大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
背景
CNN是深度学习的重中之重,而conv1D,conv2D,和conv3D又是CNN的核心,所以理解conv的工作原理就变得尤为重要。在本博客中,将简单梳理一下这三种卷积,以及在PyTorch中的应用方法。
参考
https://pytorch.org/docs/master/nn.html#conv1d
https://pytorch.org/docs/master/nn.functional.html#conv1d
文档
本节的主要内容就是一边看文档,一边用代码验证。在PyTorch中,分别在torch.nn和torch.nn.functional两个模块都有conv1d,conv2d和conv3d;从计算过程来说,两者本身没有太大区别;但是torch.nn下的都是layer,conv的参数都是经过训练得到;torch.nn.functional下的都是函数,其参数可以人为设置。本文在分析时,两者的文档一起看,但是实验主要以torch.nn.functional为主,更加方便修改。
conv1d
由于conv的参数都大同小异,但是conv1d更加方便理解(更容易可视化),所以我会话费大量时间详细介绍此卷积方式。
torch.nn.functional.conv1d(input, weight, bias=None, stride=1, padding=0, dilation=1, groups=1)
input
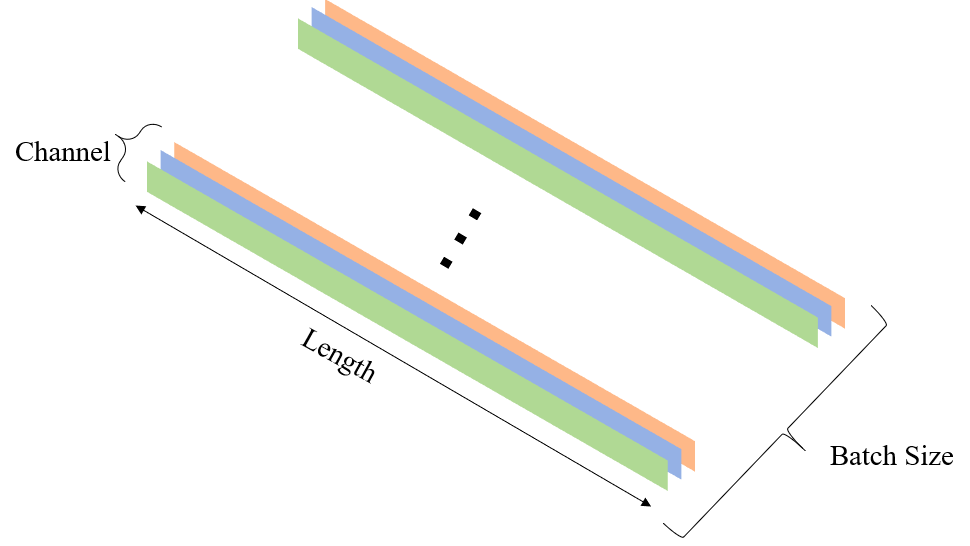
input是一维输入,其形状为(Batch_Size,In_Channel,Length);Batch_Size是训练批量的大小;In_Channel是输入的通道数量;Length是输入的长度,因为是一维输入,所以其只有长度。下图展示了一个一维输入,其包括3个通道:

weight
weight是一维卷积核,其形状为(Out_Channel,In_Channel/Group,Kernel_Size);Out_Channel是输出的通道数量;In_Channel/Group的目的是决定每一层的输出是如何由输入组成的,后续会详细介绍,此处不妨设Group=1;Kernel_Size是一维卷积核的大小。下图展示了一个一维卷积核和其对应的累加方式:
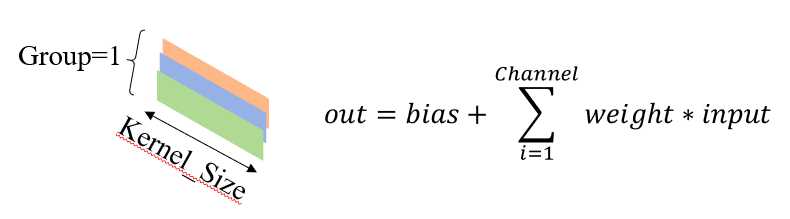
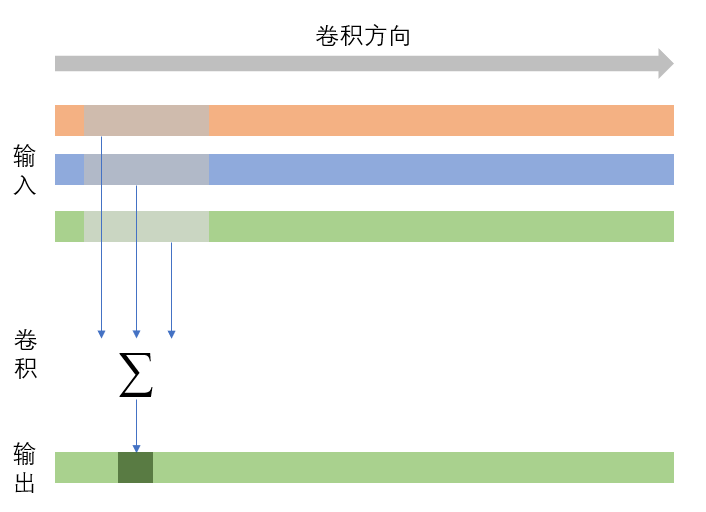
考虑到公式还是太难看懂,再画一个图展示上图右边的公式是怎么计算的(并没有画bias):
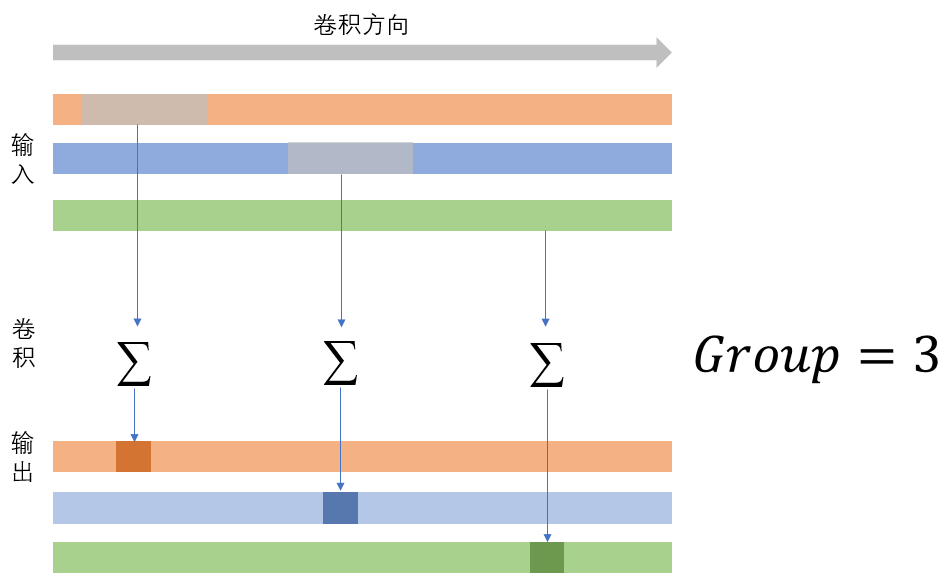
group
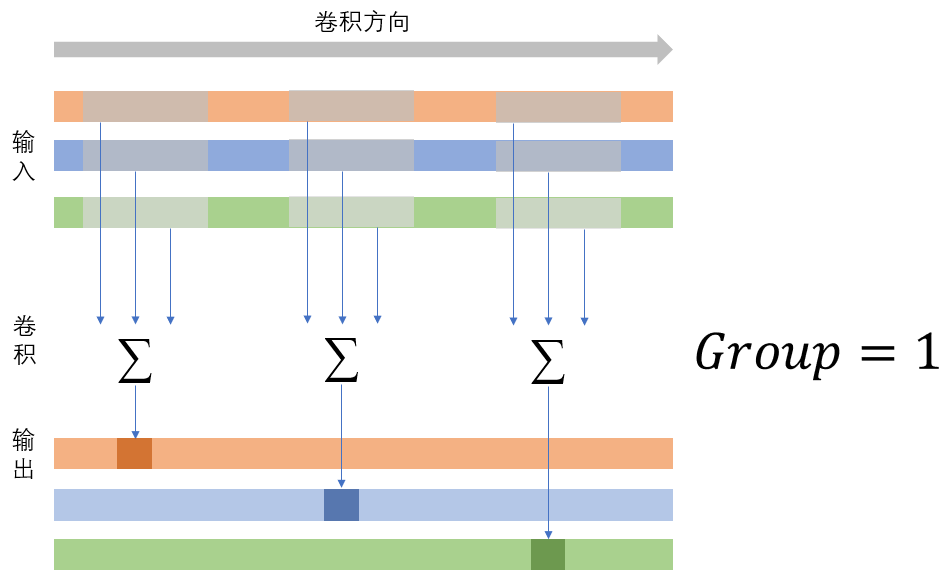
