大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
序言,关于cap
CAP是分布式系统中的一个特别重要的理论。
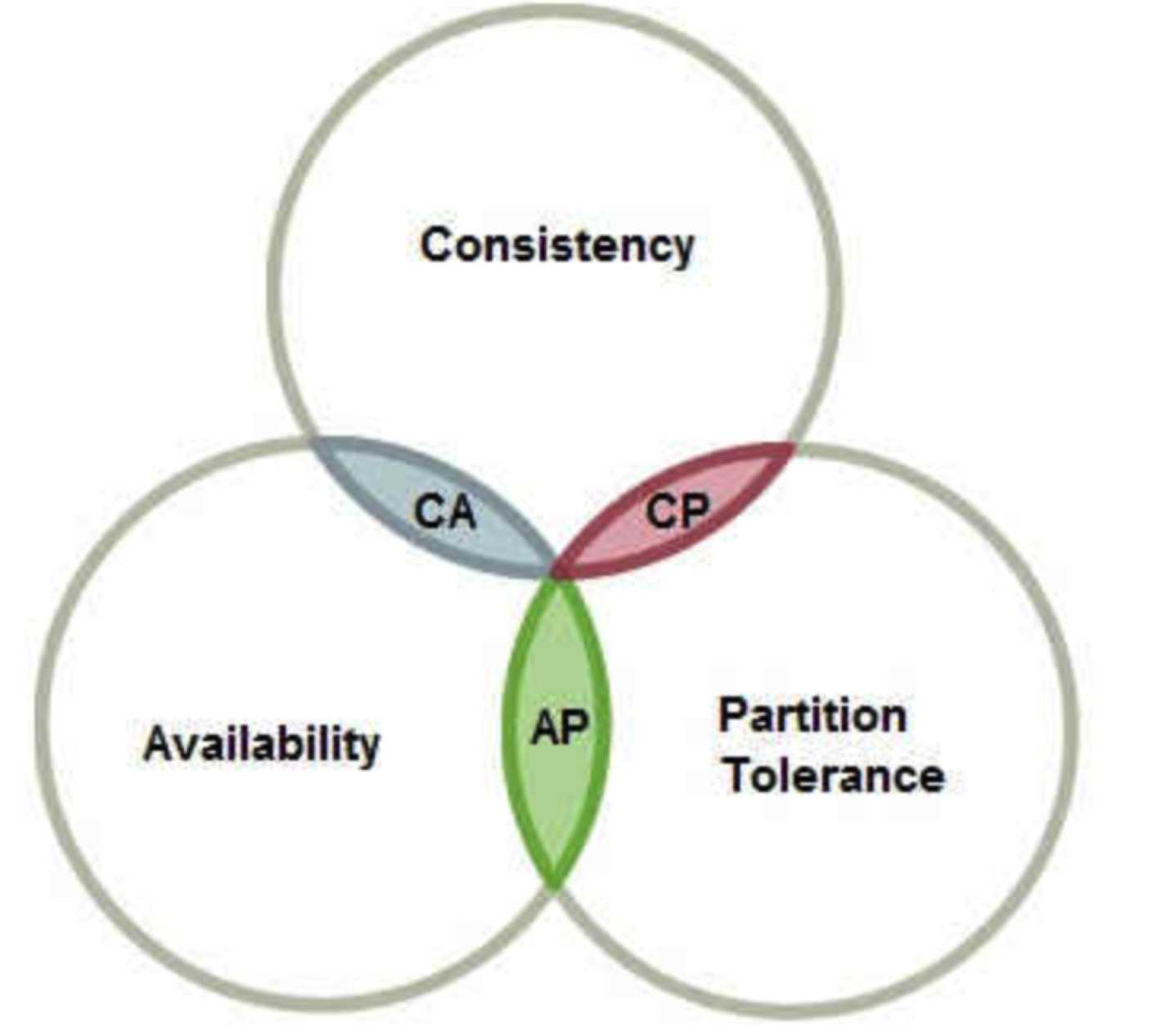

CAP原则又称CAP定理,指的是在一个分布式系统中, Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性),三者不可得兼。CAP是NOSQL数据库的基石。
分布式系统的CAP理论:理论首先把分布式系统中的三个特性进行了如下归纳:
- 一致性(C):在分布式系统中的所有数据备份,在同一时刻是否同样的值。(等同于所有节点访问同一份最新的数据副本)
- 可用性(A):在集群中一部分节点故障后,集群整体是否还能响应客户端的读写请求。(对数据更新具备高可用性)
- 分区容忍性(P):以实际效果而言,分区相当于对通信的时限要求。系统如果不能在时限内达成数据一致性,就意味着发生了分区的情况,必须就当前操作在C和A之间做出选择。
关于分区容错性,需要解释一下:所谓分区指的是网络分区的意思,详细一点解释,比如你有A B两台服务器,它们之间是有通信的,突然,不知道为什么,它们之间的网络链接断掉了。那么现在本来AB在同一个网络现在发生了网络分区,变成了A所在的A网络和B所在的B网络。所谓的分区容忍性,就是说一个数据服务的多台服务器在发生了上述情况的时候,依然能继续提供服务。
如果不能满足p,就不能再网络分区的情况下保证服务,那么就是单个节点的情况,和分布式系统的设计初衷是背离的。所以讨论cap是,一般都是满足p的前提下,来选在满足a还是满足c。
如果满足C,即所有节点都需要有相同的数据,如果没有就不可服务,满足不了A;
如果满足A,即服务可以一直存在,那么在节点故障等场景下,就满足不了C。
BookKeeper是满足CP特性的分布式系统,并且同时提供了较高的可用性,下文会有论述。
BookKeeper是企业级的存储系统,提供强持久性、一致性和低延迟的保证。最初起源于Yahoo!,用来解决HDFS NN的单点问题。2011年作为ZooKeeper的子项目在Apache孵化,2015成为顶级项目。
BookKeeper
一个企业级、实时的存储平台需要满足一下要求:
- 读写低延迟(< 5ms)
- 数据存储要持久、一致并且支持容错
- 对写入数据提供流式传播或者tail传播的功能
- 高效的存储,可以提供对实时数据以及历史数据的访问
BK是一个可扩展、支持容错并且可以保证低延迟的存储服务。满足了以上的要求,适用于很多场景:
- 为分布式存储提供高可用/副本机制(HDFS NN,Manhattan(KV store in Twitter))
