大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
点赞多大胆,就有多大产!有支持才有动力!将技术分享给每一个技术使用者和爱好者!
干货满满,摆好姿势,点赞发车!
前言
数据库优化是一个老生常谈的问题,刚入门的小白或者工作N年的光头对这个问题应该都不陌生,你要面试一个中高级工程师那么他就想”哥俩好”一样那么粘,面试官肯定会问这个问题,这篇文章我们就和它哥俩好!而且这个问题就是一个送分题,数据库的优化方案基本就是那些,答案也都是固定的,大家只要好好准备这个问题就不会住你,可以在面试中安排面试官,不然就被面试官安排!话不多说下边就针对数据库优化展开讲!
相关文章
面试开始


小伙子看你简历上写了Mysql,数据库优化了解吗?
摸摸头之后笑着说数据库优化不是很了解嘿嘿~~~,这时和蔼的面试官头上出现了一抹红!
如果这时你正好想到了我这篇文章,那么你就会说数据库优化方面我还是很有研究的,请您听我慢慢道来……
首先
面试官我想解释一下为什么做数据库优化(这个你心里知道就好了,面试的时候就不要说了)
- 系统的数据都从数据库上来,数据库的吞吐量和速度一定程度决定系统的并发和响应速度
- 系统运行与数据量成正比,数据读处理尤其是查询自然就慢
- Mysql数据库的数据最终在磁盘上持久化存储,读写不如Redis等这些内存数据库
其次
面试官大人我想说一下数据库优化一般从以下几个方面来:
- 数据库设计:数据表设计遵循三范式,使用合适的数据类型,使用合适的存储引擎
- 适当创建索引
- 数据库扩展:数据库的分表分库,读写分离等
- SQL语句优化等
接下来我们一一说明解释
数据库设计
数据库设计3范式
数据库设计范式如果要满足N范式必须要先满足N-1范式
第一范式1NF:字段原子性
第一范式简单的说就是表中的字段是最小不可再分的,我们下边举个例子,我们看到以下一张用户表。里边的字段是不可再分的,这样就符合第一范式的原子性,可能有些朋友会疑问,这个地址还可以分成省份、城市、区/县三个字段,是的!如果是一个电商项目它需要再分,那么就不符合第一范式,所以具体还是看项目的需求,没有固定标准,在项目需求中它的设计已不可再分那么就符合第一范式!
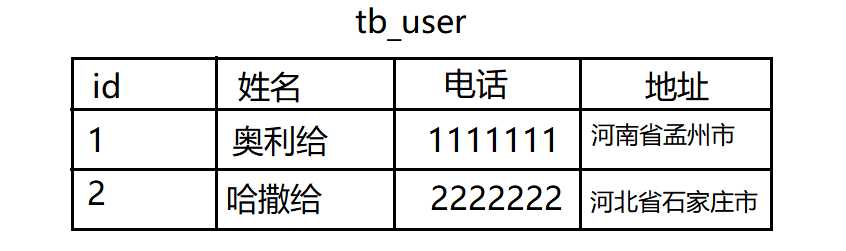
第二范式2NF: 消除对主键的部分依赖
2NF的使用是需要满足1NF为前提,在表中添加一个业务字段,而主键不用来做业务处理,比如我们的商品表有商品id,商品id为商品的主键,但是需要创建一个商品编号列来专门处理业务,因为id太敏感,我们处理业务都是用商品编号来处理,比如展示商品时展示编号等等!

