大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
Hadoop集群搭建(超级超级详细)
1、集群规划
安装VMware,使用三台 Ubuntu18.04 虚拟机进行集群搭建,下面是每台虚拟机的规划:
| 主机名 | IP | 用户 | HDFS | YARN |
|---|---|---|---|---|
| hadoopWyc | 待定 | wyc | NameNode、DataNode | NodeManager、ResourceManager |
| hadoopWyc2 | 待定 | wyc | DataNode、SecondaryNameNode | NodeManager |
| hadoopWyc3 | 待定 | wyc | DataNode | NodeManager |
2、网络配置
我首先在VMware中新建一台8G内存(安装Ubuntu默认系统的内存就可以了),20G硬盘空间的Ubuntu虚拟机。新建完成后进行下面操作。
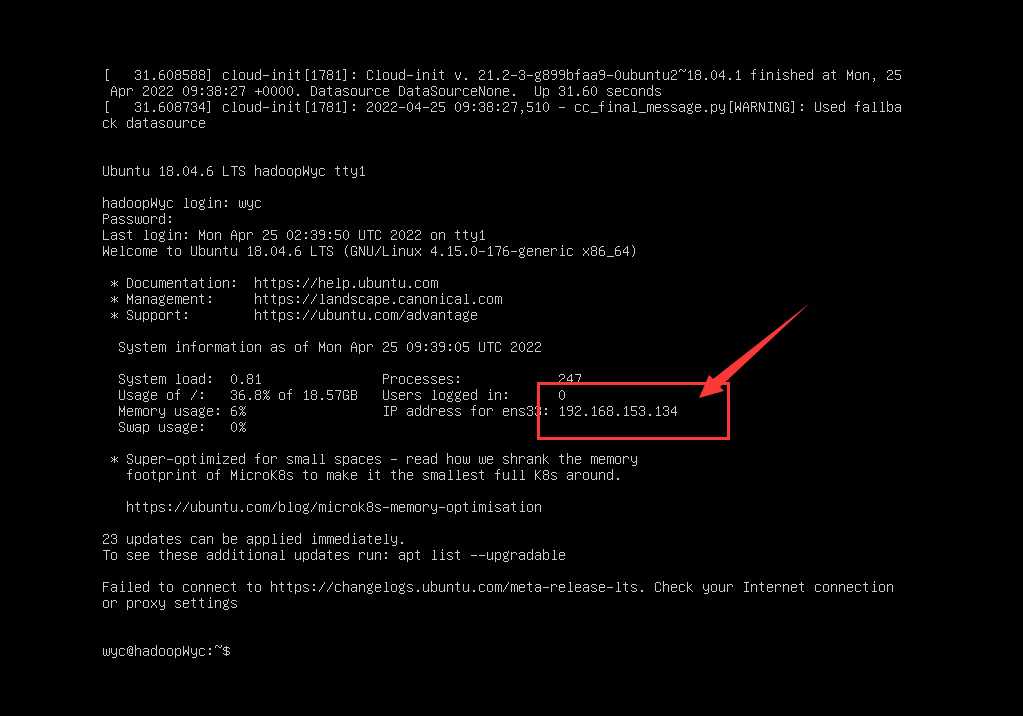

普通用户登录后请记住这个IP地址,后面需要用到!!!
先登入root用户,后面都在root用户下操作。
su root #登入root用户
还没设置root用户密码的参考 Ubuntu18.04设置root密码(初始密码)
2.1 修改主机名
vim /etc/hostname #修改文件
执行上面的命令打开“/etc/hostname”这个文件,将其中内容删除,并修改为“hadoopWyc”(你们可以根据你们需要修改想要的主机名),保存退出vim编辑器,重启Linux即可看到主机名发生变化。
2.2 查看虚拟机网络信息
2.2.1 点击VMware的编辑里的虚拟网络编辑器
2.2.2 选择VMnet8网络,点击NAT设置
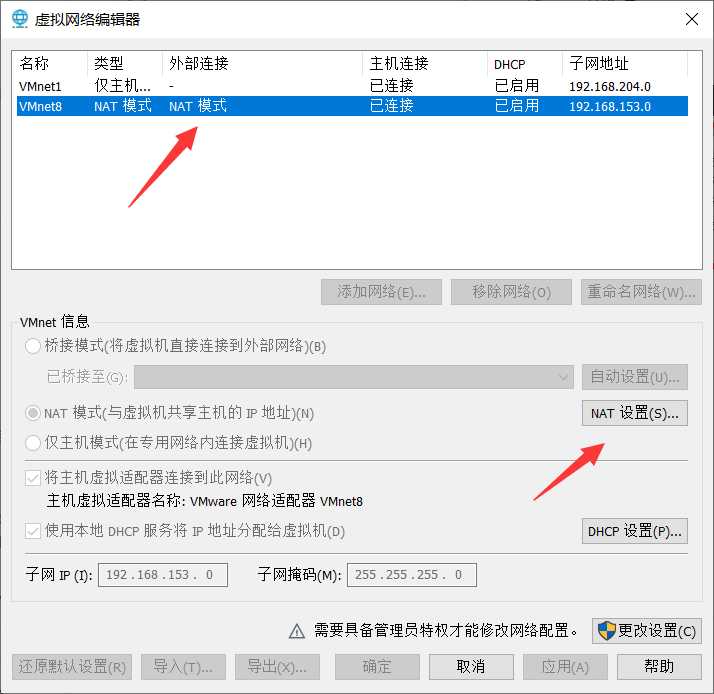
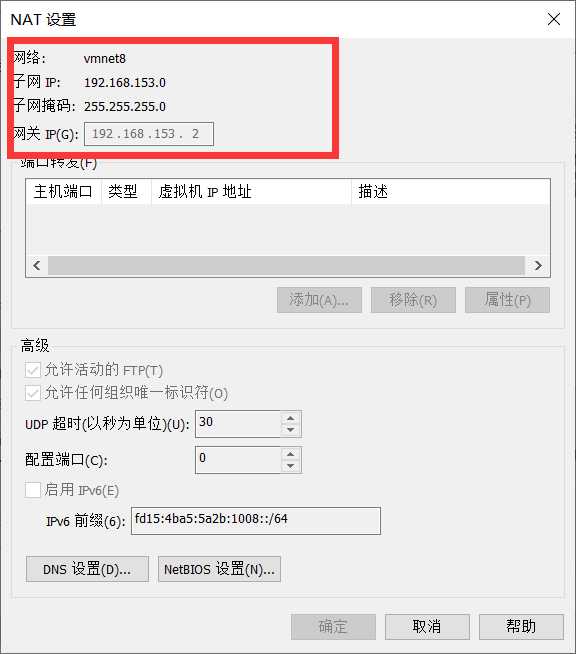
记录上面图中子网掩码、网关,加上前面的IP地址三个属性,这些在后面的步骤有用,不同的电脑会有不同。
2.2.3 获取Ubuntu虚拟机的网卡编号
ifconfig
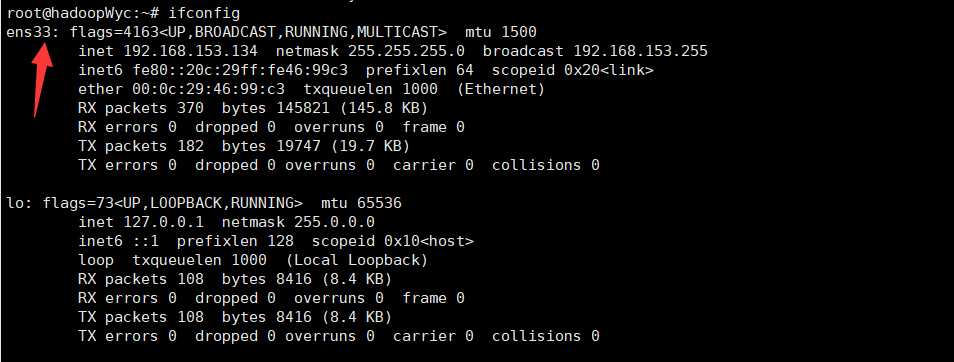
2.2.4 设置静态网络
vim /etc/network/interfaces
在原有的内容上添加
