大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
文章目录
Introduction
深度学习模型正在创建一些复杂任务的最先进模型,包括语音识别、计算机视觉、机器翻译等。然而,训练深度学习模型(如深度神经网络)是一项复杂的任务,因为在训练阶段,各层的输入不断变化。
归一化是在数据准备过程中应用的一种方法,当数据中的特征具有不同的范围时,为了改变数据集中的数字列的值,使用一个相同的尺度(common scale)。归一化的优点如下:
- 对每个特征进行归一化处理,以保持每个特征的贡献,因为有些特征的数值比其他特征高。这样我们的网络就是无偏的(对高值特征)。
- 减少了内部协方差(Internal Covariate Shift,ICS)。它是指在训练过程中,由于网络参数的变化而导致的网络激活分布的变化。为了提高训练效果,我们寻求减少内部协方差的变化。
- 在论文 How Does Batch Normalization Help Optimization? 中,作者称Batch Norm使损失平面更平滑(即它对梯度的大小约束得更严格)。
- 使优化速度更快,因为归一化不允许权重到处爆炸,而把它们限制在一定范围内。
- 归一化的一个非预期的好处是,它有助于网络应用正则化(Regularization)(只是略微的,并不明显)。
正确的归一化可以成为让你的模型有效训练的关键因素,但这并不像听起来那么容易。
让我们举个例子,假设一个输入数据集包含一列的数据,其值范围为0到10,另一列的值范围为100,000到10,00,000。在这种情况下,输入数据中包含的数字比例差异很大,在建模时将这些值作为特征组合时,最终会出现误差。这些问题可以通过归一化来缓解,通过创建新的数值并保持数据中的一般或正态分布。
Overview
在深度学习模型中有几种常用的归一化方法:
| 归一化方法 | 简介 | 优点 | 论文 | 年份 | 被引 | 作者 |
|---|---|---|---|---|---|---|
| Batch Normalization | 批量归一化是用于训练深度学习模型的流行归一化方法之一。它通过在训练阶段稳定层输入的分布,使深度神经网络的训练更加快速和稳定。这种方法主要与内部协方差(internal covariate shift,ICS)有关,其中内部协方差指的是前几层更新时引起的层输入分布的变化。为了提高模型的训练效果,减少内部协方差偏移很重要。批量归一化在这里的作用是通过增加网络层,控制层输入的均值和方差来减少内部协方差偏移。 | (1)批量归一化降低了内部协方差(ICS),加速了深度神经网络的训练。(2)减少了梯度对参数规模或其初始值的依赖性,从而提高了学习率,且没有发散(divergence)的风险。(3)批量归一化通过防止网络陷入饱和模式,使得使用饱和非线性(saturating nonlinearities)成为可能。 | Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift | 2015 | 24410(2021/1/29) | Sergey Ioffe, Christian Szegedy (Google) |
| Weight Normalization | 权重归一化是对深度神经网络中的权重向量进行重新参数化的过程,其工作原理是将这些权重向量的长度与其方向解耦(decoupling)。简单来说,我们可以将权重归一化定义为提高神经网络模型的权重可优化性的方法。 | (1)权重归一化可以改善优化问题的条件,并加快随机梯度下降的收敛速度。(2)它可以成功地应用于循环模型,如LSTMs,以及深度强化学习或生成模型。 | Weight Normalization: A Simple Reparameterization to Accelerate Training of Deep Neural Networks | 2016 | 1042(2021/1/29) | Tim Salimans, Diederik P. Kingma (OpenAI) |
