大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
Mechanize模块介绍
Scrapy和BeautifulSoup获取的页面大多数都是静态页面,即不需要用户登录即可获取数据,然而许多网站是需要用户登录操作的,诚然,Scrapy和BeautifulSoup可以完成用户登录等操作,但相对的工作量会大了很多,这里我们可以使用Mechanize模块,Mechanize是python的一个模块,用于模仿浏览器操作,包括操作账号密码登录等
安装Mechanize包
Windows安装Mechanize
pip install mechanize
Ubuntu下安装Mechanize
pip install mechanize
Mechanize的使用
这里我们直接用案例来学习使用Mechanize
Mechanize抓取音悦台公告
目标分析
我们要获取http://www.yinyuetai.com/的用户公告
这里如果模拟登陆操作,会涉及到大量验证操作,操作难度大大增大,我们这里采用Cookie直接获取目标页面数据.
获取cookie
使用Chrome或者FireFox登录网站,截图第一次请求的request headers.
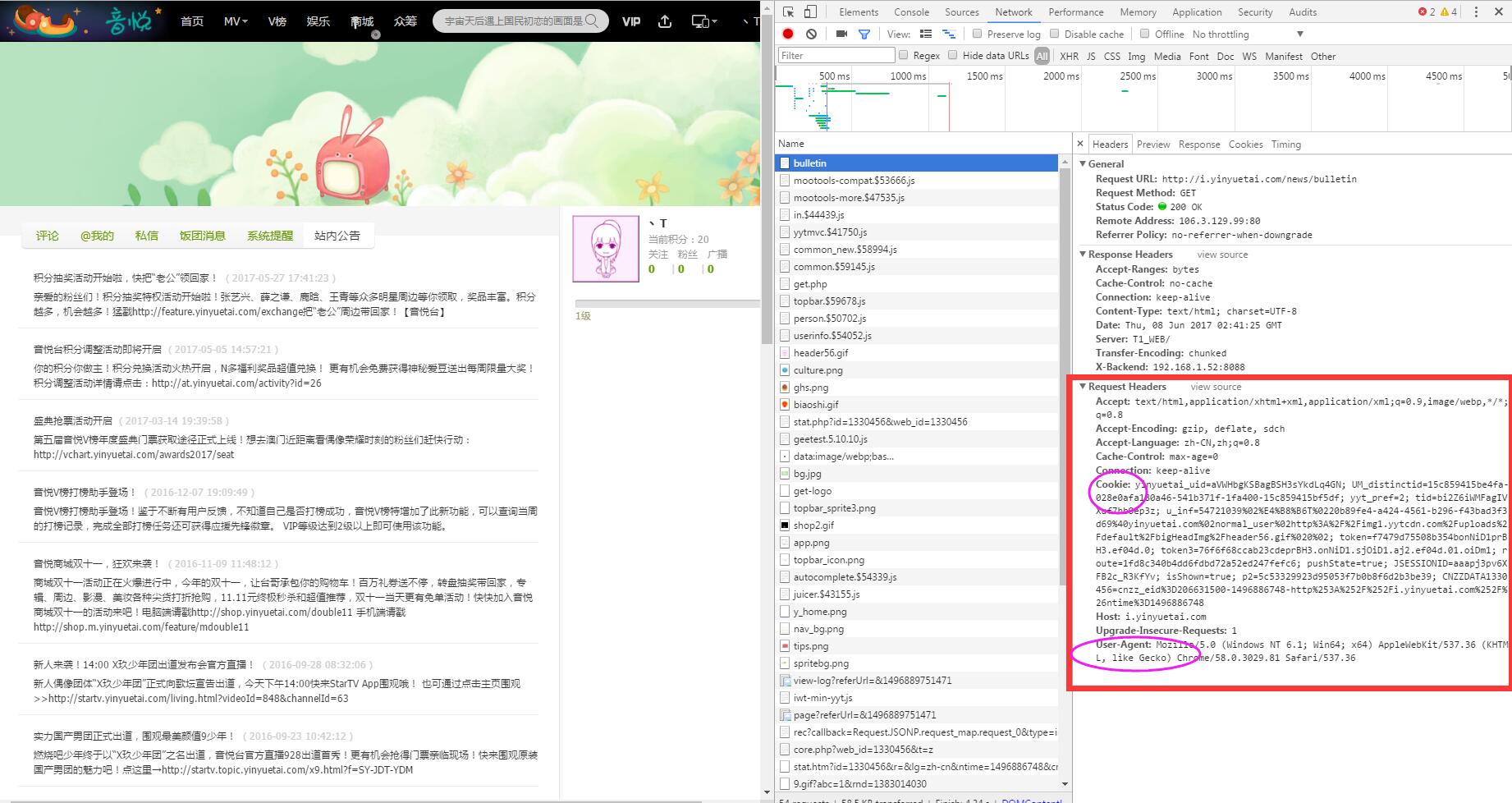
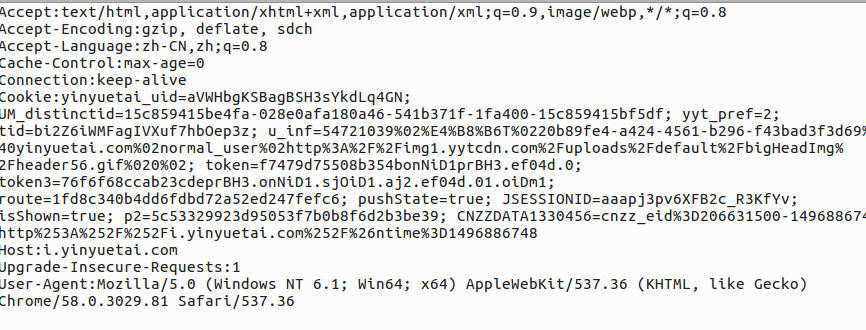
其中的cookie和request是我们需要的内容.
工程实现
- 编写log类,记录操作过程
- 编写getHeadersFromFile,用于从headersRaw.txt文件中获取Cookie和User-Agent
- 编写getYinyuetaiBulletin类
mylog类
# -*- coding:utf-8 -*-
''' Created on 2017年6月5日 @author: root '''
import logging
import getpass
import sys
#### 定义MyLog类
class MyLog(object):
#### 类MyLog的构造函数
def __init__(self):
self.user = getpass.getuser() #获取当前登录名
self.logger = logging.getLogger(self.user)
self.logger.setLevel(logging.DEBUG)
#### 日志文件名
self.logFile = sys.argv[0][0:-3] + '.log' #sys.argv[0]表示代码文件本身的路径 [0:-3]即获取除了末尾三个字符.py的文件名
#log格式 当前时间-日志级别-Logger名称-用户输出信息
