大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
目录
一、模型简介和思想
 NER是2022年NER任务最新SOTA的论文——Unified Named Entity Recognition as Word-Word Relation Classification,它统一了Flat普通扁平NER、Nested嵌套NER和discontinuous不连续的NER等三种NER任务模型,并且在14个数据集上刷新了SOTA。个人很喜欢这篇文章,一个是文章确实在NER这种最基本的任务继续刷新SOTA;二是它能完美的解决多种不同类型的NER的问题,普通、嵌套和不连续的NER之前都需要设计不同的模型来解决,而该论文确是直接统一了这三种类型的NER;三是论文的思想比较简单清晰并且提供了源码——思想简单不复杂好理解,容易复现和迁移到具体的业务场景上。
NER是2022年NER任务最新SOTA的论文——Unified Named Entity Recognition as Word-Word Relation Classification,它统一了Flat普通扁平NER、Nested嵌套NER和discontinuous不连续的NER等三种NER任务模型,并且在14个数据集上刷新了SOTA。个人很喜欢这篇文章,一个是文章确实在NER这种最基本的任务继续刷新SOTA;二是它能完美的解决多种不同类型的NER的问题,普通、嵌套和不连续的NER之前都需要设计不同的模型来解决,而该论文确是直接统一了这三种类型的NER;三是论文的思想比较简单清晰并且提供了源码——思想简单不复杂好理解,容易复现和迁移到具体的业务场景上。
我们知道NER任务一般采取的建模思路,要么就是序列标注——BIO,seq2seq或者span——基于实体的首尾index来进行建模的。而NER则是采用了Word-Pair——构建词和词的关系的方式。论文构建了这样的一种建模方式:
1、Next-Neighboring-Word(NHW):表示word和它相邻的连接word之间的关系,注意是相邻
2、Tail-Head-Word-*(THW-*):表示tail-word和head-word的连接关系,并且带有label实体的类型信息
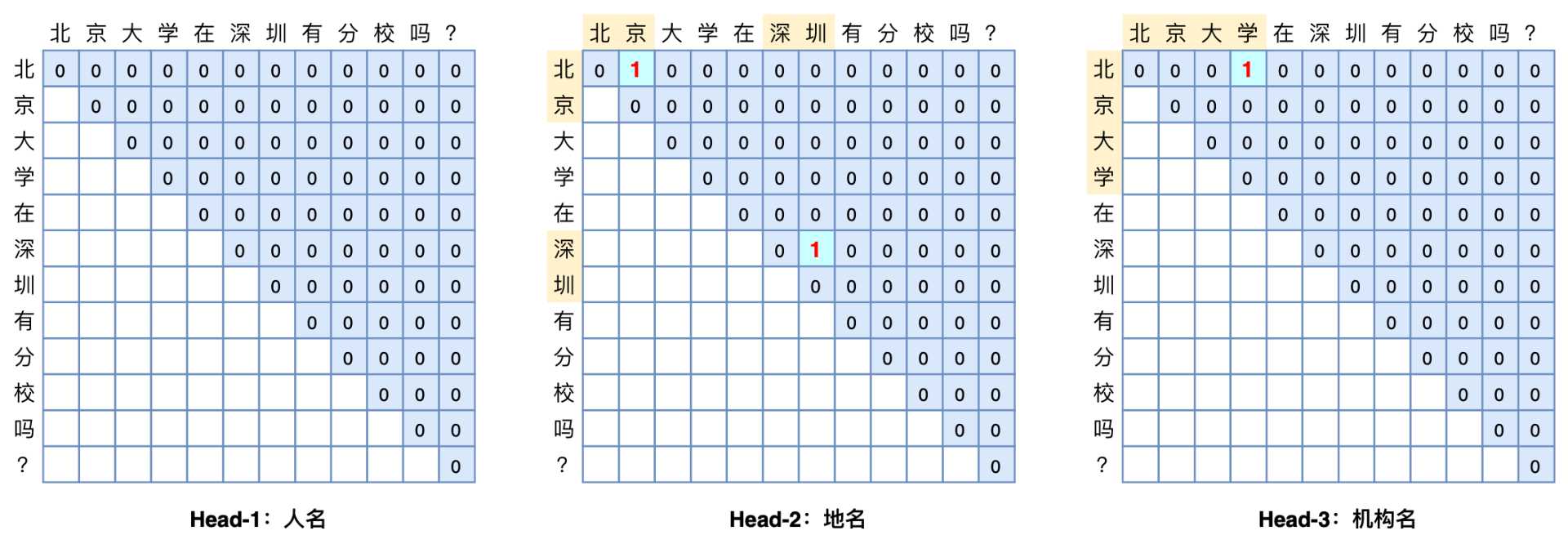
如下图示例中,句中的两个实体e1和e2,它们之间就是重叠嵌套实体。用NER的建模方式来表,就是需要找出所有实体的NHW关系和THM-*关系,然后做一个多分类任务。

具体的怎么建模THW和NHW的向量表示呢?对一句话,构建这样一个二维表格。表格的上三角部分表示NHW关系标注,下三角区域则表示THW-* 关系标注。
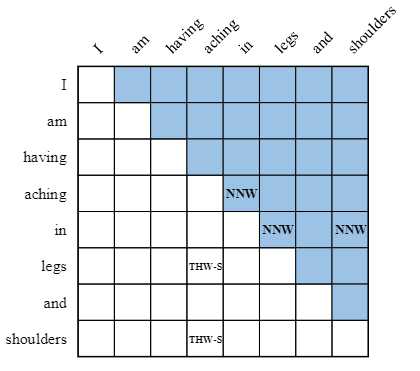
假设S是第二种实体,以上二维表格就可以使用一个二维矩阵来表示:
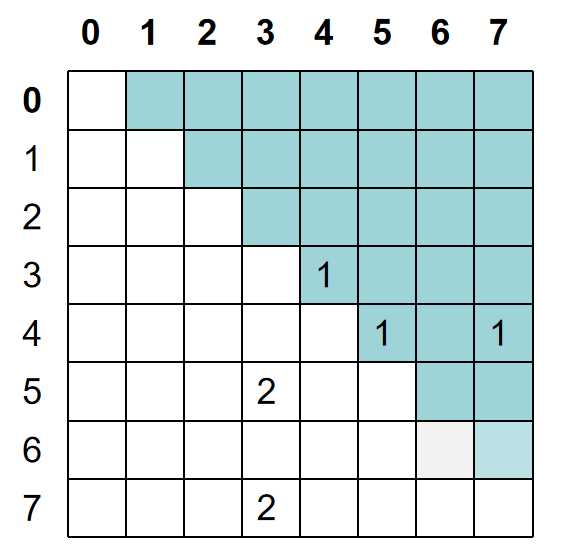
针对不同类型的NER,NHW和THW的关系,上表和矩阵都能有一个很好的表示,那么这种建模解码方式能完全区分清楚吗?
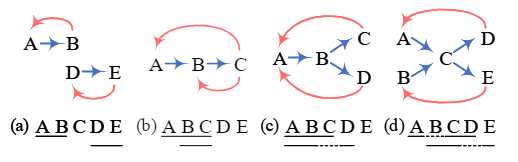
上图中,列举了不同的示例,A中表示普通扁平的NER,AB和DE分别是一个实体,A的NHW是B,B的head是A,同理DE直接具有THW关系,E的head是D;其他示例分辨是b表示ABC实体中有个重叠嵌套识别BC;C中的示例比赛ABC和ABD也是有嵌套和不连续实体;d中表示的是连个不连续的实体ACE和BCD;之所有能区分开来,其原理就是利用THW和THW两种关系联合起来判定的。
二、模型结构
模型模块其实比较多,模型图如下:
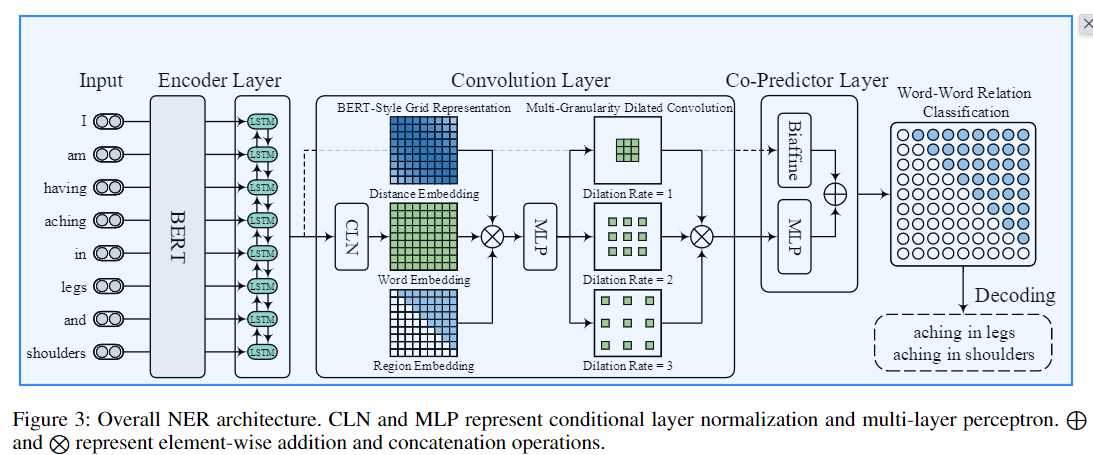
图中显示的模型结构,比较复杂可以分为三部分来看:
第一部分encoder层
其实就是Bert后接一个LSTM,图上显示的比较简单,代码实现的时候,这里的embedding做了一些细节处理了的,具体怎么处理的后面可以阅读一下代码。
第二部分Convolution Layer卷积层
论文作者们认为卷积神经网络适合2D网格特征提取,因此设计了卷积层,它含了3个模块
a、conditional layer with normalization:生成word对网格的表示,这里是直接把encoder输出的word_embedding输入一个CLN模块,可以得到网格表示的embedding。