auto ens33 # 网卡编号,我这里是ens33
iface ens33 inet static # 设置为静态IP
address 192.168.153.136 # 该机器的IP,就是我们登录后显示的那个IP 地址
netmask 255.255.255.0 # 子网掩码,刚才获取VMware的子网掩码
gateway 192.168.153.2 # 网关,也是刚才获取的网关
dns-nameserver 192.168.153.2 # DNS,和网关一样即可
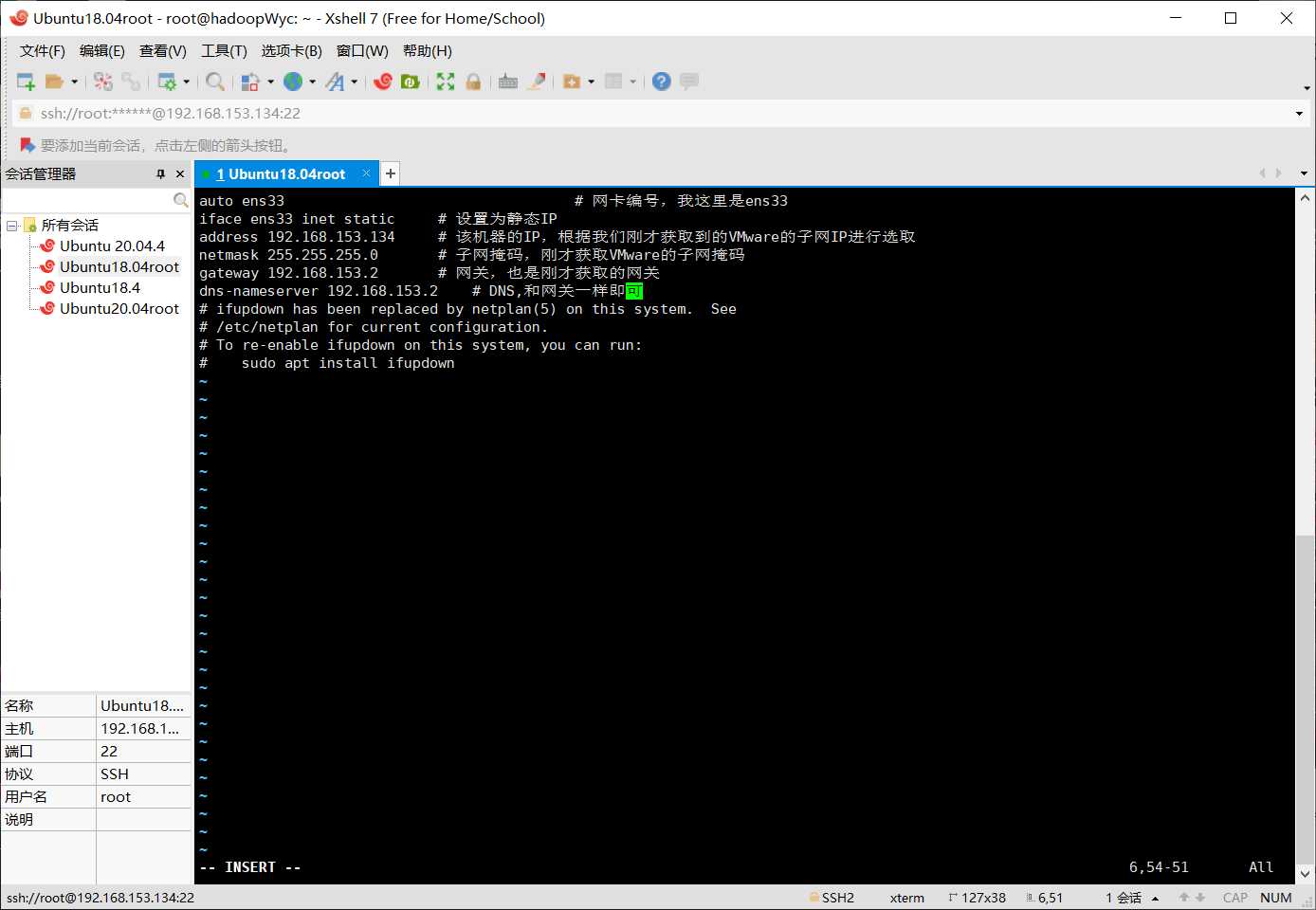
上面的内容根据各自的电脑进行设置,一定要和VMware中的子网IP、子网掩码、网关保持一致,不然会上不了网。保存退出vim编辑器,重启Ubuntu即可生效。
3、安装 ssh 服务端
apt-get install openssh-server
安装虚拟机时有勾选安装ssh的会和下图一样,继续往下做就行了

安装后,使用下面命令登录本机:
ssh localhost
补充:ssh localhost = ssh <当前用户>@localhost -p 22 -i ~/.ssh/id_rsa
SSH首次登录会有提示,输入yes即可,然后按照提示输入本机密码即可。
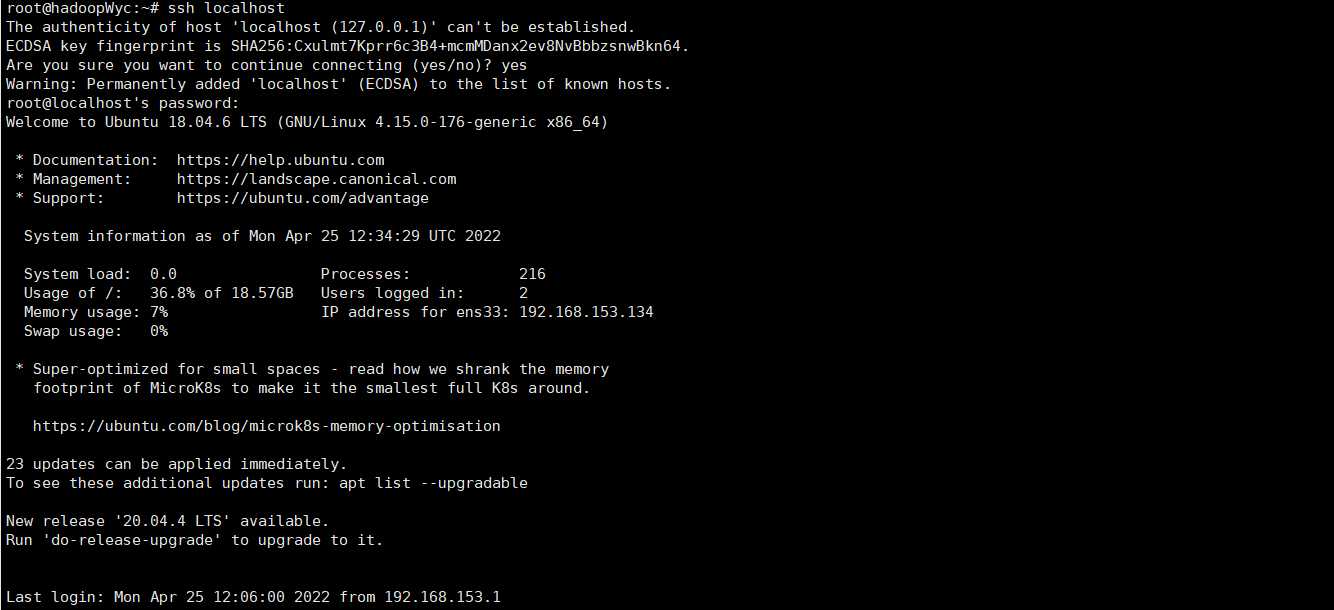
但是这样每次登录都要输入密码,现在设置SSH无密码登录。首先退出SSH,利用ssh-keygen生成密钥,并将密钥加入到授权中。
exit # 退出ssh localhost
cd ~/.ssh/
ssh-keygen -t rsa # 会有提示,都按回车就行
cat ./id_rsa.pub >> ./authorized_keys # 加入授权
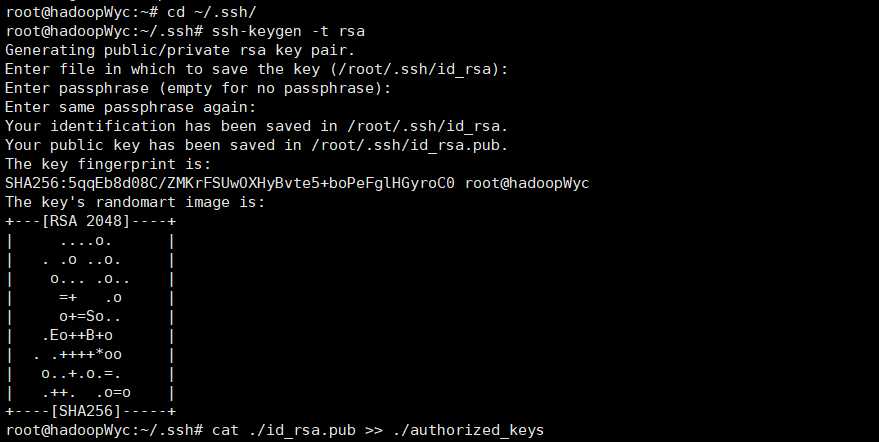
现在再使用”ssh localhost”,就可以不用输入密码登录ssh
4、安装Java环境
Hadoop3.1.3需要JDK版本在1.8及以上,点击右边链接可以下载符合版本的JDK:jdk-8u162-linux-x64.tar.gz(提取码:ik9p)。
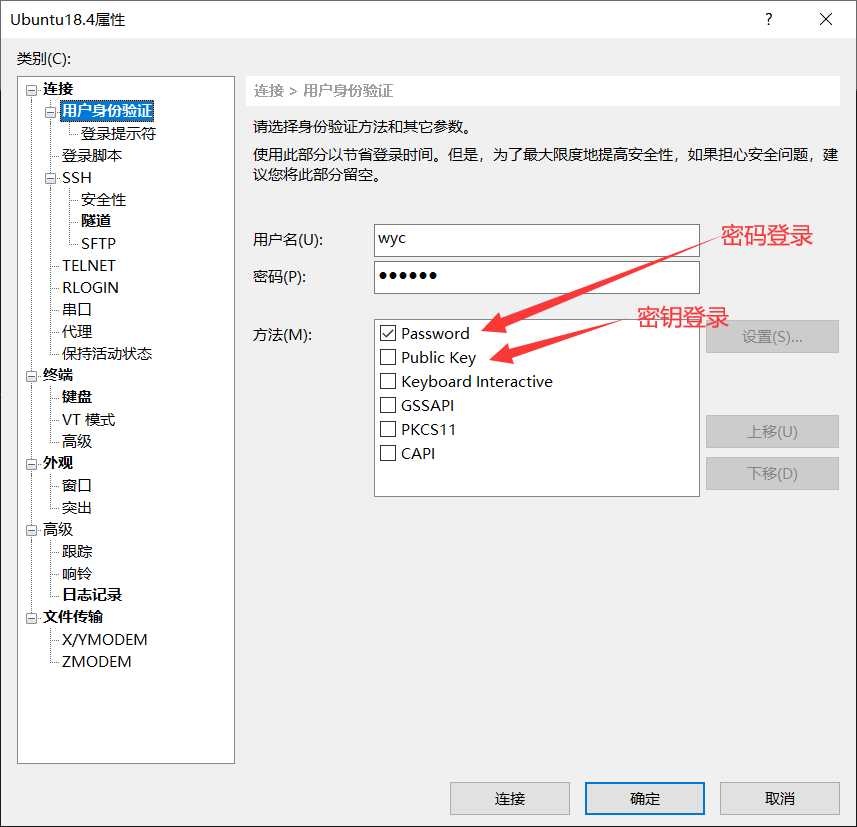
我们可以通过Xshell连接虚拟机,主机名就是刚才登录显示的那个IP地址,端口默认22,选择账户密码登录输入用户名和密码就可以登录了(如果上面没有安装开启.ssh服务,在这里会连接不上虚拟机)
