大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
大家好,我是小小明,今天我计划搭建一个代理IP池,采集一些公开的免费的代理IP,放入缓存池中。
要搭建一个代理ip池,我的思路:
- 爬虫定期爬取代理IP,验证代理iP有效性,有效则存入Redis数据库
- 一个线程或进程定期检查代理ip池的有效性,无效则从中删除
虽然不如直接购买付费的代理IP好用,但是以此训练一下相关技术能力。
本文的目标是至少演示如下技术:
- pandas超简代码带请求头解析表格
- 查看访问IP的方法
- 搭建简易检验代理Ip的网站
- Redis数据库的基本操作
- 代理ip在request库中的使用方法
- Timer定时器的使用
- Redis 图形化工具的使用介绍
代理IP的爬取与解析
下面,首先去选择几个免费代理ip的网址去爬一下,百度一下代理ip关键字能够查到很多网站。
这里我选择崔老师书中推荐的一个代理网站进行测试,它提供了高匿代理和普通代理两个页面。
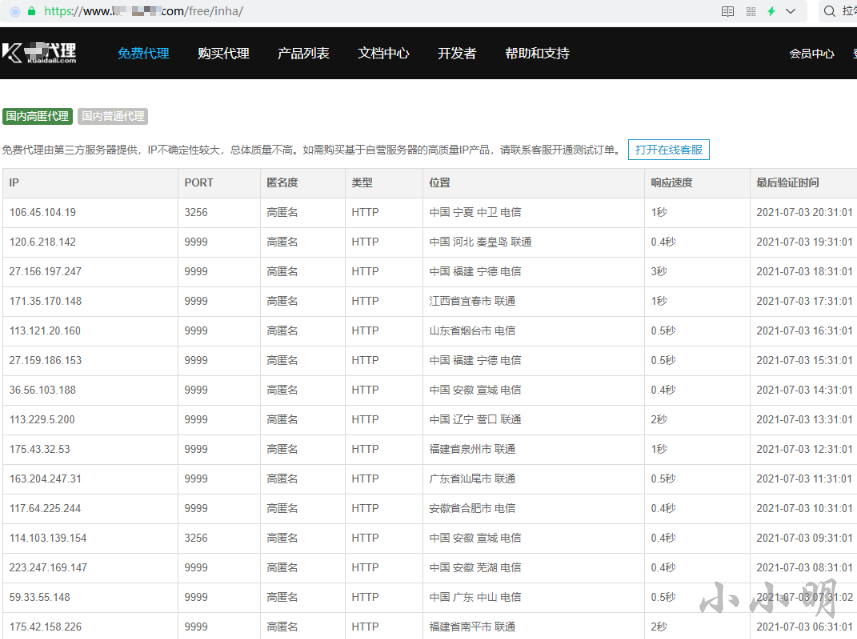

爬取高匿测试一下:
import requests
import pandas as pd
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.106 Safari/537.36'
}
i = 1
url = f'https://www.kuaidaili.com/free/inha/{
i}/'
r = requests.get(url, headers=headers)
r.encoding = 'u8'
ip_df, = pd.read_html(r.text)
ip_df
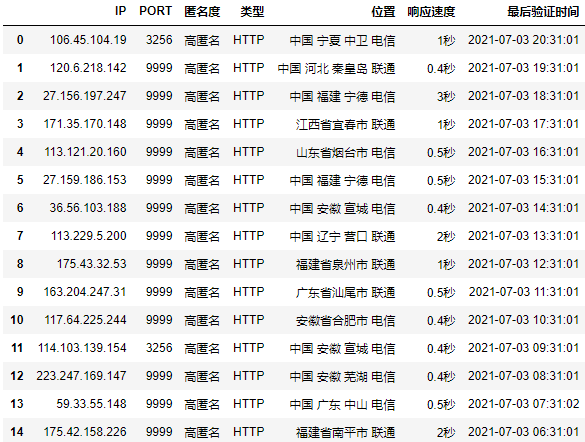
代理IP爬了,但是是否真的能用呢?