groups是卷积中一个非常特殊的参数,前边已经提到,此处再详细介绍;当Group=1时,每一层输出由所有输入分别与卷积核卷积的累加得到,当Group=2,每一层输出仅由一般的输入卷积累加得到(前提是,输入通道数和输出通道数都可以被Group整除),当Group=In_Channel时,每一层输出由每一层输入卷积得到,无需累加,换句话说,Group的值会打断输入层之间的卷积关系。下图左是是Group=1,右图是Group=3,体会一下。
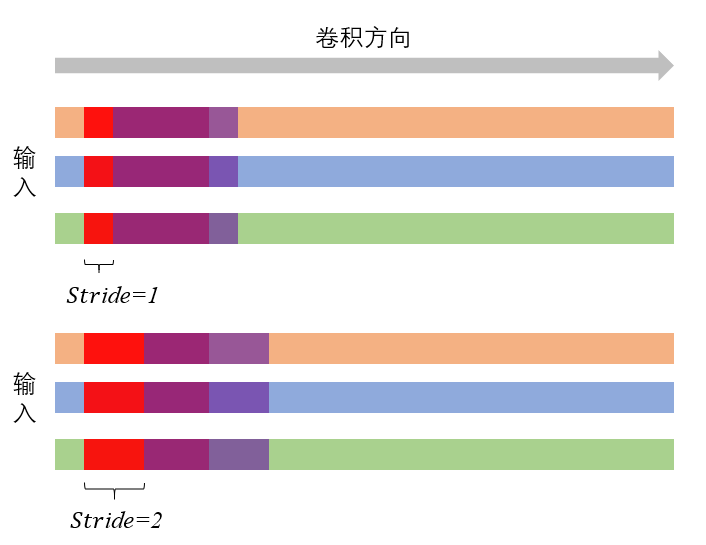
stride
stride理解起来还是很容易;当stride=1时,卷积核在原始输入上以步长为1进行移动;当stride=2时,卷积核就以不是为2进行移动;以此类推。下图展示了不同的卷积stride,其中红色表示第一次卷积,紫色表示第二次卷积。
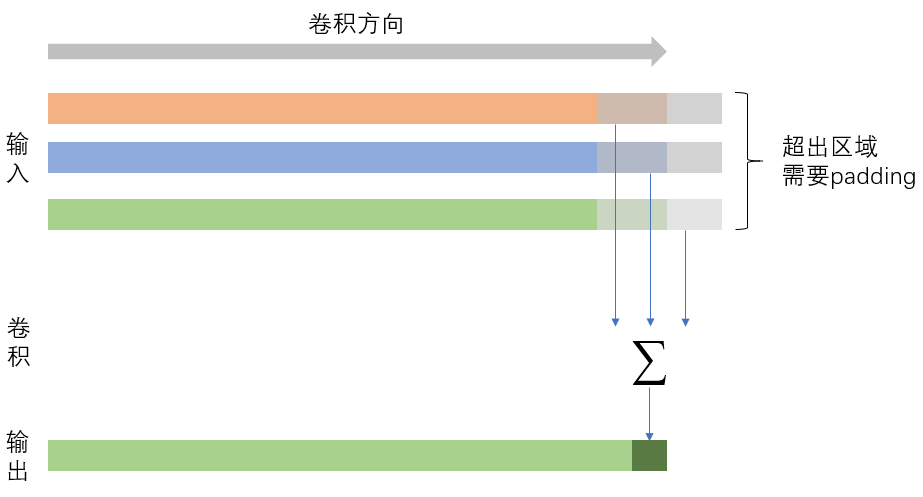
padding
padding也是一个非常容易理解的概念,其主要用于处理卷积的边界情况。对于torch.nn.Conv1d而言,padding有非常多的模式,什么置为0,镜像,复制等等;但是torch.nn.functional.Conv1d就只有置为0。
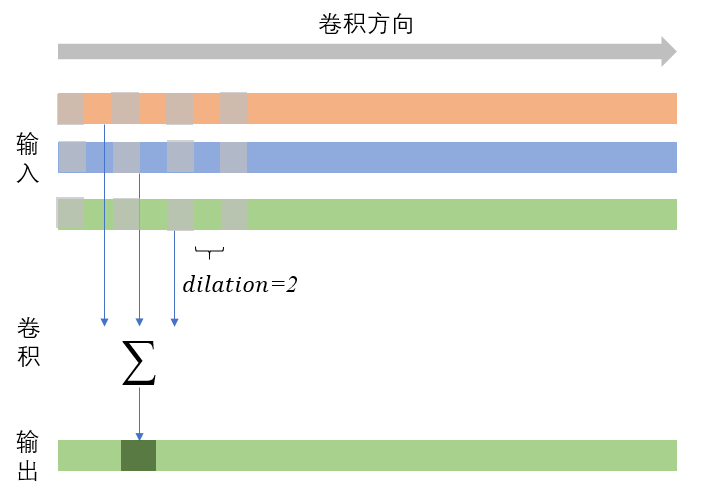
dilation
dilation,按照我的理解就是带孔卷积,其控制输入层上的取样间隔,当dilation=1时,就是前文所示的卷积。下图展示了一个dilation=2的情形,不难发现,这个参数能够在不增强计算量的前提下增大感受野。
bias
bias没啥好说的。
conv2d&conv3d
原则上讲,如果看文档,会发现conv2d、conv3d和conv1d并没有太大的区别,只不过在维度上有所区别。因此,我也就不分开介绍,直接放在一起。不难发现,唯一的区别在于维度的上升;因此为weights的定义也有所不同,分别是(Out_Channels, In_channels/Groups,kH,kW)和(Out_Channels, In_channels/Groups,kT,kH,kW)。
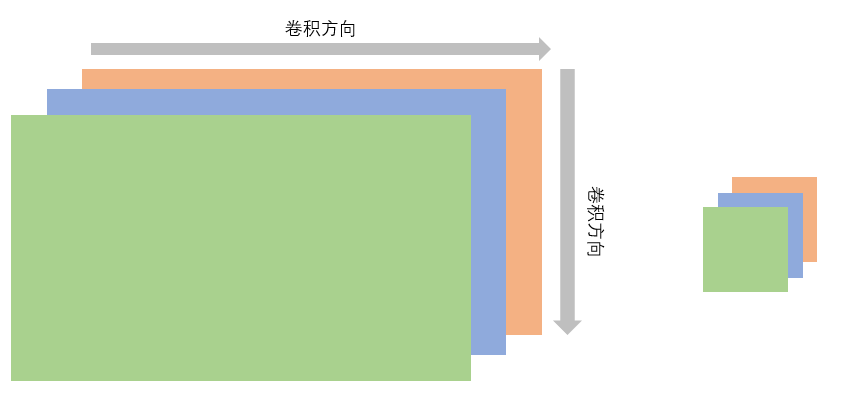
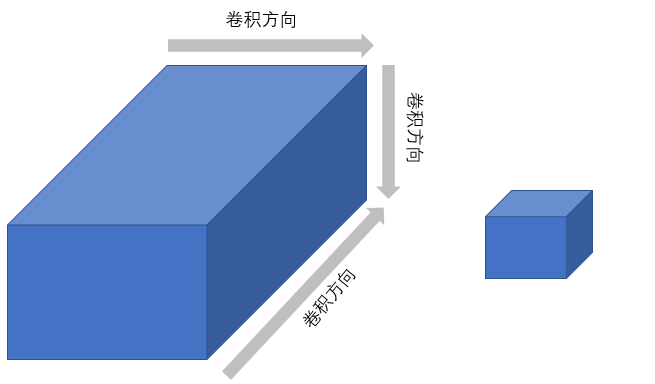
不过这里,我额外说一下,当输入图像有RGB三个通道时,似乎看起来conv2d和conv3d没啥区别,反正都要对所有通道进行卷积。但是其实这里有非常大的区别:
conv3d除了可以在图像平面上移动卷积之外,还可以在深度方向进行卷积;而conv2d并没有这个能力。conv3d中的深度和conv2d中的Channel是不对应的,conv3d中的每一个深度上都可以对应多个Channel(虽然图不是这样画的),因此深度和Channel是不同的概念。