点击上面绿色小图标,我们就打开了Xftp,可以直接把本地的文件传输到虚拟机
用普通用户登录Xshell的人会报错误本地文件传不到虚拟机上:
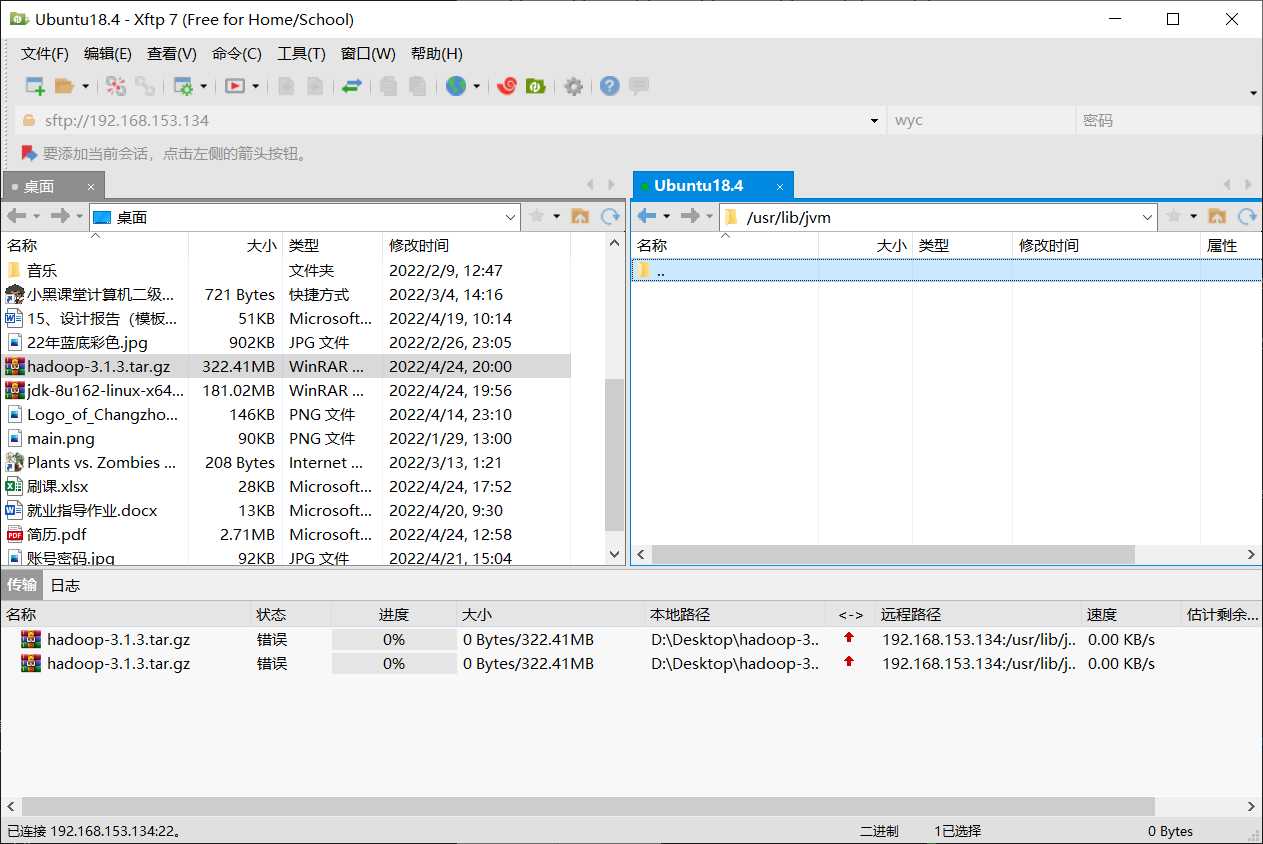
有两种解决方案:
- Xshall用root登录,再打开Xftp(这样Xftp也是root用户打开,拥有所有权限),可是Xshall用root登录虚拟机会连接不上,参考:Xshell用root用户连接Linux 可以解决
- 参考:Xftp 传文件到虚拟机一直显示状态错误,传不进去
将文件放在随便一个目录中后,执行下面命令:
cd /usr/lib
mkdir jvm # 创建目录来存放JDK文件
然后再进入 jdk-8u162-linux-x64.tar.gz 所在的文件夹解压JDK到刚才创建的 jvm 文件夹
tar -zxvf ./jdk-8u162-linux-x64.tar.gz -C /usr/lib/jvm #解压JDK到刚才创建的jvm文件夹
将JDK文件解压之后,进入/usr/lib/jvm目录下会有个jdk1.8.0_162文件,下面我们开始设置环境变量
vim ~/.bashrc
在打开的文件首部添加下面内容
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_162
export JRE_HOME=${
JAVA_HOME}/jre
export CLASSPATH=.:${
JAVA_HOME}/lib:${
JRE_HOME}/lib
export PATH=${
JAVA_HOME}/bin:$PATH
保存退出vim编辑器,执行下面命令让.bashrc文件的配置生效:
source ~/.bashrc
接下来使用下面命令查看是否安装成功:
java -version
如果如下面一样有显示java的版本信息,则表示安装成功:

5、安装Hadoop3.1.3
hadoop-3.1.3.tar.gz (提取码: x2vu)可以在这点击下载,将其下载并上传到相应的位置上,使用下面命令安装,也要和安装Java一样给文件夹权限:
tar -zxvf hadoop-3.1.3.tar.gz -C /usr/local # 解压到/usr/local中
cd mv ./hadoop-3.1.3/ ./hadoop # 将文件名改为hadoop
sudo chown -R rmc0924 ./hadoop # 修改权限,当前是什么用户登录,就给他赋予用户的权限