- 在单个集群或者多个集群之间提供复制功能
- 为订阅/发布系统提供存储能力(EvnentBus in Twitter and Apache pulsar)
- 为流式作业存储不可变对象(比如checkpoint 数据快照)
BK概念和术语
Records(Entry)
数据在BK以record的形式而非bytes的形式写入BK。Record是最小的I/O单位,也是地址单元。每个record都包含了一个序列号(单调递增的long性数)。Client从某一个record开始读取数据,或者tail一个序列,即监听添加到log的下一个record。可以单条或者批量接收record。序列号也可以用来随机检索record。
Entry除了包含写入bookie的实际数据之外,还包含一些元数据信息
| 字段 | 说明 | 类型 |
|---|---|---|
| Ledger Number | Entry写入的ledger ID | long |
| Entry number | Entry的唯一ID | long |
| Last confirmed (LC) | 最后记录的Entry ID | long |
| Date | 数据 | byte[] |
| Authentication code | 鉴权数据 which includes all other fields in the entry | byte[] |
Logs(BK的存储)
BK为提供了两种存储原语:
- ledger,即 log segment
- stream ,即 log stream
一个Ledger是数据records的序列,ledger在客户端显式的关闭或者writer写入失败时终止。一旦一个ledger 终止以后,就不能append记录。ledger是最底层的存储原语,可以用于存储有限的序列或者无限的流。
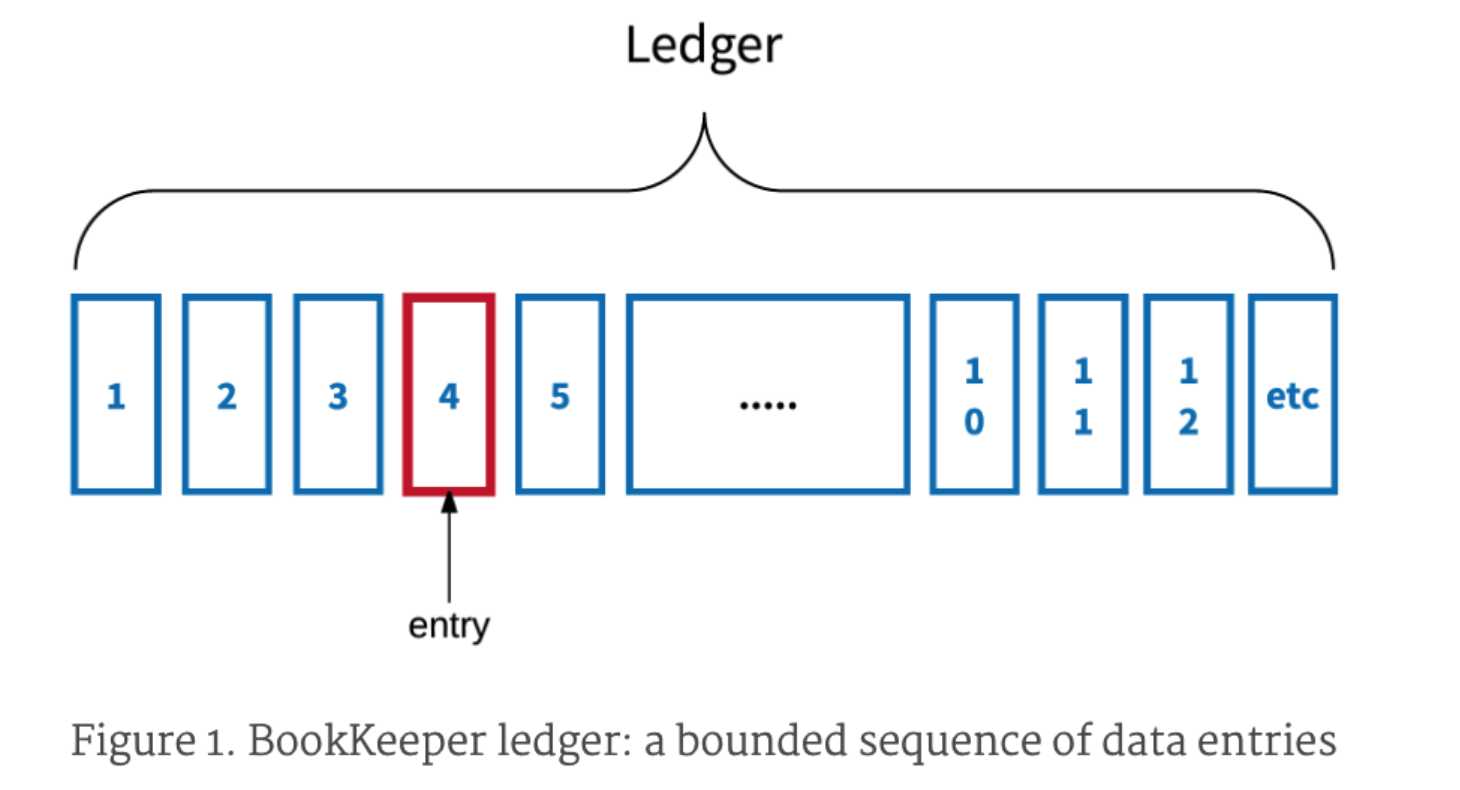
Ledgers是entry的序列,Entry是bytes序列。Entry写入ledger时,是
- 顺序的
- at most once
ledgers支持 append-only的语义。Entry写入到ledgers之后,就不可以被修改了。Client应用决定写入的顺序。
一个stream是无界的,无限的record序列。Leger可以被打开多次来append record。一个stream物理上会有多个ledger组成,每个ledger会根据时间或者空间滚动策略来滚动。stream会存在很长时间,所以保留数据策略是truncating,会根据时间或者空间策略来丢弃老的数据。
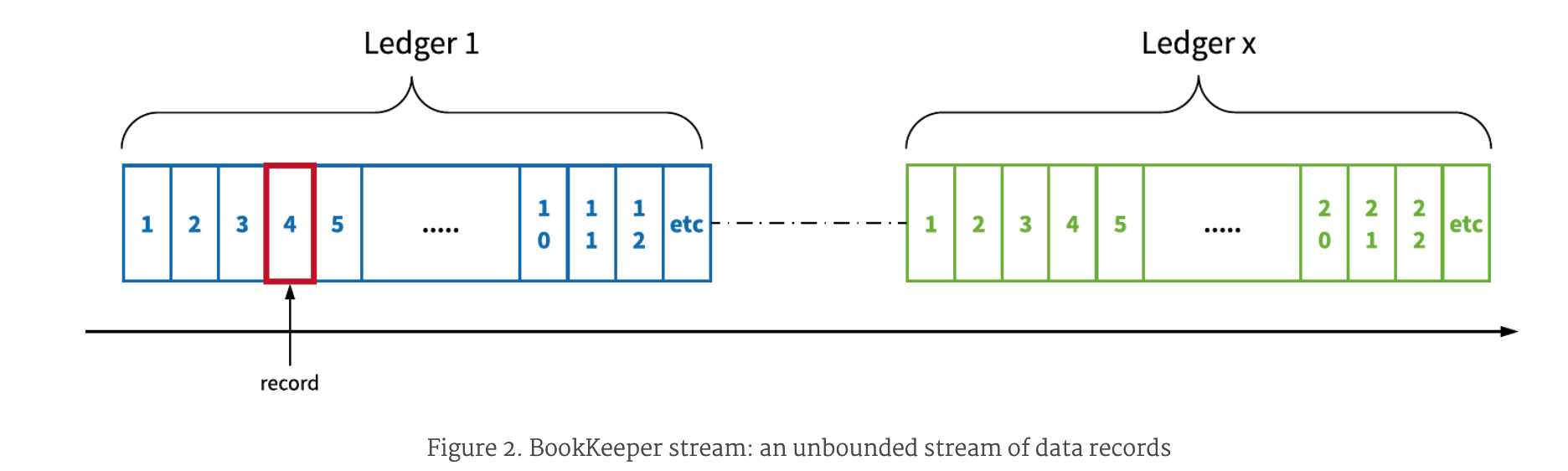
