大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
文章内容引用自 咕泡科技
咕泡出品,必属精品
前置知识:
所谓的
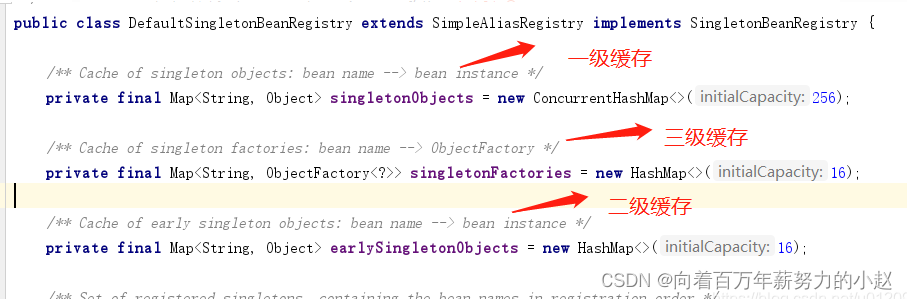
三级缓存只是三个可以当作是全局变量的Map,Spring的源码中大量使用了这种
先将数据放入容器中等使用结束再销毁的代码风格

Spring的初始化过程大致有四步
- 创建beanFactory,加载配置文件
- 解析配置文件转化beanDefination,获取到bean的所有属性、依赖及初始化用到的各类处理器等
- 刷新beanFactory容器,初始化所有单例bean
- 注册所有的单例bean并返回可用的容器
我们说的循环依赖就是第四步在给Bean属性注入的时候发生的一个问题
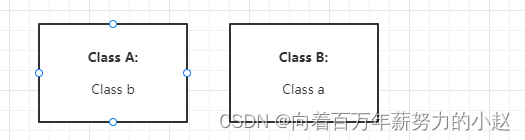
1什么是循环依赖
循环依赖就是:
假设有两个类 A和B,A中需要注入B,B中需要注入A
由于A注入B时B没有创建,B创建时A也无法创建导致的死循环问题
2 如何解决循环依赖
我们都知道AOP是Spring的一个重要核心思想,其实现就是根据动态代理来实现的,也就是说我们的Bean其实很大概率都是要生成代理类,让我们先来看无代理的情况:
Bean的初始化大概是这样的:
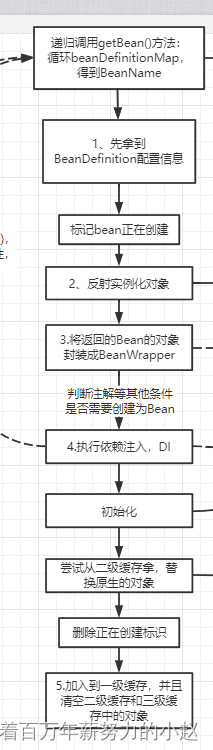
