#结果:
[(1, {'weight': 0.2}), (2, {}), (3, {}), (4, {}), (5, {})]
6、检查是否存在某个结点:
print(G.has_node(1))
#结果:
True
边
图的边用于表示两个结点之间的关系,因此,边是由两个顶点唯一确定的。为了表示复杂的关系,通常会为边增加一个权重weight属性;为了表示关系的类型,也会设置为边设置一个关系属性。
1、向图中增加边
边是由对应顶点的名称构成的,例如,顶点2和3之间有一条边,记作e=(2,3),通过add_edge(node1,node2)向图中添加一条边,也可以通过add_edges_from(list)向图中添加多条边;在添加边时,如果顶点不存在,那么networkx会自动把相应的顶点加入到图中。
g.add_edge(2,3)
g.add_edges_from([(1,2),(1,3)])
g.edges()
g.add_edge(1, 2, weight=4.7, relationship='renew') #向图中增加边,同时设置边得属性
##边的权重weight是非常有用和常用的属性,因此,networkx模块内置以一个函数,专门用于在添加边时设置边的权重,该函数的参数是三元组,前两个字段是顶点的ID属性,用于标识一个边,第三个字段是边的权重,如下:
g.add_weighted_edges_from([(1,2,0.125),(1,3,0.75),(2,4,1.2),(3,4,0.375)])
#在增加边时,也可以一次增加多条边,为不同的边设置不同的属性如下:
g.add_edges_from([(1,2,{'color':'blue'}), (2,3,{'weight':8})])
2、查看边得属性:
(1)查看所有边:
g.edges(data=True) #就是查看边的数据(data),查看所有边及其属性
(2)查看特定边得属性:两种方式
g[1][2]
g.get_edge_data(1,2)
3、删除边:
边是两个结点ID属性组成得元组标识,通过 edge=(node1,node2) 来标识边,进而从图中找到边:
g.remove_edge(edge)
g.remove_edges_from(edges_list)
4、更新边得属性:
通过边来更新边的属性,由两种方式,一种是使用update函数,一种是通过属性赋值来实现:
g[1][2]['weight'] = 4.7
g.edge[1][2]['weight'] = 4
g[1][2].update({"weight": 4.7})
g.edges[1, 2].update({"weight": 4.7})
5、删除边得属性:
通过 del命令来删除边的属性
del g[1][2]['name']
6、查看边是否存在
g.has_edge(1,2)
图属性
图的属性主要是指相邻数据,节点和边
1、adj
ajd返回的是一个AdjacencyView视图,该视图是结点的相邻的顶点和顶点的属性,用于显示用于存储与顶点相邻的顶点的数据,这是一个只读的字典结构,Key是结点,Value是结点的属性数据。
list1=[(1,2,{"name":"hh"}),(2,3,{"name":"xx"}),(1,4,{"name":"tt"}),(4,5,{"name":"yy"})]
G.add_edges_from(list1)
print(G.adj[1])
print(G.adj[1][2])
#结果:
{2: {'name': 'hh'}, 4: {'name': 'tt'}}
{'name': 'hh'}
2、edges
图的边是由边的两个顶点唯一确定的,边还有一定的属性,因此,边是由两个顶点和边的属性构成的:
list1=[(1,2,{"name":"hh"}),(2,3,{"name":"xx"}),(1,4,{"name":"tt"}),(4,5,{"name":"yy"})]
G.add_edges_from(list1)
print(G.edges()) #仅仅提供边的信息,可以通过属性g.edges或函数g.edges()来获得图的边视图。
print(G.edges.data()) #提供图的边和边的属性,可以通过EdgeView对象来调用data()函数获得