代码
下边写几个测试代码,并简单说明一下。
conv1d
Batch_Size = 1
In_Channel = 2
Length = 7
Out_Channel = 2
Group = 1
Kernel_Size = 3
Padding = 1
Dilation = 1
one = torch.rand(Batch_Size,In_Channel,Length)
print('one',one)
# 定义了两个Kernel
# 第一个Kernel取第一个Channel中间那个值
# 第二个Kernel将第一个Channel与第二个Channel相减
filter = torch.zeros(Out_Channel,int(In_Channel/Group),Kernel_Size)
filter[0][0][1] = 1
filter[1][0][1] = 1
filter[1][1][1] = -1
result = F.conv1d(one,filter,padding=Padding,groups=Group,dilation=Dilation)
print('result',result)
结果
one tensor([[[0.6465, 0.3762, 0.3227, 0.6881, 0.6364, 0.5725, 0.8627],
[0.9221, 0.7417, 0.3096, 0.1008, 0.8527, 0.4099, 0.4143]]])
result tensor([[[ 0.6465, 0.3762, 0.3227, 0.6881, 0.6364, 0.5725, 0.8627],
[-0.2756, -0.3655, 0.0131, 0.5873, -0.2163, 0.1626, 0.4485]]])
conv2d
Batch_Size = 1
In_Channel = 2
Height = 5
Width = 5
Out_Channel = 2
Group = 1
Kernel_Size_H = 3
Kernel_Size_W = 3
Padding = 1
Dilation = 1
# 定义了两个Kernel
# 第一个Kernel取第一个Channel左上角的值
# 第二个Kernel取第二个Channel右下角的值
two = torch.rand(Batch_Size,In_Channel,Height,Width)
print('two',two)
filter = torch.zeros(Out_Channel,int(In_Channel/Group),Kernel_Size_H,Kernel_Size_W)
filter[0][0][0][0]=1
filter[1][1][2][2]=1
depth = F.conv2d(two,filter,padding=Padding)
