大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
目录
(7)App/Workplace Search(企业功能,未实现)
主要参考链接
《Linux命令行大全》(The Linux Command Line by William E. Shotts, Jr.)中英双语版
文中所有其他链接型文字都可以单击跳转,大多为其他参考博客或我的专栏博客
一、什么是ELK(端口9200)
一般我们需要进行日志分析场景:直接在日志文件中 grep、awk 就可以获得自己想要的信息。但在规模较大的场景中,此方法效率低下,面临问题包括日志量太大如何归档、文本搜索太慢怎么办、如何多维度查询。需要集中化的日志管理,所有服务器上的日志收集汇总。常见解决思路是建立集中式日志收集系统,将所有节点上的日志统一收集,管理,访问。
一般大型系统是一个分布式部署的架构,不同的服务模块部署在不同的服务器上,问题出现时,大部分情况需要根据问题暴露的关键信息,定位到具体的服务器和服务模块,构建一套集中式日志系统,可以提高定位问题的效率。一个完整的集中式日志系统,需要包含以下几个主要特点:
-
收集-能够采集多种来源的日志数据
-
传输-能够稳定的把日志数据传输到中央系统
-
存储-如何存储日志数据
-
分析-可以支持 UI 分析
-
警告-能够提供错误报告,监控机制
ELK提供了一整套解决方案,并且都是开源软件,之间互相配合使用,完美衔接,高效的满足了很多场合的应用。是目前主流的一种日志系统。
(1)ELK
ELK是Elasticsearch(ES) , Logstash, Kibana的结合,是一个开源日志收集软件。
Elasticsearch(ES):开源分布式搜索引擎,提供搜集、分析、存储数据功能。
Logstash:日志搜集、分析、过滤,支持大量数据获取。其自带输入(input)、过滤语法(grok)、输出(output)三部分。其输入有两种方式:①由各beat采集器输入,经过滤后输出到ES ②本机数据输入,经过滤后输出到ES。
Kibana:提供日志分析友好的 Web 界面。数据存储到ES中后,可以在Kibana页面上增删改查,交互数据,并生成各种维度表格、图形。
新增的Filebeat是一个轻量级的日志收集处理工具(Agent),占用资源少,官方也推荐此工具。还有其他beat等,可以在各服务器上搜集信息,传输给Logastash。
总的来说就是:beats+Logstash收集,ES存储,Kibana可视化及分析。下面分别是单机和集群的示意图(集群中也可以采用多beats)。
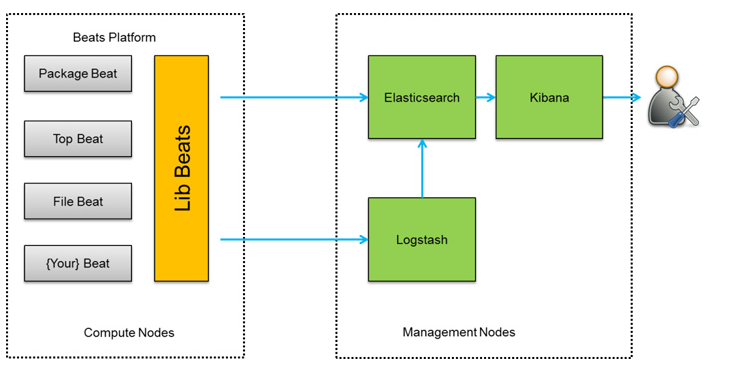

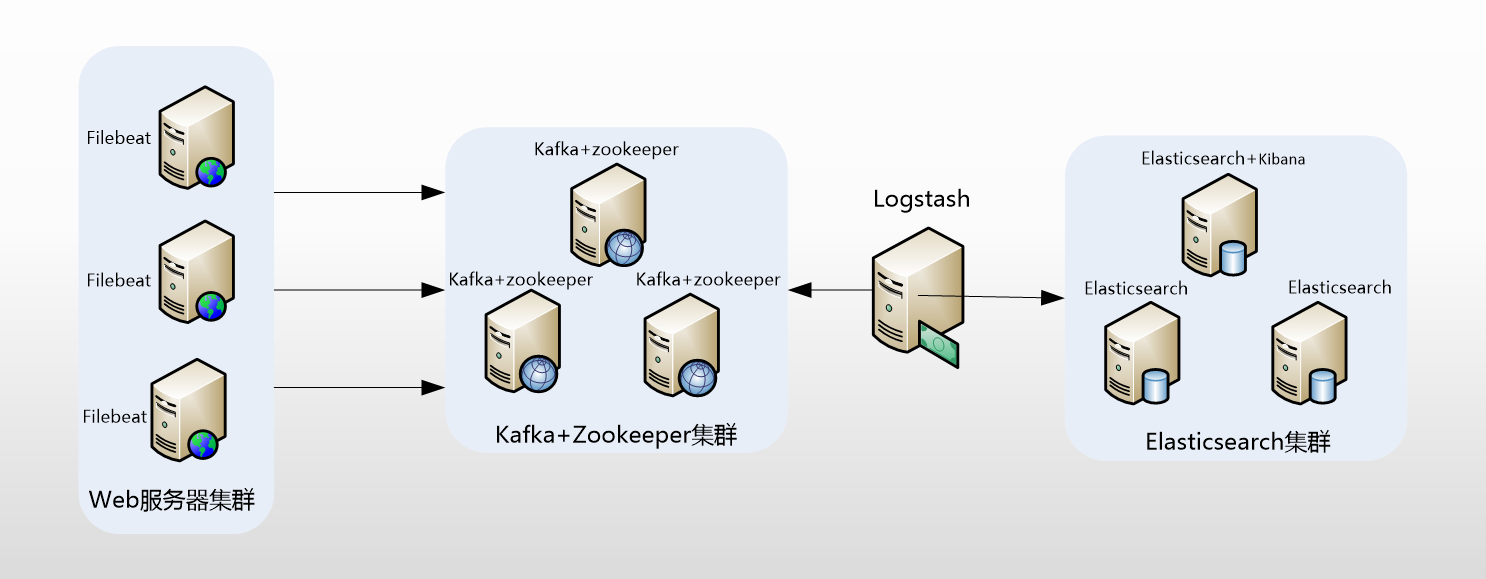
(我们的集群目前未使用Kafka)
更多术语参见其他人的博客:
ELK合集(该专栏的3-14为关键术语内容)
(2)安装
一般来说,各个部件的安装过程就是:下载→修改配置文件(xx.yml或xx.conf)→启动。
在我们的内网已经完成了Elasticsearch集群搭建,过程未记录,可以直接使用。
以下提供了单机的安装过程,便于对ELK和beats的理解。
主要特点:
1.存储:面向文档+JSON
(1)面向文档
Elasticsearch是面向文档(document oriented)的,这意味着它可以存储整个对象或文档(document)。然而它不仅仅是存储,还会索引(index)每个文档的内容使之可以被搜索。在Elasticsearch中,你可以对文档(而非成行成列的数据)进行索引、搜索、排序、过滤。这种理解数据的方式与以往完全不同,这也是Elasticsearch能够执行复杂的全文搜索的原因之一。
(2)JSON
ELasticsearch使用Javascript对象符号(JavaScript Object Notation),也就是JSON,作为文档序列化格式。JSON现在已经被大多语言所支持,而且已经成为NoSQL领域的标准格式。它简洁、简单且容易阅读。尽管原始的user对象很复杂,但它的结构和对象的含义已经被完整的体现在JSON中了,在Elasticsearch中将对象转化为JSON并做索引要比在表结构中做相同的事情简单的多。传统数据库有表名.字段.,属性 然后对应下面行为数据,但是在es中不区分,统一将一行数据转换为json格式进行存储,所以es中存储非格式化的方式
2.检索:倒排+乐观锁
(1)倒排
倒排是一种索引方法,用来存储在全文检索下某个单词在一个/组文档中的存储位置,也常被称为反向索引、置入档案或反向档案。也是ES为何具有高检索性能的原因。