ledge和stream为历史数据或者实时数据提供了统一的存储抽象。Log streams提供了数据tail或者stream能力。实时数据存储在ledger中,随着时间会变成历史数据。
NameSpackes
Log stream通常在namespacke下分类、管理。NameSpace是租户创建流时会使用到的一种机制。一个namespace是数据存储策略的部署和管理单元。在同一个namespace下的所有stream继承相同的配置,数据存储在存储策略配置的存储节点上。可以方便的管理过个stream。
Bookie
BK在多个server之间备份存储数据entry,这些server成为Bookie。Bookie是个独立的Bk存储服务。
Bookies是处理ledgers(更具体一些,是ledger的片段)的server。Bookies作为ensemble的一部分起作用
一个bookie是一个独立的BookKeeper存储服务。出于性能的考虑,Bookie储存ledger的片段,而不是真个ledgers。对于任意的一个ledger, ensemble是存储这个ledger entries的bookies组。entry写入ledger时,会在ensemble中进行条带化的存储。
向ledger写入entry时,entry会被条带化到ensemble中(bookie的子集不是全部)。
Metadata
BK的元数据主要是可用的BK以及ledger信息。使用ZK存储。
与BookKeeper交互
BookKeeper客户端主要有两个角色:创建和删除ledgers,向ledgers写入或者从ledgers中读取entry。
主要两种方式和BK交互:
- 创建ledger或者stream来写数据
- 打开ledger或者stream来读数据
BK提供了两种API:
- ledger API: 底层API,可以直接操作ledger,比较灵活。
- Stream API: higher-level面向流的API,通过Apache DistributedLog提供,直接操作流,不用关心与ledger交互的复杂性。
选择哪种API,应该基于应用对于ledger的控制粒度。两种API可以在应用中共同使用。
BookKeeper 框架图
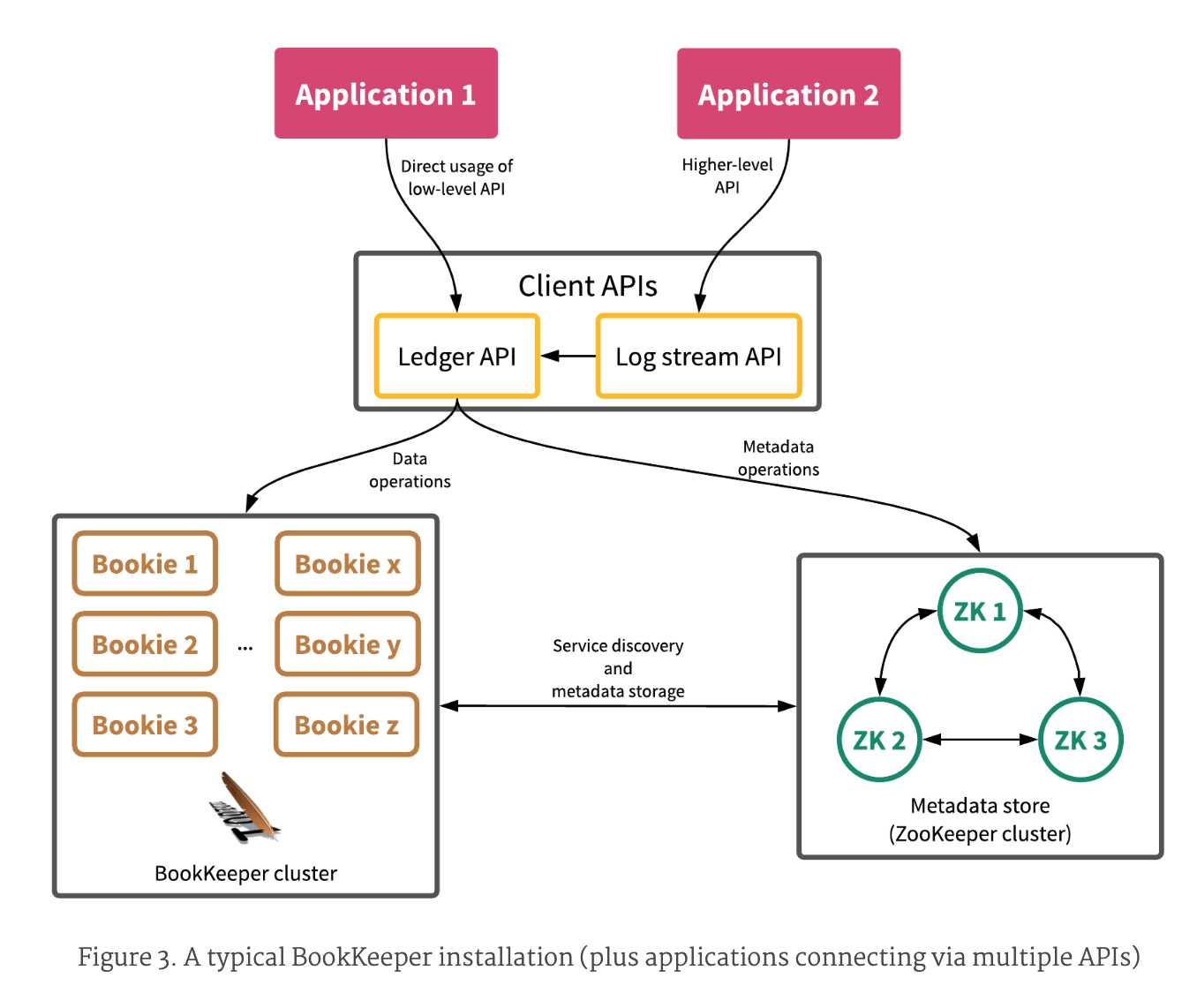
注意:
- BK的典型安装会包含:Metadata store,bookie cluster,多个cilent
- Bookie自己向metadata store注册自己
- Bookie在进行GC来清理数据时需要和metadata store交互
- 应用程序使用Client lib来和BK交互
