大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
DCGAN入门
前言
根据之前的两片入门级别的GAN文章,相信各位对GAN有一丝丝了解。
知道对抗网络究竟是干什么的就能读懂这篇文章了=·=
DCGAN介绍
DCGAN的英文全名为:Deep Convolution Generative Adversarial Networks
顾名思义,DCGAN主要由两部分组成,即:
- 生成模型 G
- 判别模型 D
其工作的基本原理很简单,以图片生成任务为例来说明。生成模型的作用是根据网络输入的随机噪声 z ,来生成一张图片 G(z) ;而判别模型的作用则是判别网络输入的图片 x 是否是”真实”的,即 D(x) 。这里的”真实”意味着输入的图片不是由生成模型生成,而是真实存在的。
简单画个示例图吧:
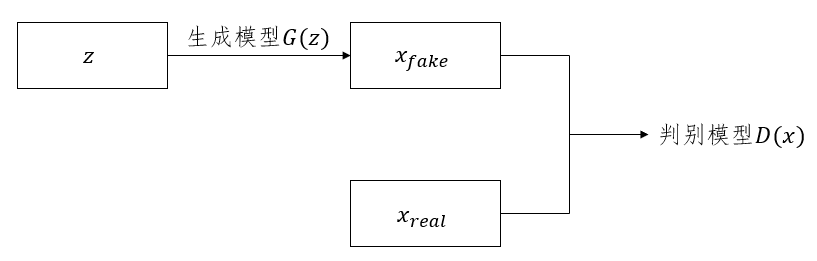

在DCGAN的训练过程中,生成模型的训练目标是使得生成的图片可以很好地欺骗判别模型,使得判别模型认为生成模型生成的图片是”真实”的;而判别模型的训练目标则是尽量地正确区分生成模型生成的图片和真实存在的图片。于是,这种训练方式就很自然地产生了生成模型和判别模型之间的”博弈”。
在理想情况下,我们希望DCGAN训练好之后,生成模型 G 生成的图片是可以以假乱真的,即 D(G(z)) = 0.5 。
具体思路是,生成器是将一个噪点生成一副假图片,然后将假图片传给判别器进行判断,如果判别器判断为真,则代码生成器性能很好,而判别器是从真实图片中学习模型,对生成的假图片进行判断,如果判断出来为假则代码判别器性能很好。
所需环境
- Python 3.7
- torch >= 1.0.0
- torchvision
- argparse
- pillow
代码解刨
训练集获取
本文数据集来自kaggle的tagged-anime-illustrations作为训练使用。
共包含51222个64×64的动漫头像。
作者已经为你们打包到项目中供你们使用。
所需参数构造
我们会将参数放到一个py文件中,方便其他代码引用一些全局参数。
介绍代码的时候我会讲解全局参数的作用,这里我们先忽略参数意义。
# 潜在空间的维度
NUM_LATENT_DIMS = 100
# 批次大小
BATCH_SIZE = 128
# 图片尺寸
IMAGE_SIZE = (64, 64)
# 图片规范化信息
IMAGE_NORM_INFO = {
'means': [0.5, 0.5, 0.5], 'stds': [0.5, 0.5, 0.5]}
# 训练批次的数量
NUM_EPOCHS = 500
# 保存检查点之间的间隔
SAVE_INTERVAL = 5
# 图片路径
ROOTDIR = os.path.join(os.getcwd(), 'images/*')
# 检查点保存位置
BACKUP_DIR = os.path.join(os.getcwd(), 'checkpoints')
# 日志保存位置
LOGFILEPATH = {
'train': os.path.join(BACKUP_DIR, 'train.log'), 'test': os.path.join(BACKUP_DIR, 'test.log')}
# 优化器配置参数
OPTIMIZER_CFG = {
'generator': {
'type': 'adam', 'adam': {
'lr': 1e-4, 'betas': [0.5, 0.999]}},
'discriminator': {
'type': 'adam', 'adam': {
'lr': 1e-4, 'betas': [0.5, 0.999]}}}
前期准备工作代码编写
由于是个长时间训练的深度学习,准备工作不能缺少。在这里主要介绍以下几点方面:
- 日志输出
- 训练节点保存
- 训练节点读取
- 生成优化器
- 权重能否正常初始化
- 图像数据集由torch读取
- 运行额外参数填写
日志输出
使用的是Python3自带的 logging 模块处理日志。
日志格式为:当前时间 + level等级 + message内容
'''log function.'''