print(depth.shape)
print(depth)
结果
two tensor([[[[0.6886, 0.5815, 0.2635, 0.5373, 0.2606],
[0.7335, 0.2440, 0.5123, 0.9990, 0.1864],
[0.5270, 0.1498, 0.0728, 0.1900, 0.0408],
[0.0819, 0.2725, 0.7476, 0.8551, 0.2504],
[0.2355, 0.5189, 0.7329, 0.8619, 0.3117]],
[[0.5712, 0.4581, 0.7050, 0.2502, 0.3364],
[0.1892, 0.6736, 0.3675, 0.2895, 0.8894],
[0.5782, 0.0020, 0.5400, 0.4404, 0.3508],
[0.3597, 0.1373, 0.0068, 0.0440, 0.9917],
[0.3296, 0.0371, 0.0367, 0.0597, 0.8797]]]])
torch.Size([1, 2, 5, 5])
tensor([[[[0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.6886, 0.5815, 0.2635, 0.5373],
[0.0000, 0.7335, 0.2440, 0.5123, 0.9990],
[0.0000, 0.5270, 0.1498, 0.0728, 0.1900],
[0.0000, 0.0819, 0.2725, 0.7476, 0.8551]],
[[0.6736, 0.3675, 0.2895, 0.8894, 0.0000],
[0.0020, 0.5400, 0.4404, 0.3508, 0.0000],
[0.1373, 0.0068, 0.0440, 0.9917, 0.0000],
[0.0371, 0.0367, 0.0597, 0.8797, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000]]]])
conv3d
Batch_Size = 1
In_Channel = 2
Height = 5
Width = 5
Depth = 5
Out_Channel = 2
Group = 1
Kernel_Size_D = 3
Kernel_Size_H = 3
Kernel_Size_W = 3
Padding = 1
Dilation = 1
# 定义了两个Kernel
# 第一个Kernel取第一个深度,左上角的值
# 第二个Kernel啥也不做
thr = torch.rand(Batch_Size,In_Channel,Depth,Height,Width)