self.formatter = logging.Formatter('%(asctime)-12s %(levelname)-8s %(name)-10s %(message)-12s\r\n')
#### 日志显示到屏幕上并输出到日志文件内
self.logHand = logging.FileHandler(self.logFile, encoding='utf8') #创建日志文件流
self.logHand.setFormatter(self.formatter) #输出文件格式
self.logHand.setLevel(logging.DEBUG) #log等级
self.logHandSt = logging.StreamHandler() #创建输出到sys.stdout流,stdout在Eclipse里就是Console
self.logHandSt.setFormatter(self.formatter) #输出流格式
self.logHandSt.setLevel(logging.DEBUG)
self.logger.addHandler(self.logHand) #添加文件输出流
self.logger.addHandler(self.logHandSt) #添加stdout输出流
#### 日志的5个级别对应以下的5个函数
def debug(self,msg):
self.logger.debug(msg)
def info(self,msg):
self.logger.info(msg)
def warn(self,msg):
self.logger.warn(msg)
def error(self,msg):
self.logger.error(msg)
def critical(self,msg):
self.logger.critical(msg)
if __name__ == '__main__':
mylog = MyLog()
mylog.debug(u"I'm debug 测试中文")
mylog.info("I'm info")
mylog.warn("I'm warn")
mylog.error(u"I'm error 测试中文")
mylog.critical("I'm critical")getHeadersFromFile类
#-*- coding: utf-8 -*-
''' Created on 2017年6月8日 @author: root '''
def getHeaders(fileName):
headers = []
headerList = ['User-Agent', 'Cookie']
with open(fileName, 'r') as fp:
for line in fp.readlines():
name, value = line.split(':', 1)
if name in headerList:
headers.append((name.strip(), value.strip()))