第三范式3NF:在2NF的基础上添加外键
3NF的使用必须满足2NF,要求表中的每一列只与主键直接相关而不是间接相关,(表中的每一列只能依赖于主键),比如下面的例子,订单表中有客户相关信息,在分离出客户表之后,订单表中只需要有一个用户id即可(外键),而不能有其他的客户信息。因为其他的客户信息直接关联于用户id,而不是直接与订单id直接相关。如下图所示:

分离之后:
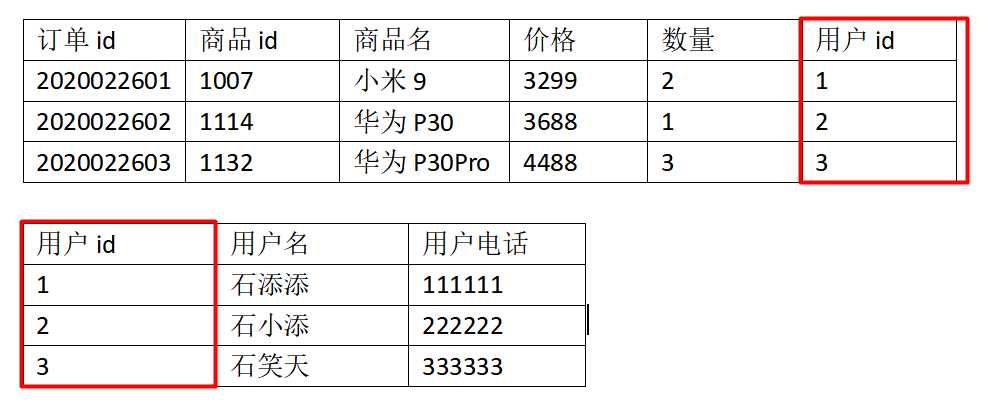
三大范式只是一般设计数据库的基本理念,可以建立冗余较小、结构合理的数据库。如果有特殊情况,当然要特殊对待,数据库设计最重要的是看需求跟性能,需求>性能>表结构。所以不能一味的去追求范式建立数据库!需求才是粑粑
数据类型
尽量使用可以正确存储数据的最小数据类型
更小的数据类型意味着更快,占用更少的磁盘,内存、缓存和处理时间
尽量使用整型表示字符串
因为字符集和校对规则,使处理字符比整型更复杂,比如:我们使用数据库内置的datetime类型存储时间而不是字符类型,我们使用整型存储ip而不是直接将ip字符串存到数据库中
尽可能使用not null
这个值是很烦人的,建字段时请尽量指定是否非空,NULL使得索引,统计,比较都变得更复杂,而且索引尽量不要创建到可以为null的字段上
字符串类型
VARCHAR是可变长字符串
比定长字符串(CHAR)更节省空间,仅使用必要的空间另外VARCHAR需要额外字节记录字符串长度(不同情况需要字节数不同)
CHAR类型是定长字符串
开发中基本很少用(一些公司甚至基本上不考虑这种类型了),注意:字符串长度定义不是字节数,是字符数
日期和时间类型
datetime
使用8字节存储空间,保存从1001年到9999年的秒数。与时区无关,默认情况下,Mysql以一种可排序的格式显示它的值,例如:”2018-10-14 22:30:08″
timestamp
只使用4字节存储,保存1970年1月1日午夜以来的秒数,依赖于系统时区,和UNIX时间戳相同,转换函数分别为FROM_UNIXTIME()和UNIX_TIMESTAMP(),可以设置根据当前时间戳更新,比如我们熟悉的update_time字段
整数类型
UNSIGNED
属性表示不允许负值,可以使得正数的上限提高一倍,比如tinyint+unsigned可以使原本的-128~127的范围变为0~255
tinyint
我们一般用它存储状态值而不要用int,如果是Boolean类型,那么tinyint(1)当值为1和0时,查询结果自动转为true和false,条件参数相应的也可以直接传入true和false即可
INT(11)
不会限制值的范围,只是规定了一些客户端工具用来显示的字符的个数,所以对于存储和计算来说INT(11)和INT(1)相同
IP地址
实际上是32位无符号整数,用INT存储,Mysql提供转换函数为INET_ATON()和INET_NTOA()
小数
decimal不会损失精度,存储空间会随数据的增大而增大。double占用固定空间,较大数的存储会损失精度,通常存金额用decimal(11,2),这表示整数部分和小数部分分别为9位和2位注意!,当然可以根据具体的金额大小选择长度,注意这时候对应的java中用BigDecimal类来处理运算时要仔细,因为加减法和比较跟平常不一样
存储引擎
介绍
数据库存储引擎是数据库底层组件,数据库管理系统使用数据引擎进行创建、查询、更新和删除数据操作。不同的存储引擎提供不同的存储机制、索引技巧、锁定水平等功能,使用不同的存储引擎还可以获得特定的功能。我们可以通过SHOW ENGINES;
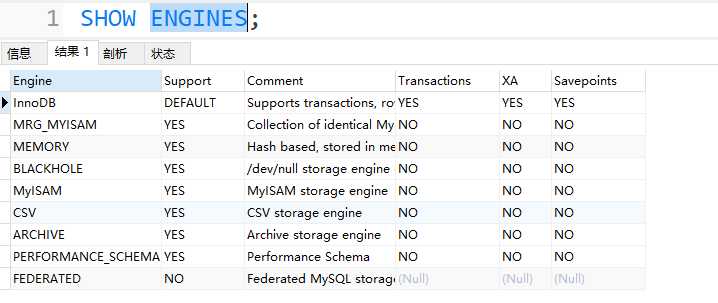
InnoDB存储引擎
InnoDB越做越好从MySQL5.5版本之后,MySQL的默认内置存储引擎已经是InnoDB,主要特点有
- 容灾恢复性比较好
- 支持事务,默认事务隔离界别为可重复读
- 使用的锁粒度为行锁,可以支持更高的并发
- 支持外键
- 配合一些热备工具可以支持在线热备份
- 在InnoDB中存在着缓冲管理,通过缓冲池,将索引和数据全部缓存起来,加快查询的速度
- 对于InnoDB类型的表,其数据的物理组织形式是聚簇表。所有的数据按照主键来组织。根据主键进行排序,数据和索引放在一块,都位于B+数的叶子节点上
MyISAM存储引擎
在5.5版本之前,MyISAM是MySQL的默认存储引擎,该存储引擎并发性差,不支持事务,所以使用场景比较少,主要特点有
- 不支持事务
- 不支持外键,如果强行增加外键,不会提示错误,只是外键不其作用
- 对数据的查询缓存只会缓存索引,不会像InnoDB一样缓存数据,而且是利用操作系统本身的缓存