解压后使用下面命令看是否安装成功,安装成功会显示Hadoop的版本信息。
cd /usr/local/hadoop
./bin/hadoop version
如图所示:

6、克隆虚拟机
经过上面步骤,名称为hadoopWyc的Ubuntu已经配置完成,现在退出该虚拟机。将该虚拟机克隆出另外两台虚拟机,分别命名为hadoopWyc2和hadoopWyc3。
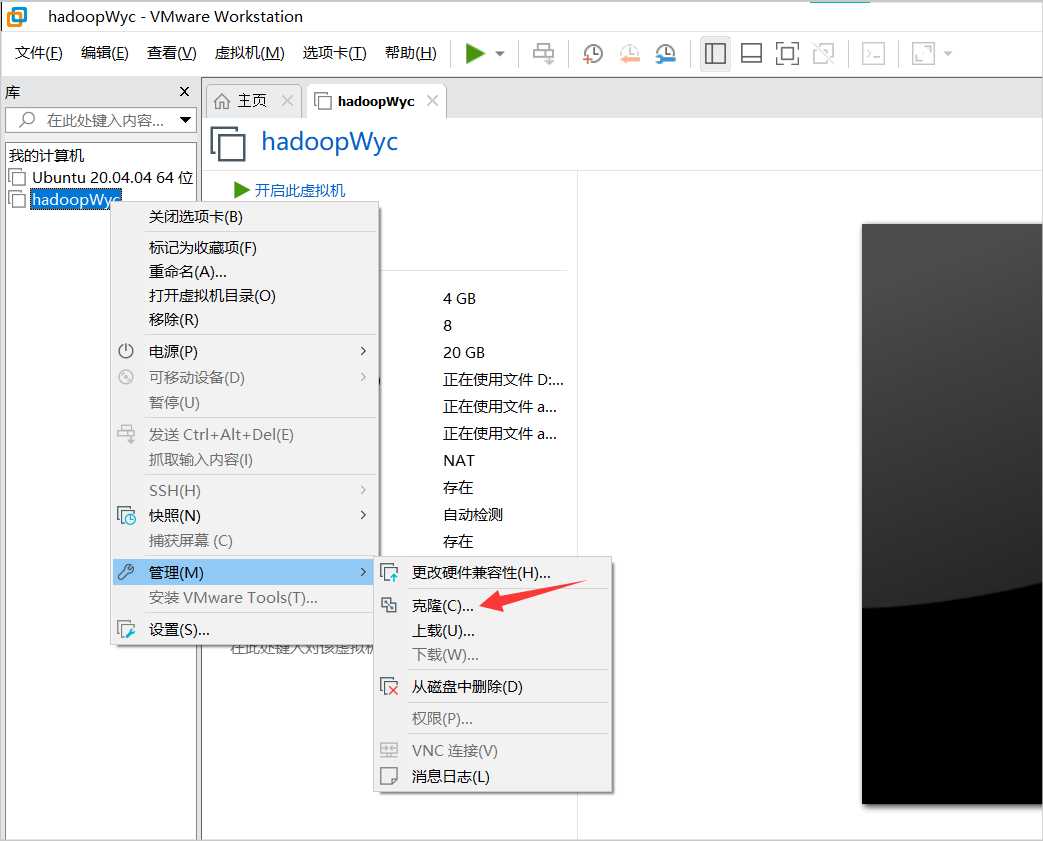
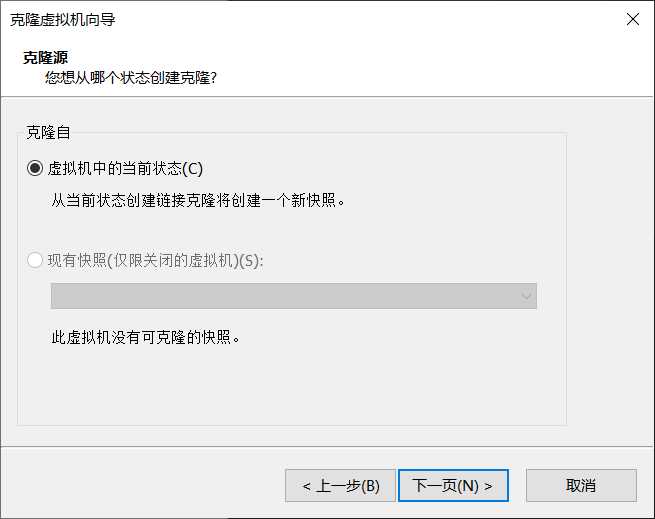
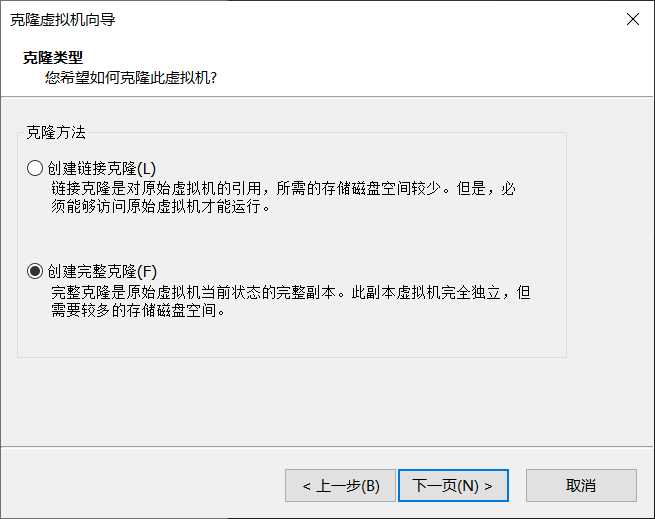
在后面的提示框中依次选择“虚拟机中的当前状态”、“创建完整克隆”、对克隆的虚拟机命名、选择位置,等待克隆完成。
最后的虚拟机如下所示:
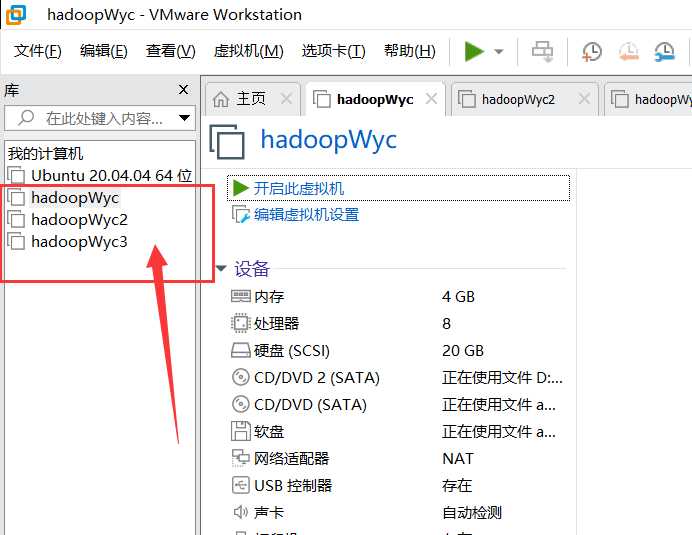
将hadoopWyc2和hadoopWyc3两台虚拟机按照2.1和2.2中步骤,修改主机名以及各自的静态IP,备用。最后我们可以把最初的那张表补全:
| 主机名 | IP | 用户 | HDFS | YARN |
|---|---|---|---|---|
| hadoopWyc | 192.168.153.136 | wyc | NameNode、DataNode | NodeManager、ResourceManager |
| hadoopWyc2 | 192.168.153.137 | wyc | DataNode、SecondaryNameNode | NodeManager |
| hadoopWyc3 | 192.168.153.138 | wyc | DataNode | NodeManager |
7、三台虚拟机都加上主机IP映射
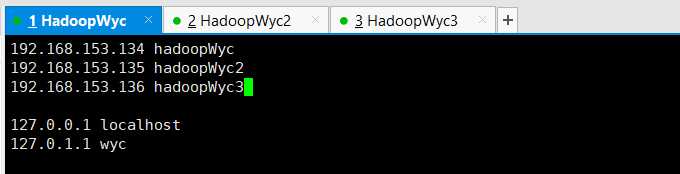
打开hosts文件,新增三条IP与主机的映射关系:
vim /etc/hosts
192.168.153.136 hadoopWyc
192.168.153.137 hadoopWyc2
192.168.153.138 hadoopWyc3
8、集群搭建
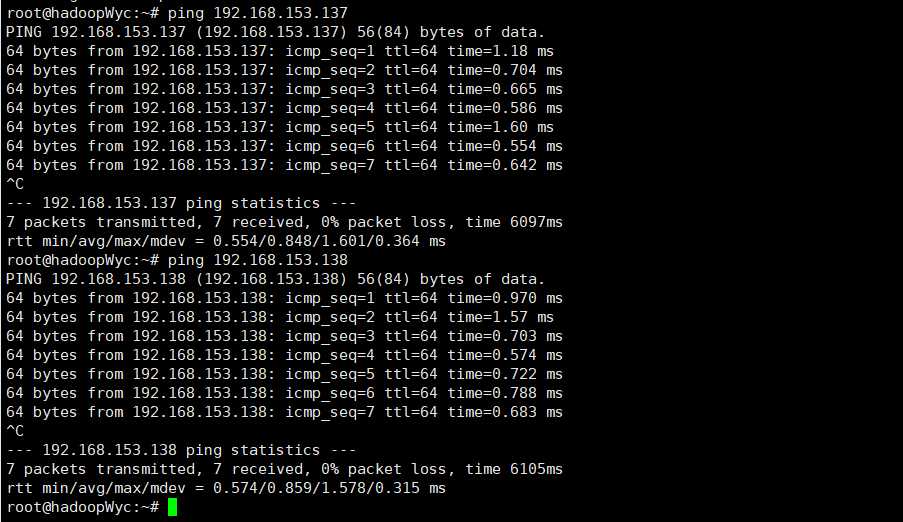
现在正式搭建Hadoop集群。首先我们还是需要打开VMware中的三台虚拟机,然后用Xshall连接好三台虚拟机就行了。