#结果:
[(1, 2), (1, 4), (2, 3), (4, 5)]
[(1, 2, {'name': 'hh'}), (1, 4, {'name': 'tt'}), (2, 3, {'name': 'xx'}), (4, 5, {'name': 'yy'})]
3、nodes
图的顶点是顶点和顶点的属性构成的
list1=[(1,2,{"name":"hh"}),(2,3,{"name":"xx"}),(1,4,{"name":"tt"}),(4,5,{"name":"yy"})]
G.add_edges_from(list1)
print(G.node,type(G.node))
print(G.nodes,type(G.nodes))
print(G.node.data)
print(G.nodes.data())
#结果:
[1, 2, 3, 4, 5] <class 'networkx.classes.reportviews.NodeView'>
[1, 2, 3, 4, 5] <class 'networkx.classes.reportviews.NodeView'>
<bound method NodeView.data of NodeView((1, 2, 3, 4, 5))>
[(1, {'name': 'yy', 'weight': 0.2}), (2, {}), (3, {}), (4, {}), (5, {})]
4、degree
对于无向图,顶点的度是指跟顶点相连的边的数量;对于有向图,顶点的图分为入度和出度,朝向顶点的边称作入度;背向顶点的边称作出度。
通过g.degree 或g.degree()能够获得DegreeView对象
print(G.degree,type(G.degree))
print(G.degree(),type(G.degree()))
#结果:[(1, 2), (2, 2), (3, 1), (4, 2), (5, 1)] <class 'networkx.classes.reportviews.DegreeView'>
[(1, 2), (2, 2), (3, 1), (4, 2), (5, 1)] <class 'networkx.classes.reportviews.DegreeView'>
图遍历
图的遍历是指按照图中各顶点之间的边,从图中的任一顶点出发,对图中的所有顶点访问一次且只访问一次。图的遍历按照优先顺序的不同,通常分为深度优先搜索(DFS)和广度优先搜索(BFS)两种方式。
#1、查看结点得相邻结点:
#返回顶点1的相邻顶点,g[n]表示图g中,与顶点n相邻的所有顶点
list1=[(1,2,{"name":"hh"}),(2,3,{"name":"xx"}),(1,4,{"name":"tt"}),(4,5,{"name":"yy"})]
G.add_edges_from(list1)
print(G[1])
print(G.adj[1])
print(G.neighbors(1))
for i in G.neighbors(1):
print("遍历后:",i,type(i))
#结果:
{2: {'name': 'hh'}, 4: {'name': 'tt'}}
{2: {'name': 'hh'}, 4: {'name': 'tt'}}
<dict_keyiterator object at 0x00000237C0DEBF48>
遍历后: 2 <class 'int'>
遍历后: 4 <class 'int'>
2、查看结点以及结点得相邻结点所有信息:
list1=[(1,2,{"name":"hh"}),(2,3,{"name":"xx"}),(1,4,{"name":"tt"}),(4,5,{"name":"yy"})]
G.add_edges_from(list1)
for n,nbrs in G.adjacency():
print("结点:",n)
print("相邻结点信息:",nbrs)
#结果:
结点: 1
相邻结点信息: {2: {'name': 'hh'}, 4: {'name': 'tt'}}
结点: 2
相邻结点信息: {1: {'name': 'hh'}, 3: {'name': 'xx'}}