- 使用Ledger API获取细粒度的管控
- 不需要底层ledger控制,则使用stream api
BookKeeper提供的保证
前文中提到了一个实时储存系统需要满足的一些要求,总结如下:
| Guarantee | Description |
|---|---|
| Replication | 数据在多台机器上都有持久存储的副本存在 |
| Durability | 数据写入时,在ack之前需要写fsync到磁盘 |
| Consistency | 提供 repeatable read的一致性 |
| Avaliablity | 写:ensemble可以切换;读:提供了speculative read |
| Low Latency | 读写I/O隔离 |
Replication
BK会为每个记录都复制并且存储几个独立的备份,通常是3或者5,备份可以位于相同或者不同数据中心。不同于其他的HA系统,使用了主/备复制或者流水线的算法来同步数据,BK使用 quorum-vote parallel replication algorithm,这种算法保证了可预测的数据复制延迟。下图描述了BK内部的数据复制:
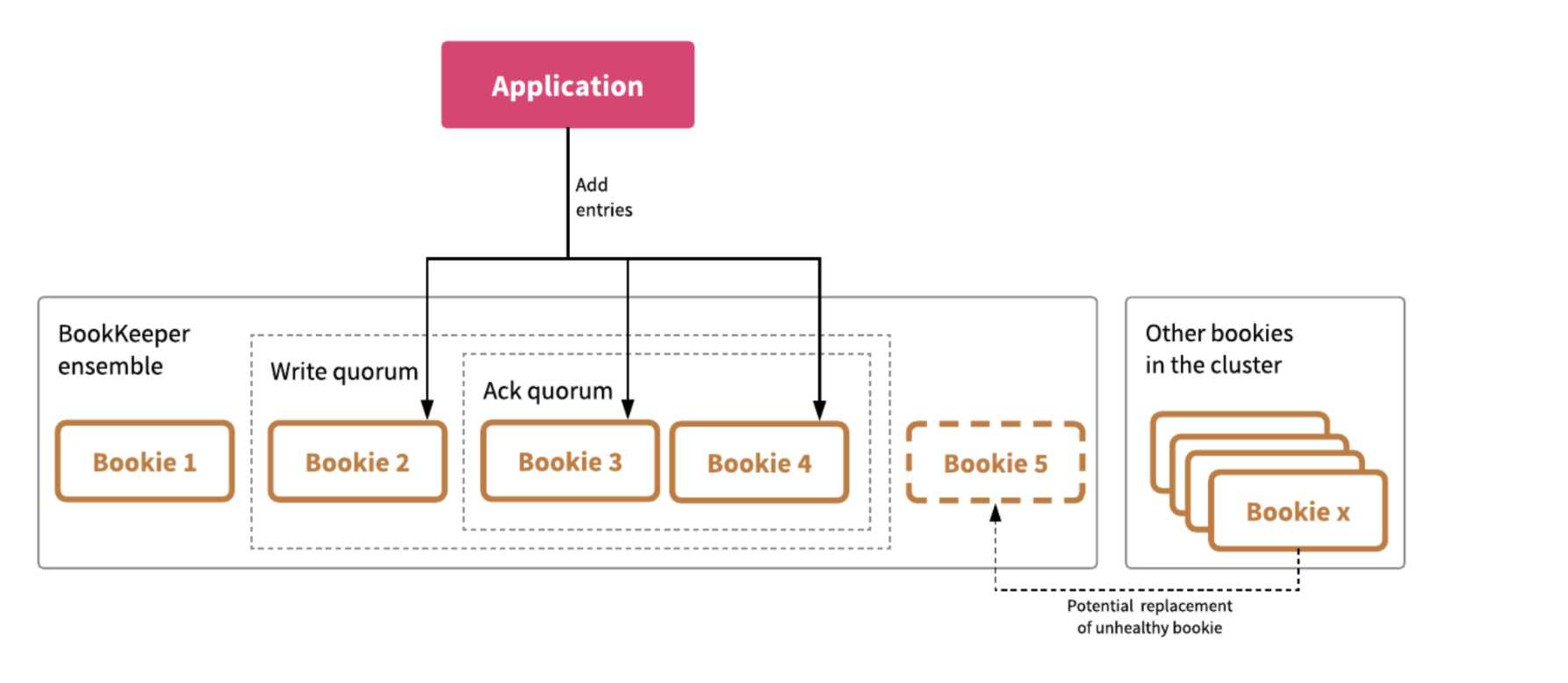
上图中:
- 从BK集群中选取bookie集合。这个集合作为ledger存储记录的 ensemble。
- Ledger的record条带化的存储在ensemble的bookie上。也就是说,么个record都会存储在一定数量的副本上。这个数量,可以通过client配置,成为write quorum size。上图中的quorum是3, record会写到bookie 2,3,4上。
- 当一个client写如数据到ensemble时,client会等待一定使用量的ack。Ack的数量成为ack quorum size。当ack的数量达到要求时,客户端才会认为写入操作成功。上图中的ack quorum是2,即客户端收到2个ack即可认为数据写入成功。
- Ensemble在bookie失败时会有变更。失败的bookie会被替换掉。比如bookie x替换掉bookie5。
Replication: core ideas
BK复制的核心思想:
- Log stream是面向record的,而不是面向bytes的。即数据总是以不可分割的record的形式存在,而不是字节数组。
- Log stream 中record的顺序和实际副本中存储的record的顺序是解耦的(实际日志文件是多个ledger共享的,record写入日志之前会根据多个ledger排序,排序之后写入文件)