三台机子之间互相ping,看是否能ping通。
8.1 SSH无密码登录节点
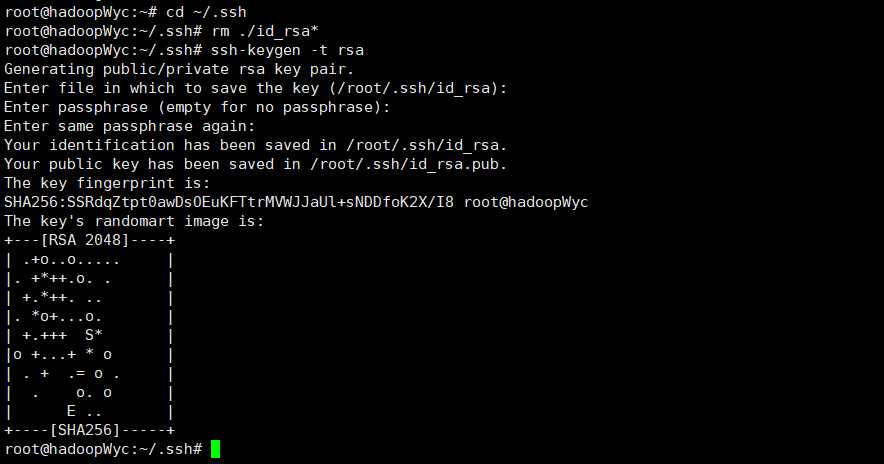
必须要让hadoopWyc节点可以SSH无密码登录到各个hadoopWyc2和hadoopWyc3节点上。首先生成hadoopWyc节点公钥,如果之前已经生成,必须删除,重新生成一次。在hadoopWyc上进行下面操作:
cd ~/.ssh
rm ./id_rsa* # 删除之前生成的公钥
ssh-keygen -t rsa # 遇到信息,一直回车就行
再让hadoopWyc节点能够无密码SSH登录本机,在hadoopWyc节点上执行下面命令:
cat ./id_rsa.pub >> ./authorized_keys
使用下面命令进行测试:
ssh hadoopWyc
接下来将hadoopWyc上的公钥传给各个hadoopWyc2&3节点:
scp ~/.ssh/id_rsa.pub hadoopWyc2:/home/wyc
scp ~/.ssh/id_rsa.pub hadoopWyc3:/home/wyc
其中scp是secure copy的简写,在Linux中用于远程拷贝。执行scp时会要求输入hadoopWyc2&3用户的密码,输入完成后会显示传输完毕:

接着在hadoopWyc2节点上,将接收到的公钥加入授权:
mkdir ~/.ssh # 如果不存在该文件夹,先创建
cat /home/wyc/id_rsa.pub >> ~/.ssh/authorized_keys
rm /home/wyc/id_rsa.pub # 加完就删除
在hadoopWyc3节点中也执行以上的命令。执行完了之后,在hadoopWyc节点上就可以无密码登录hadoopWyc2&3节点,在hadoopWyc节点上执行下面命令:
ssh hadoopWyc2
在hadoopWyc登录hadoopWyc2,这个时候输入命令等于在虚拟机hadoopWyc2执行一样
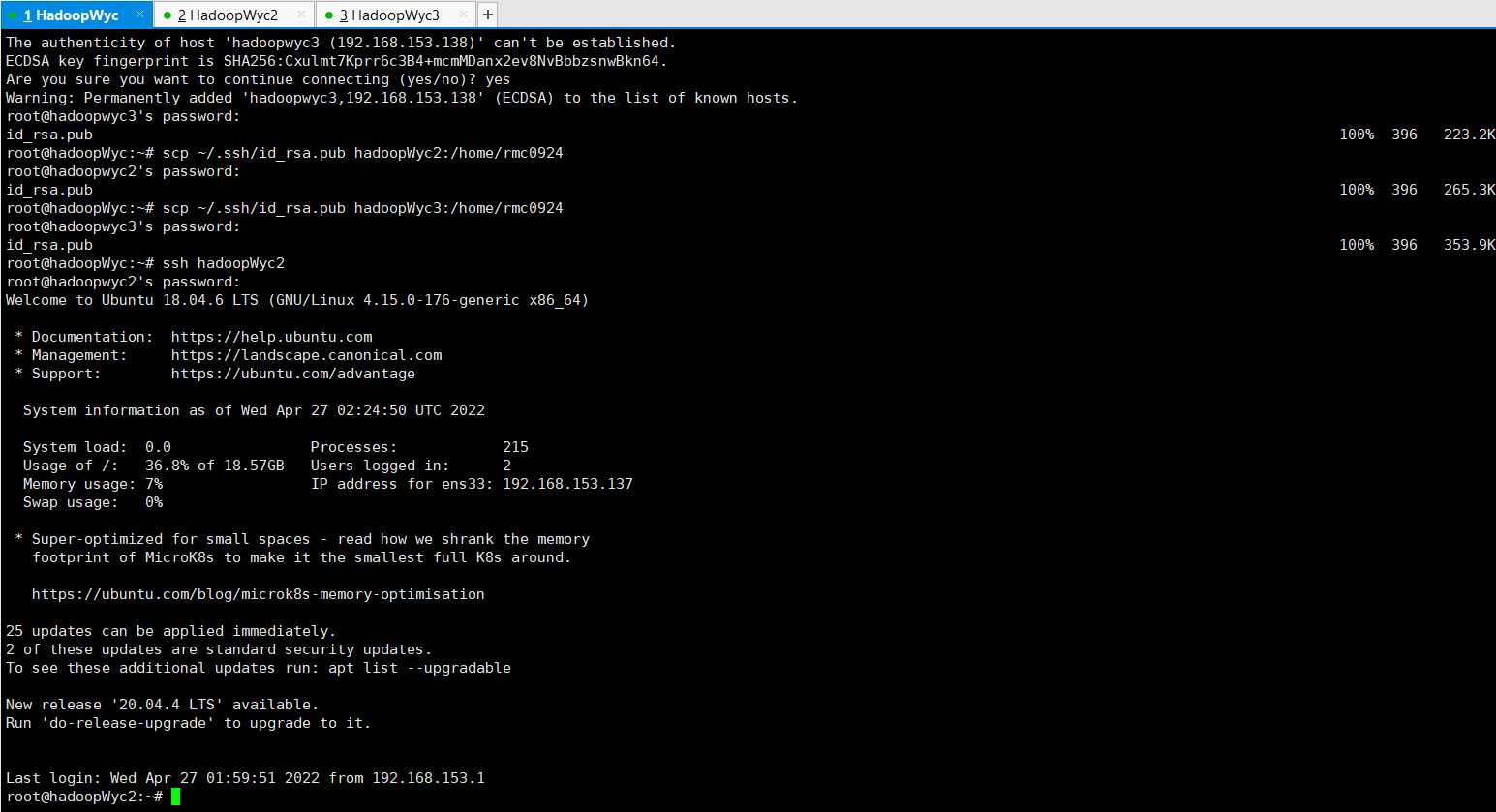
输入exit即可退出
8.2 配置集群环境
配置集群模式时,需要修改“/usr/local/hadoop/etc/hadoop”目录下的配置文件,包括workers、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml。
8.2.1 修改workers文件
