大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
基于SRGAN的图像超分辨率重建
本文偏新手项,因此只是作为定性学习使用,因此不涉及最后的定量评估环节
目录
1 简要介绍
SRGAN的原论文发表于CVPR2017,即《Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network》
SRGAN使用了生成对抗的方式来进行图像的超分辨率重建,同时提出了一个由Adversarial Loss和Content Loss组成的损失函数。
更详细的介绍可以去看看这篇文章 传送门
2 代码实现
2.1 开发环境
pytorch == '1.7.0+cu101'
numpy == '1.19.4'
PIL == '8.0.1'
tqdm == '4.52.0'
matplotlib == '3.3.3'
对于开发文件的路径为
/root
- /Urban100
- img_001.png
- img_002.png
···
- img_100.png
- /Img
- /model
- /result
- main.py #主代码应该放在这里
2.2 主要流程
这次代码的主要流程为
构 建 数 据 集 → 构 建 生 成 模 型 → 构 建 辨 别 模 型 → 构 建 迭 代 器 → 构 建 训 练 循 环 构建数据集\rightarrow 构建生成模型\rightarrow 构建辨别模型\rightarrow 构建迭代器\rightarrow 构建训练循环 构建数据集→构建生成模型→构建辨别模型→构建迭代器→构建训练循环
2.3 构建数据集
这次的数据集用的是Urban100数据集,当然使用其他数据集也没有太大的问题(不建议使用带有灰度图的数据集,会报错)


在这里使用的构造方法和我的上一篇博客相同 传送门
首先我们先把数据集预处理类构建好
import torchvision.transforms as transforms
import torch
from torch.utils.data import Dataset
import numpy as np
import os
from PIL import Image
#图像处理操作,包括随机裁剪,转换张量
transform = transforms.Compose([transforms.RandomCrop(96),
transforms.ToTensor()])
class PreprocessDataset(Dataset):
"""预处理数据集类"""
def __init__(self,imgPath = path,transforms = transform, ex = 10):
"""初始化预处理数据集类"""
self.transforms = transform
for _,_,files in os.walk(imgPath):
self.imgs = [imgPath + file for file in files] * ex
np.random.shuffle(self.imgs) #随机打乱
def __len__(self):
"""获取数据长度"""
return len(self.imgs)
def __getitem__(self,index):
"""获取数据"""
tempImg = self.imgs[index]
tempImg = Image.open(tempImg)
sourceImg = self.transforms(tempImg) #对原始图像进行处理
cropImg = torch.nn.MaxPool2d(4,stride=4)(sourceImg)
return cropImg,sourceImg
随后,我们只需要构造一个DataLoader就可以在后续训练中使用到我们的模型了
path = './Urban100/'
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
BATCH = 32
EPOCHS = 100
#构建数据集
processDataset = PreprocessDataset(imgPath = path)
trainData = DataLoader(processDataset,batch_size=BATCH)
#构造迭代器并取出其中一个样本
dataiter = iter(trainData)
testImgs,_ = dataiter.next()
testImgs = testImgs.to(device) #testImgs的用处是为了可视化生成对抗的结果
2.4 构建生成模型(Generator)
在文章中的生成模型即为SRResNet,下图为他的网络结构图
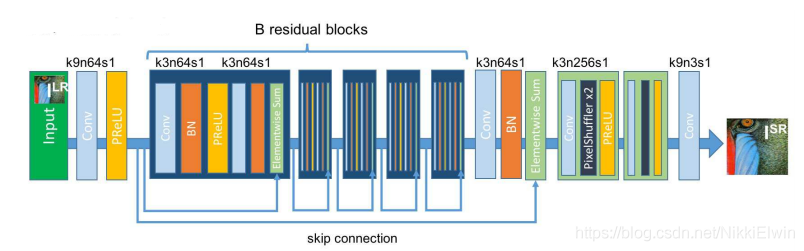
该模型是可以单独用于进行超分辨率训练的,详情请看 → \rightarrow → 传送门
模型的构造代码如下
import torch.nn as nn
import torch.nn.functional as F
class ResBlock(nn.Module):
"""残差模块"""
def __init__(self,inChannals,outChannals):
"""初始化残差模块"""
super(ResBlock,self).__init__()
self.conv1 = nn.Conv2d(inChannals,outChannals,kernel_size=1,bias=False)
self.bn1 = nn.BatchNorm2d(outChannals)
self.conv2 = nn.Conv2d(outChannals,outChannals,kernel_size=3,stride=1,padding=1,bias=False)