这两个原则使得 BookKeeper replication 可以:
- 提供写record到bookie的多种选择,只要BK有足够的容量就可以保证即使在许多bookie宕机或者响应慢的情况下依然可以写入成功,这是会涉及到ensemble的变更
- 通过增加ensemble的大小,增加单个Log stream的带宽,一个单独的log就不会限制到一台或者几台机器上。可以通过配置ensemble大小大于write quorum size来实现。
- 可以通过调整ack quorum大小的值来提升延迟性能,这个配置在保证一致性和持久性的前提下获取低延迟的关键。
- 通过many-to-many的复制恢复提供快速的re-replication (re-replication 为under-replicated(小于write quorum size)状态的record创建 more replicas ). 所有的bookie都可以作为record副本的提供者和接收者。
Durability
每个数据record写入BK时,都会保证被复制并且持久的存储在一定数量的bookie上。这种保证是通过显式的disk fsync和写入确认来实现的。
- 在单个bookie上,data record在ack之前会被显式的写入磁盘(fsynced)。
- 在一个集群内,为了容错,数据record会被复制到多个bookie上。
- 数据record只有在客户端收到一定数量(配置的)bookie的响应之后才会ack。
大多数的NoSQL类型的数据库,分布式文件系统以及消息系统(比如Kafka),都假设将数据复制到多个node的易失存储/内存就已经足够满足 best-effort 持久性要求,但是这些系统允许潜在的数据丢失。BK设计用来提供更强的持久性保证,可以完全避免数据丢失。
Consistency
一致性保证是分布式系统的常见问题,尤其是在引入复制机制来提供持久性和可用性时。BK提供了一个简单但是强大的一致性保证——可重复读 :
- 如果一个record已经ack,那么这个record必须立即可读。
- 如果一个record被读过一次,那么这个record必须总是可读的。
- 如果一个record R写入成功,那么所有的在R之前的记录都是成功提交/持久化的并且是可读的。
- 数据存储的顺序对于多有的reader来讲必须都是一样的。
可重复读一致性是通过LAC协议保证的。
Availability
在一个CAP理论体系中,BK是个CP系统。实际上,即使在硬件、网络或者其他失败的情况下,BK依旧提供了非常高的可用性。BK使用了一下的机制,为了保证读写的高可用性:
| Availability type | Mechanism | Description |