vim workers
该文件内容可以指定某几个节点作为数据节点,默认为localhost,我们将其删除并修改为hadoopWyc2和hadoopWyc。当然也可以将hadoopWyc加进去,让hadoopWyc节点既做名称节点,也做数据节点,本文将hadoopWyc一起加进去作为数据节点。
hadoopWyc
hadoopWyc2
hadoopWyc3
8.2.2 修改core-site.xml文件
vim core-site.xml
fs.defaultFS:指定namenode的hdfs协议的文件系统通信地址,可以指定一个主机+端口
hadoop.tmp.dir:hadoop集群在工作时存储的一些临时文件存放的目录
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoopWyc:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
</property>
</configuration>
8.2.3 修改hdfs-site.xml文件
vim hdfs-site.xml
dfs.secondary.http.address:secondarynamenode运行节点的信息,应该和namenode存放在不同节点
dfs.repliction:hdfs的副本数设置,默认为3
dfs.namenode.name.dir:namenode数据的存放位置,元数据存放位置
dfs.datanode.data.dir:datanode数据的存放位置,block块存放的位置
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoopWyc2:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
8.2.4 修改mapred-site.xml文件
vim mapred-site.xml
mapreduce.framework.name:指定mapreduce框架为yarn方式
mapreduce.jobhistory.address:指定历史服务器的地址和端口
mapreduce.jobhistory.webapp.address:查看历史服务器已经运行完的Mapreduce作业记录的web地址,需要启动该服务才行