| Layer Normalization | 层归一化是一种提高各种神经网络模型训练速度的方法。与批归一化不同的是,这种方法直接从隐藏层内神经元的输入之和估计归一化统计量。层归一化基本上是为了克服批归一化的缺点,如依赖小批量等。 | 通过在每个时间步长分别计算归一化统计量,可以很容易地将层归一化应用于递归神经网络。这种方法能有效稳定循环网络中的隐藏状态动态。 | Layer Normalization | 2016 | 2678(2021/1/29) | Jimmy Lei Ba, Jamie Ryan Kiros, Geoffrey E. Hinton |
| Instance Normalization | 实例归一化又称对比归一化(contrast normalization),与层归一化几乎相似。与批量归一化不同的是,实例归一化是应用于整批图像而不是单个图像。 | 这种归一化简化了模型的学习过程。实例归一化可以在测试时应用。 | Instance Normalization: The Missing Ingredient for Fast Stylization | 2016 | 1307(2021/1/29) | Dmitry Ulyanov, Andrea Vedaldi, Victor Lempitsky |
| Group Normalization | 分组归一化可以说是批量归一化的一种替代方法。这种方法的工作原理是将通道分成若干组,并在每组内计算均值和方差进行归一化,即对每组内的特征进行归一化。与批量归一化不同,分组归一化不受批量大小的影响,而且在很大的批量大小范围内其精度也很稳定。 | 在一些深度学习任务中,它有能力取代批量归一化。只需几行代码,就可以在现有库中轻松实现。 | Group Normalization | 2018 | 1031(2021/1/29) | Yuxin Wu, Kaiming He |
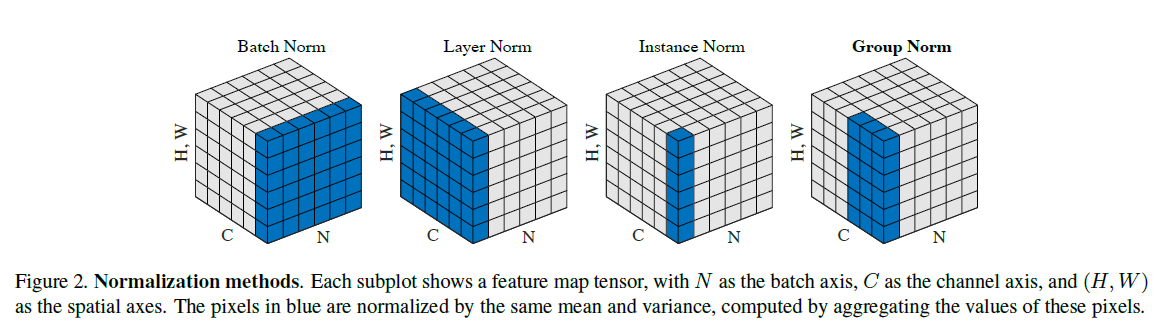

图自Group Normalization paper
其他方法:
|归一化方法| 论文| 年份| 被引| 作者|
|:–|:–|:–|:–|:–|:–|:–|
| Batch Renormalization | Batch Renormalization: Towards Reducing Minibatch Dependence in Batch-Normalized Models | 2017 | 271(2021/1/29) | Sergey Ioffe (Google) | |
| Batch-Instance Normalization | Batch-Instance Normalization for Adaptively Style-Invariant Neural Networks | 2018| 59(2021/1/29) | Hyeonseob Nam, Hyo-Eun Kim |
| Spectral Normalization | Spectral Normalization for Generative Adversarial Networks | 2018 | 1741(2021/1/29) | Takeru Miyato, Toshiki Kataoka, Masanori Koyama, Yuichi Yoshida| |
1. Batch Normalization
批量归一化是一种将网络中的激活在确定大小的小批量中进行归一化的方法。对于每个特征,批量归一化计算该特征在小批量中的平均值和方差。然后,它减去平均值并将该特征除以其小批量标准差。
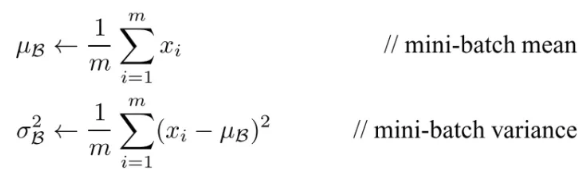
如果增加权重的大小让网络表现更好呢?为了解决这个问题,可以添加γ和β分别作为scale和shift可学习参数(下式中,ϵ是方程式中的稳定常数)。

【批量归一化的缺点】
-
可变的批量大小 → 如果批量大小为1,那么方差将为0,此时批量归一化不work。此外,如果小批量大小过小,那么它将变得过于嘈杂,训练可能会受到影响。在分布式训练中也会有问题。因为,如果是在不同的机器上进行计算,那么必须采取相同的批量大小,否则γ和β在不同的系统中会有所不同。