-
一般的正向索引
一般的正向索引要搜索某个单词,是遍历文档,检查文档中是否有这个单词。
| 文档1 | [单词1,单词2] |
| 文档2 | [单词1,单词2,单词3] |
-
倒排索引
而倒排索引是建立一个映射关系,确定单词属于哪几个文档
| 单词1 | [文档1,文档2] |
| 单词2 | [文档1,文档2,文档3] |
ES中采用的就是倒排索引结构。
(2)冲突处理和修改操作
ES采用乐观锁处理冲突,乐观锁概念参考Elasticsearch-并发冲突处理机制,因此在执行一些操作时可能要进行多次操作才可以完成,并且ES的修改操作有以下方面有几个特性
修改:
-
文档不能被修改,只能被替换
删除:
-
文档删除操作只是标记为”已删除“,并没有真正释放内存
-
尽管不能再对旧版本的文档进行访问,但它并不会立即消失
-
当继续索引更多的数据,Elasticsearch 会在后台清理这些已删除文档
-
删除索引会直接释放内存
3.分析:监控+预警+可视化
ELK将所有节点上的日志统一收集,传输,存储,管理,访问,分析,警告,可视化。
它提供了大量应用于监控的可视化界面,例如Uptime、Metric、Machine Learning、DashBoard、Stack Monitoring,都是我们将系统/服务器/应用的数据传入ES后,就可以利用Kibana的模板来展示相关内容。
对于各种常见的采集器采集到的数据,官方提供了一系列对应的模板,但是我们也可以针对自己的数据自定义,来按需求展示想要的信息。
关于各个板块的具体展示内容和查看方式,在后文具体提到,见三、Beats和四、Kibana+插件。
4.支持集群
集群真正的扩容能力是来自于水平扩容–为集群添加更多的节点,并且将负载压力和稳定性分散到这些节点中。
(1)ES集群特点
-
一个集群拥有相同的cluster.name 配置的节点组成, 它们共同承担数据和负载的压力
-
主节点负责管理集群的变更例如增加、删除索引,或者增加、删除节点等。 而主节点并不需要涉及到文档级别的变更和搜索等操作
(2)分片的特点
-
Elasticsearch 是利用分片将数据分发到集群内各处
-
分片是数据的容器,文档保存在分片内
-
分片又被分配到集群内的各个节点里
-
当集群规模变动,ES会自动在各个节点中迁移分片。使得数据仍然均匀分布在集群中
-
副分片是主分片的一个拷贝,作为硬件故障时的备份。并提供返回文档读操作
-
在创建索引时,确定主分片数,但是副分片可以在后面进行更改
因为ELK的内容较多且一些功能相互依赖,本文的板块划分更注重解释上的功能理解优先,而不是安装优先。
二、Logstash(端口5044)
可以采集各种样式、大小和来源的数据,对数据进行转换,然后将数据发送到存储库中,如我们的存储库是ES。
在其配置文件中有input(输入)、grok(过滤语句)、output(输出)三大板块。
input:它可以直接采集服务器上的文件/数据,也可以接受来自其他地方的数据(ip:从5044号端口传过来)
grok:自定义过滤语句,对原始数据的内容进行处理
output:输出到我们的存储库(如ES)
在我们的应用中,是把其当作一个中间件,大部分采集器(beats)将自己采集到的数据或文件传输到5044端口,启动的logstash从5044端口接收数据,输出到ES(9200端口)。我们对logstash文件进行了配置,设置了一定的过滤语句,目前的过滤语句主要是为了时间戳匹配。
时间戳匹配:每个数据都会自带一个时间戳,默认为我们导入数据的时间,但是对于一些系统日志,如下图,

将会自带一个日志时间,因此我们希望将时间戳更改为消息中的日期,而不是导入时间。
在logastash配置文件中,我们已经设置了时间戳匹配的过滤语句,可以在文件中查看
vim /data/elk-ayers/logstash-7.10.1/config/logstash-sample.conf关于logstash的相关操作,可以查看
三、Beats
Beats Platform Reference(官方文档)
Beats是用来捕获在服务器上的数据,将数据通过logstash发送到ES或直接发送到ES,即采集器。官方给出了多种Beats及其在ES中的数据模板(可以用于进行可视化、分析等)
我们目前采用的是部分Filebeat→ES→Kibana可视化,而其他Beat全部都是beat→logstash→ES→Kibana可视化
关于Kibana,可以先浏览第四板块“Kibana+插件”,其中还涉及到ES-head插件,也是第四板块的部分内容
1.Filebeat
Kibana展示界面(打开左侧菜单栏):
-
