大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
http://blog.csdn.net/pipisorry/article/details/51788955
(个性化)推荐系统构建三大方法:基于内容的推荐content-based,协同过滤collaborative filtering,隐语义模型(LFM, latent factor model)推荐。这篇博客主要讲协同过滤。
协同过滤Collaborative Filtering
协同过滤:使用某人的行为behavior来预测其它人会做什么。协同过滤就是基于邻域的算法,分为基于用户的协同过滤算法UserCF和基于物品的协同过滤算法ItemCF。
CF has an interesting property:feature learning can start to learn for itself what features to use. (NG)
本文主要讲基于cosin相似度的非参数协同过滤算法。另一种基于低秩矩阵分解的参数协同过滤算法参考[Machine Learning – XVI. Recommender Systems 推荐系统(Week 9) ]。
基于用户的协同过滤算法UserCF
User-user collaborative filtering主要思想
对于一个用户x,首先找到与其相似的一个用户集,这个相似是通过它们的评分rating来判定的,likes和dislikes越相似,他们就越相似。然后推荐这些相似用户集喜欢的items并且预测x评分最高的items给用户x。

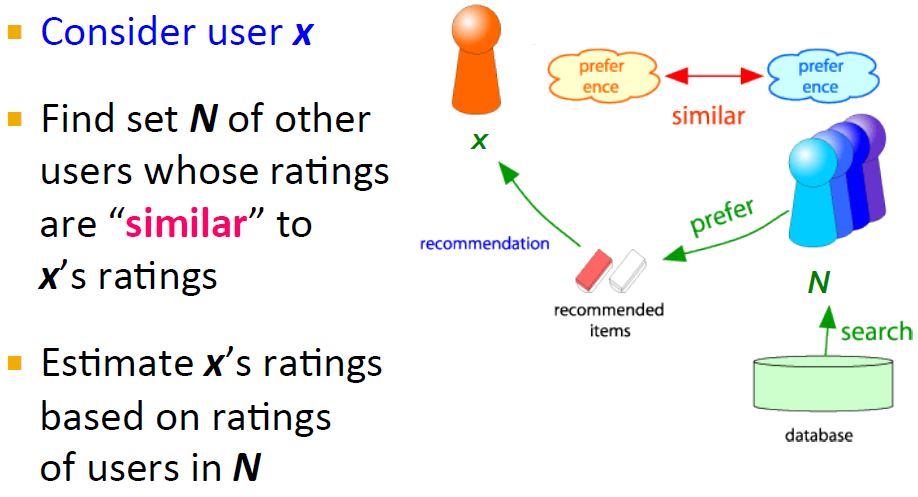
兴趣相投的用户可能带来新颖的东西。
UserCF的两个假设
Assumption: Our past agreement predicts our future agreement
Base Assumption #1: 个人品味稳定或者和品味相同的人同步迁移。Our tastes are either individually stable or move in sync with each other.
Base Assumption #2: Our system is scoped within a domain of agreement(e.g Politics, humor, technology). UserCF推荐系统中的item要是同一个领域中,不然虽然在某个领域相似,但是也不能推荐另一个用户在另一个不同的领域喜欢的东西?
UserCF要解决的问题
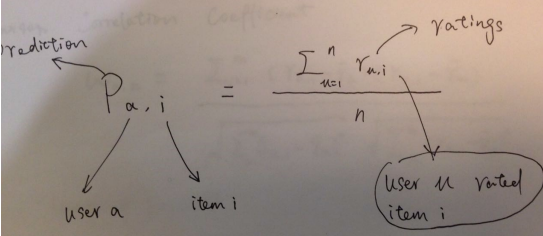
已知用户评分矩阵Matrix R(一般都是非常稀疏的),元素R_{ui}: user u 在 item I上的评分rating。
问题:推断矩阵中空格empty cells处的值。
非个性化方法的解决思路
1 直接使用对item i评分过的所有用户的平均评分作为user a对item i的评分
2 考虑到给分偏颇,计算评分均值时都减去每个单独用户的评分均值。
给分者的偏颇问题:tough raters:给分相对较小不慷慨。easy raters:给分总是比较高,慷慨。即不同用户的给分程度是不一样的,如有的用户很mean,给分都很低,有的很generous,给分都很高,所以所有用户减去其给分的均值比较好。
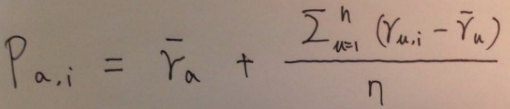
Note:
1 这个评分可能超出评分区间rating scale,但是我们是要做推荐,只要计算最大topk个item推荐出去就可以了,超出范围没关系。
2 做推荐时,user a对item i的评分pai可以不加上bar(ra),加上只是在后面的评估模型中有用。
个性化推荐的解决思路
改进上面的非个性化思路,计算均分时只考虑与当前user a相似的用户对item i的评分,这样对item i的评分都有一个权重(即user u和a的相似度)。
Note: 删除非一致值negative agreement values的邻居,即如果w_{a,u}是负值,则去掉(或者等价设置为0)。
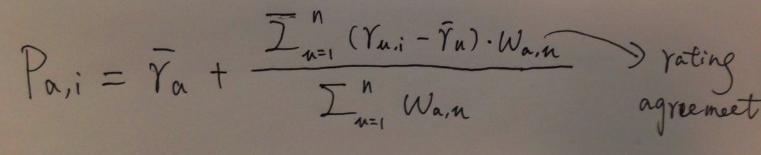
neighborhoods的选择:用户相似度量方法
用户-电影矩阵