return headers
if __name__ == '__main__':
headers = getHeaders('headersRaw.txt')
print headersgetYinyuetaiBulletin类
#-*- coding: utf-8 -*-
''' Created on 2017年6月8日 @author: root '''
import codecs
import mechanize
from bs4 import BeautifulSoup
from mylog import MyLog as mylog
from getHeadersFromFIle import *
class Item(object):
title = None
content = None
class GetBulletin(object):
def __init__(self):
self.url = 'http://i.yinyuetai.com/news/bulletin'
self.log = mylog()
self.headersFile = 'headersRaw.txt'
self.outFile = 'bulletin.txt'
self.spider()
def getResponseContent(self, url):
self.log.info('begin use mechanize module get response')
br = mechanize.Browser()
br.set_handle_equiv(True)
br.set_handle_redirect(True)
br.set_handle_referer(True)
br.set_handle_robots(False)
br.set_handle_refresh(mechanize._http.HTTPRefreshProcessor(), max_time=1)
headers = getHeaders(self.headersFile)
br.addheaders = headers
br.open(url)
return br.response().read()
def spider(self):
self.log.info('beging run spider module')
items = []
responseContent = self.getResponseContent(self.url)
soup = BeautifulSoup(responseContent, 'lxml')
tags = soup.find_all('div', attrs={
'class':'item_info'})
for tag in tags:
item = Item()
item.title = tag.find('p', attrs={