Kibana→Discover
-
Kibana→DashBoard→[Filebeat System] Syslog dashboard ECS(未实现)
Filebeat是一个日志收集软件,Filebeat安装过程。
在Filebeat中,我们可以将各种文件类型进行传入,一般是*.log以及message*文件。
vim /data/elk-ayers/filebeat-7.10.1/filebeat.yml(1)数据处理方式
对于传入的文件,我们可能要对其进行一定的数据处理,一般有两种方式
-
利用logstash的grok语句进行过滤(filebeat→logstash→ES中使用),参见logstash实现时间戳替换。
vim /data/elk-ayers/logstash-7.10.1/config/logstash-sample.conf- 利用pipeline的grok语句进行过滤(filebeat→ES中使用),语法与第一种类似。pipeline是ES中的内容,称为管道。我们可以自定义一个pipeline,当filebeat的数据传输到ES中时,调用这个管道,或者说让数据通过这个管道,则可以实现对数据的过滤和处理。
参见pipeline实现时间戳替换(这里涉及到Kibana的内容,可以先浏览第四板块了解什么是Kibana)。
vim /data/elk-ayers/filebeat-7.10.1/filebeat.yml(2)配置文件调整
在filebeat的配置文件中,我们一般会调整的内容主要有:
-
filebeat.input:输入的文件+文件的pipeline方式+字段
-
output.elasticsearch/output.logstash:输出方式,若是elasticsearch,输出时可以指定索引名称(indices);若是logstash,输出到对应主机的5044端口。
-
index.number_of_shards:设置分片大小
Filebeat可以实现可视化(目前未实现),关于可视化可以先看过其他beat的可视化结果再回来研究
2.Metricbeat
Kibana展示界面(打开左侧菜单栏):
-
Kibana→DashBoard→[Metricbeat System] Overview ECS
-
Kibana→Machine Learning→概览→查看(metricbeat)
-
Observability→指标/Metric
用于从系统和服务收集指标。Metricbeat 能够以一种轻量型的方式,输送各种系统和服务统计数据,从 CPU 到内存。可以获取系统级的 CPU 使用率、内存、文件系统、磁盘 IO 和网络 IO 统计数据,还可针对系统上的每个进程获得与 top 命令类似的统计数据。
Metricbeat安装过程与可视化效果(一般时间设置Last 15 minutes)
3.Heartbeat
Kibana展示界面(打开左侧菜单栏):
-
Kibana→Machine Learning→概览→查看(uptime)
-
Observability→运行时间/Uptime
通过主动探测监测服务可用性,询问监测的网站是否正常运行。无论您要测试同一台主机上的服务,还是要测试开放网络上的服务,Heartbeat 都能轻松生成运行时间数据和响应时间数据
4.Auditbeat
Kibana展示界面(打开左侧菜单栏):
-
Kibana→DashBoard→[Auditbeat File Integerity] Overview ECS
监控Linux系统上的文件数据和信息,实时采集事件发送到ES。监控用户的行为和系统进程,分析用户事件数据。Auditbeat 会记住是谁在什么时间做了什么事情,记住所有这些原始的系统调用数据,以及相关联的路径
5.Functionbeat(未安装)、Journalbeat(未安装)、Packetbeat(未安装)、Winlogbeat(不适用)
四、Kibana+插件
1.ES-head插件(localhost:9100)
现在,我们已经有了一堆采集器,采集了数据,或是直接或是通过logstash传输到存储库ES中,我们希望查看存储库中有哪些内容,以及一些详情,则可以使用提供的ES-head插件,可以方便查看我们生成的索引、数据内容,也提供了简易的增删改查功能。
使用Head,一般是为了以下几个目的:
-
查看我们导入的数据是否正常生成索引
-
数据浏览
在Head界面,有一些简易的功能:
(1)别名
head索引下显示的彩色
可以在 Kibana 的 Dev tools使用命令PUT /索引名/_alias/别名,例如下面代码