-
递归神经网络(RNN) → 在RNN中,每个时间步的recurrent activations会有所不同(即统计)。这意味着,必须为每个时间步长拟合一个单独的批量归一化层。这使得模型变得更加复杂和耗费空间,因为它迫使我们在训练过程中存储每个时间步的统计数据。
2. Weight Normalization
权重归一化即对层的权重进行归一化。
w = g ∣ ∣ v ∣ ∣ v w = \frac{g}{||v||} v w=∣∣v∣∣gv
它将权重向量与其方向分开,这与方差批量归一化的效果类似。唯一的区别是在变化(variation)而不是方向上。
至于均值,本文作者巧妙地将仅有均值的批量归一化和权重归一化结合起来,即使在小的小批量中也能得到理想的输出。这意味着他们减去了小批量的均值,但不除以方差。最后,他们使用权重归一化代替除以方差。注:由于有大数定律,因此与方差相比,均值的噪声要小。
3. Layer Normalization
层归一化将输入跨特征进行归一化,而不是批归一化中跨批维度对输入特征进行归一化。
一个小批量由多个具有相同数量特征的样本组成。小批量是矩阵 (或tensors),其中一个轴对应于批,其他轴(或轴)对应于特征维度。(i代表批量,j代表特征。 xᵢ,ⱼ 是输入数据的第 i,j个元素)
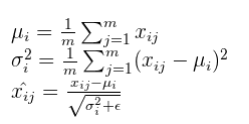
论文的作者声称,在RNN的情况下,层归一化的性能优于批量归一化。
4. Instance(or Contrast) Normalization
层归一化和实例归一化非常相似,但它们之间的区别在于实例归一化是对每个训练实例中的每个通道进行归一化,而不是对一个训练实例中的输入特征进行归一化。与批处理归一化不同的是,实例归一化层也是在测试时应用的(由于小批量的非依赖性)。
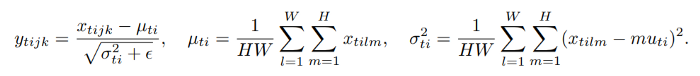
这里, x ∈ R T × C × W × H x∈ℝ^{T×C×W×H} x∈RT×C×W×H 是一个包含T批图像的输入张量。让 x t i j k x_{tijk} xtijk 表示其第 t i j k tijk tijk 个元素,其中 k 和 j 跨越空间维度(图像的高度和宽度),i 是特征通道(如果输入是RGB图像,则为颜色通道),t 是该批图像的索引。
这种技术最初是为风格迁移(style transfer)而设计的,实例归一化试图解决的问题是网络与原始图像的对比度不可知。
5. Group Normalization
顾名思义(As the name suggests),Group Normalization是对每个训练实例的通道组进行归一化。我们可以说,Group Norm介于Instance Norm和Layer Norm之间。
当把所有的通道放到一个组中时,组归一化就变成了层归一化,而当把每个通道放到不同的组中时,就变成了实例归一化。
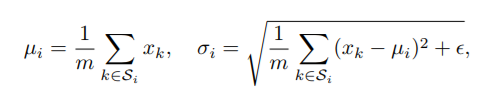
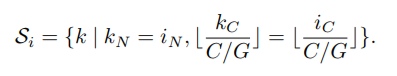
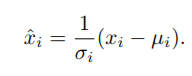
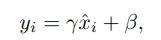
这里,x是一个层计算出的特征,i是一个索引。在二维图像的情况下,i = (iN , iC , iH, iW )是一个4D向量,按(N, C, H, W)的顺序对特征进行索引,其中N是批量轴,C是通道轴,H和W是空间高度和宽度轴。G为组(groups)数,为预先定义的超参数。C/G是每组的通道数。⌊.⌋是向下取整运算,”⌊kC/(C/G)⌋= ⌊iC/(C/G)⌋”表示指数i和k在同一组通道中,假设每组通道沿C轴按顺序存储。GN沿(H,W)轴和沿一组C/G通道计算μ和σ。
6. Batch Renormalization