|---|---|---|
| Write availability | Ensemble changes | 在bookkie出现失败时,client会重新配置写入的bookie。这就保证了在有足够的bookie时,写入总会成功。 |
| Read availability | Speculative reads | This helps spread read traffic across bookies, which has the added benefit of reducing tail read latency. 和其他的系统只从指定的leader节点读数据不一样,BK允许客户端从任何ensemble的任何一个bookie读取record。这种机制可以将读取分散到多个bookie上,相比于其他系统,在降低及时消费的延迟方面有额外的优势。 |
Low latency
强持久性和一致性保证是分布式系统中的复杂问题,尤其是要满足企业级的低延迟。BK可以完全满足这些要求:
- 在单个bookie上,bookie服务为不同的workload(写、tailing read,追赶读/随机读)类型提供了I/O隔离。Journal文件使用 group-committing mechanism 来均衡延迟和吞吐。
- quorum-vote parallel replication scheme 用来屏蔽网络故障、JVM GC停顿、磁盘慢等导致的延迟问题。这可以减少tail 延迟并且可以确保99%的可预测的低延迟。
- 一个长轮训机制来notify并且分发新写入的record给tailing readers(一旦record ack并且confirmed)。
最终,需要指出,显式的fsync带来的持久性、写入confirm以及重复读的一致性是状态处理的关键,尤其是对于流应用中的effectively-once处理。
I/O 隔离
可预测的低延迟对于实时应用来讲是非常重要的,尤其是一些关键性的在线商业服务以及数据库。以消息系统为例,在大多数的消息系统中,慢消费者会读取backlog,这就可能会造成性能降低,其原因是这些慢的消费者会读取辞旧存储介质,导致I/O抖动以及内存也的换近和换出。当写、tailing 读以及追赶读共享一个磁盘路径是,就会出现上述问题。
BK中bookie设计时为写入,tailing read以及catch-up read使用三个独立的I/O路径。写入和tailing read 要求可预测的延迟,catch-up read要求吞吐。为这几种workload提供物理隔离可以充分利用:
- 网卡入带宽和写入时的顺序写带宽
- 网卡出带宽和多块ledger磁盘读取的IOPS(input/output operations per second)