结点: 3
相邻结点信息: {2: {'name': 'xx'}}
结点: 4
相邻结点信息: {1: {'name': 'tt'}, 5: {'name': 'yy'}}
结点: 5
相邻结点信息: {4: {'name': 'yy'}}
3、图遍历
深度优先遍历的算法:
首先以一个未被访问过的顶点作为起始顶点,沿当前顶点的边走到未访问过的相邻顶点;
当当前顶点没有未访问过的相邻顶点时,则回到上一个顶点,继续试探别的相邻顶点,直到所有的顶点都被访问过。
深度优先遍历算法的思想是:从一个顶点出发,一条路走到底;如果此路走不通,就返回上一个顶点,继续走其他路。
广度优先遍历的算法:
从顶点v出发,依次访问v的各个未访问过的相邻顶点;
分别从这些相邻顶点出发依次访问它们的相邻顶点;
广度优先遍历算法的思想是:以v为起点,按照路径的长度,由近至远,依次访问和v有路径相通且路径长度为1,2...,n的顶点。
在进行图遍历时,需要访问顶点的相邻顶点,这需要用到adjacency()函数,例如,g是一个无向图,n是顶点,nbrs是顶点n的相邻顶点,是一个字典结构
list1=[(1,2,{"name":"hh"}),(2,3,{"name":"xx"}),(1,4,{"name":"tt"}),(4,5,{"name":"yy"})]
G.add_edges_from(list1)
print("返回所有结点信息:",G.nodes(data=True))
print("返回所有边信息:",G.edges(data=True))
for n,nbrs in G.adjacency():
print("结点:",n)
print("相邻结点信息:",nbrs)
print("以列表形式返回(Key-Value)组成元组",nbrs.items())
for nbr,attr in nbrs.items():
print("相邻结点:",nbr)
print("对应相邻结点得属性:",attr)
#结果:
返回所有结点信息: [(1, {}), (2, {}), (3, {}), (4, {}), (5, {})]
返回所有边信息: [(1, 2, {'name': 'hh'}), (1, 4, {'name': 'tt'}), (2, 3, {'name': 'xx'}), (4, 5, {'name': 'yy'})]
结点: 1
相邻结点信息: {2: {'name': 'hh'}, 4: {'name': 'tt'}}
以列表形式返回(Key-Value)组成元组 dict_items([(2, {'name': 'hh'}), (4, {'name': 'tt'})])
相邻结点: 2
对应相邻结点得属性: {'name': 'hh'}
相邻结点: 4
对应相邻结点得属性: {'name': 'tt'}
结点: 2
相邻结点信息: {1: {'name': 'hh'}, 3: {'name': 'xx'}}
以列表形式返回(Key-Value)组成元组 dict_items([(1, {'name': 'hh'}), (3, {'name': 'xx'})])
相邻结点: 1
对应相邻结点得属性: {'name': 'hh'}
相邻结点: 3
对应相邻结点得属性: {'name': 'xx'}
结点: 3
相邻结点信息: {2: {'name': 'xx'}}
以列表形式返回(Key-Value)组成元组 dict_items([(2, {'name': 'xx'})])
相邻结点: 2
对应相邻结点得属性: {'name': 'xx'}
结点: 4
相邻结点信息: {1: {'name': 'tt'}, 5: {'name': 'yy'}}
以列表形式返回(Key-Value)组成元组 dict_items([(1, {'name': 'tt'}), (5, {'name': 'yy'})])
相邻结点: 1
对应相邻结点得属性: {'name': 'tt'}
相邻结点: 5
对应相邻结点得属性: {'name': 'yy'}
结点: 5
相邻结点信息: {4: {'name': 'yy'}}
以列表形式返回(Key-Value)组成元组 dict_items([(4, {'name': 'yy'})])
相邻结点: 4
