大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
Louvain算法
一种基于模块度的图算法模型,与普通的基于模块度和模块度增益不同的是,该算法速度很快,而且对一些点多边少的图,进行聚类效果特别明显。
算法流程:
1、初始时将每个顶点当作一个社区,社区个数与顶点个数相同。
2、依次将每个顶点与之相邻顶点合并在一起,计算它们的模块度增益是否大于0,如果大于0,就将该结点放入该相邻结点所在社区。
3、迭代第二步,直至算法稳定,即所有顶点所属社区不再变化。
4、将各个社区所有节点压缩成为一个结点,社区内点的权重转化为新结点环的权重,社区间权重转化为新结点边的权重。
5、重复步骤1-3,直至算法稳定。
# coding=utf-8
import collections
import random
def load_graph(path):
G = collections.defaultdict(dict)
with open(path) as text:
for line in text:
vertices = line.strip().split()
v_i = int(vertices[0])
v_j = int(vertices[1])
w = float(vertices[2])
G[v_i][v_j] = w
G[v_j][v_i] = w
return G
class Vertex():
def __init__(self, vid, cid, nodes, k_in=0):
self._vid = vid
self._cid = cid
self._nodes = nodes
self._kin = k_in # 结点内部的边的权重
class Louvain():
def __init__(self, G):
self._G = G
self._m = 0 # 边数量
self._cid_vertices = {} # 需维护的关于社区的信息(社区编号,其中包含的结点编号的集合)
self._vid_vertex = {} # 需维护的关于结点的信息(结点编号,相应的Vertex实例)
for vid in self._G.keys():
self._cid_vertices[vid] = set([vid])
self._vid_vertex[vid] = Vertex(vid, vid, set([vid]))
self._m += sum([1 for neighbor in self._G[vid].keys() if neighbor > vid])
def first_stage(self):
mod_inc = False # 用于判断算法是否可终止
visit_sequence = self._G.keys()
random.shuffle(list(visit_sequence))
while True:
can_stop = True # 第一阶段是否可终止
for v_vid in visit_sequence:
v_cid = self._vid_vertex[v_vid]._cid
k_v = sum(self._G[v_vid].values()) + self._vid_vertex[v_vid]._kin
cid_Q = {}
for w_vid in self._G[v_vid].keys():
w_cid = self._vid_vertex[w_vid]._cid
if w_cid in cid_Q:
continue
else:
tot = sum(
[sum(self._G[k].values()) + self._vid_vertex[k]._kin for k in self._cid_vertices[w_cid]])
if w_cid == v_cid:
tot -= k_v
k_v_in = sum([v for k, v in self._G[v_vid].items() if k in self._cid_vertices[w_cid]])
delta_Q = k_v_in - k_v * tot / self._m # 由于只需要知道delta_Q的正负,所以少乘了1/(2*self._m)
cid_Q[w_cid] = delta_Q
cid, max_delta_Q = sorted(cid_Q.items(), key=lambda item: item[1], reverse=True)[0]
if max_delta_Q > 0.0 and cid != v_cid:
self._vid_vertex[v_vid]._cid = cid
self._cid_vertices[cid].add(v_vid)
self._cid_vertices[v_cid].remove(v_vid)
can_stop = False
mod_inc = True
if can_stop:
break
return mod_inc
def second_stage(self):
cid_vertices = {}
vid_vertex = {}
for cid, vertices in self._cid_vertices.items():
if len(vertices) == 0:
continue
new_vertex = Vertex(cid, cid, set())
for vid in vertices:
new_vertex._nodes.update(self._vid_vertex[vid]._nodes)
new_vertex._kin += self._vid_vertex[vid]._kin
for k, v in self._G[vid].items():
if k in vertices:
new_vertex._kin += v / 2.0
cid_vertices[cid] = set([cid])
vid_vertex[cid] = new_vertex
G = collections.defaultdict(dict)
for cid1, vertices1 in self._cid_vertices.items():
if len(vertices1) == 0:
continue
for cid2, vertices2 in self._cid_vertices.items():
if cid2 <= cid1 or len(vertices2) == 0:
continue
edge_weight = 0.0
for vid in vertices1:
for k, v in self._G[vid].items():
if k in vertices2:
edge_weight += v
if edge_weight != 0:
G[cid1][cid2] = edge_weight
G[cid2][cid1] = edge_weight
self._cid_vertices = cid_vertices
self._vid_vertex = vid_vertex
self._G = G
def get_communities(self):
communities = []
for vertices in self._cid_vertices.values():
if len(vertices) != 0:
c = set()
for vid in vertices:
c.update(self._vid_vertex[vid]._nodes)
communities.append(c)
return communities
def execute(self):
iter_time = 1
while True:
iter_time += 1
mod_inc = self.first_stage()
if mod_inc:
self.second_stage()
else:
break
return self.get_communities()
if __name__ == '__main__':
G = load_graph(r'C:\\Users\\程勇\\Desktop\\similarity.txt')
algorithm = Louvain(G)
communities = algorithm.execute()
# 按照社区大小从大到小排序输出
communities = sorted(communities, key=lambda b: -len(b)) # 按社区大小排序
count = 0
for communitie in communities:
count += 1
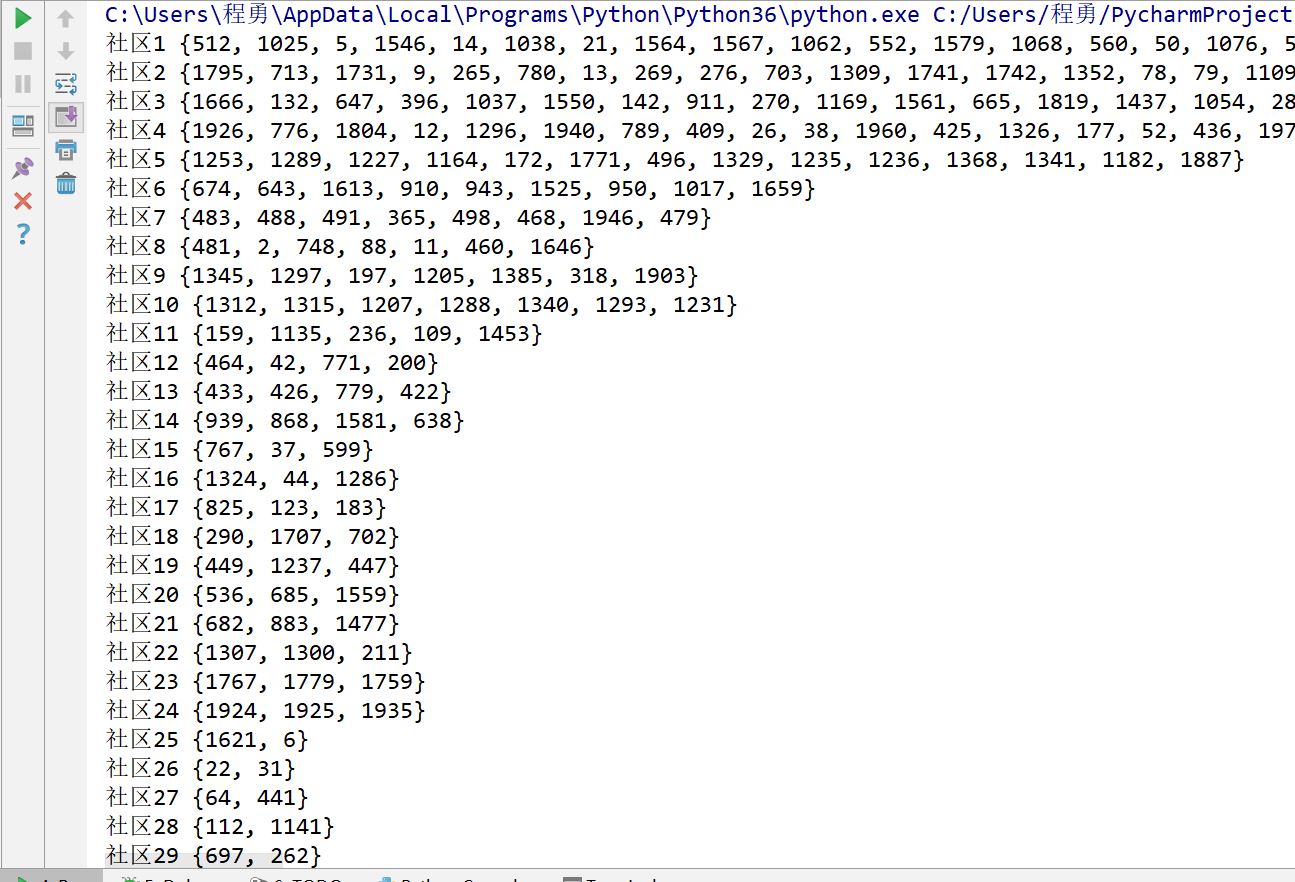
print("社区", count, " ", communitie)
测试用例文件如图:


这是部分测试用例的截图,一行的前两个数是顶点编号,第三个数是权重。按照每个社区大小顺序从大到小打印:
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/213519.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