class Logger():
def __init__(self, logfilepath, **kwargs):
logging.basicConfig(level=logging.INFO,
format='%(asctime)s %(levelname)-8s %(message)s',
datefmt='%Y-%m-%d %H:%M:%S',
handlers=[logging.FileHandler(logfilepath),
logging.StreamHandler()])
@staticmethod
def log(level, message):
logging.log(level, message)
@staticmethod
def debug(message):
Logger.log(logging.DEBUG, message)
@staticmethod
def info(message):
Logger.log(logging.INFO, message)
@staticmethod
def warning(message):
Logger.log(logging.WARNING, message)
@staticmethod
def error(message):
Logger.log(logging.ERROR, message)
训练节点保存
torch.save模块可以提供模型的保存。
使用这种方法,将会保存模型的参数和结构信息。
参数一为模型的字典格式特征,参数二为保存的位置路径。
'''save checkpoints'''
def saveCheckpoints(state_dict, savepath, logger_handle):
logger_handle.info('Saving state_dict in %s...' % savepath)
torch.save(state_dict, savepath)
return True
训练节点读取
torch.load模块可以提供模型的读取,参数为保存的位置路径
该读取为测试时需要读取模型。当运行代码为测试时,我们必须提供此参数。
'''load checkpoints'''
def loadCheckpoints(checkpointspath, logger_handle):
logger_handle.info('Loading checkpoints from %s...' % checkpointspath)
if torch.cuda.is_available():checkpoints = torch.load(checkpointspath)
else:checkpoints = torch.load(checkpointspath, map_location='cpu')
return checkpoints
生成优化器
torch.optim.Adam()利用系统自带Adam优化器更新参数。
参数如下:
params (iterable)– 待优化参数的iterable或者是定义了参数组的dictlr(float, 可选) – 学习率(默认:1e-3)。同样也称为学习率或步长因子,它控制了权重的更新比率。较大的值在学习率更新前会有更快的初始学习,而较小的值会令训练收敛到更好的性能。betas(Tuple[float,float], 可选) – 用于计算梯度以及梯度平方的运行平均值的系数(默认:0.9,0.999)eps(float, 可选) – 为了增加数值计算的稳定性而加到分母里的项(默认:1e-8)。该参数是非常小的数,其为了防止在实现中除以零。weight_decay(float, 可选) – 权重衰减(L2惩罚)(默认: 0)
'''build optimizer'''
def buildOptimizer(params, cfg):
if cfg['type'] == 'adam':
optimizer = torch.optim.Adam(params, lr=cfg['adam']['lr'], betas=(cfg['adam']['betas'][0], cfg['adam']['betas'][1]))
else:
raise ValueError('Unsupport type %s in buildOptimizer...' % cfg['type'])
return optimizer
权重初始化
首先用self.__class__将实例变量指向类,然后再去调用__name__类属性
两种情况分别讨论:
Conv类中,使w参数服从正态分布。BatchNorm2d类中,首先将w参数服从正态分布,其次将b参数初始化为常数。
torch.nn.init.normal_(tensor, mean=0, std=1)服从正态分布。满足~N(mean,std)
torch.nn.init.constant_(tensor, val)初始化为常数。初始化整个矩阵为val
'''normal initialization'''
def weightsNormalInit(m):
classname = m.__class__.__name__
if classname.find("Conv") != -1:
torch.nn.init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find("BatchNorm2d") != -1:
torch.nn.init.normal_(m.weight.data, 1.0, 0.02)
torch.nn.init.constant_(m.bias.data, 0.0)
图像数据集读取
该ImageDataset类继承torch.utils.data.Dataset。
传进来的参数一共有三个。
rootdir为图像数据集的位置,需要断言此参数的最后一个字符串为*,数据集不能是单个必须是个整体。imagesize为图像数据集的尺寸大小,可被Resize到相应的尺寸方便处理。img_norm_info为图像数据集的平均值和标准差,方便Normalize进行归一化处理。
__getitem__魔法为在整个类运行时,出现单方面映射则会调用此方法。在此魔法中将读取每一张图片给torch传输数据做特征处理后返回给主变量。方便接下来处理。
preprocess函数中用到了以下函数,一一介绍:
torchvision.transforms.Compose()作用是可以将图像预处理操作连起来。torchvision.transforms.Resize()作用是把给定的图片resize到给定的尺寸。torchvision.transforms.ToTensor()作用是将一个PIL图像转换为tensor。即,(H × W × C)范围在[0,255]的PIL图像 转换为 (CHW)范围在[0,1]的torch.tensor。torchvision.transforms.Normalize()作用是均值和标准差对图像做归一化处理。
'''load images'''
class ImageDataset(Dataset):
def __init__(self, rootdir, imagesize, img_norm_info, **kwargs):
assert rootdir.endswith('*')
self.rootdir = rootdir
self.imagesize = imagesize
self.img_norm_info = img_norm_info
self.imagepaths = glob.glob(rootdir)
'''get item'''
def __getitem__(self, index):
image = Image.open(self.imagepaths[index])
return ImageDataset.preprocess(image, self.imagesize, self.img_norm_info)
'''calculate length'''
def __len__(self):
return len(self.imagepaths)
'''preprocess image'''
@staticmethod
def preprocess(image, imagesize, img_norm_info):
means_norm, stds_norm = img_norm_info.get('means'), img_norm_info.get('stds')
transform = torchvision.transforms.Compose([torchvision.transforms.Resize(imagesize),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(mean=means_norm, std=stds_norm)])
return transform(image)
运行额外参数
主要让代码知道你运行代码的需求。究竟是训练还是测试。
如果是测试的话你的检查点位置又在哪里。
'''parse arguments in command line'''
def parseArgs():
parser = argparse.ArgumentParser(description='use wcgan to generate anime avatar')
parser.add_argument('--mode', dest='mode', help='train or test', default='train', type=str)
parser.add_argument('--checkpointspath', dest='checkpointspath', help='the path of checkpoints', type=str)
args = parser.parse_args()
return args
基础工作大致已经做完了。接下来就是核心代码编写阶段了。
核心代码
核心代码分为以下三个阶段:
- 生成器G(x)的编写
- 判别器D(x)的编写
- 主函数main.py的编写
生成器G(x)
生成模型 G(x) 由几个转置卷积/卷积构成。
nn.Sequential()的作用:一个有序的容器,神经网络模块将按照在传入构造器的顺序依次被添加到计算图中执行,同时以神经网络模块为元素的有序字典也可以作为传入参数。nn.ConvTranspose2d()的作用:进行反卷积操作。nn.ConvTranspose2d(in_channels, out_channels, kernel_size, stride=1, padding=0, output_padding=0, groups=1, bias=True, dilation=1)- 参数
in_channels作用:输入维度。 - 参数
out_channels作用:输出维度。 - 参数
kernel_size作用:卷积核大小。 - 参数
stride作用:步长大小。 - 参数
padding作用:输入的每一条边补充0的层数,高宽都增加2*padding。 - 参数
output_padding作用:输出边补充0的层数,高宽都增加padding。 - 参数
groups作用:从输入通道到输出通道的阻塞连接数。
- BatchNormalization的目的是使我们的Batch feature map满足均值为0,方差为1的分布规律。
nn.BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)- 参数
num_features作用:一般输入参数为height*width,即为其中特征的数量。 - 参数
eps作用:分母中添加的一个值,目的是为了计算的稳定性,避免分母为0。 - 参数
momentum作用:一个用于运行过程中均值和方差的一个估计参数。 - 参数
affine作用:当设为true时,会给定可以学习的系数矩阵gamma和beta。
ReLU是将所有的负值都设为零,Leaky ReLU是给所有负值赋予一个非零斜率。
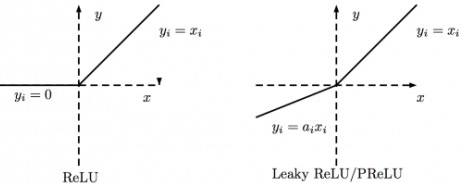
最后的激活函数用nn.Tanh()以保证输出的图片像素取值范围为[-1, 1]。原因是我们训练集中的真实图片在输入判别模型之前也会先归一化到[-1, 1]。(训练GAN的话图片一般都是归一化到[-1, 1]的)
'''generator'''
class Generator(nn.Module):
def __init__(self, cfg, **kwargs):
super(Generator, self).__init__()
assert cfg.IMAGE_SIZE[0] == cfg.IMAGE_SIZE[1] and cfg.IMAGE_SIZE[0] == 64
self.cfg = cfg