'class':'title'}).get_text().strip()
item.content = tag.find('p', attrs={
'class':'content'}).get_text().strip()
items.append(item)
self.pipelines(items)
def pipelines(self, items):
self.log.info('begin run pipeline function')
with codecs.open(self.outFile, 'w', 'utf8') as fp:
for item in items:
fp.write(item.title + '\r\n')
self.log.info(item.title)
fp.write(item.content + '\r\n')
self.log.info(item.content)
fp.write('\r\n'*8)
if __name__ == '__main__':
GB = GetBulletin()运行结果
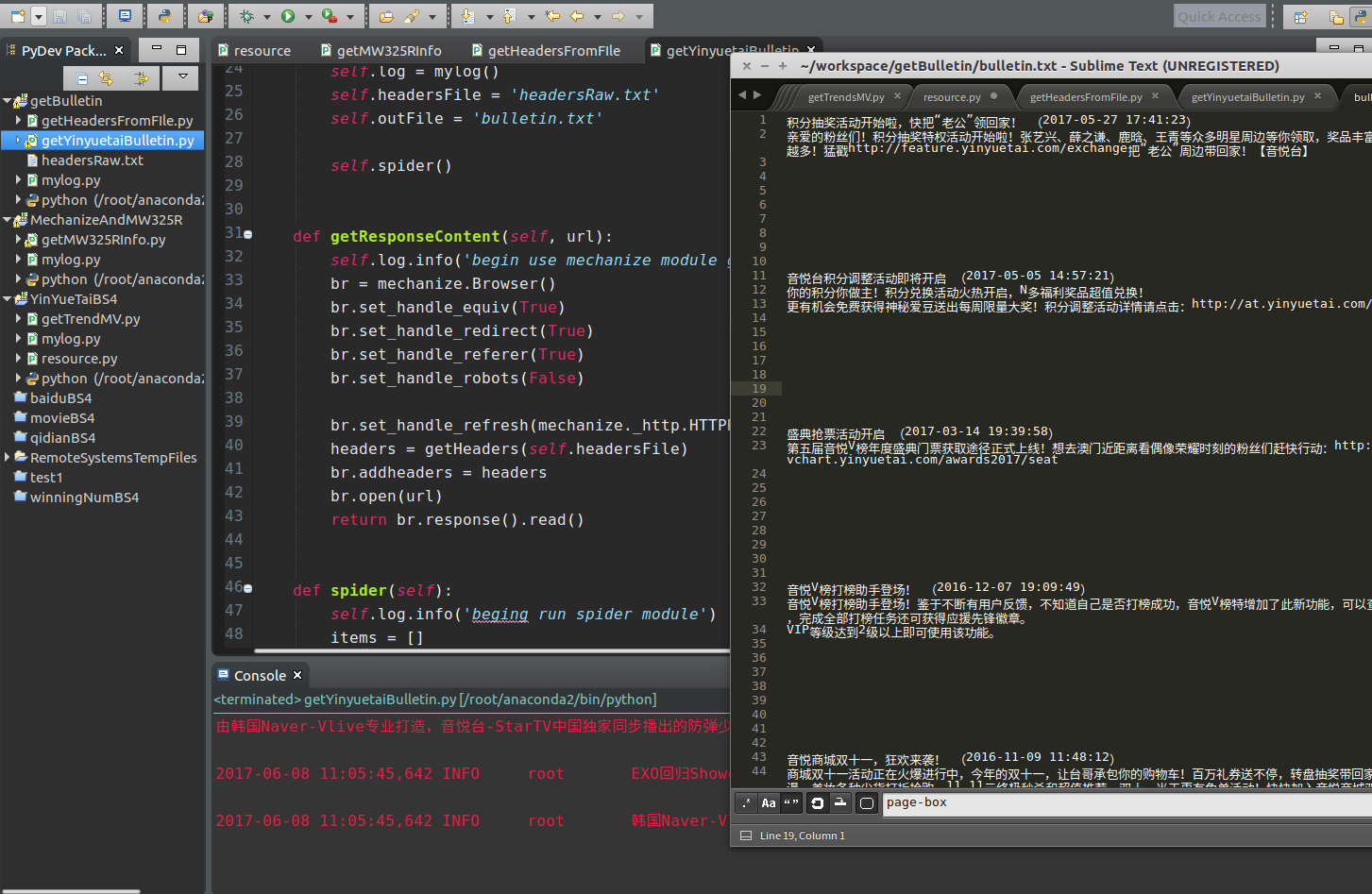
成功~
Selenium模块介绍
许多网站的数据是通过JavaScript程序获取的,Python对JavaScript的支持不是太好,想用Python获取网站中JavaScript返回的数据,也能是模拟浏览器了。Mechanize不支持JavaScript,我们可以选用一款支持JavaScript的模块-Selenium.
Selenium是一套完整的Web应用程序测试系统,包含了测试的录制(Selenium IDE),编写和运行(Selenium Remote Control)和测试的并行处理(Selenium Gird).符合我们Python爬虫程序的需求.
安装Selenium包
Windows安装Selenium
pip install selenium
Ubuntu下安装Selenium
pip install Selenium

Selenium使用
浏览器的支持
编写爬虫时,我们主要用的是使用Selenium的Webdriver工具包,Webdriver工具包支持主流的浏览器.使用help命令查看支持浏览器的列表
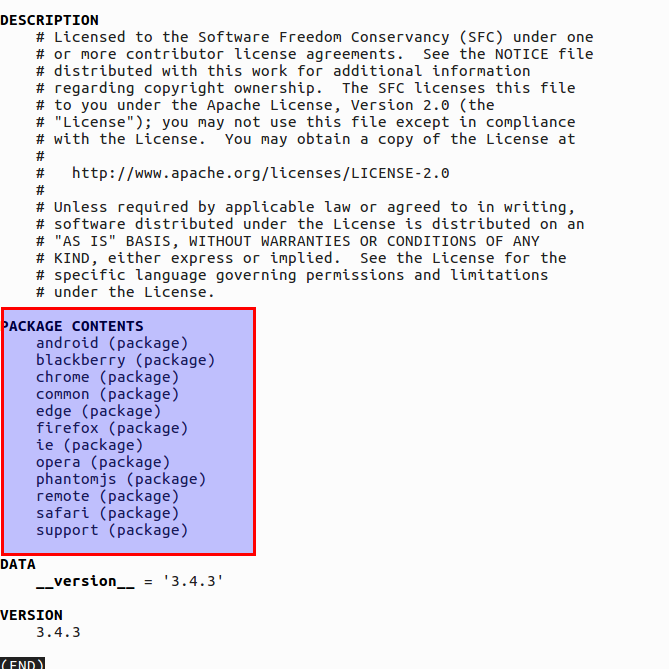
选择合适的浏览器
参考Webdriver的支持列表:
- 移动端: android/blackberry
- 常见浏览器:chrome/edge/firefox/Opera/Safari/ie
- 不常见的:common/phantomjs/remote/support
PhantomJS是一个基于WebKit的服务端JavaScript API.全面支持Web,因为是无界面,开销小,比较适合用于爬虫程序.