PUT /kibana_sample_data_flights/_alias/flights会将kibana_sample_data_flights取个别名flights,使用 flights 的时候,其实也就是对索引kibana_sample_data_flights 进行操作。在索引下出现,但是不会作为新的索引出现。
可以设置为不显示
(2)刷新
在概览界面右上角,有一个刷新按钮,选择箭头。就无需手动操作,快速查看索引中 的数据变化
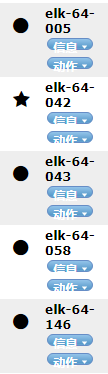
(3)主节点
在head界面,可以展示我们的集群和目前接入的节点。主机名前为★的代表当前选举出的主节点,●代表从节点,当主节点崩溃后,集群会从其余未崩溃的节点中自动选举出满足要求的节点,成为新的主节点。
(4)健康值
在页面顶端,显示了集群的健康状态,如果未连接,可以参考集群未连接问题解决。
而连接后,存在三种不同的健康状况:green、yellow、red
-
green 主副分片均正常
-
yellow 主都正常,不是所有的副都正常,这不一定是有错误,如果刚进行过部分节点重启或者集群的重启,则一般都会出现这种情况,需要等待一定时间来让各节点处理重启状况。可以在Dev tools检查健康状态
GET _cat/health找到显示yellow的索引,如果索引数据量大,可能需要等待较长时间。
-
red 所有主分片都不正常
2.Kibana(localhost:5601)
Kibana可以说是一个基于ES的可视化界面和分析界面,是一个开源的用户界面,利用Kibana,我们可以更好地展示和检索已经被收集到ES的数据。Kibana可以实现的功能有非常多。
Kibana完整功能列表(官方文档)、Kibana功能专栏(Elastic中国社区官方博客)
像Uptime(运行时间)、Metric(指标)等数据展示界面,以及很多Kibana功能在前文和相关博客中已经提到很多,应该对界面有了初步的了解,这里主要介绍一下Kibana中的Stack Management、Discover、DashBoard+Visualize、Dev tools(开发工具)、Stack Monitor(堆栈监测)、APM、App Search/Workplace Search的部分功能和使用方式。
(1)Stack Management
打开左侧菜单栏,选择Management→Stack Management,进入管理界面,在这里,目前使用的主要是两个功能
a.索引模板(index template)
找到数据→索引管理→索引模板,在其中我们可以创建一个Index template。
对于各个导入的数据,我们都会生成不同的字段,而字段各有其类型,在ES中称作mapping(映射)【这很重要!】当我们新建一个索引模板时,我们按需求可以为不同的字段创建mapping
当我们导入的数据满足两个条件:①索引模板的名称是导入数据索引名的前缀 ②导入的数据字段与定义的字段相匹配。则会将该字段的类型转为我们定义的类型。
这一用处体现在可视化中,某些字段类型(如“text”)是无法进行聚合的,若是我们不进行定义,则导入的数据会成为text类型,并同时生成一个xx.keyword字段,该字段可聚合。这里可能会说,那不是也生成可聚合字段了么,text无法聚合并没有影响。但是,对于一些可视化的模板内容,默认选取的字段是原始字段名而不是原始字段.keyword,因此必须使原始字段可聚合,否则数据无法正常展示,而模板往往是详细而复杂的,对于初学者来说难以复制,所以最好是改变自己来匹配模板,而不是试着复制模板。
例如,在导入各个beat之前,我们需要先进行加载模板的操作,在这个操作中,除了加载可视化模板,还同时加载了索引模板,这时,如果我们导入的索引和字段名正确,则数据可以正常被聚合及可视化。关于这个更多的原理可以参考未加载模板而产生的不可聚合问题。
b.索引模式(index pattern)+脚本字段(Script Fields)
找到数据→Kibana→索引模式,这里会出现一些索引名称。
-
创建索引模式
很多时候,我们导入数据时会以采集器-版本-年月命名索引,例如filebeat-7.10.1-2021.03/filebeat-7.10.1-2021.04,我们想查看以filebeat-7.10.1为前缀的所有索引,就可以定义一个索引模式为filebeat-7.10.1*,则在Discover界面就会出现filebeat7.10.1版本传入的所有年月数据。
-
创建脚本字段
而在索引模式中,还有一个重要的功能,就是创建脚本字段(Script fileds)。
点进一个具体的索引模式,发现有字段、脚本字段、筛选源三个部分。
