大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
目录
交叉验证是什么?
在模型建立中,通常有两个数据集:训练集(train)和测试集(test)。训练集用来训练模型;测试集是完全不参与训练的数据,仅仅用来观测测试效果的数据。
一般情况下,训练的结果对于训练集的拟合程度通常还是挺好的,但是在测试集总的表现却可能不行。比如下面的例子:
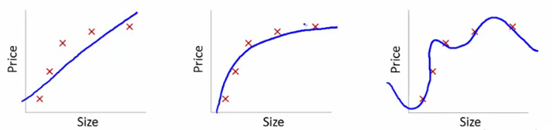

- 图一的模型是一条线型方程。 可以看到,所有的红点都不在蓝线上,所以导致了错误率很高,这是典型的不拟合的情况
- 图二 的蓝线则更加贴近实际的红点,虽然没有完全重合,但是可以看出模型表示的关系是正确的。
- 图三,所有点都在蓝线上,这时候模型计算出的错误率很低,(甚至将噪音都考虑进去了)。这个模型只在训练集中表现很好,在测试集中的表现就不行。 这是典型的‘过拟合’情况。
所以,训练的模型需要找出数据之间‘真正’的关系,避免‘过拟合’的情况发生。
交叉验证:就是在训练集中选一部分样本用于测试模型。
保留一部分的训练集数据作为验证集/评估集,对训练集生成的参数进行测试,相对客观的判断这些参数对训练集之外的数据的符合程度。
留一验证(LOOCV,Leave one out cross validation )
只从可用的数据集中保留一个数据点,并根据其余数据训练模型。此过程对每个数据点进行迭代,比如有n个数据点,就要重复交叉验证n次。例如下图,一共10个数据,就交叉验证十次
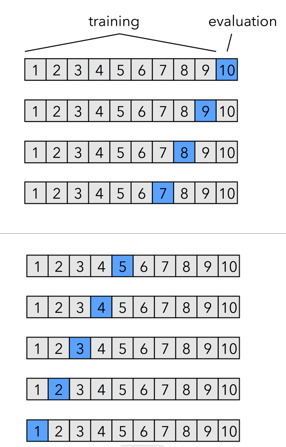
优点:
- 适合小样本数据集
- 利用所有的数据点,因此偏差将很低
缺点:
- 重复交叉验证过程n次导致更高的执行时间
- 测试模型有效性的变化大。因为针对一个数据点进行测试,模型的估计值受到数据点的很大影响。如果数据点被证明是一个离群值,它可能导致更大的变化
LOOCC是保留一个数据点,同样的你也可以保留P个数据点作为验证集,这种方法叫LPOCV(Leave P Out Cross Validation)
LOOCC代码
R
score = list()
LOOCV_function = function(x,label){
for(i in 1:nrow(x)){
training = x[-i,]
model = #... train model on training
validation = x[i,]
pred = predict(model, validation[,setdiff(names(validation),label)])
score[[i]] = rmse(pred, validation[[label]]) # score/error of ith fold
}
return(unlist(score)) # returns a vector
}
验证集方法
交叉验证的步骤如下:
- 保留一个样本数据集, (取出训练集中20%的样本不用)
- 使用数据集的剩余部分训练模型 (使用另外的80%样本训练模型)
- 使用验证集的保留样本。(完成模型后,在20%的样本中测试)
- 如果模型在验证数据上提供了一个肯定的结果,那么继续使用当前的模型。
优点: 简单方便。直接将训练集按比例拆分成训练集和验证集,比如50:50。
缺点: 没有充分利用数据, 结果具有偶然性。如果按50:50分,会损失掉另外50%的数据信息,因为我们没有利用着50%的数据来训练模型。
验证集方法代码
Python 使用train_test_split
from sklearn.model_selection import train_test_split