Note: 从各自的均值分析,A喜欢TW讨厌SW1,而C喜欢SW1讨厌TW。
Jaccard Similarity

Jaccard相似度没有考虑评分,导致相似度计算错误。
Spearman rank correlation
在这里表现并不佳。
Cosine Similarity

但是由于将缺失值设为0(从上节可以看出评分为0(最小的评分值)实际上是评分为负),也没有揭示出A,B相似度远大于A,C相似度的直觉。
Centered Cosine(Pearson Correlation) 1
需要归一化减去每个user对应的所有评分的均值,考虑所有的items。(这里就相当于用每行user的均值去填充空值,这样空值就不会影响两个向量应有的点积)
Note: 这里是对每个用户的所有打分归一化,不是对每个item的打分归一化(如果有个用户没有打分,也就是cold start,这时可以使用所有item的均值作为其打分,其实就是item列的归一化了,这个和下面的改进方法使用baseline合成方法是一个道理,注意区分NG course中协同过滤)!!!
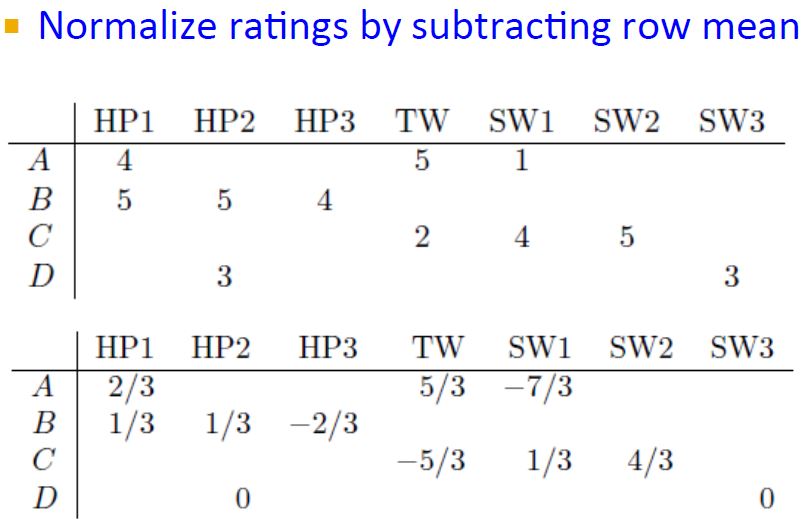
注意现在行和都为0了,也就是用户评分均值为0,>0表示喜欢,<0表示不喜欢。缺失值当然也就设置为0,表示既不like也不dislike。

皮尔逊相关系数将缺失值设置为均值,符合没打分的要求;同时也解决了给分者的偏颇问题。tough raters:给分相对较小的,不慷慨的。easy raters:给分总是比较高的,慷慨的。
Pearson Correlation Coefficient 2(lz不建议如此设计,一般也不会只考虑共同原始打分的)
这里归一化时user减去的是和当前uesr a打过分的分数均值,计算相似度时却只考虑in common的items(lz觉得这个不合理,毕竟和别人对比应该拿自己和别人相似和不相似处的一起比,而且这样做还可能导致数据更加稀疏)。