print(thr)
filter = torch.zeros(Out_Channel,int(In_Channel/Group),Kernel_Size_D,Kernel_Size_H,Kernel_Size_W)
filter[0][0][0][0][0]=1
result = torch.conv3d(thr,filter,padding=1)
print(result)
结果
tensor([[[[[0.9226, 0.8931, 0.7071, 0.7718, 0.5866],
[0.1164, 0.8881, 0.5236, 0.7025, 0.1280],
[0.1002, 0.0013, 0.1704, 0.1424, 0.5018],
[0.8796, 0.3582, 0.2792, 0.7098, 0.9759],
[0.4871, 0.3776, 0.9242, 0.5693, 0.0594]],
[[0.7816, 0.8589, 0.4025, 0.0712, 0.4381],
[0.2501, 0.1536, 0.5014, 0.4333, 0.9369],
[0.9491, 0.8624, 0.4953, 0.6443, 0.4056],
[0.7834, 0.2791, 0.5448, 0.0204, 0.4199],
[0.1179, 0.0021, 0.3744, 0.6835, 0.4836]],
[[0.9522, 0.0417, 0.0653, 0.4445, 0.2879],
[0.2581, 0.8633, 0.2610, 0.9866, 0.9338],
[0.2689, 0.6511, 0.0543, 0.7373, 0.2599],
[0.7211, 0.9832, 0.9786, 0.3957, 0.2649],
[0.3640, 0.5514, 0.6898, 0.9033, 0.2067]],
[[0.5609, 0.7697, 0.0895, 0.1205, 0.2559],
[0.7284, 0.0997, 0.3773, 0.1338, 0.9526],
[0.1489, 0.0499, 0.6159, 0.9188, 0.9630],
[0.0550, 0.0325, 0.0619, 0.2393, 0.9781],
[0.6343, 0.4791, 0.6076, 0.7346, 0.1744]],
[[0.4132, 0.2946, 0.3903, 0.6658, 0.6961],
[0.7019, 0.1594, 0.6541, 0.5868, 0.0685],
[0.7312, 0.9089, 0.8287, 0.4644, 0.3078],
[0.7363, 0.2700, 0.7368, 0.8905, 0.2089],
[0.3708, 0.5744, 0.2688, 0.7639, 0.8681]]],
