大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
ElasticJob分布式调度,分布式多个微服务执行只需要执行一个定时任务,基本概念介绍(一)
问题背景
最近的项目中需要做一个定时任务,该项目是一个分布式多节点调度任务,所以里面的定时任务在不同的节点不应该同时进行,应该使用其中一个节点做定时任务,目前寻找的方案为ElasticJob,这个篇章简单介绍一下
ElasticJob简介
1 Elastic-job官网地址:https://shardingsphere.apache.org/elasticjob/current/cn/overview/
Elastic-Job的github地址: https://github.com/elasticjob
2 打开官网可以知道ElasticJob 已于 2020 年 5 月 28 日成为 Apache ShardingSphere 的子项目,所以在这之前我看别人都是使用dangdang的依赖,Elastic-Job 是elastic-job是当当开源的作业框架,在这之前,开发定时任务一般都是使用quartz或者spring-task(ScheduledExecutorService),无论是使用quartz还是spring-task,都会至少遇到两个痛点:
- 不敢轻易跟着应用服务多节点部署
- 可能会重复多次执行而引发系统逻辑的错误
3 quartz的集群仅仅只是用来HA(提高可用性),节点数量的增加并不能给我们的每次执行效率带来提升,即不能实现水平扩展
4 Elastic job是当当网基于Zookepper、Quartz开发并开源的一个Java分布式定时任务,解决了Quartz不支持分布式的弊端
5 Elastic job主要的功能有支持弹性扩容,通过Zookepper集中管理和监控job,支持失效转移等。项目由两个相互独立的子项目Elastic-Job-Lite和Elastic-Job-Cloud组成
6 分布式:一个大的业务拆分成多个小业务分别部署在服务器,如:订单服务、商品服务和用户服务
7 分布式任务调度:订单服务中定时统计订单信息,商品服务中定时更新商品信息,用户服务定时更新用户信息
8 Elastic-Job的优点:
- 并行任务调度(多台服务器同时执行任务)
- 高可用
- 高扩展
- 任务管理和检测
- 避免任务重复执行
单节点的定时任务
1 如果只是一个单节点,定时任务大可使用spring的注解@Scheduled,并在启动类使能定时注解@EnableScheduling注解,此注解才能让定时任务生效
@Scheduled(cron = "0/5 * * * * ? ") //此为cron表达式,设置定时所需的时间点或周期
public void timeTask(){
//doSomething
}
如果任务的数据量为3000W非常大,一台服务器的硬件资源cpu和内存都是有限的,这是就可以使用分布式定时调度,可以分为3个节点分别处理1000W数据
分布式调度
1 使用分布式调度的情况
- 单机处理极限:原本1分钟内需要处理1万个订单,但是现在需要1分钟内处理10万个订单;原来一个统计需要1小时,现在业务方需要10分钟就统计出来。如果使用多线程、单机多进程处理,多线程并行处理可以提高单位时间的处理效率,但是单机能力有限(主要是CPU、内存和磁盘),始终会有单机处理不过来的情况
- 高可用:单机版的定式任务调度只能在一台机器上运行,如果程序或者系统出现异常就会导致功能不可用,对于核心功能是不允许的,所以才有集群出现
- 防止重复执行: 在单机模式下,定时任务是没什么问题的。但当我们部署了多台服务,同时又每台服务又有定时任务时,若不进行合理的控制在同一时间,只有一个定时任务启动执行,这时,定时执行的结果就可能存在混乱和错误了
2 两种情况使用分布式调度
- 例1:要去对表的数据进行备份的操作,这个表中有1000W条数据,若是我们只是单一去执行这个需求,那么会耗费很多的时间,那么这种情况就有可能会去进行一个集群,但是集群后又会出现一个问题,就是在spring定时器情况下,所有的集群做的都是同样的是事情,而我们需要的就是不同的微服务做的是不同的,但是都是为了去备份这一份数据库的数据,所以无法实现。分布式调度就是分治思想,将大的拆成小的,分成多份各自执行各自的,但是都是为了完成一个需求