self.bn2 = nn.BatchNorm2d(outChannals)
self.conv3 = nn.Conv2d(outChannals,outChannals,kernel_size=1,bias=False)
self.relu = nn.PReLU()
def forward(self,x):
"""前向传播过程"""
resudial = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out += resudial
out = self.relu(out)
return out
class Generator(nn.Module):
"""生成模型(4x)"""
def __init__(self):
"""初始化模型配置"""
super(Generator,self).__init__()
#卷积模块1
self.conv1 = nn.Conv2d(3,64,kernel_size=9,padding=4,padding_mode='reflect',stride=1)
self.relu = nn.PReLU()
#残差模块
self.resBlock = self._makeLayer_(ResBlock,64,64,5)
#卷积模块2
self.conv2 = nn.Conv2d(64,64,kernel_size=1,stride=1)
self.bn2 = nn.BatchNorm2d(64)
self.relu2 = nn.PReLU()
#子像素卷积
self.convPos1 = nn.Conv2d(64,256,kernel_size=3,stride=1,padding=2,padding_mode='reflect')
self.pixelShuffler1 = nn.PixelShuffle(2)
self.reluPos1 = nn.PReLU()
self.convPos2 = nn.Conv2d(64,256,kernel_size=3,stride=1,padding=1,padding_mode='reflect')
self.pixelShuffler2 = nn.PixelShuffle(2)
self.reluPos2 = nn.PReLU()
self.finConv = nn.Conv2d(64,3,kernel_size=9,stride=1)
def _makeLayer_(self,block,inChannals,outChannals,blocks):
"""构建残差层"""
layers = []
layers.append(block(inChannals,outChannals))
for i in range(1,blocks):
layers.append(block(outChannals,outChannals))
return nn.Sequential(*layers)
def forward(self,x):
"""前向传播过程"""
x = self.conv1(x)
x = self.relu(x)
residual = x
out = self.resBlock(x)
out = self.conv2(out)
out = self.bn2(out)
out += residual
out = self.convPos1(out)
out = self.pixelShuffler1(out)
out = self.reluPos1(out)
out = self.convPos2(out)
out = self.pixelShuffler2(out)
out = self.reluPos2(out)
out = self.finConv(out)
return out
2.5 构建辨别模型(Discriminator)
辨别器采用了类似于VGG结构的模型,因此在实现上也没有很大难度

class ConvBlock(nn.Module):
"""残差模块"""
def __init__(self,inChannals,outChannals,stride = 1):
"""初始化残差模块"""
super(ConvBlock,self).__init__()
self.conv = nn.Conv2d(inChannals,outChannals,kernel_size=3,stride = stride,padding=1,padding_mode='reflect',bias=False)
self.bn = nn.BatchNorm2d(outChannals)
self.relu = nn.LeakyReLU()
def forward(self,x):
"""前向传播过程"""
out = self.conv(x)
out = self.bn(out)
out = self.relu(out)
return out
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator,self).__init__()
self.conv1 = nn.Conv2d(3,64,kernel_size=3,stride=1,padding=1,padding_mode='reflect')
self.relu1 = nn.LeakyReLU()
self.convBlock1 = ConvBlock(64,64,stride = 2)
self.convBlock2 = ConvBlock(64,128,stride = 1)
self.convBlock3 = ConvBlock(128,128,stride = 2)
self.convBlock4 = ConvBlock(128,256,stride = 1)
self.convBlock5 = ConvBlock(256,256,stride = 2)