b、BERT-style grid representation:丰富的bert风格式语义网格,由Bert的token_embedding/position_embedding/segment_embedding思路设计了distance_embedding(word之间的位置远近)/word_embedding(word对网格的表示)/reg_embedding(区分网格上三角和下三角区域的embedding),然后concat起来得到一个丰富的bert风格式语义网格表示作为下一个模块的输入。
c、multigranularity dilated convolution:多粒度膨胀卷积,采用3个不同的膨胀率来捕获远近word之间的交互表示
第三部分Co-Predictor Layer联合预测层
它是有MLP模块和Biaffine(双仿射分类器)构成
1、MLP层将经过Conditional Layer Normalization、BERT-Style Grid Representation Build-Up、Multi-Granularity Dilated Convolution输出的向量通过MLP进行关系分数预测
2、Biaffine直接把encoder层(Bert+LSTM)的输出word_embedding进行关系分类预测,这里直接使用encoder层(Bert+LSTM)的输出word_embedding,整体上而言有点残差的意味,防止模型退化以及缓解模型梯度爆炸和消失的作用让模型训练更加良好。
3、最后把MLP层的关系分数和Biaffine关系分数进行相加,它就是Co-Predictor Layer的最后结果。
直接看论文其实是有很多细节不会展示回来的,也不好展示出来,剩余的细节就需要在代码中仔细阅读,论文其实就是展示了大致的思想,所以论文和代码都是需要好好看的。
三、模型代码解读
模型输入
作为一个模型,首先要清楚它的输入是什么样的,以及输入的具体维度信息,这部分论文中没有详细的给出,代码中可以看到
bert_inputs = [] #bert模型的输入token_ids也就是input_ids包含[CLS]和[SEP] 维度[B,L+2] grid_labels = [] #标注数据实体构建的THW和NHW关系二维矩阵 维度[B,L,L] grid_mask2d = [] #网格的mask信息,有效信息Ture,padding为False 维度[B,L,L] dist_inputs = [] #网格中字符的相对位置信息 维度[B,L,L] pieces2word = [] #维度[B,L,L+2] sent_length = [] #句长[B]
这里的数据处理主要是在data_loader.py中的process_bert()函数中
def process_bert(data, tokenizer, vocab):
bert_inputs = []
grid_labels = []
grid_mask2d = []
dist_inputs = []
entity_text = []
pieces2word = []
sent_length = []
for index, instance in enumerate(data):
if len(instance['sentence']) == 0:
continue
tokens = [tokenizer.tokenize(word) for word in instance['sentence']]
pieces = [piece for pieces in tokens for piece in pieces]
_bert_inputs = tokenizer.convert_tokens_to_ids(pieces)
_bert_inputs = np.array([tokenizer.cls_token_id] + _bert_inputs + [tokenizer.sep_token_id])
length = len(instance['sentence'])
_grid_labels = np.zeros((length, length), dtype=np.int)
_pieces2word = np.zeros((length, len(_bert_inputs)), dtype=np.bool)
_dist_inputs = np.zeros((length, length), dtype=np.int)
_grid_mask2d = np.ones((length, length), dtype=np.bool)
#得到的矩阵去掉首位两列,对角线为1的矩阵_pieces2word
if tokenizer is not None:
start = 0
for i, pieces in enumerate(tokens):
if len(pieces) == 0:
continue
pieces = list(range(start, start + len(pieces)))