PhantomJS
Windows下安装PhantomJS
找到PhantomJS的官网 http://phantomjs.org/ 点击download
选择对于的Windows版本
这里强烈建议使用迅雷下载,浏览器下载速度太慢了
下载完成后,解压 ,将phantomjs.exe拷贝到python的安装目录下
测试是否可用
导入成功,可用~
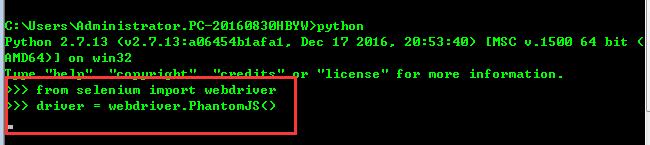
Linux下安装PhantomJS
同样的,Linux的安装包也使用迅雷下载,传到Linux上
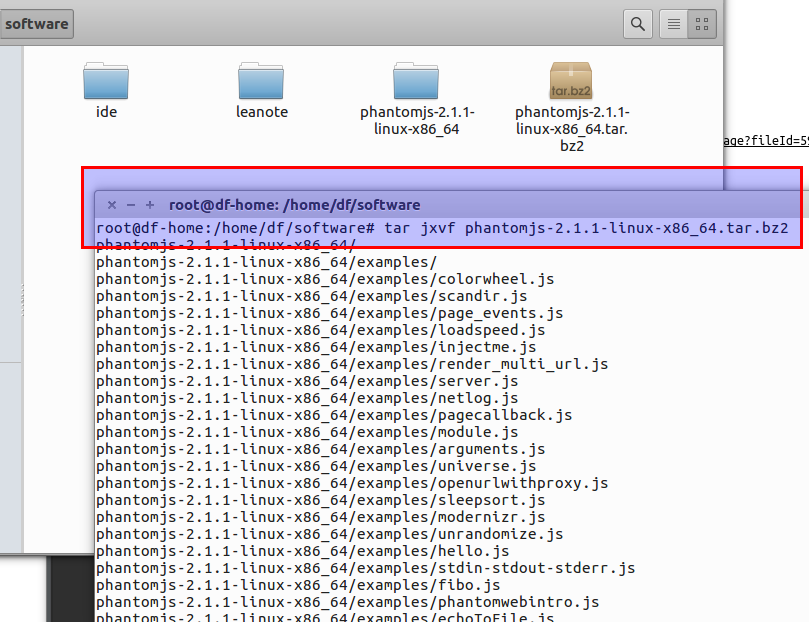
到文档目录下,使用指令解压
tar jxvf phantomjs-2.1.1-linux-x86_64.tar.bz2
将文件夹拷贝到/usr/local/bin目录
cp phantomjs-2.1.1-linux-x86_64/bin/phantomjs /usr/local/bin/

测试是否可用
导入成功,可用~
Selenium&PhantomJS抓取数据
Selenium本身有一套自己的定位过滤函数,可以不用BS4
Selenium模块的基本用法
要了解一个模块,可以使用官方的help函数,在命令行,help函数输出不利于查看,想法子将help的输出存储到一个txt文档内.
使用程序将help函数保存到一个txt文件:
import sys
from selenium import webdriver
browser = webdriver.PhantomJS()
out = sys.stdout
sys.stdout = open('browserHelp.txt','w')
help(browser)
sys.stdout.close()
sys.stdout = out
browser.quit()
模拟浏览器编写爬虫程序,获取感兴趣的数据,需要如下三个步骤:
- 先获取到网站的数据
- 定位到感兴趣的数据
- 获取到有效数据
获取到网站的数据
以www.baidu.com为例,有两种方法会可以获取搜索页面结果
1,用浏览器搜索,将搜索结果用Selenium&PhantomJS打开
2,直接用Selenium&PhantomJS打开百度主页我们采取第二种方法,使用
from selenium import webdriver
browser = webdriver.PhantomJS()
browser.get('https://www.baidu.com')
browser.implicitly_wait(10)这里的 implicitly_wait(10)设定了JavaScript需要多长时间,这个时间设定是智能的。
从获取的网页数据定位到输入框和搜索命令
Selenium提供了多个函数用于定位有效数据:
browser.find_element(self,by='id',value=None)
browser.find_element_by_id(self,id_)
browser.find_element_by_name(self,name)
browser.find_element_by_class_name(self,name)
browser.find_element_by_tag_name(self,name)
browser.find_element_by_xpath(self,xpath)
browser.find_element_by_css_selector(self,css_selector)
browser.find_element_by_link_text(self,link_text)
browser.find_element_by_partial_link_text(self,link_text)
#还有是
browser.find_elements(self,by='id',value=None)
browser.find_elements_by_id(self,id_)
browser.find_elements_by_name(self,name)
browser.find_elements_by_class_name(self,name)
browser.find_elements_by_tag_name(self,name)
browser.find_elements_by_xpath(self,xpath)
browser.find_elements_by_css_selector(self,css_selector)
browser.find_elements_by_link_text(self,link_text)
browser.find_elements_by_partial_link_text(self,link_text)其中find_element不带s的是返回第一个符合条件的element,而find_elements是返回一个列表.
