大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
更多博文请关注:https://blog.bigcoder.cn
前不久在学习中意外发现了自己原来忽略的一个小知识点,挺有意思的,现在我来给大家分享一下!
我们先来看一段代码
public class Hello {
public static void main(String[] args) {
String str="haha";
new Thread() {
@Override
public void run() {
System.out.println(str);
}
}.start();
}
}
现在我问问大家,这个打印的程序的结果是什么?
可能大部分人毫不犹豫的会说:打印“haha”。其实这个程序根本就编译不通过(有点答非所问的感觉,哈哈)。
因为在JDK8之前,如果我们在匿名内部类中需要访问局部变量,那么这个局部变量必须用final修饰符修饰。这里所说的匿名内部类指的是在外部类的成员方法中定义的内部类。既然是在方法中创建的内部类,必然会在某些业务逻辑中出现访问这个方法的局部变量的需求。那么我们下面就会研究这种情况。
为什么java语法要求我们需要用final修饰呢?想了想没有什么答案,那我们就通过jd-gui反编译工具一探究竟,我们对匿名内部类的字节码文件进行反编译得到以下内容。

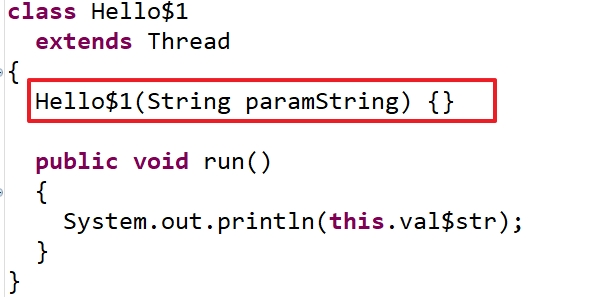
我们可以看到匿名内部类的构造器中传入了一个参数,我们可以推理出这个参数就是底层传入的str的值,但因为反编译工具的某种疏忽将构造器的方法体写成了空,事实上真正的反编译代码应该是下面:
public class Hello$1 extends Thread {
private String val$str;
Hello$1(String paramString) {
this.val$str = paramString;
}
public void run() {
System.out.println(this.val$str);
}
}
也就是说匿名内部类之所以可以访问局部变量,是因为在底层将这个局部变量的值传入到了匿名内部类中,并且以匿名内部类的成员变量的形式存在,这个值的传递过程是通过匿名内部类的构造器完成的。
那么问题又来了,为什么需要用final修饰局部变量呢?
按照习惯,我依旧先给出问题的答案:用final修饰实际上就是为了保护数据的一致性。
这里所说的数据一致性,对引用变量来说是引用地址的一致性,对基本类型来说就是值的一致性。
这里我插一点,final修饰符对变量来说,深层次的理解就是保障变量值的一致性。为什么这么说呢?因为引用类型变量其本质是存入的是一个引用地址,说白了还是一个值(可以理解为内存中的地址值)。用final修饰后,这个这个引用变量的地址值不能改变,所以这个引用变量就无法再指向其它对象了。
回到正题,为什么需要用final保护数据的一致性呢?