_pieces2word[i, pieces[0] + 1:pieces[-1] + 2] = 1
start += len(pieces)
#得到的是一个对称下三角为正上三角为负,对角线为0的矩阵_dist_inputs
for k in range(length):
_dist_inputs[k, :] += k
_dist_inputs[:, k] -= k
#然后把_dist_inputs中的负值做绝对值后,把所有的距离做分类然后使用dis2idx映射为20类距离值[0-19]
#dis2id具体定义如下
"""
dis2idx[1] = 1
dis2idx[2:] = 2
dis2idx[4:] = 3
dis2idx[8:] = 4
dis2idx[16:] = 5
dis2idx[32:] = 6
dis2idx[64:] = 7
dis2idx[128:] = 8
dis2idx[256:] = 9
"""
for i in range(length):
for j in range(length):
if _dist_inputs[i, j] < 0:
_dist_inputs[i, j] = dis2idx[-_dist_inputs[i, j]] + 9
else:
_dist_inputs[i, j] = dis2idx[_dist_inputs[i, j]]
_dist_inputs[_dist_inputs == 0] = 19
#修改版1——我修改的并非论文作者
# for i in range(length):
# for j in range(length):
# if _dist_inputs[i, j] < 0:
# _dist_inputs[i, j] = dis2idx[-_dist_inputs[i, j]]
# else:
# _dist_inputs[i, j] = dis2idx[_dist_inputs[i, j]]
# _dist_inputs[_dist_inputs == 0] = 19
#修改版2——我也修改的并非论文作者
# for i in range(length):
# for j in range(length):
# if _dist_inputs[i, j] < 0:
# _dist_inputs[i, j] = -_dist_inputs[i, j]
for entity in instance["ner"]:
index = entity["index"]
for i in range(len(index)):
if i + 1 >= len(index):
break
_grid_labels[index[i], index[i + 1]] = 1
_grid_labels[index[-1], index[0]] = vocab.label_to_id(entity["type"])
_entity_text = set([utils.convert_index_to_text(e["index"], vocab.label_to_id(e["type"]))
for e in instance["ner"]])
sent_length.append(length)
bert_inputs.append(_bert_inputs)
grid_labels.append(_grid_labels)
grid_mask2d.append(_grid_mask2d)
dist_inputs.append(_dist_inputs)
pieces2word.append(_pieces2word)
entity_text.append(_entity_text)
return bert_inputs, grid_labels, grid_mask2d, pieces2word, dist_inputs, sent_length, entity_text举例如下,句子:常建良,男,
NER实体:常建良 实体类型:Name,第二类实体
则数据处理后,得到模型的输入单条如下:
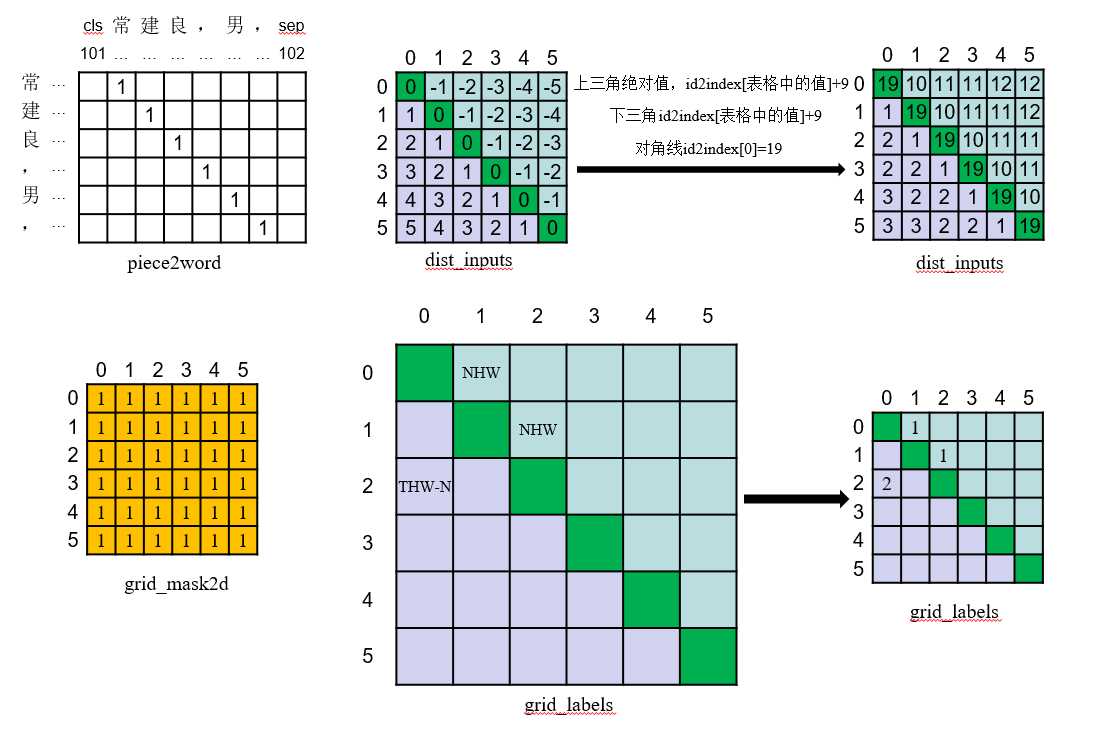
比较难看懂的是dist_inputs,以及为何需要做上下三角不对称以及把位置相对距离做了一个id2index的映射,本质上做了20个类别的划分——我的观点是论文中提到模型中的reg_embedding起到区分上下三角的表示,所有只有把dist_inputs设计的有上下三角明显的差异性,才会具有区分性;至于为何要做20个类别的切分——(距离0为index 19、距离1为index 1、距离[2,3]为index 2、距离[4,5,6,7]为index 3……距离[256——1000]为9,还有一部分负值做了偏移后(+9)就刚好是index10——index18)