Note: 公式中 \bar{r}_u表示用户u对u和v共同打分过的items的打分均值average value over the ratings of u on the items both u and a have rated,m是user a和user u共同打分过的items数目。
U-U CF算法
For a user a
使用Pearson Correlation Coefficient计算与其它所有用户的相似度,得到最相近的邻居。Compute its similarity values to all the other users, Identify its nearest neighbors
给定a的所有邻居,预测用户a对item i的打分 With the nearest neighbors, for each item i
Predict r_{ai}
Note: 对某个用户a推荐一些items来说(只需排名而不用计算具体打分分数),\bar{r_a}和第二项分母是可以省略的。
UserCF存在的问题issues
理论问题Low coverage
对于一个新用户,几乎没有评分has only few ratings,这样就找不到邻居用户。
对于一个item,所有最近的邻居都在其上没有多少ratings。
UserCF实现问题Implementation Issues
Given m users and n items
Computation can be a bottleneck
Correlation between two users is O(n)
All correlations for a user is O(mn)
All pairwise correlations is O(m^2n)
Recommendations at least O(mn)
Lots of ways to make more practical
More persistent neighborhoods
Cached or incremental correlations
UserCF算法的改进 User-User Variations and Tuning
改进方法:Similarities; Significance weighting; Variance weighting; Selecting neighborhoods; Normalizing ratings.
1 Similarities
相似度计算最好使用Pearson Correlation Coefficient,或者Spearman ranking correlation。
2 Significance weighting
考虑共同打分items的数目,如乘上min(n,50)/50,其中n是共同打分的数目,50是cutoff number。表示的是共同打分多的两个用户相似的可能性更高。
3 Variance weighting(然并卵)
考虑每个item的rating variance。原因是,对某个item如果其评分波动大,也就是不同人有不同意见,这样item对应的评分对于比较两个用户的差异更重要(如一个大家都喜欢的评分都高的Titanic相对于一部评分波动大的恐怖片的重要性可能小些,因为喜欢恐怖片的用户和不喜欢恐怖片的用户其打分肯定相差大)。
Variance weighting
原始的Z-score based
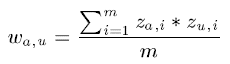
加入variance weighted的改进
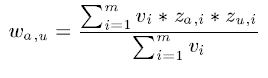
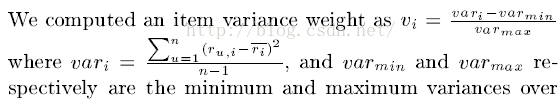
然而实验表明,这个在UserCF中并没有什么卵用。
4 Normalizing ratings
归一化的原因
即给分者的偏颇问题:Users rate differently, Some rate high, others low.
Averaging ignores these differences, Normalization compensates for them.
4.1 Rating Normalization: Mean-centering
如上所述可能超出范围,但是不影响。
4.2 Rating Normalization: z-score normalization

实际上这样对数据进行转换之后,就不用Pearson Correlation Coefficient来计算相似度了,这时的cosine相似度就和Pearson Correlation Coefficient一样的了。lz建议直接对数据进行这种变换,后面就不用考虑复杂了。
5 Selecting neighborhoods
Threshold similarity:设置一个阈值,相似度大于这个阈值就作为nerghborhoods
Top-N neighbors by similarity: 一般Top 30
Combined:这个应该更好
选择How Many Neighbors?的问题
In theory, the more the better
If we have a good similarity measure
In practice, noise from dissimilar neighbors decreases usefulness
Between 25 and 100 is often used
Fewer neighbors → lower coverage
Use the same group of neighbors for different items
Give up personalized recommendation if the neighbors do not have enough ratings on the target item
评分预测
迭代求出与x最相似的k个用户,预测x对 这k个用户也评分过的items i 的评分

[1999_SIGIR An Algorithmic Framework for Performing Collaborative Filtering.pdf]
基于物品的协同过滤算法ItemCF
ItemCF的Motivation和Idea
User-User CF的问题
稀疏问题Issues of Sparsity
Amazon: millions of items, each user rates hundreds of items
With large item sets, small numbers of ratings, too often there are points where no recommendation can be made
解决方案包括:item-item, dimensionality reduction
计算性能Computational performance
With millions of users (or more), computing all-pairs correlations is expensive
Even incremental approaches were expensive
用户属性user profiles可能变化很快– needed to compute in real time to make users happy
The Item-Item Insight
Item-Item相似度相对更稳定fairly stable:
依赖于用户数比item数更多。Average item has many more ratings than an average user
Intuitively, items don’t generally change rapidly – at least not in ratings space (special case for time-bound items)
Item similarity is a route to computing a prediction of a user’s item preference
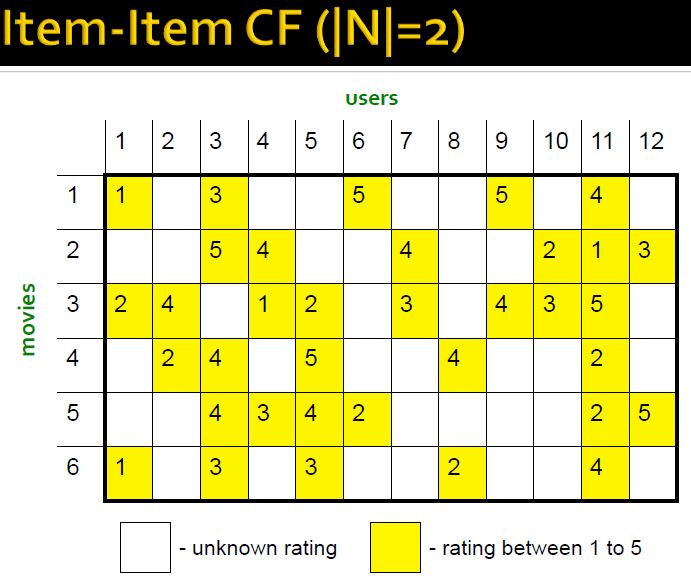
基于物品的协同过滤算法Item-item collaborative filtering(简称ItemCF)给用户推荐那些和他们之前喜欢的物品相似的物品。
比如,该算法会因为你购买过《数据挖掘导论》而给你推荐《机器学习》。不过,ItemCF算法并不利用物品的内容属性计算物品之间的相似度,它主要通过分析用户的行为记录计算物品之间的相似度。基于物品的协同过滤算法可以利用用户的历史行为给推荐结果提供推荐解释,比如给用户推荐《天龙八部》的解释可以是因为用户之前喜欢《射雕英雄传》。