I/O隔离意味着BK可以提供多种优势并且不会妨碍其他优势。
Data distribution
构建在BK上的服务以segment ledger的形式存储log stream,这些segment会被复制到多个bookie。这样做带来了一系列的优势: 写入的高可用、负载均衡以及简化的操作体验。
首先,一个log stream的容量不会被限制到单个机器的存储容量,数据可以存储在整个集群上。
其次,扩展BK cluster时不需要log stream进行均衡。扩展BK只需要加入新的机器即可。新的bookie节点会被集群发现,然后立即写入可用。BK可以提供多种数据放置的策略,包括机架感知、区域感知以及基于权重等。
再次,有助于更快、更高效的失败恢复。当一个segment丢失(由于机器故障)或者崩溃(由于磁盘故障),BK可以确定需要修复哪一个segment(re-replicating entries to meet the replicas requirement),然后以多对多的形式并发修复。
相比于以分区为核心的系统(Kafka),BK的水平扩展具有优势的,log stream(类比于kafka的分区)顺序存储在一组机器上。扩展kafka时,需要负载均衡,这是一个资源密集、易错并且昂贵的操作。另外,partition-centric system的系统,单个机器故障或者磁盘故障都会导致复制全部的log stream。
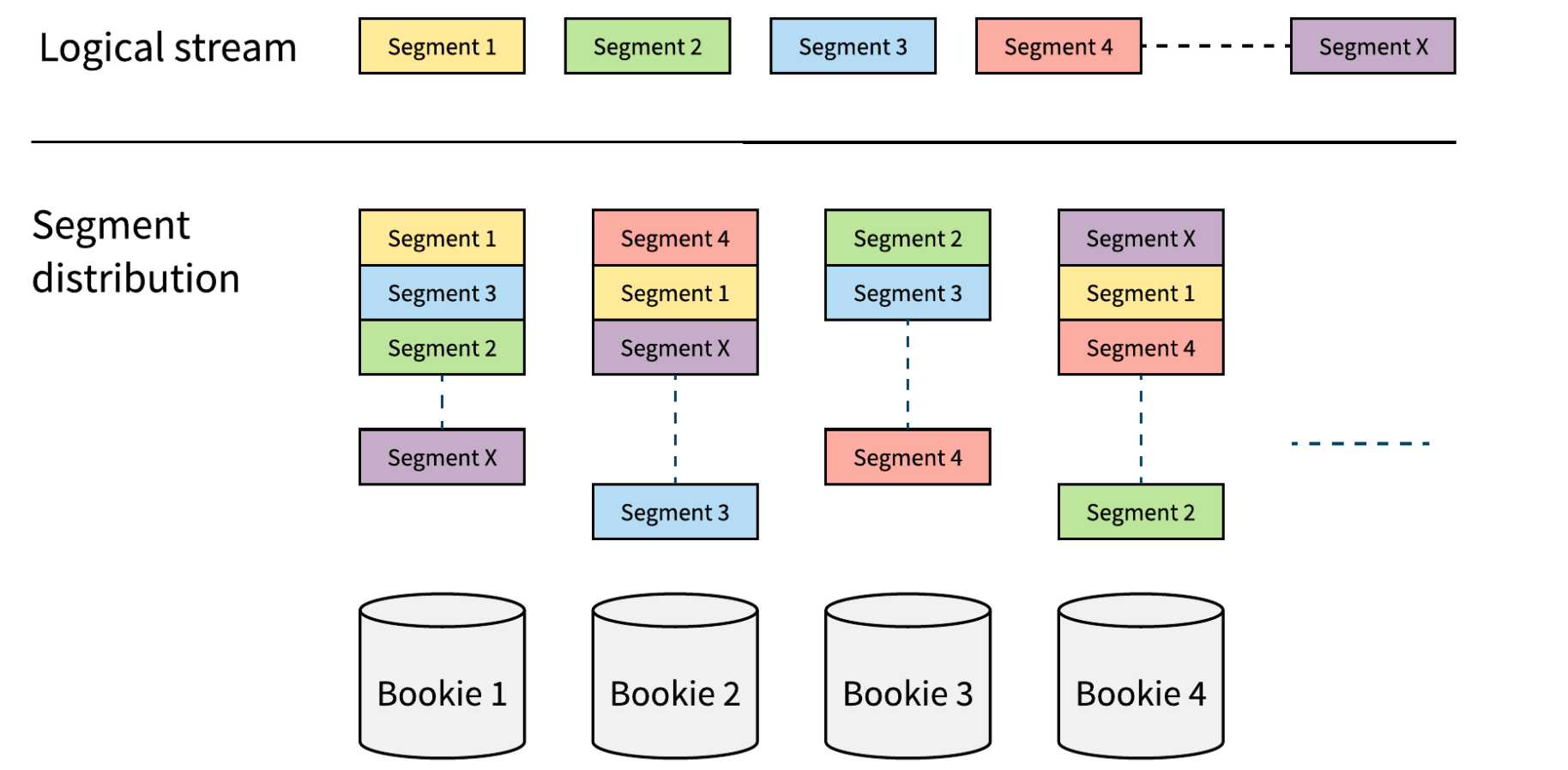
Figure 1. Log stream: 所有的log segment都会被复制到配置数量的bookie’上(这里为3),并且数据可以跨一个配置的bookie上(这里为4). Log segment 均匀的分布,因此均有水平扩展的能力,并且不需要均衡。
Scalability
作为一个实时的log stream存储,当负载增加或者愈来愈多的数据写入时,扩展性是十分重要的。BK的扩展性主要有一些因素决定:
Number of ledgers/streams
Stream的扩展性是指BK可以支撑大量的log stream, 几百到几百万个ledger,并且可以保证一致性。获取这种特性的关键是数据的存储格式。如果ledgers存储在独立的文件,在刷盘时,就会导致I/O分散在磁盘上。BK按照一种交替的格式存储数据,不同的ledger或者stream的数据会汇聚,然后存储在一个大文件中并且会做索引。这样降低了文件数量以及I/O操作,是的BK可以支撑大量的ledger或者stream。
Number of bookies