模型代码
模型整体结构在论文的图中已经有了比较详细的展示,下面对应代码一起看模型结构:
def __init__(self, config):
super(Model, self).__init__()
self.use_bert_last_4_layers = config.use_bert_last_4_layers
self.lstm_hid_size = config.lstm_hid_size
self.conv_hid_size = config.conv_hid_size
lstm_input_size = 0
#Bert模型
self.bert = AutoModel.from_pretrained(config.bert_path, output_hidden_states=True)
lstm_input_size += config.bert_hid_size
#位置编码——因为位置是从0-19 所以只有20的容量
self.dis_embs = nn.Embedding(20, config.dist_emb_size)
#区域编码——上下三角和mask位置(padding补0的地方),所有Embedding的第一个参数也只有3
self.reg_embs = nn.Embedding(3, config.type_emb_size)
#双休LSTM 没啥好说的
self.encoder = nn.LSTM(lstm_input_size, config.lstm_hid_size // 2, num_layers=1, batch_first=True,
bidirectional=True)
#送入卷积层模型的channel
conv_input_size = config.lstm_hid_size + config.dist_emb_size + config.type_emb_size
self.convLayer = ConvolutionLayer(conv_input_size, config.conv_hid_size, config.dilation, config.conv_dropout)
self.dropout = nn.Dropout(config.emb_dropout)
#联合预测器
self.predictor = CoPredictor(config.label_num, config.lstm_hid_size, config.biaffine_size,
config.conv_hid_size * len(config.dilation), config.ffnn_hid_size,
config.out_dropout)
#条件LayerNorm
self.cln = LayerNorm(config.lstm_hid_size, config.lstm_hid_size, conditional=True)看到和论文的模型结构图是一致的。细节的地方在于forward和子模型中,先看forward函数的整体逻辑:1、模型输入,经过Bert和lstm得到word_resp,其中在Bert和Lstm之间对Bert向量进行了一个最大池化的处理,word_resp经过条件层归一化得到cln也就是word_embedding;2、dist_inputs经过Embedding得到位置编码dis_emb;3、grid_mask2d和上三角矩阵经过Embedding得到区域编码reg_embedding;4、把dis_emb、reg_embedding和word_embedding concat起来再经过卷积层网络,得到卷积输出conv_outputs;5、word_resp和conv_outputs分别经过由Biaffine和MLP组成的联合预测器co_predictor,得到2者的输出求和 就是模型整体的输出。
具体代码如下
def forward(self, bert_inputs, grid_mask2d, dist_inputs, pieces2word, sent_length):
'''
:param bert_inputs: [B, L']
:param grid_mask2d: [B, L, L]
:param dist_inputs: [B, L, L]
:param pieces2word: [B, L, L']
:param sent_length: [B]
:return:
'''
bert_embs = self.bert(input_ids=bert_inputs, attention_mask=bert_inputs.ne(0).float())