使用chrome查看网页的源代码

使用搜索工具搜索type=text,找到搜索输入框的代码如下
<input type=text class=s_ipt name=wd id=kw maxlength=100 autocomplete=off>找到提交按钮
<input type=submit value="百度一下" id=su class="btn self-btn bg s_btn">编写搜索代码
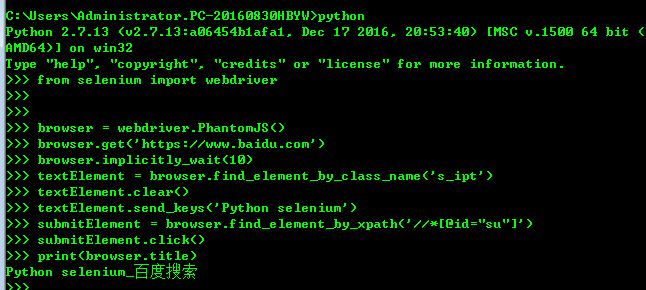
#-*- coding: utf-8 -*-
from selenium import webdriver
browser = webdriver.PhantomJS()
browser.get('https://www.baidu.com')
browser.implicitly_wait(10)
#三选1
textElement = browser.find_element_by_class_name('s_ipt')
# textElement = browser.find_element_by_id('kw')
# textElement = browser.find_element_by_name('wd')
textElement.clear()
textElement.send_keys('Python selenium')
#三选一
submitElement = browser.find_element_by_xpath('//*[@id="su"]')
#submitElement = browser.find_element_by_class_name('btn self-btn bg s_btn')
#submitElement = browser.find_element_by_id('su')
submitElement.click()
print(browser.title)
获取百度搜索结果
先使用chrome查看搜索后的结果
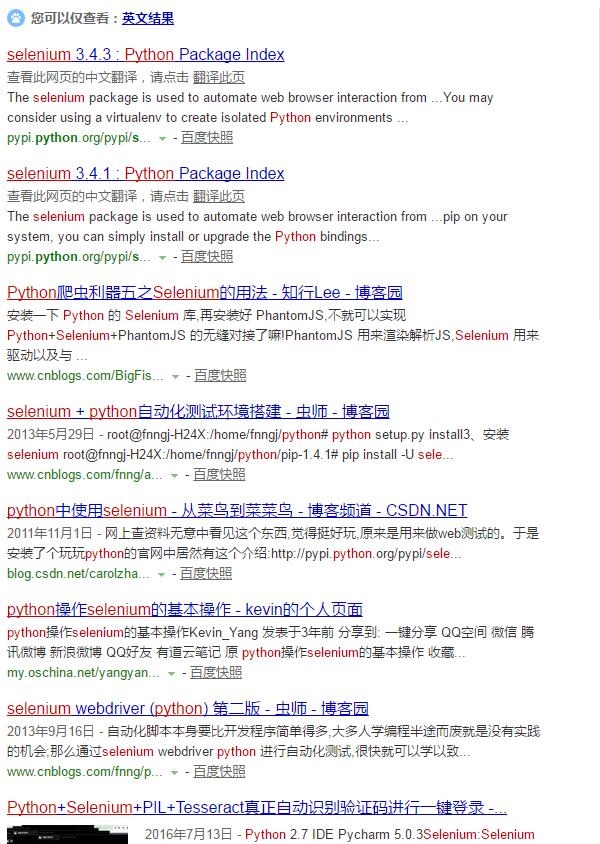
查看网页源代码,定位到标题和网页链接地址
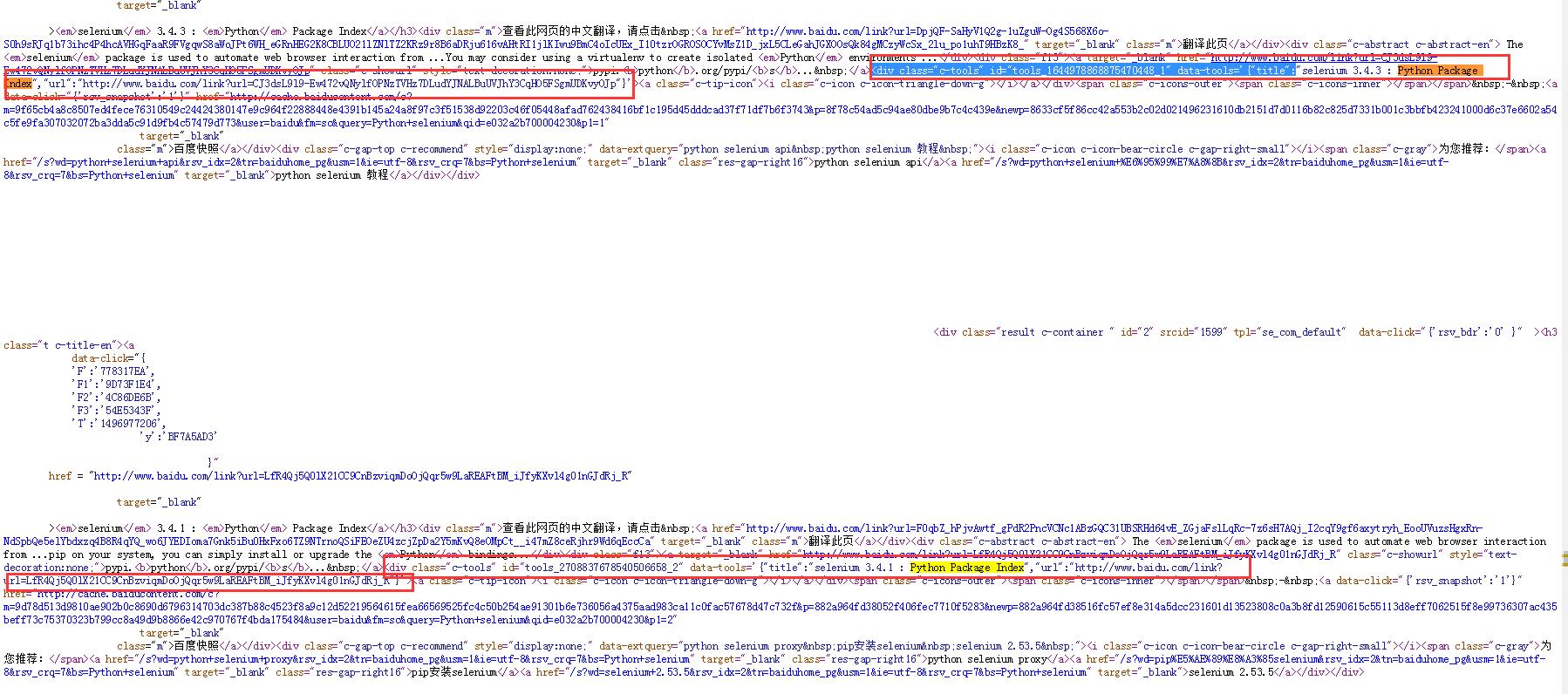