Bookie扩展性是通过增加bookie数量来支撑快速增长的流量。BK之中,bookie之间不会有直接的交互。这就允许BK通过增加机器就可以扩展集群,并且当超过了I/O带宽之后,也不需要数据均衡。这就允许BK集群在扩展时可以不用考虑数据的分布。Yahoo和Twitter的BK单个集群拥有10w+节点。
Number of clients
Client扩展性是指 log stream 存储支持大量并发client和大量扇出。通过以下要点实现:
-
client和server都是Netty做异步的网络I/O。所有的网络I/O都是复用一个tcp链接下,并且都是异步的。这样提供了一个十分高效的流水线和十分高的吞吐,并且资源消耗较少。
-
数据会复制到多台bookie上,多个bookie上的数据保持一致性。和Kafka等其他系统从leader 几点读取数据不一样,BK client可以从任意的bookie副本上读取数据,可以获取高吞吐以及读负载的分布。
-
因为client可以从任意的bookie副本读取数据,应用可以配置一个较高的副本数量来获取更高的读取性能。
Single stream throughput
应用程序可以通过增加stream数量或者bookie数量的方式来增加吞吐。另外,BK可以通过增加ensumble的大小来为单个stream增加吞吐。这对于那些需要保证数据顺序的有状态应用很有用。
Operational simplicity
BK设计为操作简单的。可以在系统运行时通过添加bookie的方式扩展容量。如果一个bookie不可用,其上的所有entries都被标记为under replicated,然后BK会自动从其他的可用的副本上将数据复制到新的bookie上。BK提供对于bookie的只读模式。在一些特定的场景下,bookie自动切换到只读模式,比如:磁盘满,磁盘损坏等。只读bookie不再接受写入,但是可以提供读服务。
另外,BK提供多种方式来管理集群:使用管理员 CLI 工具,使用 Java admin library 或者使用 HTTP REST API。REST API 可以用于实现外部工具。
Security
BK提供了一个可插拔的鉴权机制。BK也可以配置支持多种鉴权机制。一个鉴权 provider 会创建客户端的identity,然后为client分配一个identifier(标识符),这个标识复用来决定client的那种操作是被授权的。BK模式提供两种鉴权机制:TLS和SASL(Kerberos)。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/219217.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