if self.use_bert_last_4_layers:
bert_embs = torch.stack(bert_embs[2][-4:], dim=-1).mean(-1)
else:
bert_embs = bert_embs[0]
length = pieces2word.size(1)
min_value = torch.min(bert_embs).item()
# Max pooling word representations from pieces
# bert_embs[B, L',768] _bert_embs [B, L, L', 768]升维
_bert_embs = bert_embs.unsqueeze(1).expand(-1, length, -1, -1)
mask = pieces2word.eq(0).unsqueeze(-1)
#把_bert_embs不是word的位置上全部填充min_value
_bert_embs = torch.masked_fill(_bert_embs, mask, min_value)
#然后_bert_embs第3维度上取最大值,最后得到word_reps [B, L, 768]
word_reps, _ = torch.max(_bert_embs, dim=2)
word_reps = self.dropout(word_reps)
packed_embs = pack_padded_sequence(word_reps, sent_length.cpu(), batch_first=True, enforce_sorted=False)
packed_outs, (hidden, _) = self.encoder(packed_embs)
#经过Bilstm后维度信息——[B, L, 512]升维
word_reps, _ = pad_packed_sequence(packed_outs, batch_first=True, total_length=sent_length.max())
#条件层归一化——输入两个向量[B, L, 1, 512] 和 [B, L, 512]得到[B, L, L, 512]
cln = self.cln(word_reps.unsqueeze(2), word_reps)
#得到位置编码
dis_emb = self.dis_embs(dist_inputs)
#得到区域编码
tril_mask = torch.tril(grid_mask2d.clone().long())
reg_inputs = tril_mask + grid_mask2d.clone().long()
reg_emb = self.reg_embs(reg_inputs)
#把三种Embedding concat起来
conv_inputs = torch.cat([dis_emb, reg_emb, cln], dim=-1)
#对concat的向量做有效和无效信息的处理,不是word pair组成的二维矩阵之外的全部置0
conv_inputs = torch.masked_fill(conv_inputs, grid_mask2d.eq(0).unsqueeze(-1), 0.0)
# 多粒度膨胀分组二维卷积神经网络部分
conv_outputs = self.convLayer(conv_inputs)
#同样对有效和无效信息的处理,不是word pair组成的二维矩阵之外的全部置0
conv_outputs = torch.masked_fill(conv_outputs, grid_mask2d.eq(0).unsqueeze(-1), 0.0)
#经过MLP层和Biaffinde分类器两种网络,把得到的结果求和加起来
outputs = self.predictor(word_reps, word_reps, conv_outputs)
#outputs [B, L, L, num_class] num_class指的是有多少类实体
return outputs代码中我做了详细的注释,需要注意的点就是Biaffine和条件LayerNorm层的实现和作用,这个就不细说了需要去看代码和相应论文理解,它们的作用我也理解的不清楚,就不现丑了。说一说子模型self.convLayer = ConvolutionLayer多粒度膨胀二维分组卷积网络。
class ConvolutionLayer(nn.Module):
def __init__(self, input_size, channels, dilation, dropout=0.1):