ItemCF的假设和限制Core Assumptions/Limitations
Item-item关系
用户品味遵从大多数人的品味。(否则如果你的品味太奇特,只有你一个人喜欢这个item,这样就没法通过其它用户行为计算这个item与其它item的相似性)
主要缺陷limitation/complaint: 低新颖性serendipity
对比UU CF, UU算法中兴趣相投的用户可能带来新颖的东西,II算法更能选出特别相似的items,更个性化。
Item-Item优点
表现很好works quite well
Good MAE performance on prediction; good rank performance on top-N
高效的实现Efficient implementation
至少在user的数目远远>item数目时。
pre-computability:可以提前计算出item之间的相似度保存着(item间的相似性没有user那么容易变化)。
Item-item is efficient and straightforward. A few parameters need tuning for specific data, domain.
复杂度Complexity
Pre-compute similarities for all pairs of items
Item stability makes similarity pre-computation feasible
Naïvely: O(|I|)²
If symmetric: only need to compute one direction
[Hui Xiong, Wenjun Zhou, Mark Brodie, and Sheng Ma (2008). TOP-K Φ Correlation Computation. INFORMS Journal on Computing (JOC). Volume 20, Number 4, pp. 539-552.]
ItemCF算法
提前计算Pre-compute所有物品对的相似度
查找与用户likes Or has purchased Or has in their basket的物品相似的items
For each item to score
Find the similar items the user has rated
Compute the weighted average of user’s ratings
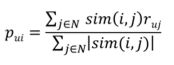
即Two step process:
计算items之间的相似度(3种方法,同userCF)
Correlation between rating vectors
co-rated cases only (only useful for multi-level ratings)
Cosine of item rating vectors
can be used with multi-level or unary ratings
Adjusted cosine (normalize each user’s ratings)
to adjust for differences in rating scales
预测user-item的打分
Weighted sum of rated “item-neighbors”
简单来说,就是预先计算好items之间的相似度,通过user u评分过的items和某个要评分的item i的相似度加权计算预测的评分。
物品相似度度量
For two item rating vectors
Centered Cosine similarity
For two unary vectors (buy or not, click or not)
Jaccard index
邻居选择策略
邻居的选择
预测user u对item i的打分:
For a user u
R_u: the set of items user u has rated
For item i
Neighbor_i: the set of items which are in the top k similar item set to item i
Item j is in the intersection of R_u and Neighbor_i
如果item i的邻居和user u打分过的items越相似,user u对item i的打分就会更高。但是如果item i的邻居和user u打分过的所有items几乎没有重叠,那预测会相当差,就没必要推荐了,放弃。The intersection of R_u and Neighbor_i too small: give up prediction.
邻居数目的选择
k too small → inaccurate scores
k too large → too much noise (low-similarity items)
k = 20 often works well
ItemCF调参Tuning the model
通过cross-validation调参:相似性度量函数Similarity function (normalization or not); 邻居大小Neighborhood size k.
Item-Item CF示例
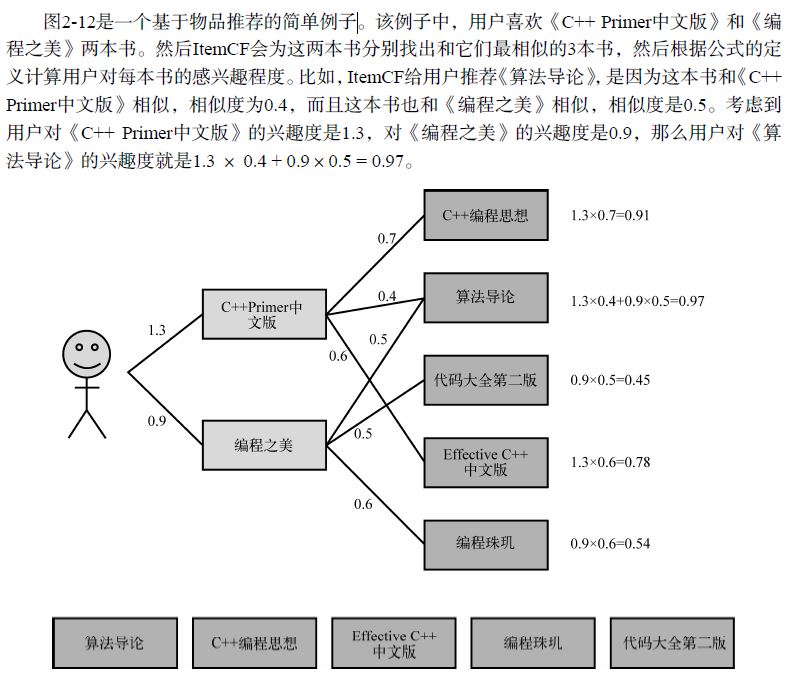
示例1:估计estimate用户5对电影1的打分(相似性函数使用pearson相关系数;邻居大小设为2)。
所以预测的打分r_51 = (0.41*2 + 0.59*3)/(0.41 + 0.59) = 2.6
示例2:
协同过滤的复杂度分析和改进
协同过滤复杂度分析

