大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
除了数字,Python中最常见的数据类型就是字符串,无论那种编程语言,字符串无处不在。例如,从用户哪里读取字符串,并将字符串打印到屏幕显示出来。 字符串是一种数据结构,这让我们有机会学习索引和切片——用于从字符串中提取子串的方法。
1 字符串索引
在Python语法支持中,我们简单的阐述过字符串的使用,现在我们看看python程序在处理字符串时,如何对其进行索引,打印出其中的每个字符串。我们输入一个字符串:’你好,Lucky’,Python使用方括号 [] 来对字符串进行索引,方括号内的数字 0~n 表示将要获取的字符串,如图1-1所示,sting[0~7]分别对应不同的值,最小的字符换索引为0,最大的字符串索引比字符串长度小1。
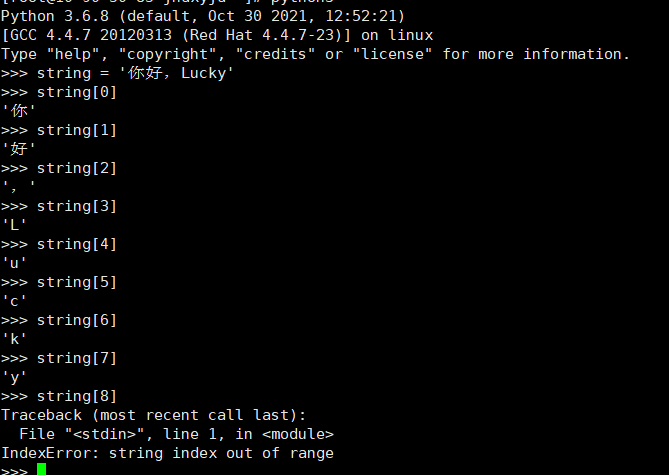

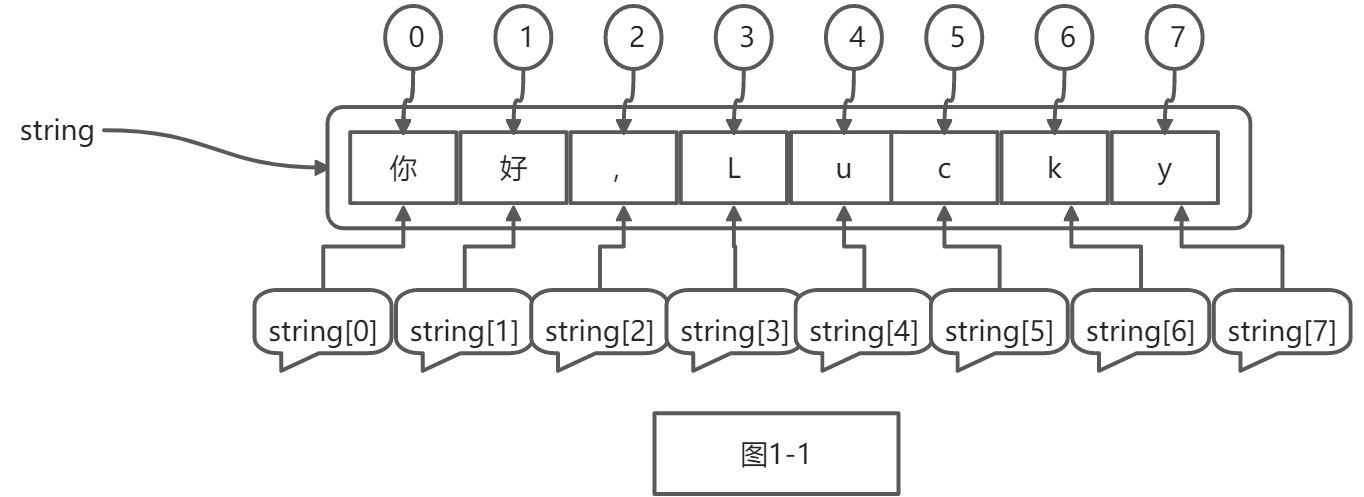
如果 string 指向一个长度为 n 的字符串, 则 string[0] 为第一个字符,string[1] 为第二个字符, string[2] 为第三个字符,依此类推。string[n-1] 为最后一个字符。当然,在上面的示例中,string[8]索引超出了字符串的末尾,导致的错误提示,这点需要注意。Python索引为何从0开始?我们这样理解便可: 索引值用于测量与字符串第一个字符相隔的距离, 就像一把尺子(其刻度也是从零开始)。这 让有些索引计算更简单,也与函数 %(求余) 一致。% 经常用于索引计算,自然也可能返回 0。
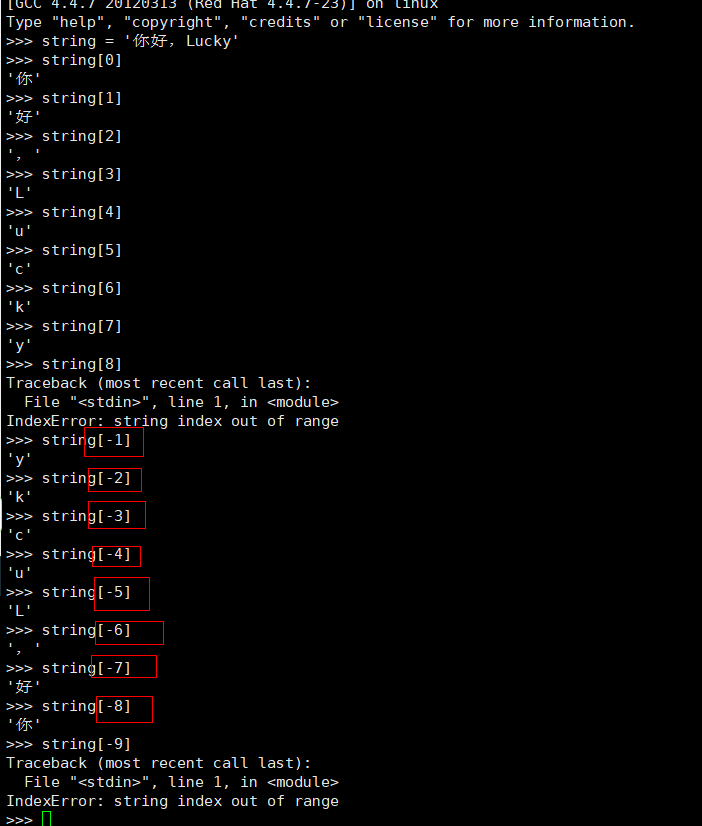
实际应用中,往往不会只用到正向索引(本文理解从左向右),当你需要访问字符串的最后一个字符时,也可以使用正向表达式,但字符串过长时明显不便,所以Python提供了一种方面的索引方式:从右向左(负数索引)来表示。如下:字符串的最后一个字符为 string[-1],其索引过程即可按照图1-1进行修改,此处不做阐述。
1.1 循环索引字符
假如需要依次访问字符串的每个字符,需要计算出所给字符串的编码总和,对比两种代码方法,如下图实现及结果,第一种codesum1()函数: 使用 for 循环时,在循环的每次迭代开头,都会将循环变量 c 设置为 s 中的 下一个字符。使用索引访问 s 中字符的工作由 for 循环自动处理。
第二种codesum2()函数使用了常规访问s中字符的方法,对比codesum1()函数可以发现,虽然二者计算结果一致,但第二种函数的代码明显较为复杂,理解程度上稍微差一些。当然,这是多数人的理解,有些人可能觉得第二种实现更好一些。
def codesum1(s):