super(ConvolutionLayer, self).__init__()
self.base = nn.Sequential(
nn.Dropout2d(dropout),
nn.Conv2d(input_size, channels, kernel_size=1),
nn.GELU(),
)
self.convs = nn.ModuleList(
[nn.Conv2d(channels, channels, kernel_size=3, groups=channels, dilation=d, padding=d) for d in dilation])self.base中没有什么注意的,这里使用了最基本的Conv2d,采用1*1的卷积核;self.convs使用了分组卷积,这里必须注意的是input和output都是channels,并且groups=channels,那么这里就使用了depth-wise conv——减少计算量,而不减少模型容量和复杂度。
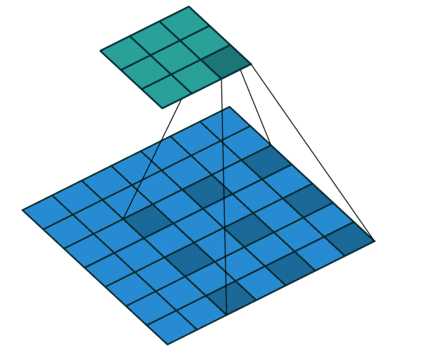
关于dilation参数,它可以改变卷积核的尺寸,但是参与的卷积计算参数维度不变。3*3的卷积核在dilation=2的时候会变成5*5的卷积,但是这个卷积中有空白的不参与计算,实际参与计算的只有9个参数。如下图所示:
具体的公式:
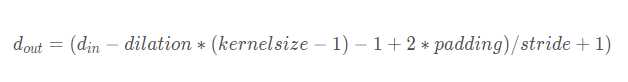
dilation参数不同,代表模型提取到的信息是不同大小区域的,换句话说也就是提取到不同粒度的信息。
模型训练Loss预测和解码
loss函数
self.criterion = nn.CrossEntropyLoss()
#outputs[B, L, L, N] grid_labels[B,L,L] grid_mask2d[B,L,L]
#计算loss的时候把padding的地方去除掉
loss = self.criterion(outputs[grid_mask2d], grid_labels[grid_mask2d])计算loss的时候不计算padding的位置,需要使用grid_mask2d把这些位置屏蔽掉
预测
这是一个分类任务,所以直接使用torch.max
outputs = torch.argmax(outputs, -1)得到word2word之间的关系THW-S和NHW的预测值
解码阶段
把上述word2word之间的THW-S和NHW关系预测值,通过解码,解码为具体的实体
def decode(outputs, entities, length):
ent_r, ent_p, ent_c = 0, 0, 0
for index, (instance, ent_set, l) in enumerate(zip(outputs, entities, length)):
forward_dict = {}
head_dict = {}
ht_type_dict = {}
# 统计NHW关系,上三角中;forward_dict的key是前面的一个word的index;val是和key相邻word的index
for i in range(l):
for j in range(i + 1, l):
if instance[i, j] == 1:
if i not in forward_dict:
forward_dict[i] = [j]
else:
forward_dict[i].append(j)
#统计THW-S关系,head_dict的key是head,val是tail;ht_type_dict保存实体类型种类index
for i in range(l):
for j in range(i, l):
if instance[j, i] > 1:
ht_type_dict[(i, j)] = instance[j, i]
if i not in head_dict:
head_dict[i] = {j}
else:
head_dict[i].add(j)
predicts = []
#内部函数,寻找实体——采用递归的方式;把实体对应的indexs 列表保存在predicts中
def find_entity(key, entity, tails):
entity.append(key)
if key not in forward_dict:
if key in tails:
predicts.append(entity.copy())
entity.pop()
return
else:
if key in tails:
predicts.append(entity.copy())
for k in forward_dict[key]:
find_entity(k, entity, tails)