self.conv1 = nn.Sequential(nn.ConvTranspose2d(in_channels=cfg.NUM_LATENT_DIMS, out_channels=64*8, kernel_size=4, stride=1, padding=0, bias=False),
nn.BatchNorm2d(64*8),
nn.LeakyReLU(0.2, inplace=True))
self.conv2 = nn.Sequential(nn.ConvTranspose2d(in_channels=64*8, out_channels=64*4, kernel_size=4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(64*4),
nn.LeakyReLU(0.2, inplace=True))
self.conv3 = nn.Sequential(nn.ConvTranspose2d(in_channels=64*4, out_channels=64*2, kernel_size=4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(64*2),
nn.LeakyReLU(0.2, inplace=True))
self.conv4 = nn.Sequential(nn.ConvTranspose2d(in_channels=64*2, out_channels=64, kernel_size=4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(64),
nn.LeakyReLU(0.2, inplace=True))
self.conv5 = nn.Sequential(nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(64),
nn.LeakyReLU(0.2, inplace=True))
self.conv6 = nn.Sequential(nn.ConvTranspose2d(in_channels=64, out_channels=3, kernel_size=4, stride=2, padding=1, bias=False),
nn.Tanh())
def forward(self, x):
batch_size = x.size(0)
x = x.view(batch_size, -1, 1, 1)
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.conv5(x)
x = self.conv6(x)
return x
判别器D(x)
判别器前置代码与生成器类似,请读者自行理解。
最后的激活函数用nn.Sigmoid(),以预测每张图是真实图片的概率。
'''discriminator'''
class Discriminator(nn.Module):
def __init__(self, cfg, **kwargs):
super(Discriminator, self).__init__()
self.conv1 = nn.Sequential(nn.Conv2d(in_channels=3, out_channels=64, kernel_size=4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(64),
nn.LeakyReLU(0.2, inplace=True))
self.conv2 = nn.Sequential(nn.Conv2d(in_channels=64, out_channels=64*2, kernel_size=4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(64*2),
nn.LeakyReLU(0.2, inplace=True))
self.conv3 = nn.Sequential(nn.Conv2d(in_channels=64*2, out_channels=64*4, kernel_size=4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(64*4),
nn.LeakyReLU(0.2, inplace=True))
self.conv4 = nn.Sequential(nn.Conv2d(in_channels=64*4, out_channels=64*8, kernel_size=4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(64*8),
nn.LeakyReLU(0.2, inplace=True))
self.conv5 = nn.Sequential(nn.Conv2d(in_channels=64*8, out_channels=1, kernel_size=4, stride=1, padding=0, bias=False),
nn.Sigmoid())
def forward(self, x):
batch_size = x.size(0)
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.conv5(x)
return x.view(batch_size, -1)
主函数
最最最重要的主函数来了。上面的大风大浪都经历过来了就没什么可担心的了。
虽说主函数并不是特别难,但是主函数拥有着编写深度学习中所有的基本方法。
为了防止介绍出错,我将每一行代码的作用写在了下方代码体中
'''main function'''
def main():
# 解析参数
args = parseArgs()
assert args.mode in ['train', 'test']
if args.mode == 'test': assert os.path.isfile(args.checkpointspath)
# 一些必要的准备工作
checkDir(cfg.BACKUP_DIR)
logger_handle = Logger(cfg.LOGFILEPATH.get(args.mode))
start_epoch = 1
end_epoch = cfg.NUM_EPOCHS + 1
use_cuda = torch.cuda.is_available() # 检测电脑是否支持CUDA
# 定义数据集
dataset = ImageDataset(rootdir=cfg.ROOTDIR, imagesize=cfg.IMAGE_SIZE, img_norm_info=cfg.IMAGE_NORM_INFO)
