大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
概念:
消费者组:Consumer Group ,一个Topic的消息能被多个消费者组消费,但每个消费者组内的消费者只会消费topic的一部分
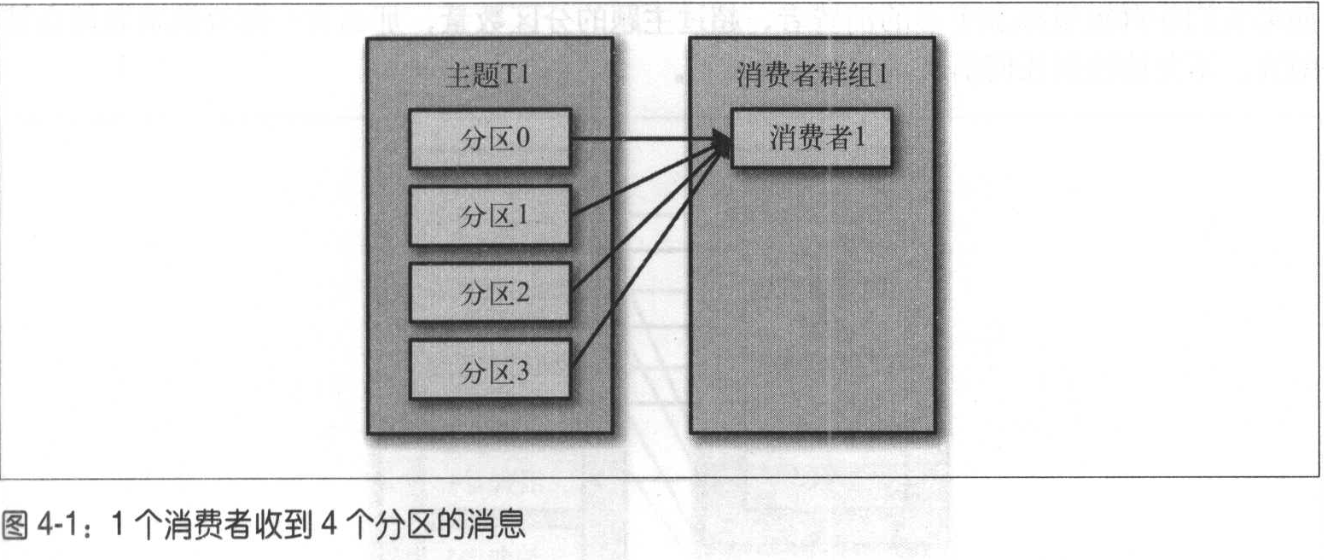

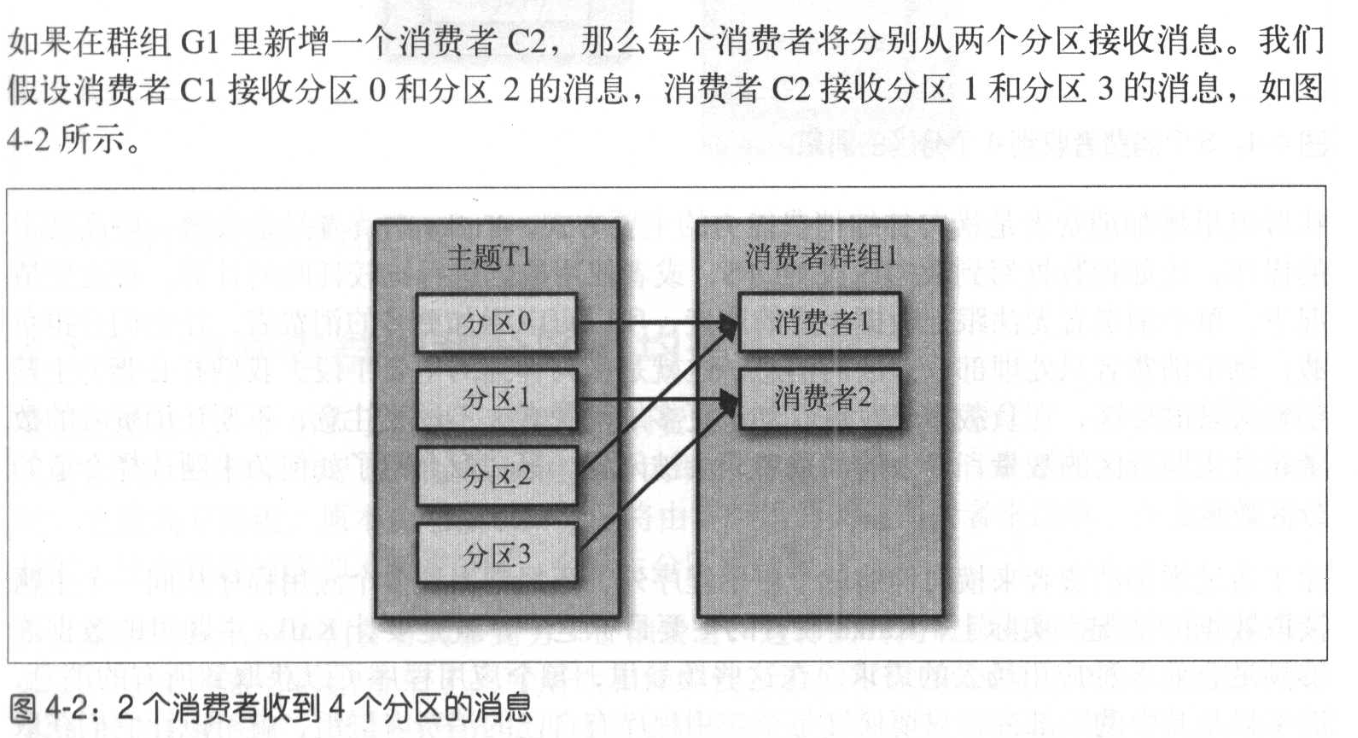
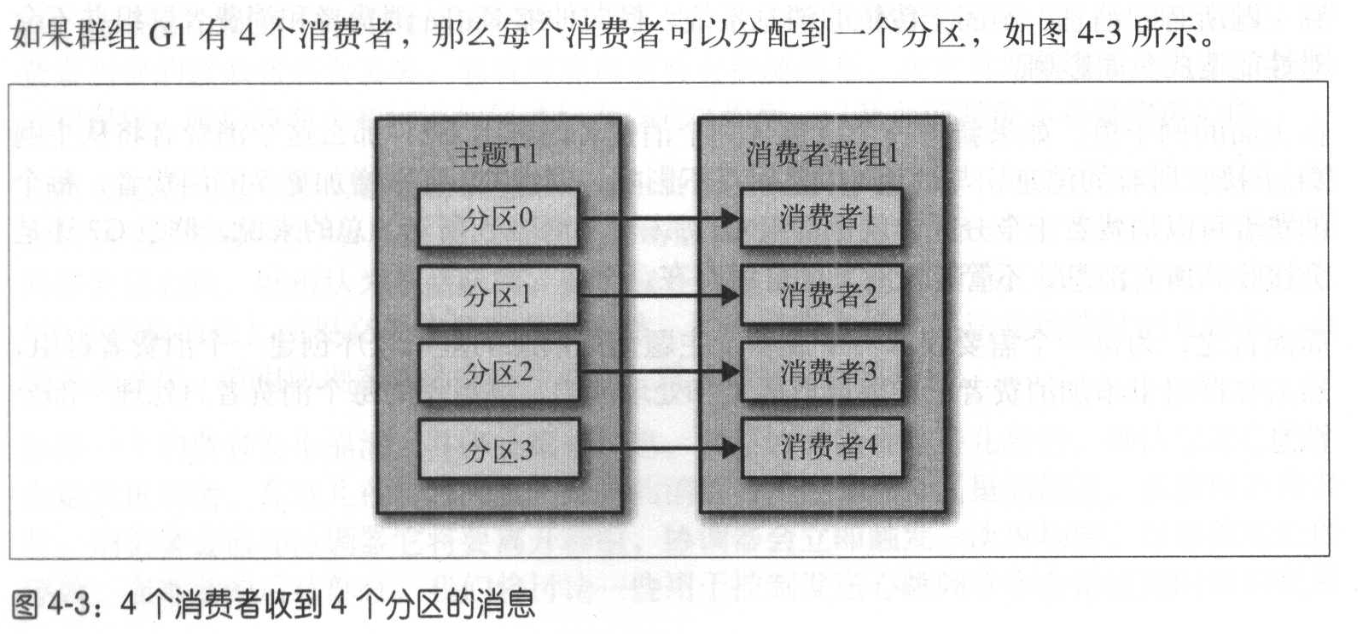
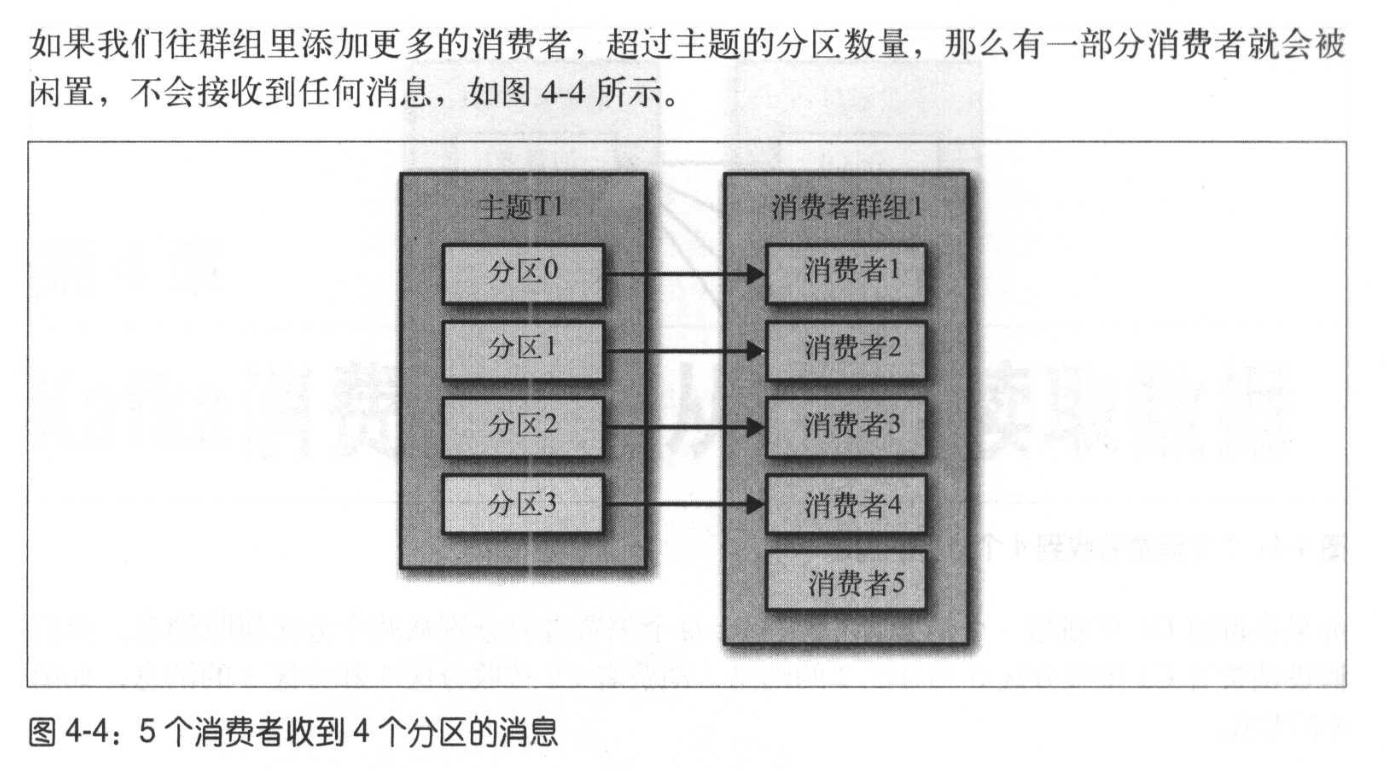
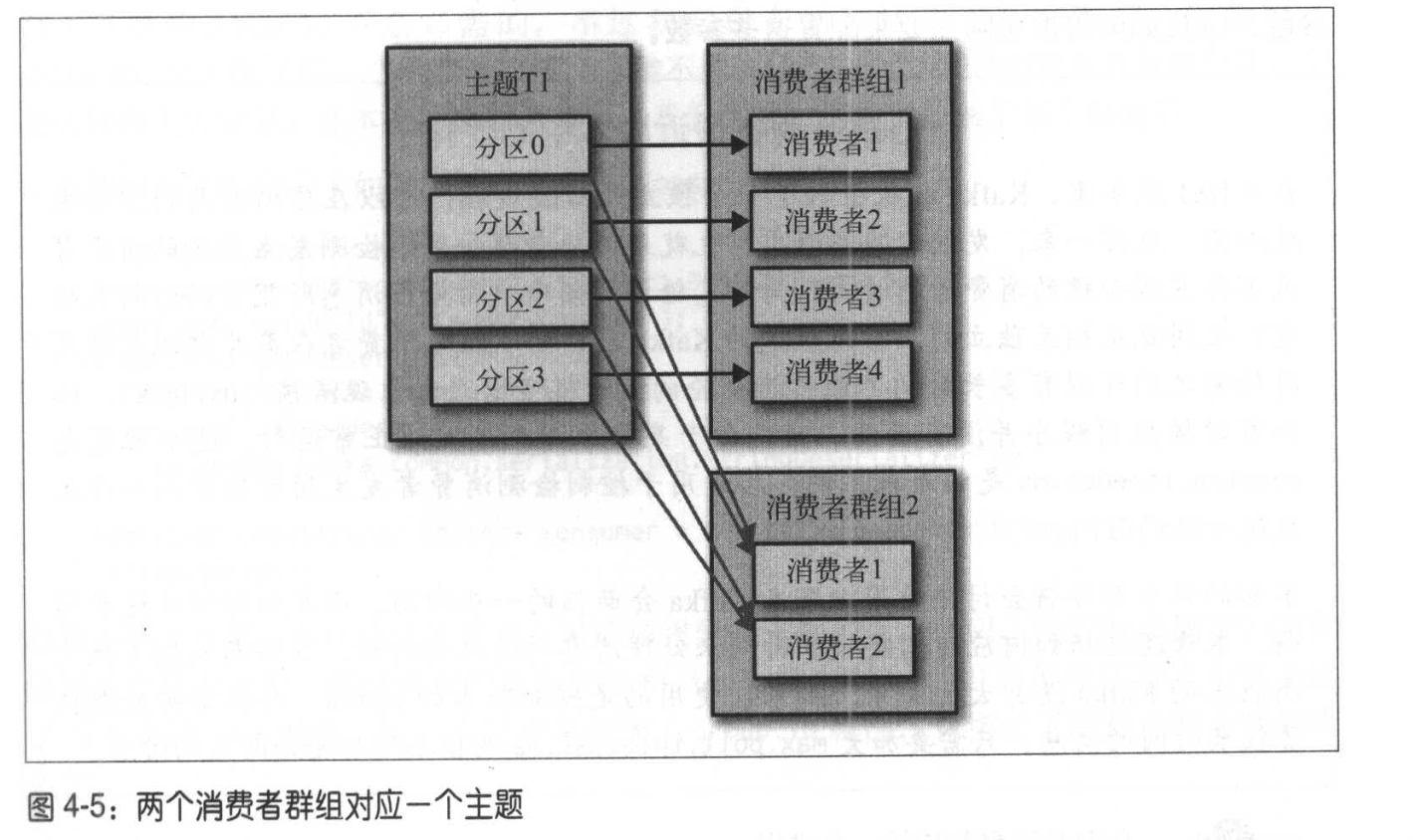
再均衡rebalance:分区的所有权从一个消费者转移到另一个消费者
消费者通过被指派为群组协调器的broker(不同的群组可以有不同的协调器) 发送心跳来维持它们和群组的从属关系以及它们对分区的所有权关系。只要消费者以正常的时间间隔发送心跳,就被认为是活跃的,说明它还在读取分区里的消息。消费者会在轮询消息或提交偏移量时发送心跳。如果消费者停止发送心跳的时间足够长,会话就会过期,群组协调器认为它已经死亡,就会触发一次再均衡。