train, validation = train_test_split(data, test_size=0.50, random_state = 5)
用train_test_split,划分成train 和test 两部分,其中train用来训练模型,test用来评估模型,模型通过fit方法从train数据集中学习,调用score方法在test集上进行评估。
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
#已经导入数据
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=20, shuffle=True)
# Logistic Regression
model = LogisticRegression()
model.fit(X_train, y_train)
prediction = model.predict(X_test)
print('The accuracy of the Logistic Regression is: {0}'.format(metrics.accuracy_score(prediction,y_test)))
R
set.seed(101) # Set Seed so that same sample can be reproduced in future also
# Now Selecting 50% of data as sample from total 'n' rows of the data
sample <- sample.int(n = nrow(data), size = floor(.50*nrow(data)), replace = F)
train <- data[sample, ]
test <- data[-sample, ]
K折交叉验证(k-fold cross validation)
针对上面通过train_test_split划分,从而进行模型评估方式存在的弊端,提出Cross Validation 交叉验证。
Cross Validation:简言之,就是进行多次train_test_split划分;每次划分时,在不同的数据集上进行训练、测试评估,从而得出一个评价结果;如果是5折交叉验证,意思就是在原始数据集上,进行5次划分,每次划分进行一次训练、评估,最后得到5次划分后的评估结果,一般在这几次评估结果上取平均得到最后的 评分。k-fold cross-validation ,其中,k一般取5或10。
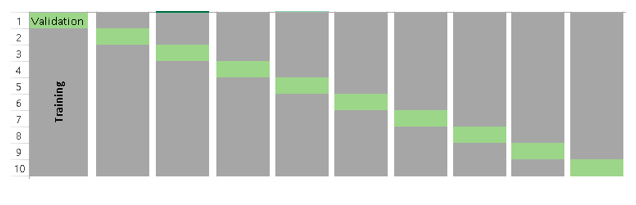
- 训练模型需要在大量的数据集基础上,否则就不能够识别数据中的趋势,导致错误产生
- 同样需要适量的验证数据点。 验证集太小容易导致误差
- 多次训练和验证模型。需要改变训练集和验证集的划分,有助于验证模型。
步骤: - 随机将整个数据集分成k折;
- 如图中所示,依次取每一折的数据集作验证集,剩余部分作为训练集
- 算出每一折测试的错误率
- 取这里K次的记录平均值 作为最终结果
优点:
- 适合大样本的数据集
- 经过多次划分,大大降低了结果的偶然性,从而提高了模型的准确性。
- 对数据的使用效率更高。train_test_split,默认训练集、测试集比例为3:1。如果是5折交叉验证,训练集比测试集为4:1;10折交叉验证训练集比测试集为9:1。数据量越大,模型准确率越高。
缺点:
- 对数据随机均等划分,不适合包含不同类别的数据集。比如:数据集有5类数据(ABCDE各占20%),抽取出来的也正好是按照类别划分的5类,第一折全是A,第二折全是B……这样就会导致,模型学习到测试集中数据的特点,用BCDE训练的模型去测试A类数据、ACDE的模型测试B类数据,这样准确率就会很低。
如何确定K值?