- 例2: 要把mysql数据同步到redis中,比如有两个服务,此时两个服务都有定时任务,这个定时任务就会在两台机器中同时执行,我们可能只想要让其中一个去执行,而不是同时执行,所以使用spring定时器是不行的。使用分布式调度,因为集群中都是同样功能,但是定时器只需要其中一个进行执行就可以
3 ElasticJob功能列表
– 分布式调度
在分布式环境中,任务能够按照指定的调度策略执行,并且能够避免同一任务多实例重复执行
– 调度策略
基于成熟的定时任务作业框架Quartz cron表达式执行定时任务
– 弹性扩容所容
当集群中增加一个实例,它应当能够被选举被执行任务;当集群减少一个实例时,他所执行的任务能被转移到别的示例中执行
– 失效转移
某示例在任务执行失败后,会被转移到其他实例执行
– 错过执行任务重触发
若因某种原因导致作业错过执行,自动记录错误执行的作业,并在下次次作业完成后自动触发
– 支持并行调度
支持任务分片,任务分片是指将一个任务分成多个小任务在多个实例同时执行
– 作业分片一致性
当任务被分片后,保证同一分片在分布式环境中仅一个执行实例
– 支持作业生命周期操作
可以动态对任务进行开启及停止操作
– 丰富的作业类型
支持Simple、DataFlow、Script三种作业类型,elasticJob会把定时任务的信息存放到zookeeper中,zookeeper不单单是注册中心,也可以作为一个存数据的容器
– 系统架构图
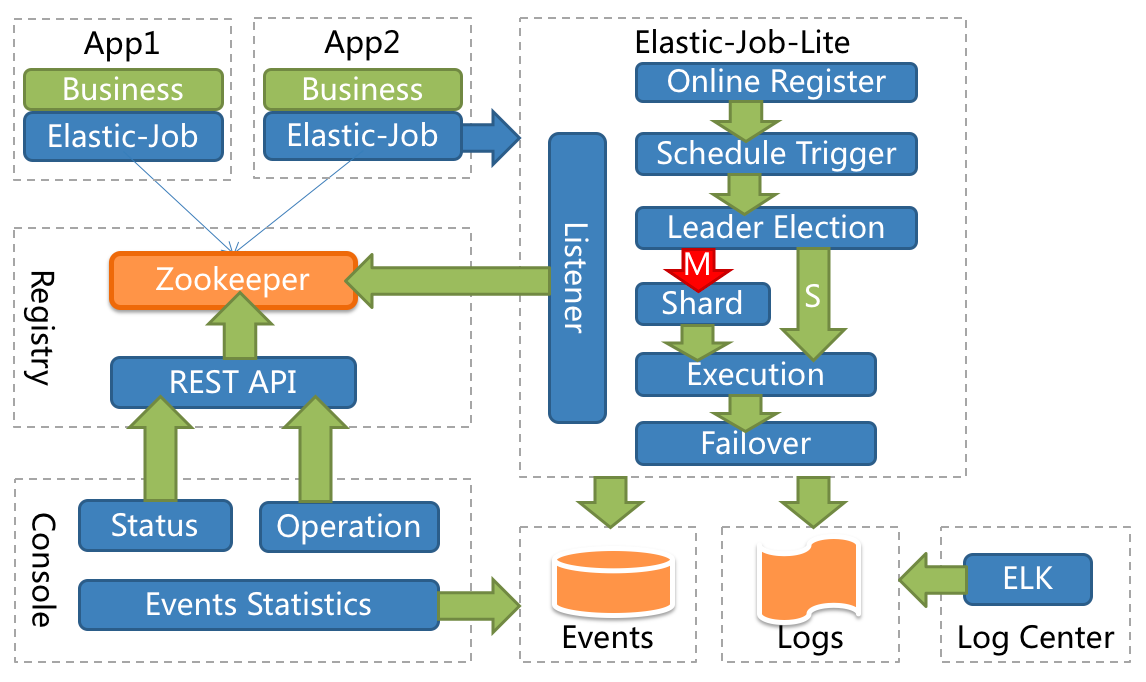

从图中可以看到,通过注册中心zookeeper去监听app应用,当出现节点数据及状态变化,可以进行通知,可以进行故障转移
分片的概念
1 作业分片是指任务的分布式执行,需要将一个任务拆分为多个独立的任务项,然后由分布式的应用实例分别执行某一个或者几个分布项
例如:有两台服务器,每台服务器分别跑一个应用实例,为了快速执行作业,可以将任务分成4片,那么每个应用实例都执行两片。作业遍历数据逻辑应为:实例1查找text和image类型文件执行备份,实例2查找radio和vedio类型文件执行备份。如果由于服务器扩容应用实例数量增加为4,则作业遍历数据的逻辑应为: 4个实例分别处理text,image,radio,video类型的文件。
通过对任务的合理分片化,从而达到任务并行处理的效果.
分片机制:多台机器执行一个任务,想要的效果就是一个大的任务拆分为很多小的任务并在多台机器中执行
2 分片项与业务处理解耦
Elastic-Job并不直接提供数据处理的功能,框架只会将分片项分配至各个运行中的作业服务器,开发者需要自行处理分片项与真实数据的对应关系
3 最大限度利用资源
将分片项设置大于服务器的数据,最好是大于服务器倍数的数量,作业将会合理利用分布式资源,动态的分配分片项.
例如: 3台服务器,分成10片,则分片项结果为服务器A=0,1,2;服务器B=3,4,5;服务器C=6,7,8,9;如果 服务器C崩溃,则分片项分配结果为服务器A=0,1,2,3,4;服务器B=5,6,7,8,9;在不丢失分片项的情况下,最大限度利用现有的资源提高吞吐量
Dataflow类型调度任务
1 Dataflow类型的定时任务需要实现Dataflowjob接口,该接口提供2个方法供覆盖,分别用于抓取(fetchData)和处理(processData)数据
2 Dataflow类型用于处理数据流,他和SimpleJob不同,它以数据流的方式执行,调用fetchData抓取数据,知道抓取不到数据才停止作业
3 simpleJob相当于生活中的搬家时一次性把所有东西都搬过去,Dataflowjob相当于分几次把东西搬走
例如:我们需要查询1000W条的数据库数据并备份,而我们若是一次性查出1000W的数据去统一做备份,那么可能效率就会比较低。若是使用dataflowjob 那么我们可以一次查询20W条数据备份完后再去处理后面的20W条数据,依次如此,一点点处理完
总结
作为程序员第 108 篇文章,每次写一句歌词记录一下,看看人生有几首歌的时间,wahahaha … 
Lyric: 就算没有结果
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/210002.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