total = 0
for c in s:
total = total + ord(c)
return total
def codesum2(s):
total = 0
for i in range(len(s)):
total = total + ord(s[i])
return total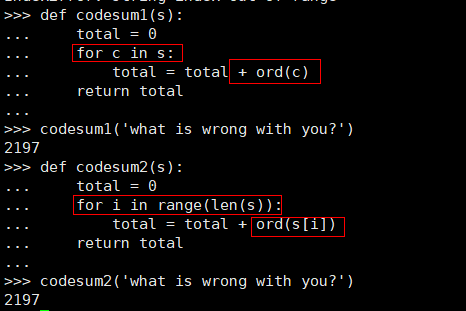
2 字符使用
在所有编程语言中,字符串都是由字符所组成,而所有字符都有对应的字符编码与之相对应。在Python中,我们可以使用ord()函数来学习。ord() 函数是 chr() 函数(对于8位的ASCII字符串)或 unichr() 函数(对于Unicode对象)的配对函数,它以一个字符(长度为1的字符串)作为参数,返回对应的 ASCII 数值,或者 Unicode 数值,如果所给的 Unicode 字符超出了你的 Python 定义范围,则会引发一个 TypeError 的异常。
关于Unicode做一个简单的背景介绍: Unicode 提供了一个大得多的字符编码集。出于方便考虑,Unicode 的前 256 个 字母为 ASCII 码,因此如果你只处理英文字符,几乎不用考虑 Unicode 的细节。
>>> ord('a')
97
>>> ord('b')
98
>>> ord('c')
99
给定字符编码,可使用函数 chr 来获悉对应的字符:
>>> chr(99)
'c'
>>> chr(98)
'b'
>>> chr(97)
'a'
字符编码是根据Unicode分配的,而Unicode是一个庞杂的编码标准,涵盖了全球各种语言中的符号和字符,使用十分广泛 。并非所有字符都有可视的标准符号。例如,换行字符、回车字符和制表符都是不可见的,虽然它们带来的效果可见。这些字符属于空白字符——在印刷页面上显示为空白。 如下表:
|
转义字符 |
描述 |
|
\(在行尾时) |
续行符 |
|
\\ |
反斜杠符号 |
|
\’ |
单引号 |
|
\” |
双引号 |
|
\a |
响铃 |
|
\b |
退格(Backspace) |
|
\e |
转义 |
|
\000 |
空 |
|
\n |
换行 |
|
\v |
纵向制表符 |
|
\t |
横向制表符 |
|
\r |
回车 |
|
\f |
换页 |
|
\oyy |
八进制数,y 代表 0~7 的字符,例如:\012 代表换行。 |
|
\xyy |
十六进制数,以 \x 开头,yy代表的字符,例如:\x0a代表换行 |
|
\other |
其它的字符以普通格式输出 |
举两个个简单的常用示例:
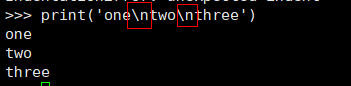
1. 在 Python 中,表示换行的标准方式是使用字符 \n:
2. 在字符串中包含反斜杠、单引号和双引号,通常需要使用对应的转义字符:
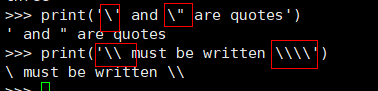
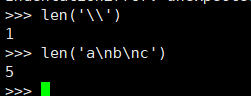
转义字符是单个字符, 为让 Python 知道下一个字符是特殊字符, 必须使用 \,但在计算字符串的长度时,并不将 \ 视为额外的字符。例如:
在使用转义字符时,还有一点需要特别注意的是:在表示文本行末尾方面,不同操作系统遵循的标准是不同的。Windows 使 用 \r\n 表示行尾,OS X 和 Linux 使用 \n, 而 OS X 之前的 Mac 操作系统使用 \r。
2.1 字符串运算
数字有其标准的运算方式,字符串同样也有着一定的运算。下面来看下字符串的运算符。
|
操作符 |
描述 |
|
+ |
字符串连接 |
|
* |
重复输出字符串 |
|
[] |
通过索引获取字符串中字符 |
|
[ : ] |
截取字符串中的一部分 |
|
in |
成员运算符 – 如果字符串中包含给定的字符返回 True |
|
not in |
成员运算符 – 如果字符串中不包含给定的字符返回 True |
|
r/R |
原始字符串 – 原始字符串:所有的字符串都是直接按照字面的意思来使用,没有转义特殊或不能打印的字符。 原始字符串除在字符串的第一个引号前加上字母”r”(可以大小写)以外,与普通字符串有着几乎完全相同的语法。 |
示例 :
1.x和y分别赋值字符串;
>>> x = "I am coming"
>>> y = "Python Language"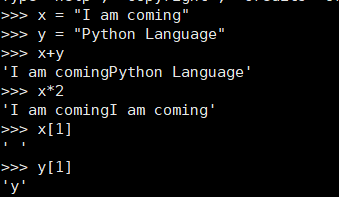
3 字符串切片
在 Python 中,可使用切片从字符串中提取子串。要对字符串执行切片操作,可指定两个索引:要提取的第一个字符的索引;要提取的最后一个字符的索引加 1。例如:
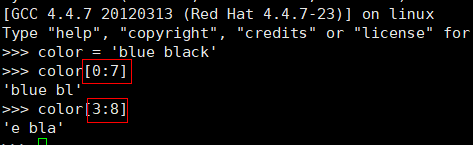
用于切片的索引与用于访问各个字符的索引相同:第一个索引总是为零,而最后一个索引总是比字符串长度小 1。一般而言,string[begin:end]返回从索 引 begin 到 end-1 的子串。注意:如果 string 是一个字符串,则要访问索引 i 对应的字符,可使用 string[i] 或 string[i:i+1]。
3.1 切片方法
如果想要省略字符串的起始索引,Python将假定为0;如果需要省略字符串的终止索引,Python 会假设你要提取到字符串末尾。
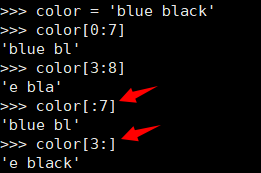
实用示例:取值文件名中的扩展名。
def get_ext(fname):
dot = fname.rfind('.')