根据以上步骤可以看出bean初始化是一个相当复杂的过程,假如初始化A bean时,发现A bean依赖B bean,即A初始化执行到了第4步填充属性,需要注入B bean,此时B还没有初始化,则需要暂停A,先去初始化B,那么此时new出来的A对象放哪里,直接放在容器Map里显然不合适,半残品怎么能用,所以需要提供一个可以标记创建中bean(A)的Map,可以提前暴露正在创建的bean供其他bean依赖,而如果初始化A所依赖的bean B时,发现B也需要注入一个A的依赖(即发生循环依赖),则B可以从创建中的beanMap中直接获取A对象(创建中)注入A,然后完成B的初始化,返回给正在注入属性的A,最终A也完成初始化,皆大欢喜。
如果没有循环依赖,A 依赖B,就是创建B,B依赖C就去创建C,创建完了逐级返回就行,并不需要什么缓存,所以,一级缓存之后的其他缓存(二三级缓存)就是为了解决循环依赖而设立的
一级缓存其实就是我们的成熟的Bean了,可以直接被使用
我们去看一下源码:
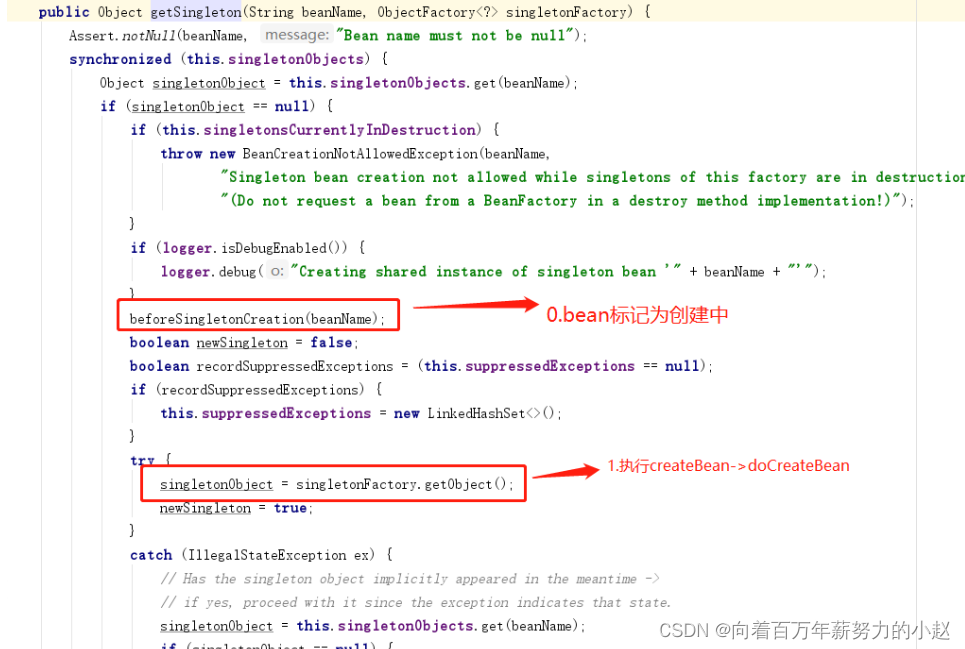
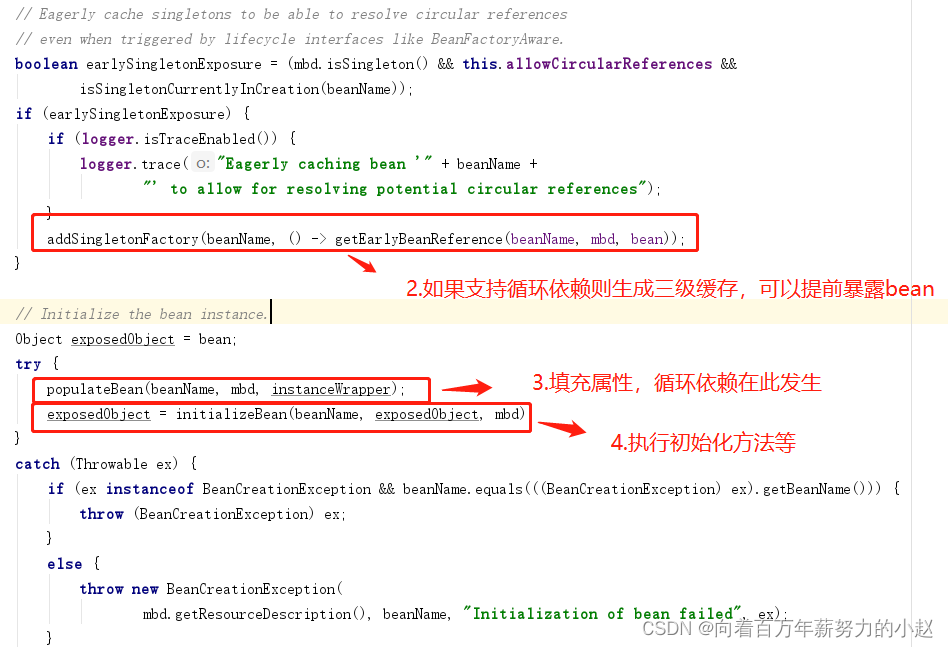
从源码中我们可以看到,三级缓存里放的并不是实例化的Bean,而是一个工厂,这是为什么呢?
循环依赖在实际应用可能会有,但很少,简单的应用场景是: controller注入service,service注入mapper,只有复杂的业务,可能service互相引用,有可能出现循环依赖,所以为了出现循环依赖才去解决,不出现就不解决,虽然支持循环依赖,但是只有在出现循环依赖时才真正暴露早期对象,否则只暴露个获取bean的方法,并没有真正暴露bean,因为这个方法不会被执行到,这块的实现就是三级缓存(singletonFactories),只缓存了一个单例bean工厂。
为什么是一个工厂?或者说这个工厂的作用?