[[[0.7363, 0.4299, 0.6298, 0.6484, 0.5674],
[0.9055, 0.7832, 0.7443, 0.1624, 0.6099],
[0.8624, 0.1860, 0.2237, 0.3271, 0.5107],
[0.2373, 0.6254, 0.8148, 0.3317, 0.6703],
[0.8364, 0.2029, 0.2762, 0.4807, 0.6596]],
[[0.1022, 0.9687, 0.4097, 0.9130, 0.5343],
[0.3665, 0.0765, 0.0136, 0.6457, 0.5640],
[0.3436, 0.1625, 0.8261, 0.5664, 0.7331],
[0.4402, 0.8114, 0.4218, 0.5149, 0.3197],
[0.2731, 0.3032, 0.9294, 0.9505, 0.3776]],
[[0.2852, 0.0566, 0.5607, 0.0690, 0.6652],
[0.5315, 0.5046, 0.9546, 0.5480, 0.4868],
[0.5333, 0.7227, 0.0407, 0.6066, 0.6386],
[0.5846, 0.2641, 0.0451, 0.0521, 0.8822],
[0.8929, 0.2496, 0.5646, 0.3253, 0.8867]],
[[0.3010, 0.5833, 0.6355, 0.2783, 0.4770],
[0.6493, 0.2489, 0.9739, 0.8326, 0.7717],
[0.3469, 0.9503, 0.3222, 0.4197, 0.5231],
[0.2533, 0.4396, 0.8671, 0.6622, 0.3155],
[0.0444, 0.3937, 0.0983, 0.5874, 0.6237]],
[[0.8788, 0.4389, 0.2793, 0.9504, 0.5325],
[0.4858, 0.3797, 0.3282, 0.6697, 0.5938],
[0.8738, 0.4183, 0.1169, 0.2855, 0.2764],
[0.0590, 0.4542, 0.8047, 0.1575, 0.3735],
[0.2168, 0.4904, 0.1830, 0.2141, 0.4013]]]]])
tensor([[[[[0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000]],
[[0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.9226, 0.8931, 0.7071, 0.7718],