对应相邻结点得属性: {'name': 'yy'}
绘制图Graph
使用networkx模块draw()函数构造graph,使用matplotlib把图显示出来:
nx.draw(g)
import matplotlib.pyplot as plt
plt.show()
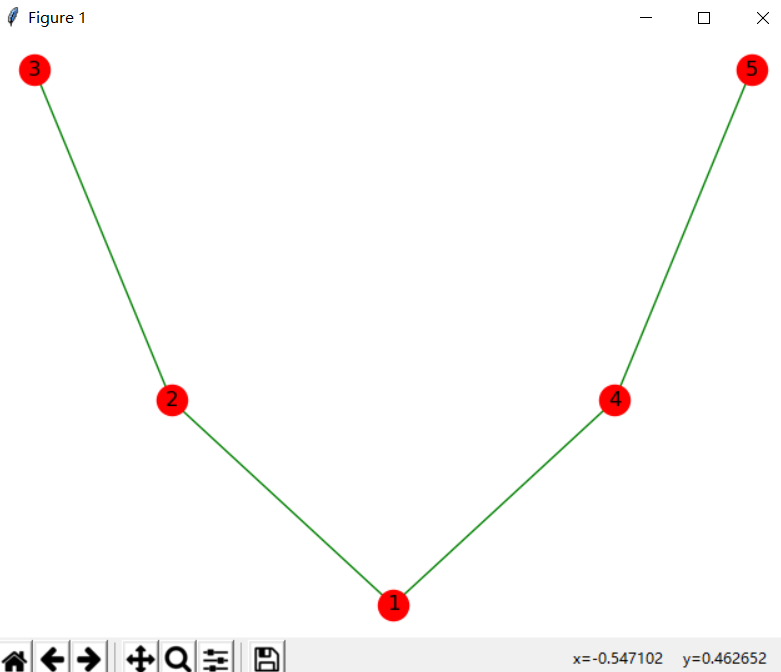
#设置结点和边得颜色
nx.draw(G,with_labels=True,pos=nx.spectral_layout(G),node_color="r",edge_color="g")
plt.show()
#结果如图:
案例
#案例1:
import matplotlib.pyplot as plt # 导入模块函数,目的是为了绘制子图
G = nx.cubical_graph() # 生成一个正则图(3-regular Platonic Cubical graph)
plt.subplot(121) # 绘制子图,创建一个1行2列的图形,并选取第1行第1列的子图作为绘图背景
nx.draw(G)
plt.subplot(122) 创建一个1行2列的图形,选取第1行第2列的子图作为绘图背景
nx.draw(G,pos=nx.circular_layout(G),nodecolor='r',edge_color='b') #绘图函数
plt.show() #展示图
结果: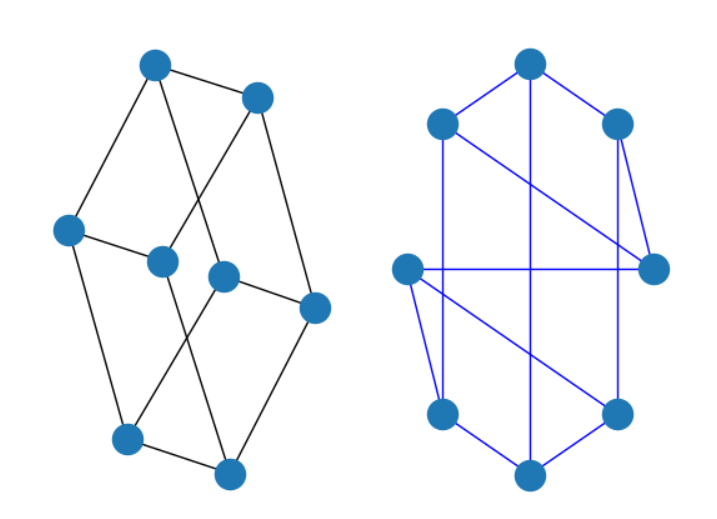
说明:
nx.draw(G, pos=None, ax=None, **kwds)
##G表示要绘制的网络图,pos是一个可选项,默认为None,其用于建立布局,不同的*_layout有不同的美化效果,如下所示。ax和**kwds是可选项,其中参数很多,可参阅官方文档,这里的“nodecolor用以控制节点颜色,edge_color用于控制边的颜色”。
##circular_layout:将节点位置调整为圆形;
##random_layout:将节点随机的放在一个单位正方形内;
##shell_layout:将节点放于多个同心圆内;
##spring_layout:使用FR算法来定位节点;
##spectral_layout:利用图拉普拉斯的特征向量定位节点
案例2:
G = nx.Graph()
G.add_edge('A','B',weight=0.5)
G.add_edge('B','C',weight=5)
print(G.adj)
nx.draw(G,with_labels=True)
plt.show()
#结果:{'B': {'C': {'weight': 5}, 'A': {'weight': 0.5}}, 'C': {'B': {'weight': 5}}, 'A': {'B': {'weight': 0.5}}}
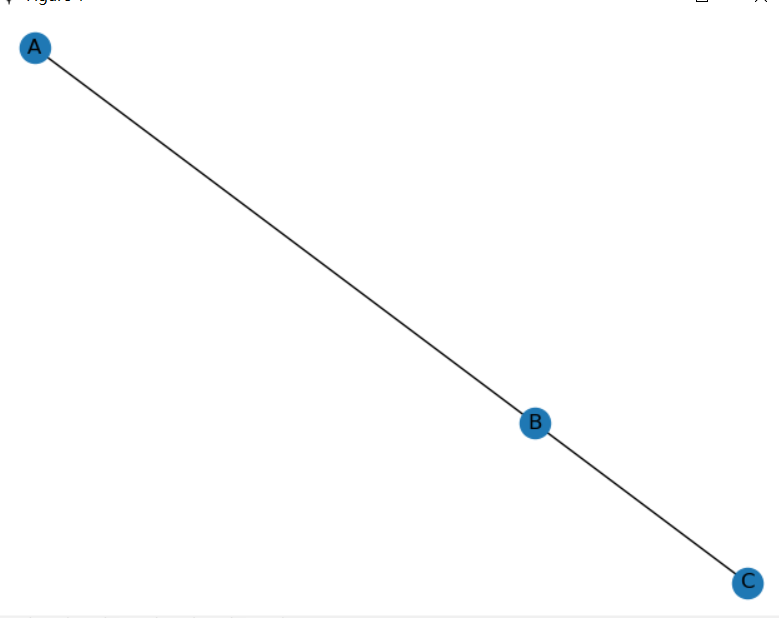
案例3:获取结点得邻居以及边得属性
G=nx.DiGraph()
G.add_edge(1,2,weight=5,color='red',size=10)
print("结点1得邻居:",G[1])
print("边得全部信息:",G[1][2])
print("边得尺寸:",G[1][2]["size"])
print("边得颜色:",G[1][2]["color"])
nx.draw(G,with_labels=True)
plt.show()
#结果:
结点1得邻居: {2: {'color': 'red', 'weight': 5, 'size': 10}}
边得全部信息: {'color': 'red', 'weight': 5, 'size': 10}
边得尺寸: 10
边得颜色: red
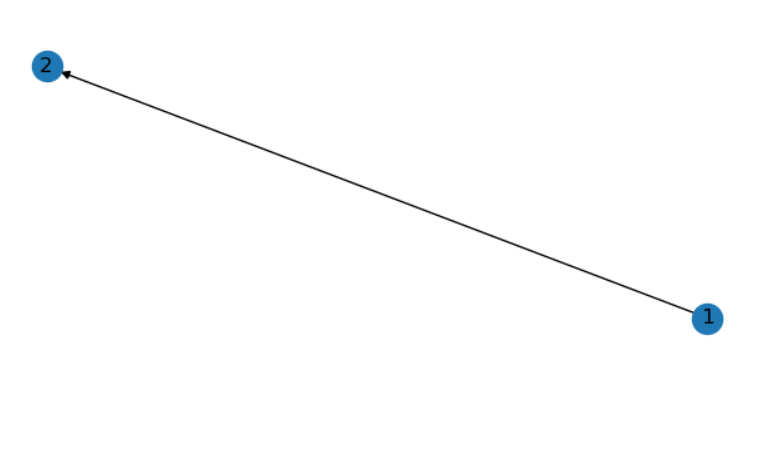
参考:https://www.cnblogs.com/ljhdo/p/10662902.html
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/223412.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