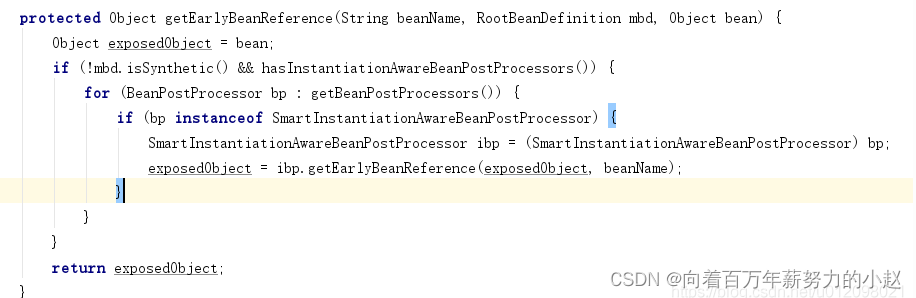
三级缓存bean工厂的getObject方式,实际执行的是getEarlyBeanReference,如果对象需要被代理(存在beanPostProcessors -> SmartInstantiationAwareBeanPostProcessor),则提前生成代理对象。
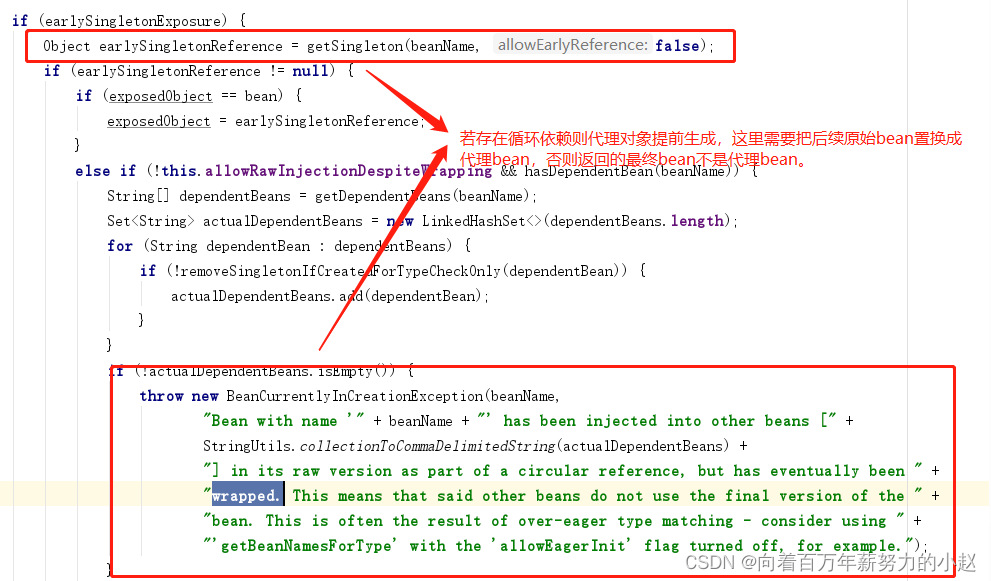
三级缓存已经解决所有问题了,二级缓存用来做什么呢?为什么三级缓存不直接叫做二级缓存?这个应该是在缓存使用时决定的:

此时这个方法中的判断逻辑是:
- 一级缓存中没有
- 对象A确实正在创建中
- 二级缓存中也没有
- 最终去三级缓存中获取对象,从三级缓存获取后把对象从三级缓存删除然后放入到二级缓存中,由于当初放入到三级缓存中的是一个工厂,所以从三级缓存中拿对象是调用getEarlyBeanReference这个方法获取,这个方法的作用是如果对象需要代理,那么就返回代理类,如果不需要代理就返回原生类,至此属性注入A完成
那么为什么要把对象从三级缓存放到二级缓存呢?