self.convBlock6 = ConvBlock(256,512,stride = 1)
self.convBlock7 = ConvBlock(512,512,stride = 2)
self.avePool = nn.AdaptiveAvgPool2d(1)
self.conv2 = nn.Conv2d(512,1024,kernel_size=1)
self.relu2 = nn.LeakyReLU()
self.conv3 = nn.Conv2d(1024,1,kernel_size=1)
self.sigmoid = nn.Sigmoid()
def forward(self,x):
x = self.conv1(x)
x = self.relu1(x)
x = self.convBlock1(x)
x = self.convBlock2(x)
x = self.convBlock3(x)
x = self.convBlock4(x)
x = self.convBlock5(x)
x = self.convBlock6(x)
x = self.convBlock7(x)
x = self.avePool(x)
x = self.conv2(x)
x = self.relu2(x)
x = self.conv3(x)
x = self.sigmoid(x)
return x
(原谅我丑的一批的代码…)
2.6 初始化训练迭代器
在构建完数据集和两个网络之后,我们需要构造训练所需要的模型实例,损失函数,迭代器等。
这里迭代器使用的是Adam,两个网络的迭代器是互不相同的,为了保证网络之间对抗的稳定性,这里设置了两个模型的学习率相同。
SRGAN中使用了基于VGG提取的高级特征作为损失函数,因此需要使用到VGG预训练模型。
import torch.optim as optim
from torchvision.models.vgg import vgg16
#构造模型
netD = Discriminator()
netG = Generator()
netD.to(device)
netG.to(device)
#构造迭代器
optimizerG = optim.Adam(netG.parameters())
optimizerD = optim.Adam(netD.parameters())
#构造损失函数
lossF = nn.MSELoss().to(device)
#构造VGG损失中的网络模型
vgg = vgg16(pretrained=True).to(device)
lossNetwork = nn.Sequential(*list(vgg.features)[:31]).eval()
for param in lossNetwork.parameters():
param.requires_grad = False #让VGG停止学习
2.7 构造训练循环
训练的循环如下
from tqdm import tqdm
import torchvision.utils as vutils
import matplotlib.pyplot as plt
for epoch in range(EPOCHS):
netD.train()
netG.train()
processBar = tqdm(enumerate(trainData,1))
for i,(cropImg,sourceImg) in processBar:
cropImg,sourceImg = cropImg.to(device),sourceImg.to(device)
fakeImg = netG(cropImg).to(device)
#迭代辨别器网络
netD.zero_grad()
realOut = netD(sourceImg).mean()
fakeOut = netD(fakeImg).mean()
dLoss = 1 - realOut + fakeOut
dLoss.backward(retain_graph=True)
optimizerD.step()
#迭代生成器网络
netG.zero_grad()
gLossSR = lossF(fakeImg,sourceImg)
gLossGAN = 0.001 * torch.mean(1 - fakeOut)
gLossVGG = 0.006 * lossF(lossNetwork(fakeImg),lossNetwork(sourceImg))
gLoss = gLossSR + gLossGAN + gLossVGG
gLoss.backward()
optimizerG.step()
#数据可视化
processBar.set_description(desc='[%d/%d] Loss_D: %.4f Loss_G: %.4f D(x): %.4f D(G(z)): %.4f' % (
epoch, EPOCHS, dLoss.item(),gLoss.item(),realOut.item(),fakeOut.item()))
#将文件输出到目录中
with torch.no_grad():
fig = plt.figure(figsize=(10,10))
plt.axis("off")
fakeImgs = netG(testImgs).detach().cpu()
plt.imshow(np.transpose(vutils.make_grid(fakeImgs,padding=2,normalize=True),(1,2,0)), animated=True)
plt.savefig('./Img/Result_epoch % 05d.jpg' % epoch, bbox_inches='tight', pad_inches = 0)
print('[INFO] Image saved successfully!')