dataloader = torch.utils.data.DataLoader(dataset, batch_size=cfg.BATCH_SIZE, shuffle=True)
# 定义损失函数
loss_func = nn.BCELoss()
if use_cuda: loss_func = loss_func.cuda()
# 定义模型
net_g = Generator(cfg)
net_d = Discriminator(cfg)
if use_cuda:
net_g = net_g.cuda()
net_d = net_d.cuda()
# 定义优化器
optimizer_g = buildOptimizer(net_g.parameters(), cfg.OPTIMIZER_CFG['generator'])
optimizer_d = buildOptimizer(net_d.parameters(), cfg.OPTIMIZER_CFG['discriminator'])
# 加载检查点
if args.checkpointspath:
checkpoints = loadCheckpoints(args.checkpointspath, logger_handle)
net_d.load_state_dict(checkpoints['net_d'])
net_g.load_state_dict(checkpoints['net_g'])
optimizer_g.load_state_dict(checkpoints['optimizer_g'])
optimizer_d.load_state_dict(checkpoints['optimizer_d'])
start_epoch = checkpoints['epoch'] + 1
else:
net_d.apply(weightsNormalInit)
net_g.apply(weightsNormalInit)
# 定义浮点张量
FloatTensor = torch.cuda.FloatTensor if use_cuda else torch.FloatTensor
# 训练模型
if args.mode == 'train':
for epoch in range(start_epoch, end_epoch):
logger_handle.info('Start epoch %s...' % epoch)
for batch_idx, imgs in enumerate(dataloader):
imgs = imgs.type(FloatTensor)
z = torch.randn(imgs.size(0), cfg.NUM_LATENT_DIMS, 1, 1).type(FloatTensor)
imgs_g = net_g(z)
# 训练生成器
optimizer_g.zero_grad()
labels = FloatTensor(imgs_g.size(0), 1).fill_(1.0)
loss_g = loss_func(net_d(imgs_g), labels)
loss_g.backward()
optimizer_g.step()
# 训练判别器
optimizer_d.zero_grad()
labels = FloatTensor(imgs_g.size(0), 1).fill_(1.0)
loss_real = loss_func(net_d(imgs), labels)
labels = FloatTensor(imgs_g.size(0), 1).fill_(0.0)
loss_fake = loss_func(net_d(imgs_g.detach()), labels)
loss_d = loss_real + loss_fake
loss_d.backward()
optimizer_d.step()
# 输出信息
logger_handle.info('Epoch %s/%s, Batch %s/%s, Loss_G %f, Loss_D %f' % (epoch, cfg.NUM_EPOCHS, batch_idx+1, len(dataloader), loss_g.item(), loss_d.item()))
# 保存检查点
if epoch % cfg.SAVE_INTERVAL == 0 or epoch == cfg.NUM_EPOCHS:
state_dict = {
'epoch': epoch,
'net_d': net_d.state_dict(),
'net_g': net_g.state_dict(),
'optimizer_g': optimizer_g.state_dict(),
'optimizer_d': optimizer_d.state_dict()
}
savepath = os.path.join(cfg.BACKUP_DIR, 'epoch_%s.pth' % epoch)
saveCheckpoints(state_dict, savepath, logger_handle)
save_image(imgs_g.data[:25], os.path.join(cfg.BACKUP_DIR, 'images_epoch_%s.png' % epoch), nrow=5, normalize=True)
# 测试模型
else:
z = torch.randn(cfg.BATCH_SIZE, cfg.NUM_LATENT_DIMS, 1, 1).type(FloatTensor)
net_g.eval()
imgs_g = net_g(z)
save_image(imgs_g.data[:25], 'images.png', nrow=5, normalize=True)
结果展示
下图为训练一百批次后生成的图像。看起来还行趴。

学以致用
真庆幸你们能学到最后,也不知道你们掌握了多少。
真的说深度学习零基础接受对抗网络是有点难。但我感觉我尽力了。
这篇文章就是想带你们感受一下深度学习的美妙之处。
也希望各位能学业有成,头发不秃。谢谢各位观看。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/222749.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