给大家一个循环依赖的流程图,大家一看便知:
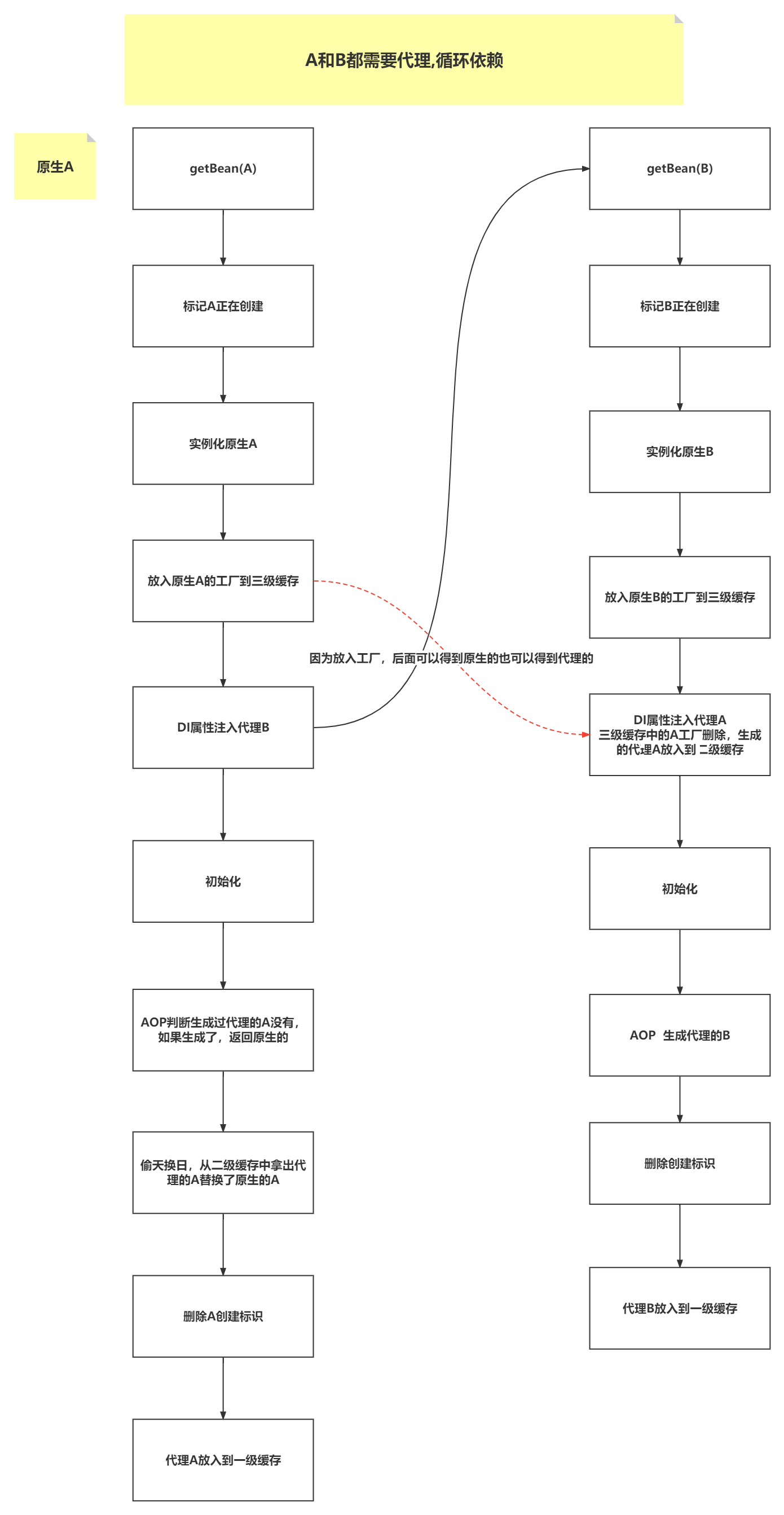
看到了吗,如果AB都需要代理,我们在A的属性注入时创建了B,但是此时A还是原生的A,但是我们需要代理A,而代理A在B注入A时已经创建并放入二级缓存中了,我们直接从二级缓存拿然后替换原生A即可。
所以,我理解的是二级缓存是为了应对代理这个情况而生的
至此,循环依赖的问题已经完美解决
3无法解决的循环依赖
构造函数循环依赖
如果我们的成员属性是在构造函数里呢?
首先要解决循环依赖就是要先实例化,然后放入三级缓存暴露出来,那么如果是构造函数这一步循环依赖,
实例化的时候就会产生无限递归创建,所以不能解决
多例的循环依赖
如果是多例的,在容器初始化的时候,不会去创建,所以早期没有放入到三级缓存中暴露出来,所以无法解决循环依赖,会报错
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/215571.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