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoopWyc:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoopWyc:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value>
</property>
</configuration>
8.2.5 修改yarn-site.xml文件
vim yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoopWyc</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
8.3 分发文件
修改完上面五个文件后,将hadoopWyc节点上的hadoop文件复制到各个结点上。在hadoopWyc节点上执行下面命令:
cd /usr/local
sudo rm -r ./hadoop/tmp # 删除 Hadoop 临时文件
sudo rm -r ./hadoop/logs/* # 删除日志文件
tar -zcf ~/hadoop.master.tar.gz hadoop # 先压缩再复制
cd ~
scp hadoop.master.tar.gz hadoopWyc2:/home/
scp hadoop.master.tar.gz hadoopWyc3:/home/

在其他hadoopWyc2&3节点将接收的压缩文件解压出来,并授予权限,命令如下:
sudo rm -r /usr/local/hadoop # 删掉旧的(如果存在)
sudo tar -zxf /home/hadoop.master.tar.gz -C /usr/local
sudo chown -R wyc /usr/local/hadoop

8.4 Hadoop初始化
HDFS初始化只能在主节点上进行
cd /usr/local/hadoop
./bin/hdfs namenode -format
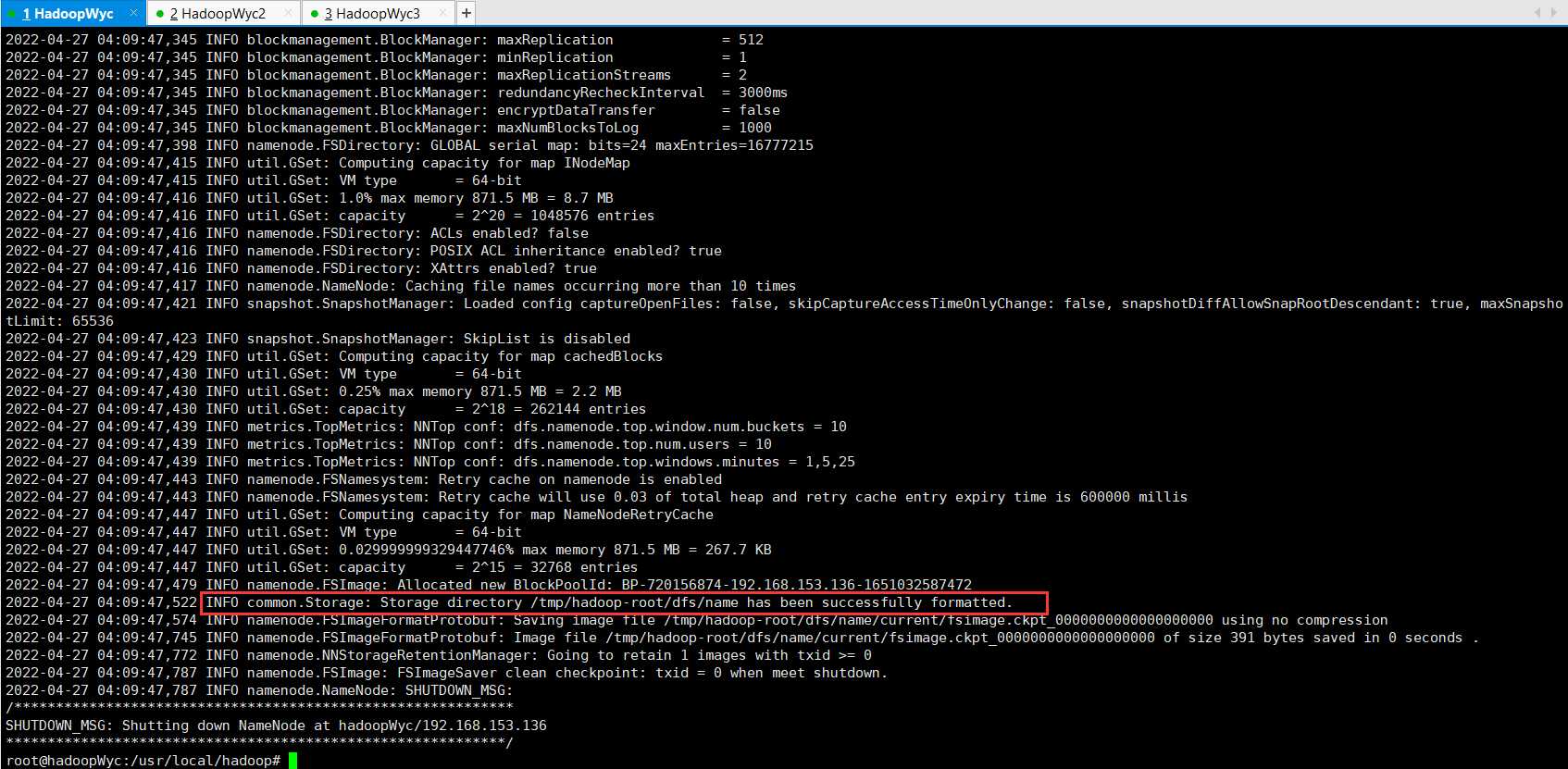
在初始化过程中,只要看到上面红框里面的信息,有个successfully formatted说明初始化成功。
8.5 Hadoop集群启动
在hadoopWyc节点上执行下面命令:
cd /usr/local/hadoop
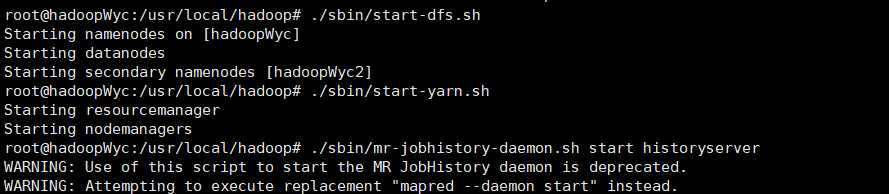
./sbin/start-dfs.sh