分配分区的过程:
当消费者要加入群组时,它会向群组协调器发送一个JoinGroup请求。第一个加入群组的消费者将成为“群主”ConsumerCoordinator。群主从协调器哪里获得群组的成员列表(列表中包含了所有最近发送过心跳的消费者,它们被认为是活跃的),并负责给每一个消费者分配分区。它使用一个实现了PartitionAssignor接口的类来决定哪些分区应该被分配给哪个消费者。
分配完毕后,群主把分配情况列表发送给群组协调器,协调器再把这些信息发送给所有消费者。每个消费者只能看到自己的分配信息,只有群主知道群组里所有消费者的分配信息。
这个过程会在每次再均衡时重复发生。
使用kafka Tool 观察kafka
记录了主题topic 、分区Partition 及偏移量
当消费者poll()数据之后,如果处理的太慢,超过了max.poll.interval.ms的时间限制,则会触发rebalance,导致commit提交失败,再次拉取重复消息,再次处理超时,死循环。
这种情况可以
1.调低max.poll.records每次poll的数据量
2.调大max.poll.interval.ms
3.优化业务逻辑
以下参考:https://cloud.tencent.com/developer/article/1336570
协调器
在 kafka-0.10 版本,Kafka 在服务端引入了组协调器(GroupCoordinator),每个 Kafka Server 启动时都会创建一个 GroupCoordinator 实例,用于管理部分消费者组和该消费者组下的每个消费者的消费偏移量。同时在客户端引入了消费者协调器(ConsumerCoordinator),实例化一个消费者就会实例化一个 ConsumerCoordinator 对象,ConsumerCoordinator 负责同一个消费者组下各消费者与服务端的 GroupCoordinator 进行通信。
(1) 消费者协调器(ConsumerCoordinator)
ConsumerCoordinator 定义的位置:
public class KafkaConsumer<K, V> implements Consumer<K, V> {