pre-compute的复杂度是计算item两两之间的复杂度的时间|U|,再乘以计算每个user进行推荐的用户数。
pre-compute花费时间仍旧相当高,所以就有了下面的改进策略。
改进策略1

改进策略2:混合方法Hybrid Methods

1 first rater问题解决:处理新物品问题,使用物品的profiles。
2 cold start问题解决:处理新人物问题时,使用人口统计学知识建立人物profiles。
3 使用一个baseline算法,加上协同过滤就可以了。
Baseline与协同过滤的结合算法
整体基线估计Global Baseline Estimate
user-item矩阵稀疏性带来的一个问题

使用baseline方法估计joe对电影sixth sense的评分示例

Mean是所有user对所有item评分的均值。3.7 is the average rating across all movies and all users.
可以看出Joe相对来说是一个tough rater。
注意这里并没有使用joe已经评分过的电影的任何信息。
结合算法
实际上就是这两个独立分类器的线性组合

具体结合算法流程

Note: 其实这里就是将减去的用户均值μ+bx替换成了更好的baseline bxi。
其它改进
[基于baseline和stochastic gradient descent的个性化推荐系统]
[基于baseline、svd和stochastic gradient descent的个性化推荐系统]
[Item2Vec:协同过滤的神经项嵌入(Item2Vec: Neural Item Embedding for Collaborative Filtering)]
UserCF算法的改进 User-User Variations and Tuning
参考前面UserCF算法的改进 User-User Variations and Tuning部分
ItemCF算法的其它改进和拓展
UserCF的改进也可以应用到ItemCF中来,不过其中的significant weight可能没用,因为item对应的数目一般较多
1 惩罚流行度,提高覆盖率和新颖度
原始ItemCF算法的覆盖率和新颖度都不高,这是由于哈利波特效应:(假如是使用类似jaccard公式计算unary items相似性,如果使用centered cosine应该没有这个问题了)