因为将数据拷贝完成后,如果不用final修饰,则原先的局部变量可以发生变化。这里到了问题的核心了,如果局部变量发生变化后,匿名内部类是不知道的(因为他只是拷贝了局不变量的值,并不是直接使用的局部变量)。这里举个栗子:原先局部变量指向的是对象A,在创建匿名内部类后,匿名内部类中的成员变量也指向A对象。但过了一段时间局部变量的值指向另外一个B对象,但此时匿名内部类中还是指向原先的A对象。那么程序再接着运行下去,可能就会导致程序运行的结果与预期不同。
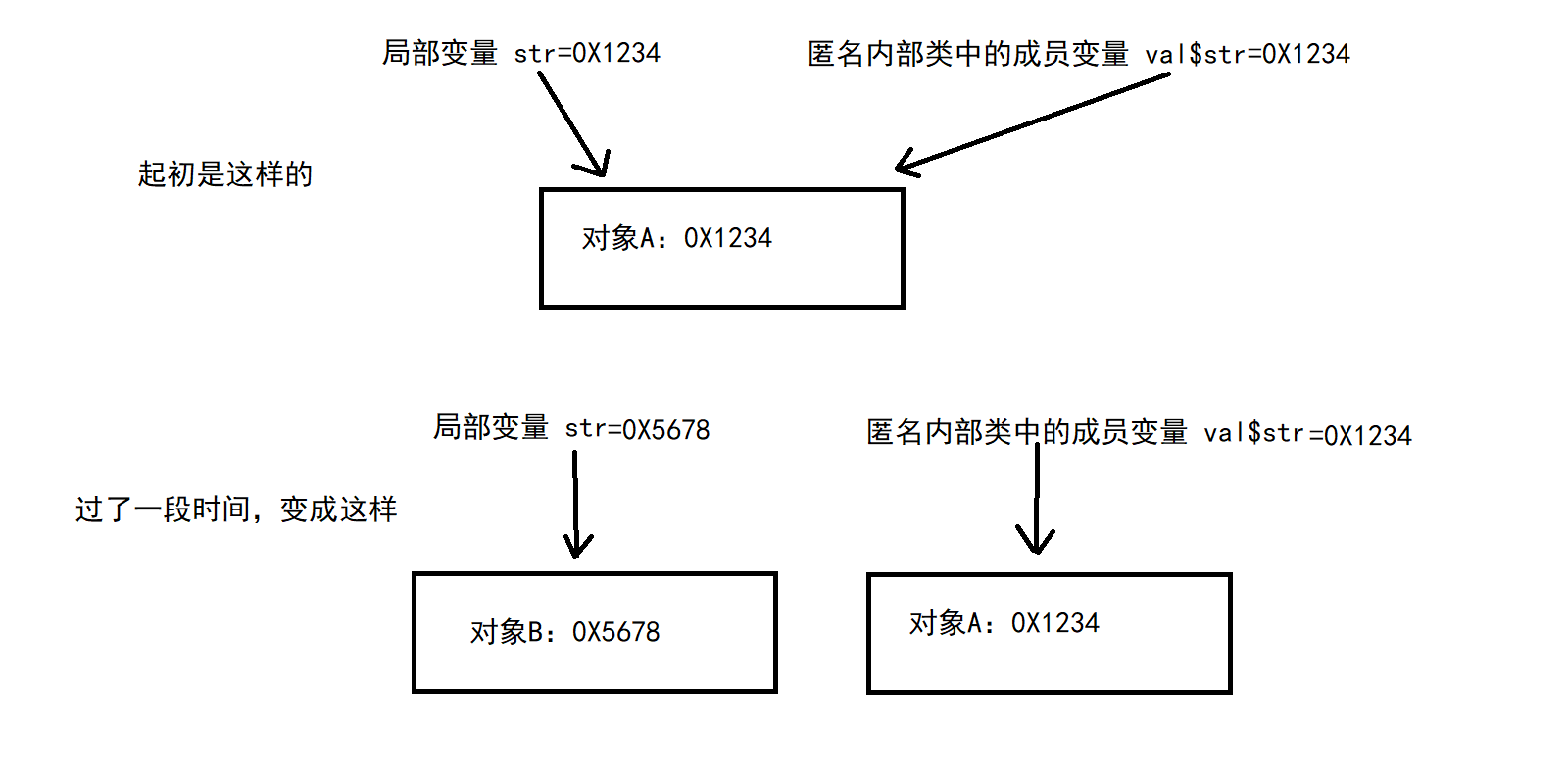
介绍到这里,关于为什么匿名内部类访问局部变量需要加final修饰符的原理基本讲完了。那现在我们来谈一谈JDK8对这一问题的新的知识点。在JDK8中如果我们在匿名内部类中需要访问局部变量,那么这个局部变量不需要用final修饰符修饰。看似是一种编译机制的改变,实际上就是一个语法糖(底层还是帮你加了final)。但通过反编译没有看到底层为我们加上final,但我们无法改变这个局部变量的引用值,如果改变就会编译报错。
有兴趣的小伙伴可以关注博主
原创不易,帮忙点个赞撒!!!!(如有错误,欢迎指正!!)
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/210036.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