[0.0000, 0.1164, 0.8881, 0.5236, 0.7025],
[0.0000, 0.1002, 0.0013, 0.1704, 0.1424],
[0.0000, 0.8796, 0.3582, 0.2792, 0.7098]],
[[0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.7816, 0.8589, 0.4025, 0.0712],
[0.0000, 0.2501, 0.1536, 0.5014, 0.4333],
[0.0000, 0.9491, 0.8624, 0.4953, 0.6443],
[0.0000, 0.7834, 0.2791, 0.5448, 0.0204]],
[[0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.9522, 0.0417, 0.0653, 0.4445],
[0.0000, 0.2581, 0.8633, 0.2610, 0.9866],
[0.0000, 0.2689, 0.6511, 0.0543, 0.7373],
[0.0000, 0.7211, 0.9832, 0.9786, 0.3957]],
[[0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.5609, 0.7697, 0.0895, 0.1205],
[0.0000, 0.7284, 0.0997, 0.3773, 0.1338],
[0.0000, 0.1489, 0.0499, 0.6159, 0.9188],
[0.0000, 0.0550, 0.0325, 0.0619, 0.2393]]],
[[[0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000]],
[[0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000]],
[[0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000]],
[[0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000]],
[[0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000]]]]])
总结
莫名其妙就写了一大堆,也许还是不懂,但是跑跑代码就明白了。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/222994.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