entity.pop()
for head in head_dict:
find_entity(head, [], head_dict[head])
#predicts的元素X是一个列表,表示实体的index x[0]头 x[-1]尾
predicts = set([convert_index_to_text(x, ht_type_dict[(x[0], x[-1])]) for x in predicts])这个代码逻辑稍显复杂,需要仔细debug才能理解。
解码过程中数据展示:
forward_dict {0: [1], 1: [2]}
head_dict {0: {2}}
ht_type_dict {(0, 2): 2}
predicts [[0, 1, 2]] ———> {‘0-1-2-#-2’} 这就是最后的实体,根据句子中的位置和实体类型就可以明确具体的实体文本了。
四、实验
论文公布数据集resume
首先看看论文给的数据集,作者公布了resume的数据集。数据如下:
{"sentence": ["吴", "重", "阳", ",", "中", "国", "国", "籍", ",", "大", "学", "本", "科", ",", "教", "授", "级", "高", "工", ",", "享", "受", "国", "务", "院", "特", "殊", "津", "贴", ",", "历", "任", "邮", "电", "部", "侯", "马", "电", "缆", "厂", "仪", "表", "试", "制", "组", "长", "、", "光", "缆", "分", "厂", "副", "厂", "长", "、", "研", "究", "所", "副", "所", "长", ",", "获", "得", "过", "山", "西", "省", "科", "技", "先", "进", "工", "作", "者", "、", "邮", "电", "部", "成", "绩", "优", "异", "高", "级", "工", "程", "师", "等", "多", "种", "荣", "誉", "称", "号", "。"], "ner": [{"index": [0, 1, 2], "type": "NAME"}, {"index": [4, 5, 6, 7], "type": "CONT"}, {"index": [9, 10, 11, 12], "type": "EDU"}, {"index": [14, 15, 16, 17, 18], "type": "TITLE"}, {"index": [32, 33, 34, 35, 36, 37, 38, 39], "type": "ORG"}, {"index": [40, 41, 42, 43, 44, 45], "type": "TITLE"}, {"index": [47, 48, 49, 50, 51, 52, 53], "type": "TITLE"}, {"index": [55, 56, 57, 58, 59, 60], "type": "TITLE"}]}
{"sentence": ["历", "任", "公", "司", "副", "总", "经", "理", "、", "总", "工", "程", "师", ","], "ner": [{"index": [2, 3], "type": "ORG"}, {"index": [4, 5, 6, 7], "type": "TITLE"}, {"index": [9, 10, 11, 12], "type": "TITLE"}]}我实验的结果是:
+————+——–+———–+——–+
| TEST Final | F1 | Precision | Recall |
+————+——–+———–+——–+
| Label | 0.9812 | 0.9716 | 0.9916 |
| Entity | 0.9630 | 0.9609 | 0.9650 |
+————+——–+———–+——–+
论文的结果是:
+————+——–+———–+——–+
| TEST Final | F1 | Precision | Recall |
+————+——–+———–+——–+
| Entity | 96.65| 96.96 | 96.35 |
+————+——–+———–+——–+
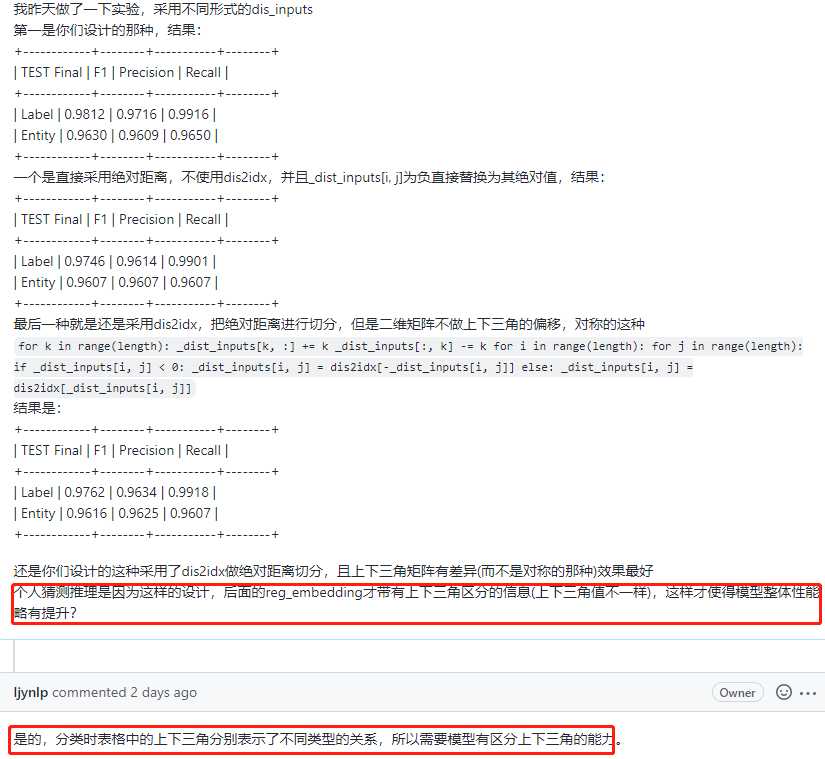
略有偏差,和作者沟通后,作者实验时发现使用CNN后随机种子就不起效果,所以就没有固定随机种子。结果偏差不大,我就没有深究了,效果确实还可以的。——当然这是需要搞清楚的为什么是这样子的,是那里出什么问题了吗?