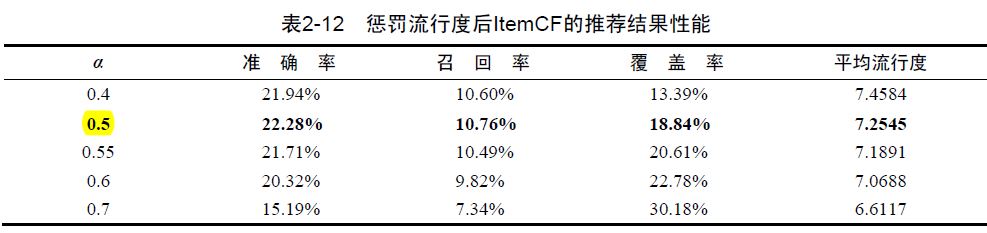
上面的问题换句话说就是,两个不同领域的最热门物品之间往往具有比较高的相似度(因为用户都买了,但是实际它们没有什么相关性)。这个时候,仅仅靠用户行为数据是不能解决这个问题的,因为用户的行为表示这种物品之间应该相似度很高。此时,我们只能依靠引入物品的内容数据解决这个问题,比如对不同领域的物品降低权重等。这些就不是协同过滤讨论的范畴了。
2 Item-item on unary data
ItemCF在unary data (implicit feedback)同样表现不错: clicks, plays, purchases
数据表示
Need some matrix to represent data
Logical (1/0) user-item ‘purchase’ matrix
Not ‘purchase’: 0
Purchase count matrix
Log function on counts
Normalize user vectors to unit vectors
Intuition: users who like many items provide less information about any particular pair. 这样打分太多的用户对应的items的打分都会除以一个大数而变小。
Similarities and Aggregating Scores
Cosine similarity
Aggregating scores
For count matrix: weighted average(count ItemCF算法的评分预测)
For binary matrix: sum of neighbor similarities(binary ItemCF算法的评分预测)
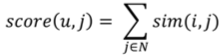
3 Incorporating user importance: User Trust
Goal: incorporate user trustworthiness into item relatedness computation
User’s global reputation, not per-user trust
Solution
weight users by trust before computing item similarities. 也就是在预先计算items之间的相似度时,对应的打分乘上用户的trust,代表这个打分的重要性。
High-trust users have more impact
[Massa and Avesani. 2004. ‘Trust-Aware Collaborative Filtering for Recommender Systems’. ]
ItemCF参考文献:
[Mukund Deshpande, George Karypis:Item-based top-N recommendation algorithms. ACM Trans. Inf. Syst. 22(1): 143-177 (2004)]
[Hui Xiong, Wenjun Zhou, Mark Brodie, and Sheng Ma (2008). TOP-K Φ Correlation Computation. INFORMS Journal on Computing (JOC). Volume 20, Number 4, pp. 539-552.]
协同过滤的冷启动问题
冷启动问题的分类:1. 用户冷启动(新用户来了);2. 物品冷启动(新物品来了);3. 系统冷启动(整个推荐系统都是新的,也可以认为,它和“用户冷启动”的区别是,所有用户对系统冷启动来讲都是新用户,都面临冷启动问题)
解决方法:
1 用户冷启动问题解决
给用户推荐热门排行;进一步利用用户的注册信息,如果知道用户的分类(如:男或者女用户),或者能够通过一些信息(如:用户的注册信息)来获得用户的分类,在这个分类中,根据已有的用户统计这个分类下的排行,再把这个排行结果推荐给新用户。如果用户的注册信息不多,且用户填写的比较全面,则这些信息可以形成一个决策树的组织形式,新用户总会落到树的一个叶子节点(分类)中,推荐该节点下的热门排行就行了。