- 一般情况下3、5是默认选项,常建议用K=10。
- k值越低,就越有偏差;K值越高偏差就越小,但是会受到很大的变化。
- k值越小,就越类似于验证集方法;而k值越大,则越接近LOOCV方法。
k-fold代码
Python 使用cross_val_score或者KFold
cross_val_score直接将整个交叉验证过程连接起来。
from sklearn.model_selection import cross_val_score
model = LogisticRegression()
scores = cross_val_score(model,X, y,cv=3) #cv:默认是3折交叉验证,可以修改cv=5,变成5折交叉验证。
print("Cross validation scores:{}".format(scores))
print("Mean cross validation score:{:2f}".format(scores.mean()))
KFold 可以显示具体的划分情况。
from sklearn.model_selection import KFold
kf = KFold(n_splits=5, random_state=None) # 5折
#显示具体划分情况
for train_index, test_index in kf.split(X):
print("Train:", train_index, "Validation:",test_index)
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
i = 1
for train_index, test_index in kf.split(X, y):
print('\n{} of kfold {}'.format(i,kf.n_splits))
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
model = LogisticRegression(random_state=1)
model.fit(X_train, y_train)
pred_test = model.predict(X_test)
score = metrics.accuracy_score(y_test, pred_test)
print('accuracy_score', score)
i += 1
#pred_test = model.predict(X_test)
pred = model.predict_proba(X_test)[:, 1]
R code
library(caret)
data(iris)
# Define train control for k fold cross validation
train_control <- trainControl(method="cv", number=10)
# Fit Naive Bayes Model
model <- train(Species~., data=iris, trControl=train_control, method="nb")
# Summarise Results
print(model)
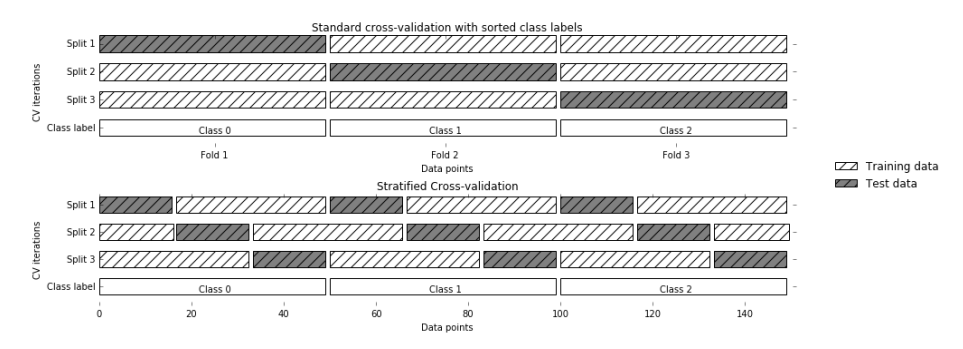
分层交叉验证 (Stratified k-fold cross validation)
分层是重新将数据排列组合,使得每一折都能比较好地代表整体。
比如下面这个例子:在一个二分类问题上,原始数据一共有两类(F和M),F:M的数据量比例大概是 1:3;划分了5折,每一折中F和M的比例都保持和原数据一致(1:3)。
这样就避免了随机划分可能产生的的情况,像是一折全是F,其他3折都是M。
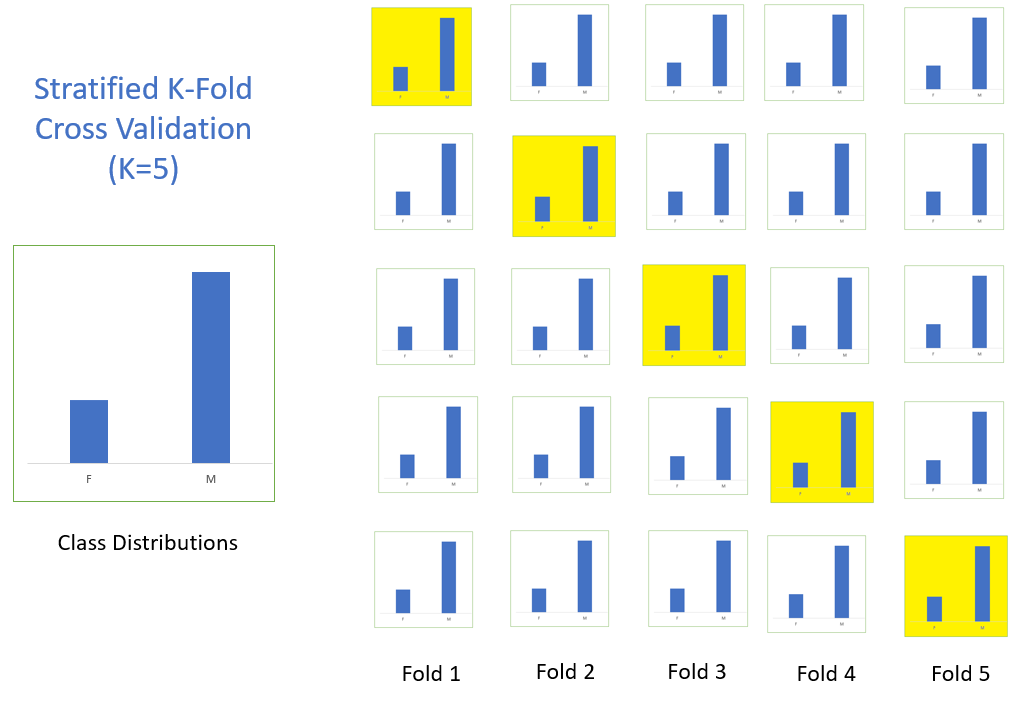
下图是标准交叉验证和分层交叉验证的区别:
标准交叉验证(即K折交叉验证):直接将数据分成几折;
分层交叉验证:先将数据分类(class1,2,3),然后在每个类别中划分三折。
分层验证代码
Python 使用cross_val_score和StratifiedKFold
from sklearn.model_selection import StratifiedKFold
skf = StratifiedKFold(n_splits=5,shuffle=False,random_state=0)