字段:指索引中现有的字段
脚本字段:利用代码实现生成新字段
筛选源:去除某些内容不展示
我们导入数据后,可能会在实际的分析过程中发现有一些需要展示的数据没有一个属于自己的字段,这就导致难以可视化,于是出现了脚本字段。可以说它是一个为可视化而生的功能。
它可以实现从现有的数据字段中提取部分我们需要的内容,生成一个新的字段。如此,在可视化界面中,我们就可以使用这个字段来展示数据。关于可视化操作,参考四、2.(3)DashBoard+Visualize部分的内容。
在myx-t1*的索引中有两个已经成功实现的脚本字段,是通过不同方式生成的同样的内容,更多详情可以参考博客Scripts-Fields生成新字段
(2)Discover
打开左侧菜单栏,选择Kibana→Discover,这是一个很常用的功能,在这个界面,我们可以根据时间戳来查看数据的分布,以及数据的详细信息,它主要有以下几个可以操作的功能
-
a.索引
通过management创建索引,或在控制台加载过模板,在左侧我们可以实现索引选择
- b.筛选(filter)
对于已有数据,我们可能想查看具有特定内容或存在特定字段的数据,就可以使用筛选功能。选择一个字段,筛选主要有几种方式:是/is(=)、不是/is not(!=)、属于/is one of(字段中含某些字/字符等)、不属于/is not one of(字段中不含某些字/字符等)、存在/exist(!=null)、不存在/is not exist(==null)
- c.搜索(search)
和筛选的功能基本类似
- d.时间
选择时间区间,来展示时间戳在该区间范围的数据,有快速选择或者绝对日期两种方式
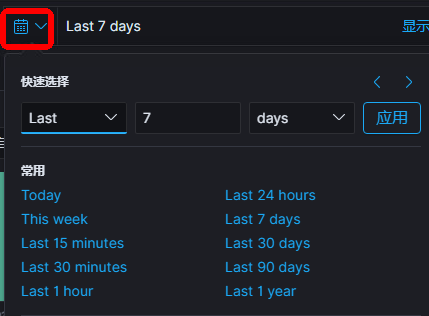
- e.字段(field)
鼠标移动到左侧字段界面,有选定字段和可用字段两个板块,我们点击某个可用字段的“+”号,则数据将会显示时间戳+该字段的信息。

- f.保存为搜索(Save)
由e操作,我们可以任意增添或删除想显示的字段,并保存为一个“搜索”(重要,在可视化界面可以使用)

(3)DashBoard+Visualize
打开左侧菜单栏,选择Kibana→DashBoard,我们进入到一个便于操作的可视化功能面板,随意点开一个DashBoard,发现里面有许多小板块。
大的一个面板称作DashBoard,其中的小板块称作Visualize,我们可以将Visualize看作是一个个小组件。在Discover面板保存的“搜索”也会作为一个Visualize,可以展示在DashBoard中。
目前官方给出的,并且我们已经导入数据,可以正常展示的,主要会用到的模板DashBoard为以下几个:
-
[Metricbeat System] Overview ECS
-
[Auditbeat File Integerity] Overview ECS
-
[Flights] Global Flight Dashboard
目前我们自定义的,有数据且可以正常展示的模板主要为以下几个
-
Hadoop-myx-test(设计方式DashBoard设计一)
-
Hadoop-myx-t1(设计方式DashBoard设计二)
-
Hadoop-fsimages-ayers
如果数据无法正常展示,可尝试调大时间间隔。
关于模板的创建和添加方式,可以参考括号内的链接
(4)Dev tools
打开左侧菜单栏,选择Management→Dev tools/开发工具,我们进入到界面。它主要提供了以下几种功能
-
控制台增删改查数据以及设置
-
Search Profiler查询(其实它的功能在控制台也可以实现,没有很多尝试)
-
Grok Debug语法调试,Grok相关内容和应用
主要使用的还是控制台功能,在这里我们可以测试许多,可以用painless语法对已经存储在ES中的数据进行增删改查,可以用SQL语句增删改查,可以实验分词器的功能,可以修改映射,可以查看索引和集群状况等等。以下介绍的也都是和Dev tools相关的内容
a.painless
Painless语法是ES专门使用的一种语法,在生成Script Fields时,我们所使用的就是painless语法,它运用了Java的一些函数和内容,与Java比较相似。ES5.5版本的painless函数介绍页面较为直观,可以查询我们需要的函数以及查看详情,painless函数大全,修改链接中的5.5为7.10,可以跳转到我们所搭建版本的页面,但是显示略有不同。
在开发工具中,使用的也是painless,它在ES的运行速度是其他语言的数倍,专门为ES定制。
b.REST接口