批量重归一化是另一种有趣的方法,用于将批量归一化应用于小批量规模。批量重归一化背后的基本思想来自于我们在推理过程中不使用单个小批量统计量进行批量归一化。取而代之的是,我们使用的是小批量统计数据的移动平均数(moving average of the mini batch statistics)。这是因为移动平均数与单个小批量相比,能更好地估计真实的均值和方差。
7. Batch-Instance Normalization
Instance normalization的问题在于它完全抹去了风格信息。虽然,这有它自己的优点(比如在风格迁移中),但在对比度很重要的情况下(比如在天气分类中,天空的亮度很重要)可能会有问题。Batch-instance normalization试图通过学习每个通道©应该使用多少风格信息来解决这个问题。
Batch-Instance Normalization只是批处理归一化和实例归一化之间的插值。(ρ的值在0到1之间)
y = ( ρ X ^ B + ( 1 − ρ ) X ^ I ) γ + β y=(\rho\hat{X}_B + (1-\rho)\hat{X}_I)\gamma + \beta y=(ρX^B+(1−ρ)X^I)γ+β
批量实例归一化的有趣之处在于,平衡参数ρ是通过梯度下降学习的。
从批实例归一化中,我们可以得出结论,模型可以学习使用梯度下降来自适应地使用不同的归一化方法。
8. Spectral Normalization
光谱归一化将权重矩阵按其光谱范数或 ℓ 2 \ell_2 ℓ2 范数进行归一化: W ^ = W l ∣ W ∣ 2 \hat{W}=\frac{W}{l\vert W\rvert_2} W^=l∣W∣2W。实验结果表明,光谱归一化以最小的额外调整改善了GANs的训练。
∣ W ∣ 2 = max h ∣ W h ∣ 2 ∣ h ∣ 2 = max h ∼ ∣ h ∣ 2 = 1 ∣ W h ∣ 2 ∣ h ∣ 2 = σ 1 ( W ) \lvert W\rvert_2 = \max_h{\frac{\lvert Wh\rvert_2}{\lvert h\rvert_2}} = \max_{h\sim \lvert h \rvert_2 = 1}{\frac{\lvert Wh\rvert_2}{\lvert h\rvert_2}} = \sigma_1(W) ∣W∣2=hmax∣h∣2∣Wh∣2=h∼∣h∣2=1max∣h∣2∣Wh∣2=σ1(W)
注意 W ∈ R M × ( N W H ) W \in \mathbb{R}^{M\times(NWH)} W∈RM×(NWH)是权重张量 W ∈ R M × N × W × H W \in \mathbb{R}^{M\times N\times W\times H} W∈RM×N×W×H的2D表示,其中 M M M是输出通道数, N N N是输入通道数。
9. Switchable Normalization
从上面理解,可能会产生一个问题:可以随时切换归一化技术吗?答案是可以。下面的技术正是这样做的。
论文 Do Normalization Layers in a Deep ConvNet Really Need to Be Distinct? 提出了开关归一化,这是一种使用批归一化、实例归一化和层归一化的不同均值和方差统计量的加权平均值的方法。作者表明,开关归一化在图像分类和对象检测等任务上有可能优于批量归一化。
论文显示,实例归一化更多地被用于早期的层,批归一化更倾向于在中间,而层归一化更多地被用于最后。较小的批处理规模导致更倾向于层归一化和实例归一化。
参考:
Understanding Normalisation Methods In Deep Learning
Normalization Techniques in Deep Neural Networks
An Overview of Normalization Methods in Deep Learning
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/219979.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