private final ConsumerCoordinator coordinator;
}
ConsumerCoordinator 是 KafkaConsumer 的一个私有的成员变量,因此 ConsumerCoordinator 中存储的信息也只有与之对应的消费者可见,不同消费者之间是看不到彼此的 ConsumerCoordinator 中的信息的。
ConsumerCoordinator 的作用:
处理更新消费者缓存的 Metadata 请求
向组协调器发起加入消费者组的请求
对本消费者加入消费者前后的相应处理
请求离开消费者组(例如当消费者取消订阅时)
向组协调器发送提交偏移量的请求
通过一个定时的心跳检测任务来让组协调器感知自己的运行状态
Leader消费者的 ConsumerCoordinator 还负责执行分区的分配,一个消费者组中消费者 leader 由组协调器选出,leader 消费者的 ConsumerCoordinator 负责消费者与分区的分配,然后把分配结果发送给组协调器,然后组协调器再把分配结果返回给其他消费者的消费者协调器,这样减轻了服务端的负担
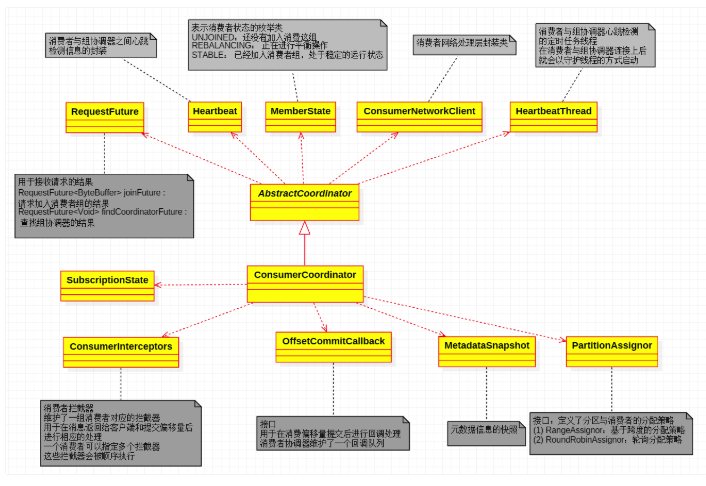
ConsumerCoordinator 实现上述功能的组件是 ConsumerCoordinator 类的私有成员或者是其父类的私有成员:
public final class ConsumerCoordinator extends AbstractCoordinator {
private final List<PartitionAssignor> assignors;
private final OffsetCommitCallback defaultOffsetCommitCallback;
private final SubscriptionState subscriptions;
private final ConsumerInterceptors<?, ?> interceptors;
private boolean isLeader = false;
private MetadataSnapshot metadataSnapshot;
private MetadataSnapshot assignmentSnapshot;
省略了部分代码....