在Kibana中,所有的接口都是通过REST实现的,也就是PUT、GET、PUST、DELETE、PATCH。具体使用在Dev tools中测试。参考官方博客的样例运行一些代码,就能很快上手。
入门3:了解如何进行分析数据: analyze 及 aggregate 数据
c.SQL语句
# 获取所有索引(含别名,在kind中标记)
POST /_sql?format=txt
{
"query": "SHOW tables"
}
# 查看SQL函数
POST /_sql?format=txt
{
"query": "SHOW FUNCTIONS"
}
#SQL语句似乎无法识别带有“-”“.”等符号的索引(下划线可以),所以可以利用 PUT /索引名/_alias/别名,另取一个名字再进行调用
# 为kibana_sample_data_flights取别名flights
PUT /kibana_sample_data_flights/_alias/flights
# 查看某个索引的字段信息
POST /_sql
{
"query": """
DESCRIBE kibana_sample_data_flights
"""
}
# 查看某个索引字段信息(以表格显示,更直观)
POST /_sql?format=txt
{
"query": """
DESCRIBE kibana_sample_data_flights
"""
}# 在服务器控制台打开SQL(这里可以直接运行语句SELECT等等)
/data/elk-ayers/elasticsearch-7.10.1-node01/bin/elasticsearch-sql-cli http://172.20.64.5:9200# 例子1(在2月份之后查找所有航班,该航班的飞行时间大于5小时,并且按照时间最长来排序)
POST /_sql?format=txt
{
"query": """
SELECT MONTH_OF_YEAR(timestamp), OriginCityName, DestCityName, FlightTimeHour FROM flights WHERE FlightTimeHour > 1 AND MONTH_OF_YEAR(timestamp) > 2 ORDER BY FlightTimeHour DESC LIMIT 20
"""
}其他具体的检索操作和启动SQL操作参见官方博客(包括查询、修改字段类型、通过需求筛选数据等)
Notes:
①SQL语句似乎无法识别带有“-”“.”等符号的索引(下划线可以),所以可以利用 PUT /索引名/_alias/别名,另取一个名字再进行调用。不过在提取字段的时候可以有“.”号,例如
SELECT agent.hostname.keyword(可以有“.”等) FROM nodemanager(不能有“-”“.”等)(5)Stack Monitoring(堆栈监测)
打开左侧菜单栏,选择Management→Stack Monitor/堆栈监测,在这里我们已经启动了监测,展示了ES集群、Kibana、Logstash的运行状况。具体点击内容,可以有相关的告警、磁盘空间等各种系统情况。
如果无法正常显示,可以参考解决:Kibana的Stack Monitoring显示节点offline
(6)APM(已安装,未部署jar包)
打开左侧菜单栏,选择Observability→APM,进入APM界面
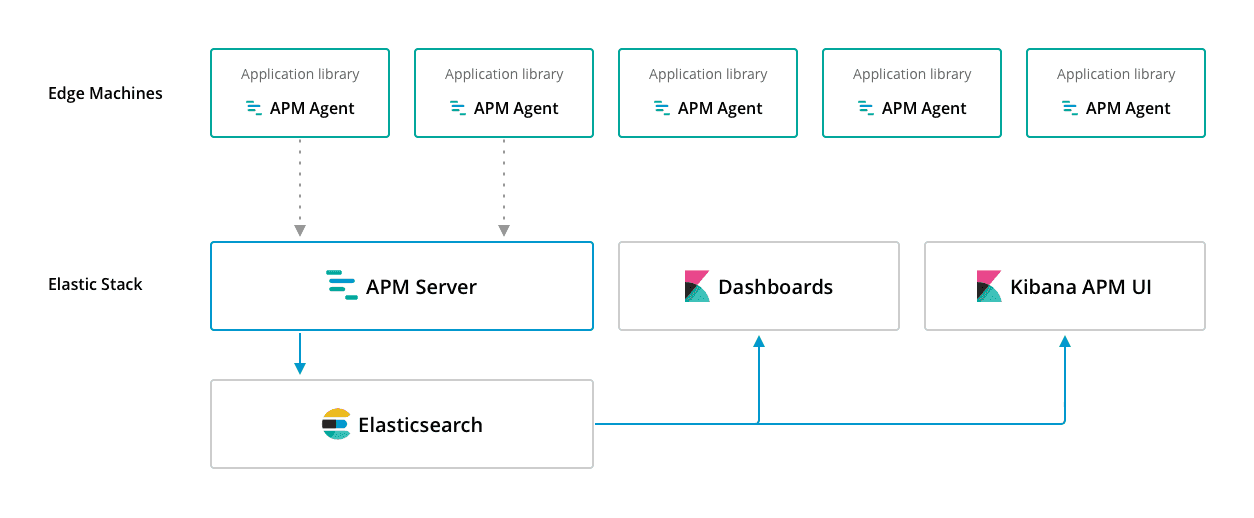
APM包含apm-server和apm-agent两个部分,其基本架构如图
-
APM Server是一个用Go编写的开源应用程序,通常在专用服务器上运行。它默认侦听端口8200,并通过JSON HTTP API从代理接收数据。然后,它根据该数据创建文档并将其存储在Elasticsearch中。
-
APM agent是一系列开源库,使用与服务器端相同的语言编写,目前支持node、python、ruby、js,java和golang。您可以像安装任何其他库一样将它们安装到服务器端中。apm agent会检测代码并在运行时收集性能数据和错误。此数据可 缓冲一小段时间并发送到APM服务器。
所以APM的主要功能是对应用的性能进行监控,例如监控我们部署的jar包。
打开左侧菜单栏,选择Observability→APM,在http://localhost:5601/app/home#/tutorial/apm链接中,官方提供了APM的部署过程。目前已经将apm-server和Java的apm-agent安装在以下目录中(安装过程链接)。