# X is the feature set and y is the target
for train_index, test_index in skf.split(X,y):
print("Train:", train_index, "Validation:", test_index)
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
model = LogisticRegression()
scores = cross_val_score(model,X,y,cv=skf)
print("straitified cross validation scores:{}".format(scores))
print("Mean score of straitified cross validation:{:.2f}".format(scores.mean()))
** R code**
library(caret)
# Folds are created on the basis of target variable
folds <- createFolds(factor(data$target), k = 10, list = FALSE)
重复交叉验证( k-fold cross validation with repetition)
如果训练集不能很好地代表整个样本总体,分层交叉验证就没有意义了。这时候,可以使用重复交叉验证。
重复验证代码
Python:RepeatedKFold重复K折交叉验证
kf = RepeatedKFold(n_splits=5, n_repeats=2, random_state=None) #默认是5折
for train_index, test_index in kf.split(X):
print("Train:", train_index, "Validation:",test_index)
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
i = 1
for train_index, test_index in kf.split(X, y):
print('\n{} of kfold {}'.format(i,i))
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
model = LogisticRegression(random_state=1)
model.fit(X_train, y_train)
pred_test = model.predict(X_test)
score = metrics.accuracy_score(y_test, pred_test)
print('accuracy_score', score)
i += 1
#pred_test = model.predict(X_test)
pred = model.predict_proba(X_test)[:, 1]
对抗验证(Adversarial Validation)
在处理实际数据集时,经常会出现测试集和训练集截然不同的情况。因此,可能导致交叉验证结果不一致
在这种情况下,可以使用对抗验证法:总体思路是根据特征分布创建一个分类模型,以检查训练集和测试集之间的相似程度。
步骤:
- 组合训练集和测试集;
- 分配0/1标签(0-训练、1-测试);
- 建立模型,(如果模型AUC在0.7以上,表示分类器表现较好,也间接说明train 和test 差异度较大
- 评估二进制分类任务来量化两个数据集的分布是否一致;
- 找出和测试集最相似的数据样本
- 构成与测试集最相似的验证集;
优点: 使验证策略在训练集和测试集高度不同的情况下更加可靠。
缺点: 一旦测试集的分布发生变化,验证集可能不再适合评估模型。
对抗验证代码
#1. 将目标变量删除
train.drop(['target'], axis = 1, inplace = True)
#2. 创建新的目标变量:训练集为1;测试集为0
train['is_train'] = 1
test['is_train'] = 0
#3. 合并训练集和测试集
df = pd.concat([train, test], axis = 0)
#4. 使用新变量训练分类模型,并预测概率
y = df['is_train']; df.drop('is_train', axis = 1, inplace = True)