}
public abstract class AbstractCoordinator implements Closeable {
private enum MemberState {
UNJOINED, // the client is not part of a group
REBALANCING, // the client has begun rebalancing
STABLE, // the client has joined and is sending heartbeats
}
private final Heartbeat heartbeat;
protected final ConsumerNetworkClient client;
private HeartbeatThread heartbeatThread = null;
private MemberState state = MemberState.UNJOINED;
private RequestFuture<ByteBuffer> joinFuture = null;
省略了部分代码....
}
各组件及其功能如下图所示:
(2) 组协调器(GroupCoordinator)
GroupCoordinator 的作用:
负责对其管理的组员(消费者)提交的相关请求进行处理
与消费者之间建立连接,并从与之连接的消费者之间选出一个 leader
当 leader 分配好消费者与分区的订阅关系后,会把结果发送给组协调器,组协调器再把结果返回给各个消费者
管理与之连接的消费者的消费偏移量的提交,将每个消费者的消费偏移量保存到kafka的内部主题中
通过心跳检测消费者与自己的连接状态
启动组协调器的时候创建一个定时任务,用于清理过期的消费组元数据以及过去的消费偏移量信息
GroupCoordinator 依赖的组件及其作用:
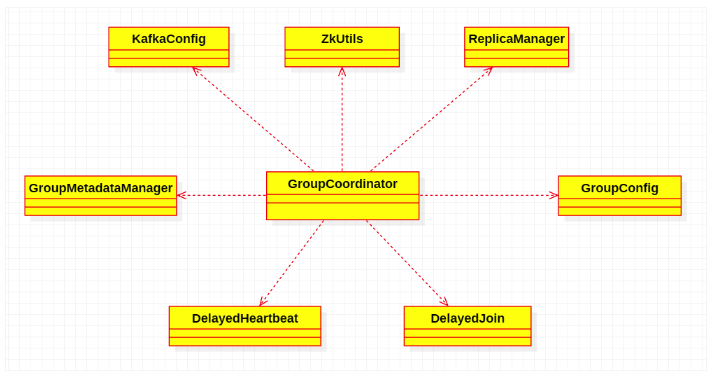
KafkaConfig:实例化 OffsetConfig 和 GroupConfig
ZkUtils:分消费者分配组协调器时从Zookeeper获取内部主题的分区元数据信息。
GroupMetadataManager:负责管理 GroupMetadata以及消费偏移量的提交,并提供了一系列的组管理的方法供组协调器调用。GroupMetadataManager 不仅把 GroupMetadata 写到kafka内部主题中,而且还在内存中缓存了一份GroupMetadata,其中包括了组员(消费者)的元数据信息,例如消费者的 memberId、leaderId、分区分配关系,状态元数据等。状态元数据可以是以下五种状态:
PreparingRebalance:消费组准备进行平衡操作
AwaitingSync:等待leader消费者将分区分配关系发送给组协调器
Stable:消费者正常运行状态,心跳检测正常
Dead:处于该状态的消费组没有任何消费者成员,且元数据信息也已经被删除
Empty:处于该状态的消费组没有任何消费者成员,但元数据信息也没有被删除,知道所有消费者对应的消费偏移量元数据信息过期。
ReplicaManager:GroupMetadataManager需要把消费组元数据信息以及消费者提交的已消费偏移量信息写入 Kafka 内部主题中,对内部主题的操作与对其他主题的操作一样,先通过 ReplicaManager 将消息写入 leader 副本,ReplicaManager 负责 leader 副本与其他副本的管理。
DelayedJoin:延迟操作类,用于监视处理所有消费组成员与组协调器之间的心跳超时
GroupConfig:定义了组成员与组协调器之间session超时时间配置
3. 消费者协调器和组协调器的交互
(1) 心跳
消费者协调器通过和组协调器发送心跳来维持它们和群组的从属关系以及它们对分区的所有权关系。只要消费者以正常的时间间隔发送心跳,就被认为是活跃的,说明它还在读取分区里的消息。消费者会在轮询获取消息或提交偏移量时发送心跳。