那么在子类中依据什么对物品进行排序呢?这就要计算物品与子类中用户的关联程度,或者说这类用户对物品的喜好程度。则形式化地,定义N(i)为喜欢物品i的用户群体,定义U(f)定义为具有某个特征f的用户群体(例如:为男性用户),定义特征f与物品i的关联程度为:p(f, i) = | N(i) join U(f) | / ( | N(i) | + alpha),参数alpha作用是解决数据稀疏问题。p表示概率,模计算表示集合的元素数量。
比如: 回答一系列问题, 选择喜欢的item, 添加属性标签, 写Bio等等。这类做法会增加新用户使用产品的成本, 太复杂的产品还可能吓跑新用户, 一般这类做法能诱导的用户数据都比较有限.。
2. 利用现有的开放数据平台
比如: facebook, twitter, google或者新浪微博,msn这些平台,通过用户授权的历史数据,来识别一些用户的属性.。
3. 曲线救国
做一款让用户更愿意或者更容易表现个人偏好的产品, 先让用户玩一段时间. 再引导用户进入其他产品。
4. 利用用户的手机等兴趣偏好进行冷启动。Android手机开放度较高,因此对于各大厂商来说多了很多了解用户的机会,就是用户安装了其他什么应用。举个例子,当一个用户安装了美丽说,蘑菇街,辣妈帮,大姨妈等应用,是否就是基本判定该手机用户是个女性,且更加可以细分的知道是在备孕还是少女,而安装了rosi写真,1024客户端带有屌丝气质的应用则可以锁定用户是个屌丝,此时对于应用方来说,是一个非常珍贵的资源。比如一个新闻应用如今日头条,拿到了这些用户安装应用的数据,用户首次安装就可以获得相对精准的推荐!目前读取用户安装的应用不仅是APP应用商店的标配。另外如豌豆荚锁屏,360卫士app更是做了检测用户每天开启应用的频率等等,这种相比只了解用户安装什么应用,对用户的近期行为画像会更为精准。
2 物品冷启动问题解决
UserCF对物品冷启动问题并不敏感,而temCF中,物品冷启动就是比较严重的问题。
解决方法是通过物品的内容来计算物品之间的相似度,并作为ItemCF的补充。物品之间的相似度可以通过余弦距离来计算。但是当文本很短,关键词很少的时候,余弦距离就很难计算出准确的相似度。作者推荐用topic model来处理,流行的有LDA模型。LDA描述了“文档–主题–词语”之间的概率关系。在计算物品相似度的时候,可以将物品(文档)通过LDA计算物品在话题上的分布,再利用话题分布的相似度来计算物品之间的相似度。话题分布相似度可以利用KL距离来计算,距离越大相似度越低——其时相似度数值并不重要,能比较就行。
3 系统冷启动问题解决
让用户回答一个问题列表,奥妙在于这个列表是随着用户的回答而改变问题的——系统计算,每次给用户提出最具区分力的物品,问用户是否感兴趣。
那么对于当前用户来讲,什么是“最具区分力的”物品?Nadav Golbandi是这样想的:首先,对于一群用户和一些物品,如果用户对这些物品的打分的方差很大,说明这些用户的兴趣不一致;其次,对于某一个物品,用户的反应是,喜欢、不喜欢、无所谓(没有打分),这三种反应可以将用户分为三个群体;最后,要找的物品i满足如下条件,即物品i对将用户群体分为三类,这三类用户的方差都很大,即用户兴趣都不很一致,则物品i说是对这群用户是有区分力的。
发挥专家的作用
即利用专家来对数据进行标注。
同时解决1,2
参考前面的改进策略2:混合方法Hybrid Methods
[项亮《推荐系统实践》_第三章推荐系统冷启动问题 ]
[【学习笔记】读项亮的《推荐系统实践》_第三章推荐系统冷启动问题 ]
UserCF和ItemCF两种算法对比
UU CF: Getting information from the subset of people who most share your tastes
II CF: To getting information from potentially everybody in the community, but filtered so that it’s the information that’s relevant to the items that you have in common with them
UserCF的推荐结果着重于反映和用户兴趣相似的小群体的热点,而ItemCF的推荐结果着重于维系用户的历史兴趣。换句话说,UserCF的推荐更社会化,反映了用户所在的小型兴趣群体中物品的热门程度,而ItemCF的推荐更加个性化,反映了用户自己的兴趣传承。