./sbin/start-yarn.sh
./sbin/mr-jobhistory-daemon.sh start historyserver
#这样我们就可以在相应机器的19888端口上打开历史服务器的WEB UI界面。可以查看已经运行完的作业情况
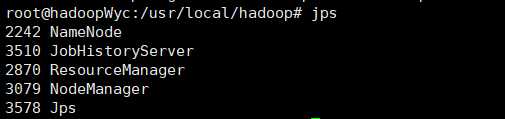
通过jps可以查看各个节点所启动的进程,如果按照本文的设置,正确启动的话,在hadoopWyc节点上会看到以下进程:
hadoopWyc2节点的进程:
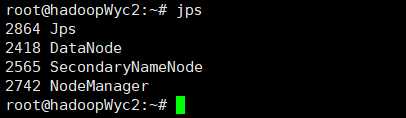
hadoopWyc3节点的进程:
hadoop-3.1.0启动hadoop集群时还有可能会报如下错误:
root@hadoopWyc3:/usr/local/hadoop# ./sbin/start-dfs.sh
Starting namenodes on [hadoopWyc]
ERROR: Attempting to operate on hdfs namenode as root
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.
Starting datanodes
ERROR: Attempting to operate on hdfs datanode as root
ERROR: but there is no HDFS_DATANODE_USER defined. Aborting operation.
Starting secondary namenodes [hadoopWyc2]
ERROR: Attempting to operate on hdfs secondarynamenode as root
ERROR: but there is no HDFS_SECONDARYNAMENODE_USER defined. Aborting operation.
参考:解决 Hadoop 启动 ERROR: Attempting to operate on hdfs namenode as root 的方法 解决
至此,Hadoop的完全分布式部署已经完成。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/219152.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