# Xgboost parameters
xgb_params = {
'learning_rate': 0.05,
'max_depth': 4,
'subsample': 0.9,
'colsample_bytree': 0.9,
'objective': 'binary:logistic',
'silent': 1,
'n_estimators':100,
'gamma':1,
'min_child_weight':4}
clf = xgb.XGBClassifier(**xgb_params, seed = 10)
probs = clf.predict_proba(x1)[:,1]
#5. 使用步骤4中计算的概率对序列集进行排序,并将前n%个样本/行作为验证集(n%是您希望保留在验证集中的序列集的分数)
new_df = pd.DataFrame({
'id':train.id, 'probs':probs})
new_df = new_df.sort_values(by = 'probs', ascending=False) # 30% validation set
val_set_ids = new_df.iloc[1:np.int(new_df.shape[0]*0.3),1]
#val_set_ids将为提供列训练集的ID,这些ID将构成与测试集最相似的验证集。
时间序列的交叉验证(Cross Validation for time series)
对于时间序列的数据集,不能像上述方法一样随机地划分验证集。为了解决时间序列的预测问题,可以尝试时间序列交叉验证:采用正向链接的策略,即按照时间顺序划分每一折的数据集。
假设我们有一个时间序列,表示在n年内消费者对某一产品的年需求量。
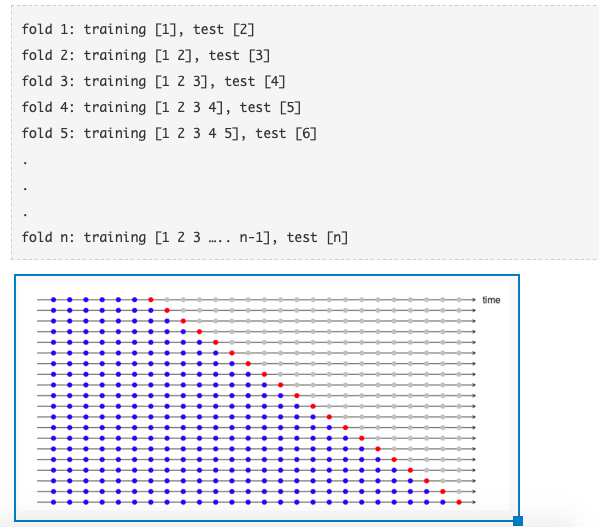
我们逐步选择新的训练集和测试集。我们从一个最小的训练集开始(这个训练集具有拟合模型所需的最少观测数)逐步地,每次都会更换训练集和测试集。在大多数情况下,不必一个个点向前移动,可以设置一次跨5个点/10个点。在回归问题中,可以使用以下代码执行交叉验证。
时间序列代码
pythonTimeSeriesSplit
from sklearn.model_selection import TimeSeriesSplit
X = np.array([[1, 2], [3, 4], [1, 2], [3, 4]])
y = np.array([1, 2, 3, 4])
tscv = TimeSeriesSplit(n_splits=3)
for train_index, test_index in tscv.split(X):
print("Train:", train_index, "Validation:", val_index)
X_train, X_test = X[train_index], X[val_index]
y_train, y_test = y[train_index], y[val_index]
TRAIN: [0] TEST: [1]
TRAIN: [0 1] TEST: [2]
TRAIN: [0 1 2] TEST: [3]
R code
library(fpp)
library(forecast)
e <- tsCV(ts, Arima(x, order=c(2,0,0), h=1) #CV for arima model
sqrt(mean(e^2, na.rm=TRUE)) # RMSE
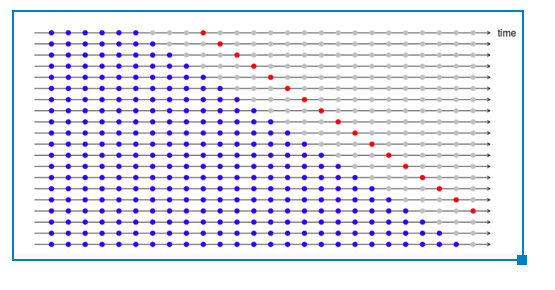
#h =1意味着我们只接受1步超前预报的误差。
#(h=4)4步前进误差如下图所示。如果想评估多步预测的模型,可以使用此选项。
参考链接:https://www.analyticsvidhya.com/blog/2018/05/improve-model-performance-cross-validation-in-python-r/
其他网上找到的有关文章:
关于时间序列的:https://zhuanlan.zhihu.com/p/99674163
关于对抗验证的:https://zhuanlan.zhihu.com/p/137580733
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/215500.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