从技术上考虑,UserCF需要维护一个用户相似度的矩阵,而ItemCF需要维护一个物品相似度矩阵。从存储的角度说,如果用户很多,那么维护用户兴趣相似度矩阵需要很大的空间,同理,如果物品很多,那么维护物品相似度矩阵代价较大。
协同过滤优缺点pros&cons

Note: 最后一个缺点popularity bias可以通过加大热门item的惩罚来解决。
UserCF和ItemCF优缺点的对比
| UserCF | ItemCF | |
| 性能 | 适用于用户较少的场合,如果用户过多,计算用户相似度矩阵的代价交大 | 适用于物品数明显小于用户数的场合,如果物品很多,计算物品相似度矩阵的代价交大 |
| 领域 | 实效性要求高,用户个性化兴趣要求不高 | 长尾物品丰富,用户个性化需求强烈 |
| 实时性 | 用户有新行为,不一定需要推荐结果立即变化 | 用户有新行为,一定会导致推荐结果的实时变化 |
| 冷启动 | 在新用户对少的物品产生行为后,不能立即对他进行个性化推荐,因为用户相似度是离线计算的; 新物品上线后一段时间,一旦有用户对物品产生行为,就可以将新物品推荐给其他用户 |
新用户只要对一个物品产生行为,就能推荐相关物品给他,但无法在不离线更新物品相似度表的情况下将新物品推荐给用户 (但是新的item到来也同样是冷启动问题) |
| 推荐理由 | 很难提供令用户信服的推荐解释 | 可以根据用户历史行为归纳推荐理由 |
Note: lz感觉某宝可能就是itemcf+item profile,因为买羽毛球拍后总是推荐相似的羽毛球拍,新买东西后就立刻变化成新的相似商品。
这些优缺点很多是可以解决的,解决方案参考如上所述的改进。
UserCF和ItemCF的适用场景
UserCF更适合用于个性化新闻推荐:个性化新闻推荐更加强调抓住新闻热点,热门程度和时效性是个性化新闻推荐的重点,而个性化相对于这两点略显次要。因此,UserCF可以给用户推荐和他有相似爱好的一群其他用户今天都在看的新闻,这样在抓住热点和时效性的同时,保证了一定程度的个性化。UserCF适合用于新闻推荐的另一个原因是从技术角度考量的。因为作为一种物品,新闻的更新非常快,每时每刻都有新内容出现,而ItemCF需要维护一张物品相关度的表,如果物品更新很快,那么这张表也需要很快更新,这在技术上很难实现。绝大多数物品相关度表都只能做到一天一次更新,这在新闻领域是不可以接受的。而UserCF只需要用户相似性表,虽然UserCF对于新用户也需要更新相似度表,但在新闻网站中,物品的更新速度远远快于新用户的加入速度,而且对于新用户,完全可以给他推荐最热门的新闻,因此UserCF显然是利大于弊。
ItemCF在图书、电子商务和电影个性化推荐中的优势:在图书、电子商务和电影网站,比如亚马逊、豆瓣、Netflix中,ItemCF则能极大地发挥优势。首先,在这些网站中,用户的兴趣是比较固定和持久的。一个技术人员可能都是在购买技术方面的书,而且他们对书的热门程度并不是那么敏感,事实上越是资深的技术人员,他们看的书就越可能不热门。此外,这些系统中的用户大都不太需要流行度来辅助他们判断一个物品的好坏,而是可以通过自己熟悉领域的知识自己判断物品的质量。因此,这些网站中个性化推荐的任务是帮助用户发现和他研究领域相关的物品。因此,ItemCF算法成为了这些网站的首选算法。此外,这些网站的物品更新速度不会特别快,一天一次更新物品相似度矩阵对它们来说不会造成太大的损失,是可以接受的。
在实际的互联网中,用户数目往往非常庞大,而在图书、电子商务网站中,物品的数目则是比较少的(lz表示天猫宣称商品数加起来有10亿)。此外,物品的相似度相对于用户的兴趣一般比较稳定,因此使用ItemCF是比较好的选择。当然,新闻网站是个例外,在那儿,物品的相似度变化很快,物品数目庞大,相反用户兴趣则相对固定(都是喜欢看热门的)。
UserCF和ItemCF离线实验性能对比及分析
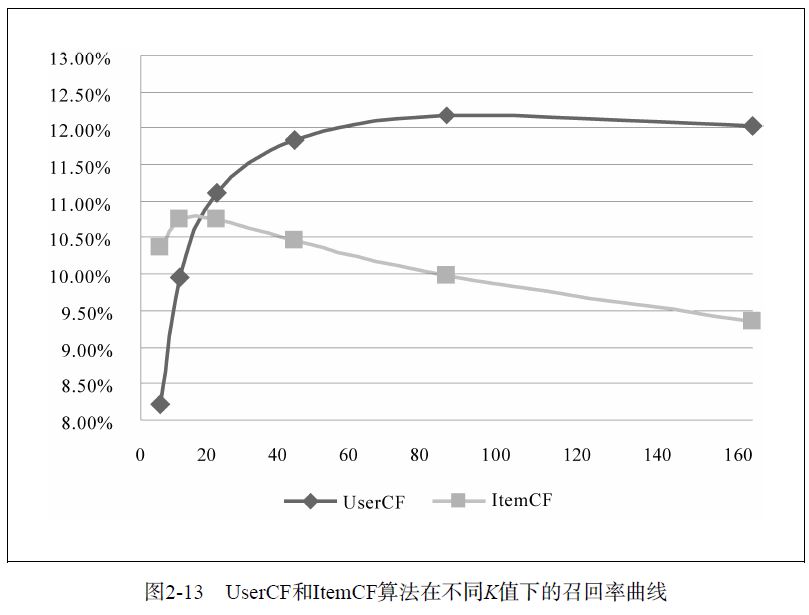
要指出的是,离线实验的性能在选择推荐算法时并不起决定作用。首先应该满足产品的需求,比如如果需要提供推荐解释,那么可能得选择ItemCF算法。其次,需要看实现代价,比如若用户太多,很难计算用户相似度矩阵,这个时候可能不得不抛弃UserCF算法。最后,离线指标和点击率等在线指标不一定成正比。而且,这里对比的是最原始的UserCF和ItemCF算法,这两种算法都可以进行各种各样的改进。一般来说,这两种算法经过优化后,最终得到的离线性能是近似的。
from: http://blog.csdn.net/pipisorry/article/details/51788955
ref: 海量数据挖掘Mining Massive Datasets(MMDs) -Jure Leskovec courses 推荐系统Recommendation System*
ICT Luoping’s recsys lessons, summer 2016*
《推荐系统实践》-项亮
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/213604.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