#保存模型路径文件
torch.save(netG.state_dict(), 'model/netG_epoch_%d_%d.pth' % (4, epoch))
torch.save(netD.state_dict(), 'model/netD_epoch_%d_%d.pth' % (4, epoch))
[0/100] Loss_D: 1.0737 Loss_G: 0.0360 D(x): 0.1035 D(G(z)): 0.1772: : 33it [00:32, 1.02it/s]
0it [00:00, ?it/s]
[INFO] Image saved successfully!
[1/100] Loss_D: 0.8497 Loss_G: 0.0216 D(x): 0.6464 D(G(z)): 0.4960: : 33it [00:31, 1.04it/s]
0it [00:00, ?it/s]
[INFO] Image saved successfully!
[2/100] Loss_D: 0.9925 Loss_G: 0.0235 D(x): 0.5062 D(G(z)): 0.4987: : 33it [00:31, 1.05it/s]
0it [00:00, ?it/s]
[INFO] Image saved successfully!
[3/100] Loss_D: 0.9907 Loss_G: 0.0277 D(x): 0.4948 D(G(z)): 0.4856: : 33it [00:31, 1.06it/s]
0it [00:00, ?it/s]
[INFO] Image saved successfully!
[4/100] Loss_D: 0.9936 Loss_G: 0.0180 D(x): 0.0127 D(G(z)): 0.0062: : 33it [00:31, 1.06it/s]
0it [00:00, ?it/s]
[INFO] Image saved successfully!
[5/100] Loss_D: 1.0636 Loss_G: 0.0300 D(x): 0.2553 D(G(z)): 0.3188: : 33it [00:31, 1.06it/s]
0it [00:00, ?it/s]
[INFO] Image saved successfully!
[6/100] Loss_D: 1.0000 Loss_G: 0.0132 D(x): 0.1667 D(G(z)): 0.1667: : 33it [00:31, 1.06it/s]
0it [00:00, ?it/s]
[INFO] Image saved successfully!
[7/100] Loss_D: 1.1650 Loss_G: 0.0227 D(x): 0.1683 D(G(z)): 0.3333: : 33it [00:31, 1.06it/s]
0it [00:00, ?it/s]
[INFO] Image saved successfully!
[8/100] Loss_D: 1.0000 Loss_G: 0.0262 D(x): 0.1667 D(G(z)): 0.1667: : 33it [00:31, 1.05it/s]
0it [00:00, ?it/s]
[INFO] Image saved successfully!
···
[56/100] Loss_D: 1.0000 Loss_G: 0.0119 D(x): 1.0000 D(G(z)): 1.0000: : 33it [00:32, 1.01it/s]
0it [00:00, ?it/s]
[INFO] Image saved successfully!
[57/100] Loss_D: 1.0000 Loss_G: 0.0084 D(x): 1.0000 D(G(z)): 1.0000: : 33it [00:32, 1.03it/s]
0it [00:00, ?it/s]
[INFO] Image saved successfully!
[58/100] Loss_D: 1.0000 Loss_G: 0.0065 D(x): 1.0000 D(G(z)): 1.0000: : 33it [00:32, 1.03it/s]
0it [00:00, ?it/s]
[INFO] Image saved successfully!