代理IP的校验
我们需要验证一下,有个不错的测试网站是httpbin.org,我们可以通过它来读取自己的ip地址:
r = requests.get(f"http://httpbin.org/ip")
r.json()
结果大致形式:
{'origin': '116.xx.xx.xxx'}
然后以如下形式访问代理ip:
r = requests.get(f"http://httpbin.org/ip",
proxies={
'http': "175.42.158.226:9999"})
r.json()
若抛出异常:

说明代理失效。
在我们的机器有公网IP时,我们也可以搭建自己的服务器用于校验代理IP有效性,flask代码:
from flask import *
app = Flask(__name__)
@app.route('/')
def index():
return request.remote_addr
if __name__ == '__main__':
app.run(host="0.0.0.0", port=8088)
基于此我们可以写一个校验代理IP的方法:
def proxie_ip_validity_check(proxie_ip, proxie_type='http', timeout=1):
try:
r = requests.get(f"{
proxie_type}://httpbin.org/ip", headers=headers,
proxies={
proxie_type: proxie_ip}, timeout=timeout)
if r.status_code == 200:
return True
return False
except Exception as e:
return False
经过我个人测试,高匿代理似乎没有一个是可以用的,所以这次我们只爬取普通代理ip。
批量爬取普通代理ip
设置超时时间为2秒,取7页数据:
import requests
import pandas as pd
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.106 Safari/537.36'
}
http_ip_pool = []
https_ip_pool = []
for page in range(1, 8):
print("当前爬取页面数:", page)
url = f'https://www.kuaidaili.com/free/intr/{
page}'
r = requests.get(url, headers=headers)
r.encoding = 'u8'
ip_df, = pd.read_html(r.text)
for ip, port, proxie_type in ip_df[["IP", "PORT", "类型"]].values:
pool = http_ip_pool if proxie_type.lower() == 'http' else https_ip_pool
proxie_ip = f"{
ip}:{
port}"
if proxie_ip_validity_check(proxie_ip, proxie_type.lower(), 2):
pool.append(proxie_ip)
len(http_ip_pool), len(https_ip_pool)
经测试爬到26个有效的代理ip,全部都是http类型:
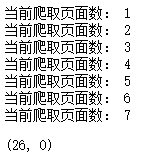
写入到Redis服务器
为了方便其他爬虫程序使用,我们将爬到的代理IP写入到Redis数据库中。
首先需要安装Redis,下载地址:https://github.com/MicrosoftArchive/redis/releases
我的是Windows平台选择了:https://github.com/microsoftarchive/redis/releases/download/win-3.0.504/Redis-x64-3.0.504.zip
解压后直接双击redis-server.exe即可启动Redis服务器:
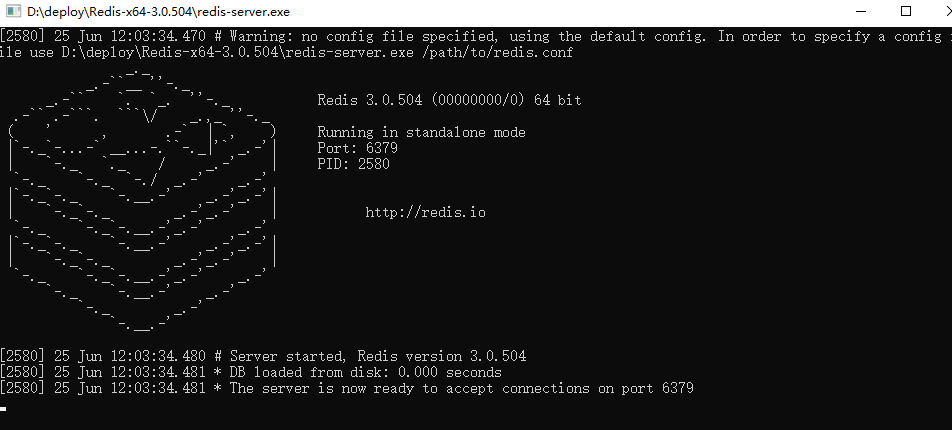
安装让Python操作redis的库:
pip install redis
基本使用:
import redis
r = redis.Redis(host='192.168.3.31', port=6379, db=0)
r.set('name', 'zhangsan') # 添加
print(r.get('name'))
b'zhangsan'
考虑将代理IP存入Redis的set集合中,因为可以自动去重,测试一下:
r.sadd("proxie_ip", "ip1", "ip2")
r.sadd("proxie_ip", "ip2", "ip3")
r.smembers("proxie_ip")
{b'ip1', b'ip2', b'ip3'}
于是我们可以通过以下命令一次性存入Redis中:
if len(http_ip_pool)>0:
r.sadd("proxie_ip_http", *http_ip_pool)
if len(https_ip_pool)>0:
r.sadd("proxie_ip_https", *https_ip_pool)
存入Redis数据库后,Redis就已经相当于一个代理IP池,下面我们另外启动一个尝试,常识使用这些代理IP:
从代理IP池中获取代理IP并使用
读取代理IP:
import redis
with redis.Redis(host='192.168.3.31', port=6379, db=0) as r:
http_ip_bytes = r.smembers("proxie_ip_http")
http_ip_pool = list(map(bytes.decode, http_ip_bytes))
http_ip_pool
['139.9.25.69:3128',
'119.3.235.101:3128',
'122.51.207.244:8888',
'106.58.191.24:8888',
'222.74.202.229:9999',
'47.111.71.29:8081',
'222.74.202.229:80',
'222.74.202.244:80',
'106.58.191.218:8888',
'222.74.202.229:8080']
然后可以拿来模拟爬百度:
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.106 Safari/537.36'
}
for ip in http_ip_pool:
try:
r = requests.get(f"http://www.baidu.com/",
headers=headers, proxies={