/data/elk-ayers/elasticsearch-7.10.1-node01/apm/官方介绍 APM :Java Agent Reference
大概了解原理后,如果我们想启用一个java的agent时,在服务器输入代码
java\
-javaagent:/data/elk-ayers/elasticsearch-7.10.1-node01/apm/apm-agent/elastic-apm-agent-1.21.0.jar \
-Delastic.apm.service_name=my-application \
-Delastic.apm.server_urls=http://172.20.64.5:8200 \
-Delastic.apm.application_packages=org.example \
-jar /路径/my-application.jar其中service_name可以自定义,最后一行是我们部署的jar包
APM的功能似乎和User Experience界面相互联结,当我们监听部署的应用后,可以实时反馈用户数据,在User Experience界面中展示。
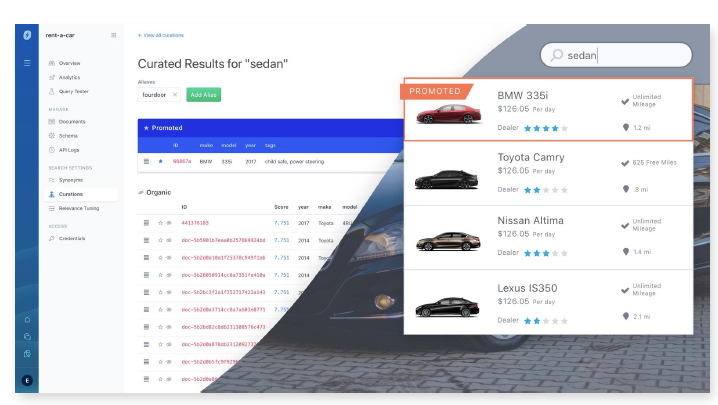
(7)App/Workplace Search(企业功能,未实现)
由于功能未实现,所以还不清晰具体的运行和操作方式,但这两者是为企业提供的功能。
-
App Search
App Search是一组功能强大的 API 和开发人员工具,旨在为开发人员构建丰富的,面向用户的搜索应用程序。
它是在背后提供搜索功能的支持,如下图,右边是用户在企业网页搜索的展示效果,左边是在App Search的界面。在App Search可以微调搜索结果,比如用户搜索的时候,我们希望优先展示和什么字段匹配,或者不展示哪些内容,都可以在App那边调整,用户搜索到的结果就是经过我们调整的结果。除此之外,App也会统计用户的搜索数据,可视化用户行动信息。
Elastic App Search:产品介绍(中国社区官博)
Elastic App Search: 搭建和应用(中国社区官博)
Elastic App Search:轻松实现高级搜索(官网)
在7.11中,App Search还进一步推出了web 爬虫器
Enterprise:推出 Elastic App Search Web 爬虫器(中国社区官博)
Enterprise:Elastic App Search – Web 爬虫器实践(中国社区官博)
-
Workplace Search
Workplace Search的功能看了几个链接,但没有特别明白它的用途,可以看一下下面的几个链接。似乎是为员工提供的,它可以关联到很多的应用,比如github、Gmail,把内容和Workplace Search关联后,我们可以搜索到各个应用中有没有我们想搜索的内容。
Elastic Workplace Search:随时随地搜索所有内容(中国社区官博)
Elastic Workplace Search:崭新的统一工作方式(中国社区官博)
Elastic 7.9 版本发布,提供免费的 Workplace Search 和终端安全功能(中国社区官博)
Elastic Workplace Search:Github应用(中国社区官博)
Elastic Workplace Search:面向虚拟工作空间的一站式求知工具(官网)
不知道理解得有没有问题,感觉App是面向用户的,我们在背后设置,让用户得到的搜索结果是我们期望他们看见的。Workplace是面向员工的,是方便我们整理自己的企业数据或检索内容
3.cerebro插件(localhost:9000)
Cerebro是一个集群管理工具,比Kibana轻量很多,很适用与生产和测试等环境的es集群管理。它是kopf的升级版本,更改了个名字,包含kopf的功能(监控工具等)和head插件的部分功能(创建索引、查看集群设置,别名、分析等)。现在kopf已经不再更新,只对cerebro进行维护。
进入localhost:9000,会出现一个登录或者说连接界面,在框中输入
http://localhost:9200就可以监控我们的集群和索引状态
4.bigdesk插件(localhost:8000)
bigdesk是一套用于监控es的插件,可以通过它来查看es集群的各种状态,如:cpu、内存使用情况,索引数据、搜索情况,http连接数等。和head一样,它也是个独立的网页程序。
进入localhost:8000,会出现一个登录或者说连接界面,在框中输入
http://localhost:9200就可以监控我们集群中的节点状态