在Img文件夹中保存了每次训练的可视化结果,在训练中,第一轮的结果如下所示:

而在第58轮中的结果为:

3 结果可视化
接下来将构造结果可视化的代码。
该代码的头文件为
import torch.nn as nn
import torch.nn.functional as F
import torch
from PIL import Image
import torchvision.transforms as transforms
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import matplotlib.pyplot as plt
首先我们需要引入生成模型
class ResBlock(nn.Module):
"""残差模块"""
def __init__(self,inChannals,outChannals):
"""初始化残差模块"""
super(ResBlock,self).__init__()
self.conv1 = nn.Conv2d(inChannals,outChannals,kernel_size=1,bias=False)
self.bn1 = nn.BatchNorm2d(outChannals)
self.conv2 = nn.Conv2d(outChannals,outChannals,kernel_size=3,stride=1,padding=1,bias=False)
self.bn2 = nn.BatchNorm2d(outChannals)
self.conv3 = nn.Conv2d(outChannals,outChannals,kernel_size=1,bias=False)
self.relu = nn.PReLU()
def forward(self,x):
"""前向传播过程"""
resudial = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(x)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(x)
out += resudial
out = self.relu(out)
return out
class Generator(nn.Module):
"""生成模型(4x)"""
def __init__(self):
"""初始化模型配置"""
super(Generator,self).__init__()
#卷积模块1
self.conv1 = nn.Conv2d(3,64,kernel_size=9,padding=4,padding_mode='reflect',stride=1)
self.relu = nn.PReLU()
#残差模块
self.resBlock = self._makeLayer_(ResBlock,64,64,5)
#卷积模块2
self.conv2 = nn.Conv2d(64,64,kernel_size=1,stride=1)
self.bn2 = nn.BatchNorm2d(64)
self.relu2 = nn.PReLU()
#子像素卷积
self.convPos1 = nn.Conv2d(64,256,kernel_size=3,stride=1,padding=2,padding_mode='reflect')
self.pixelShuffler1 = nn.PixelShuffle(2)
self.reluPos1 = nn.PReLU()
self.convPos2 = nn.Conv2d(64,256,kernel_size=3,stride=1,padding=1,padding_mode='reflect')
self.pixelShuffler2 = nn.PixelShuffle(2)
self.reluPos2 = nn.PReLU()
self.finConv = nn.Conv2d(64,3,kernel_size=9,stride=1)
def _makeLayer_(self,block,inChannals,outChannals,blocks):
"""构建残差层"""
layers = []
layers.append(block(inChannals,outChannals))
for i in range(1,blocks):
layers.append(block(outChannals,outChannals))
return nn.Sequential(*layers)
def forward(self,x):
"""前向传播过程"""
x = self.conv1(x)
x = self.relu(x)
residual = x
out = self.resBlock(x)
out = self.conv2(out)
out = self.bn2(out)
out += residual
out = self.convPos1(out)
out = self.pixelShuffler1(out)
out = self.reluPos1(out)
out = self.convPos2(out)
out = self.pixelShuffler2(out)
out = self.reluPos2(out)
out = self.finConv(out)
return out
随后,我们初始化并构建可视化函数
device = torch.device("cpu")
net = Generator()
net.load_state_dict(torch.load("你的模型pth文件路径"))
def imshow(path,sourceImg = True):
"""展示结果"""
preTransform = transforms.Compose([transforms.ToTensor()])
pilImg = Image.open(path)
img = preTransform(pilImg).unsqueeze(0).to(device)
source = net(img)[0,:,:,:]
source = source.cpu().detach().numpy() #转为numpy
source = source.transpose((1,2,0)) #切换形状
source = np.clip(source,0,1) #修正图片
if sourceImg:
temp = np.clip(img[0,:,:,:].cpu().detach().numpy().transpose((1,2,0)),0,1)
shape = temp.shape
source[-shape[0]:,:shape[1],:] = temp
plt.imshow(source)
img = Image.fromarray(np.uint8(source*255))
img.save('./result/' + path.split('/')[-1][:-4] + '_result_with_source.jpg') # 将数组保存为图片
return
plt.imshow(source)
img = Image.fromarray(np.uint8(source*255))
img.save(path[:-4] + '_result.jpg') # 将数组保存为图片
最后,只需要简单调用就好
imshow("你的图片路径",sourceImg = True)
以本次训练模型为例,拿一张从未见过的图片作为测试

能够看出细节问题还是很多的,因此可以考虑一下增加模型的训练时间,或者是修改一下模型的结构。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/209962.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