'http': ip}, timeout=1)
print(r.status_code)
except Exception as e:
print(e)
HTTPConnectionPool(host='139.9.25.69', port=3128): Max retries exceeded with url: http://www.baidu.com/ (Caused by ConnectTimeoutError(<urllib3.connection.HTTPConnection object at 0x0000028D6A993248>, 'Connection to 139.9.25.69 timed out. (connect timeout=1)'))
200
200
HTTPConnectionPool(host='106.58.191.24', port=8888): Max retries exceeded with url: http://www.baidu.com/ (Caused by ConnectTimeoutError(<urllib3.connection.HTTPConnection object at 0x0000028D6B59C2C8>, 'Connection to 106.58.191.24 timed out. (connect timeout=1)'))
200
HTTPConnectionPool(host='47.111.71.29', port=8081): Max retries exceeded with url: http://www.baidu.com/ (Caused by ProxyError('Cannot connect to proxy.', RemoteDisconnected('Remote end closed connection without response')))
200
200
HTTPConnectionPool(host='106.58.191.218', port=8888): Max retries exceeded with url: http://www.baidu.com/ (Caused by ConnectTimeoutError(<urllib3.connection.HTTPConnection object at 0x0000028D6A9C2F88>, 'Connection to 106.58.191.218 timed out. (connect timeout=1)'))
200
可以看到只有一半的代理IP能在指定时间内成功访问百度,说明免费的代理IP就是不如收费的稳定。
定期爬取并清除失效的代理IP
只要再完成这部分,我们的代理IP池就能够初见雏形,冲!
最终完成代码:
import requests
import pandas as pd
import redis
from threading import Timer
import time
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.106 Safari/537.36'
}
def proxie_ip_validity_check(proxie_ip, proxie_type='http', timeout=2):
try:
r = requests.get(f"{
proxie_type}://httpbin.org/ip",
proxies={
proxie_type: proxie_ip}, timeout=timeout)
if r.status_code == 200:
return True
return False
except:
return False
redis_conn = redis.Redis(host='192.168.3.31', port=6379)
def crawl_proxy_ip2redis():
for page in range(1, 20):
print("当前爬取页面:", page)
url = f'https://www.kuaidaili.com/free/intr/{
page}'
r = requests.get(url, headers=headers)
r.encoding = 'u8'
ip_df, = pd.read_html(r.text)
for ip, port, proxie_type in ip_df[["IP", "PORT", "类型"]].values:
proxie_ip = f"{
ip}:{
port}"
proxie_type = proxie_type.lower()
if proxie_ip_validity_check(proxie_ip, proxie_type, 2):
redis_conn.sadd(f"proxie_ip_{
proxie_type}", proxie_ip)
def get_proxy_ip_pool(proxie_type='http'):
http_ip_bytes = redis_conn.smembers(f"proxie_ip_{
proxie_type}")
http_ip_pool = list(map(bytes.decode, http_ip_bytes))
return http_ip_pool
def clear_invalid_proxie_ip():
print("开始清空失效代理ip:")
for proxie_type in ['http', 'https']:
for ip in get_proxy_ip_pool(proxie_type):
if not proxie_ip_validity_check(ip, proxie_type, 2):
print(proxie_type, ip, "失效")
redis_conn.srem(f"proxie_ip_{
proxie_type}", ip)
crawl_proxy_ip2redis()
while True:
# 5分钟后清空一次失效的代理ip
Timer(5 * 60, clear_invalid_proxie_ip, ()).start()
# 10分钟后下载一次代理ip
Timer(10 * 60, crawl_proxy_ip2redis, ()).start()
# 每隔10分钟一个周期
time.sleep(10 * 60)
目前测试,这个Redis代理IP池还算好使,作为一个雏形勉强能用。
可以通过Redis图形化工具查看代理IP池的存储情况:
我使用的工具叫Redis Desktop Manager,可以百度下载。
目前我个人还算满意。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/210034.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