如果消费者停止发送心跳的时间足够长,会话就会过期,组协调器认为它已经死亡,就会触发一次再均衡。
在 0.10 版本里,心跳任务由一个独立的心跳线程来执行,可以在轮询获取消息的空档发送心跳。这样一来,发送心跳的频率(也就是组协调器群检测消费者运行状态的时间)与消息轮询的频率(由处理消息所花费的时间来确定)之间就是相互独立的。在0.10 版本的 Kafka 里,可以指定消费者在离开群组并触发再均衡之前可以有多长时间不进行消息轮询,这样可以避免出现活锁(livelock),比如有时候应用程序并没有崩溃,只是由于某些原因导致无法正常运行。这个配置与
session.timeout.ms 是相互独立的,后者用于控制检测消费者发生崩溃的时间和停止发送心跳的时间。
(2) 分区再均衡
发生分区再均衡的3种情况:
一个新的消费者加入群组时,它读取的是原本由其他消费者读取的消息。
当一个消费者被关闭或发生崩溃时,它就离开群组,原本由它读取的分区将由群组里的其他消费者来读取。如果一个消费者主动离开消费组,消费者会通知组协调器它将要离开群组,组协调器会立即触发一次再均衡,尽量降低处理停顿。如果一个消费者意外发生崩溃,没有通知组协调器就停止读取消息,组协调器会等待几秒钟,确认它死亡了才会触发再均衡。在这几秒钟时间里,死掉的消费者不会读取分区里的消息。
在主题发生变化时,比如管理员添加了新的分区,会发生分区重分配。
分区的所有权从一个消费者转移到另一个消费者,这样的行为被称为分区再均衡。再均衡非常重要,它为消费者群组带来了高可用性和伸缩性(我们可以放心地添加或移除消费者),不过在正常情况下,我们并不希望发生这样的行为。在再均衡期间,消费者无法读取消息,造成整个群组一小段时间的不可用。另外,当分区被重新分配给另一个消费者时,消费者当前的读取状态会丢失,它有可能还需要去刷新缓存,在它重新恢复状态之前会拖慢应用程序。
(3) leader 消费者分配分区的策略
当消费者要加入群组时,它会向群组协调器发送一个 JoinGroup 请求。第一个加入群组的消费者将成为leader消费者。leader消费者从组协调器那里获得群组的成员列表(列表中包含了所有最近发送过心跳的消费者,它们被认为是活跃的),并负责给每一个消费者分配分区。
每个消费者的消费者协调器在向组协调器请求加入组时,都会把自己支持的分区分配策略报告给组协调器(轮询或者是按跨度分配或者其他),组协调器选出该消费组下所有消费者都支持的的分区分配策略发送给leader消费者,leader消费者根据这个分区分配策略进行分配。
完毕之后,leader消费者把分配情况列表发送给组协调器,消费者协调器再把这些信息发送给所有消费者。每个消费者只能看到自己的分配信息,只有leader消费者知道群组里所有消费者的分配信息。这个过程会在每次再均衡时重复发生。
(4) 消费者入组过程
消费者创建后,消费者协调器会选择一个负载较小的节点,向该节点发送寻找组协调器的请求
KafkaApis 处理请求,调用返回组协调器所在的节点,过程如下:
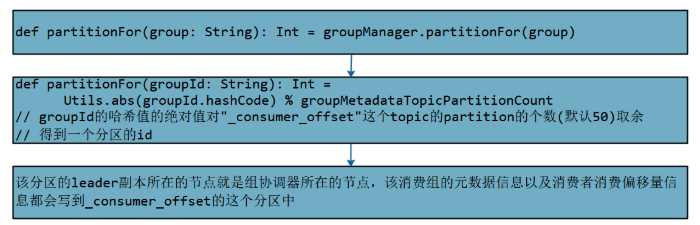
找到组协调器后,消费者协调器申请加入消费组,发送 JoinGroupRequest请求
KafkaApis 调用 handleJoinGroup() 方法处理请求
把消费者注册到消费组中
把消费者的clientId与一个UUID值生成一个memberId分配给消费者
构造器该消费者的MemberMetadata信息
把该消费者的MemberMetadata信息注册到GroupMetadata中
第一个加入组的消费者将成为leader
把处理JoinGroupRequest请求的结果返回给消费者
加入组成功后,进行分区再均衡
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/214256.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