5.IK分词器插件
ik分词器是一个方便中文分词的工具,在英文中,基本是一个个的单词表征含义,而中文的词语分割很重要,比如小米手机,如果不用IK分词器,ES默认的分词结果是“小”“米”“手”“机”,而安装了分词器之后,可以识别“小米”“手机”。
下载完IK分词器后,我们的ES中将存在三种模式的分词:Ik(ik_smart 、 ik_max_word)、standard(es自带的)。如果我们不指定分词模式,则默认会执行standard,语句被拆分成一个一个字。而ik_max_word是最细粒度的拆分,也是ik默认的,ik_smart是做最粗粒度的拆分。
举个最简单的例子,对于“进口红酒”,三种拆分分别是:
standard:进、口、红、酒
ik_smart:进口、红酒
ik_max_word:进口、口红、红酒
在检索中我们提到ES的数据排序方式是倒排,由单词定位文档,因此单词的切割方式也变得非常重要,在中文习惯中,我们并不是一个字一个字的阅读,而是通过词组构成语句来判定句意。我们更希望以有意义的词语划分句子,而不是以单个字划分。
于是,一般来说,为了更好地索引和查询,会在ES中安装插件IK分词器。在下列链接中,有一些样例可以很比较直观地感受到IK分词器与默认分词器的不同之处。
五、其他功能(未尝试)
1.继续探索Kibana界面。打开左侧菜单栏
-
Kibana→Canvas/Maps/Machine Learning/Graph
-
Enterprise→App Search/Workplace Search
-
Observability→User Experience
-
Security板块(主机界面目前有少量展示信息)
2.利用ELK的后期操作获取带有高度的建筑模型
后记
没有设置大标题,篇幅有点多就不放前言当成后记吧,看到这里的人应该也不多,只是一点自己的心情。写博客既是记录,也是分享。这是目前以来整理最长的一篇了。
在技术领域(或者所有领域),可能经验特别重要,导师的教导可以让我们快速入门,省下大量精力去进行新的摸索。很多优秀博主的整理也同样,让我们不用去啃原本生硬的词汇和解释。所以我一向乐于在自己的博客中贴上其他博主的好文章,因为真实有帮助到我或让我有所收获,希望他们能继续影响其他人。也不喜欢只是转载,还是要有所自己的增添或进一步的摸索、整合,且自己确实实验过可行才会写出来。不然全网一样的内容就没了意义,看似十个链接提供了方案,其实不过是同样的两三种而已。
ELK是我在实习期间接触到的任务,从一个从未听说过ELK的小白,到渐渐有所了解并独立解决bug,实习期两个月结束,博客也写了40篇整。是对自己学习过程的总结,是为了也许将来有一天还会重新回顾、拾起或成为下一次面试题,也为了给大家做一个参考。
一开始是上级搭建好了单机ELK,只是让我尝试使用,结果出了bug,一直无法打开。等待期间我便自己学着搭建,竟然也成功了。那时候还没有集群的概念,也对ELK做什么一知半解,但一步步跟着其他人的博客却也运行起来了。后来在内网要搭建集群,但是自己缺少了一些集群部署的基础和功力,还是上级做的规划,完成了基本的ELasticsearch安装。而我按照单机的经验和导师的建议,一步步在安装logstash、beats、kibana以及各种插件(比如head、IK分词器),常遇到一些奇奇怪怪的坑,在网上也很难查到解决方案,有时候一个坑要解决一个下午甚至一两天。
踩坑的过程中常觉得,怎么会有这种坑,这怎么解决啊,靠,怎么都搞不出来。各种方法试着试着,一种不行换一种,有时候忽然就明白问题在哪里了。或者有时候,问题解决了,其实没明白为什么, 反而是在写博客的过程中,因为希望能让他人看懂,自己才更加清晰了。所谓读书百遍其意自现,其实也就是第一遍无法理解或没有意识到的地方,多读几次,就串接在一起。灵光乍现不能算聪慧,不过是知识的积累。我也做了相关笔记希望对踩坑的人有所帮助。
ELK还有许许多多的功能没有探索,学习也永无止境。实践是最好的老师,如果是在大学上了一门ELK的课,估计课程结束可以考个高分,但也没有什么感触,这样任务导向型的学习方式我很喜欢,在达到目标的过程中掌握更多,联结知识。也在一次次尝试和磨练中让我相信,有问题就会有办法,前人的分享也需要感谢,毕竟不是每一个替我们踩坑的人都有耐心传授给他人的。发现有人的方法能解决bug的时候,简直像发现了宝藏,教师也好,讨论空间也罢,可能就是这样一次次一代代承接下来的经验在推动发展吧
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/213434.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