当然我也尝试修改了dis_inputs实现方式
1、直接采用绝对距离,不使用dis2idx,并且_dist_inputs[i, j]为负直接替换为其绝对值——(代码就在process_bert函数中注释的第一部分),结果:
+————+——–+———–+——–+
| TEST Final | F1 | Precision | Recall |
+————+——–+———–+——–+
| Label | 0.9746 | 0.9614 | 0.9901 |
| Entity | 0.9607 | 0.9607 | 0.9607 |
+————+——–+———–+——–+
2、采用dis2idx,把绝对距离进行切分,但是二维矩阵不做上下三角的偏移,对称的这种
+————+——–+———–+——–+
| TEST Final | F1 | Precision | Recall |
+————+——–+———–+——–+
| Label | 0.9762 | 0.9634 | 0.9918 |
| Entity | 0.9616 | 0.9625 | 0.9607 |
+————+——–+———–+——–+
效果均没有原论文实现的那种上下三角带有差异且对距离值做了20分类的效果好。作者的解释为——分类时表格中的上下三角分别表示了不同类型的关系,所以需要模型有区分上下三角的能力——和我的猜测一样。
biendata医疗比赛数据集
中文医学领域NER任务——数据集CMeEE实验,这是一个含有嵌套和Flat的NER的数据集,部分数据(比赛格式)如下:
对儿童SARST细胞亚群的研究表明,与成人SARS相比,儿童细胞下降不明显,证明上述推测成立。|||3 9 bod|||19 24 dis|||
研究证实,细胞减少与肺内病变程度及肺内炎性病变吸收程度密切相关。|||10 10 bod|||10 13 sym|||17 17 bod|||17 22 sym|||
因而儿童肺部病变较轻,肺内炎性病变吸收较快。|||4 5 bod|||4 7 sym|||11 11 bod|||11 16 sym|||
SARS患儿有部分出现心脏损害,对有心脏损害者应进行床边动态心电监护。|||0 3 dis|||11 12 bod|||11 14 sym|||18 19 bod|||18 21 sym|||26 33 pro|||
一般有明确SARS接触史。|||5 8 dis|||
可以看到有很多嵌套的实体
第二句的实体肺、肺内病变;肺、肺内炎性病变是嵌套重叠的;
第三句的实体肺部、肺部病变;肺、肺内炎性病变是嵌套重叠实体;
第四句的实体心脏、心脏损害是是嵌套重叠实体;
结果:
+——–+——–+———–+——–+
| EVAL 9 | F1 | Precision | Recall |
+——–+——–+———–+——–+
| Label | 0.6912 | 0.6955 | 0.6980 |
| Entity | 0.6486 | 0.6398 | 0.6576 |
+——–+——–+———–+——–+
2022-04-13 11:31:32 – INFO: Best DEV F1: 0.6486
这个数据集在苏剑林的博客GlobalPointer:用统一的方式处理嵌套和非嵌套NER中也进行了评测,只不过使用的是另外的网络——GlobalPointer——简单的理解就是对连续的候选实体做多标签分类问题,具体的去拜读博客。
结果如下:
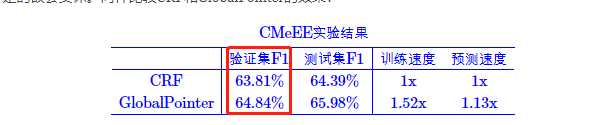
其实两者相差不大, NER和GlobalPointer基本持平,但是前者还可以处理不连续的NER问题,不过我这里没有相应的不连续NER中文数据集,就不做测试了。
总体看 NER,个人认为还是比较好的一个方法,把NER三者的任务都统一起来了,并且效果也很不错,思想也是和经典的CRF、span等都不同,理解起来也很好理解,不过细节的地方需要仔细琢磨。
参考文章
Unified Named Entity Recognition as Word-Word Relation Classification
GlobalPointer:用统一的方式处理嵌套和非嵌套NER
算法框架-信息抽取-NER识别-Unified Named Entity Recognition as Word-Word Relation Classification
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/216263.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