- 默认的锁粒度为表级锁,所以并发度很差,加锁快,锁冲突较少,所以不太容易发生死锁
- 支持全文索引(MySQL5.6之后,InnoDB存储引擎也对全文索引做了支持),但是MySQL的全文索引基本不会使用,对于全文索引,现在有其他成熟的解决方案,比如:ElasticSearch,Solr,Sphinx等
- 数据库所在主机如果宕机,MyISAM的数据文件容易损坏,而且难恢复
MEMORY存储引擎
将数据存在内存中,和市场上的Redis,memcached等思想类似,为了提高数据的访问速度,主要特点有
- 支持的数据类型有限制,不支持TEXT和BLOB类型,对于字符串类型的数据,只支持固定长度的行,VARCHAR会被自动存储为CHAR类型
- 支持的锁粒度为表级锁。所以,在访问量比较大时,表级锁会成为MEMORY存储引擎的瓶颈
- 由于数据是存放在内存中,所以在服务器重启之后,所有数据都会丢失
- 查询的时候,如果有用到临时表,而且临时表中有BLOB,TEXT类型的字段,那么这个临时表就会转化为MyISAM类型的表,性能会急剧降低
ARCHIVE存储引擎
ARCHIVE存储引擎适合的场景有限,由于其支持压缩,故主要是用来做日志,流水等数据的归档,主要特点有
- 支持Zlib压缩,数据在插入表之前,会先被压缩
- 仅支持SELECT和INSERT操作,存入的数据就只能查询,不能做修改和删除;
- 只支持自增键上的索引,不支持其他索引
CSV存储引擎
数据中转试用,主要特点有
- 其数据格式为.csv格式的文本,可以直接编辑保存
- 导入导出比较方便,可以将某个表中的数据直接导出为csv,试用Excel办公软件打开
选择依据
如果没有特殊需求默认使用InnoDB引擎即可
MyISAM:以读写插入为主的应用程序,比如博客系统、新闻门户网站。
Innodb:更新(删除)操作频率也高,或者要保证数据的完整性;并发量高,支持事务和外键保证数据完整性。比如OA自动化办公系统
索引
已为客官备好,轻点哦《这小伙子把MySQL索引使用讲的真明白,真好,快来戳他》
索引数据结构在这在这《搞懂MySQL数据库索引数据结构这一篇足够从此不再萌萌哒》
MySQL读写分离
MySQL分表分库
一样点一下就成《手把手基于Mycat实现MySQL数据拆分》
SQL优化
这里列举出来一些用过的,看到的欢迎大家评论区补充讨论
1、查询尽量避免全表扫描,首先考虑在where、order by字段上添加索引
2、避免在where字段上使用NULL值,所以在设计表时尽量使用NOT NULL约束,有些数据会默认为NULL,可以设置默认值为0或者-1
3、避免在where子句中使用!=或<>操作符,Mysql只对<,<=,=,>,>=,BETWEEN,IN,以及某些时候的LIKE使用索引
4、避免在where中使用OR来连接条件,否则可能导致引擎放弃索引来执行全表扫描,可以使用UNION进行合并查询
select id from t where num = 30 union select id from t where num = 40;
5、尽量避免在where子句中进行函数或者表达式操作
6、最好不要使用select * from t,用具体的字段列表代替”*”,不要返回用不到的任何字段
7、in 和 not in 也要慎用,否则会导致全表扫描,如
select id from t where num IN(1,2,3)如果是连续的值建议使用between and,select id from t where between 1 and 3;
8、select id from t where col like %a%;模糊查询左侧有%会导致全表检索,如果需要全文检索可以使用全文搜索引擎比如es,slor
9、limit offset rows关于分页查询,尽量保证不要出现大的offset,比如limit 10000,10相当于对已查询出来的行数弃掉前10000行后再取10行,完全可以加一些条件过滤一下(完成筛选),而不应该使用limit跳过已查询到的数据。这是一个==offset做无用功==的问题。对应实际工程中,要避免出现大页码的情况,尽量引导用户做条件过滤
关注本系列文章的朋友应该发现,这里的未完待续已经消失,我们的MySQL优化就告一段落,主要从数据库设计、索引、数据库拆分和SQL语句上进行优化,更多优化方案希望大家通过评论区留言!
路漫漫其修远兮,吾将上下而求索
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/215874.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