if dot == -1: # fname 中没有
return ''
else:
return fname[dot + 1:]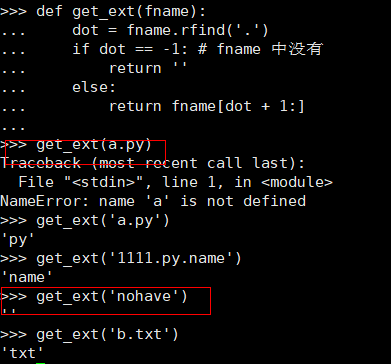
注意第一处标红需要加引号好,第二处输入的文件名没有扩展名,故没有返回值。该函数的实现过程:确定最右边的 ‘.’ 的索引(因此使用 rfind 从右往左查 找);如果 fname 不包含 ‘.’,则返回一个空字符串,否则返回 ‘.’ 后面的所有字符。
在索引字符串时所讲述的正向、负向索引同样可以应用于切片中。
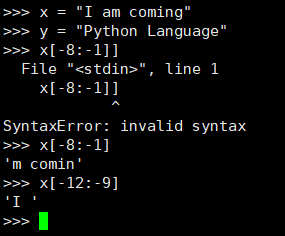
使用负数索引时,这样做通常会有所帮助:将字符串写到纸上,再标出每个字符的正索引和负索引,就像图 1-1 那样。虽然这样做确实需要多用一两分钟时间,但可以很好地避免常见的索引错误。
4 字符串格式化
Python 支持格式化字符串的输出 。这会用到一个较为复杂的表达式,但最基本的用法是将一个值插入到一个有字符串格式符 %s 的字符串中。
>>> print("我最喜欢的食物是%s,它的热量是%d千焦" %('hot dog',3500))
我最喜欢的食物是hot dog,它的热量是3500千焦我们将python字符串格式化符号整理如下:标红为字符串格式化中的辅助指令
|
符 号 |
描述 |
|
%c |
格式化字符及其ASCII码 |
|
%s |
格式化字符串 |
|
%d |
格式化整数 |
|
%u |
格式化无符号整型 |
|
%o |
格式化无符号八进制数 |
|
%x |
格式化无符号十六进制数 |
|
%X |
格式化无符号十六进制数(大写) |
|
%f |
格式化浮点数字,可指定小数点后的精度 |
|
%e |
用科学计数法格式化浮点数 |
|
%E |
作用同%e,用科学计数法格式化浮点数 |
|
%g |
%f和%e的简写 |
|
%G |
%F 和 %E 的简写 |
|
%p |
用十六进制数格式化变量的地址 |
|
* |
定义宽度或者小数点精度 |
|
– |
用做左对齐 |
|
+ |
在正数前面显示加号( + ) |
|
<sp> |
在正数前面显示空格 |
|
# |
在八进制数前面显示零(‘0′),在十六进制前面显示’0x’或者’0X'(取决于用的是’x’还是’X’) |
|
0 |
显示的数字前面填充’0’而不是默认的空格 |
|
% |
‘%%’输出一个单一的’%’ |
|
(var) |
映射变量(字典参数) |
|
m.n. |
m 是显示的最小总宽度,n 是小数点后的位数(如果可用的话) |
示例:
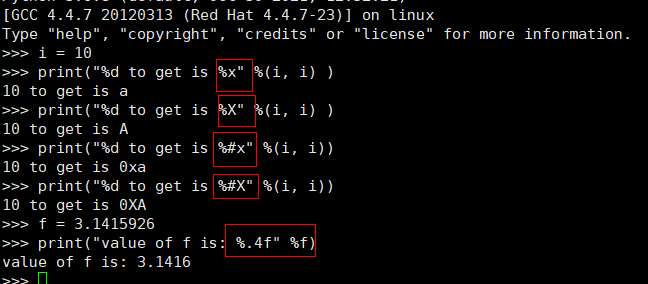

对于Python字符串格式化的输出,可以通过上述几个例子体验一下字符串区别与基本使用。Python本身已经自带了许多很有用的函数模块,简化了字符串的使用,增强了其功能。后面,我们会对Python的字符串函数以及正则使用做较为详细的阐述。
Python:变量、参数、模块_涤生手记大数据-CSDN博客
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/210039.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