可以看到第一条搜索信息如下
<div class="c-tools" id="tools_1644978868875470448_1" data-tools='{"title":"selenium 3.4.3 : Python Package Index","url":"http://www.baidu.com/link?url=CJ3dsL9l9-Ew472vQNylfOPNzTVHz7DLudYJNALBuUVJhY3CqHO5FSgmUDKvyOJp"}'>第二条搜索信息如下
<div class="c-tools" id="tools_2708837678540506658_2" data-tools='{"title":"selenium 3.4.1 : Python Package Index","url":"http://www.baidu.com/link?url=LfR4Qj5Q0lX21CC9CnBzviqmDoOjQqr5w9LaREAFtBM_iJfyKXvl4g01nGJdRj_R"}'>经检验每条搜索信息都包含class=”c-tools”这条属性,据此可以编写搜索代码:
resultElements = browser.find_elements_by_class_name('c-tools')使用命令len(resultElements)

Selunium提供了获取数据的常用方法
element.text #获取文本
element.get_attribute(name)#获取属性遍历上述resultElements,可得到标题和地址:
for result in resultElements:
value=result.get_attribute('data-tools')
valueDic = eval(value)
print(valueDic.get('title').decode('utf8'))
print(valueDic.get('url'))以上就是Selenium&PhantomJS的示例~
Selenium&PhantomJS实战-获取代理
任务目标
从http://www.kuaidaili.com/ 获取代理IP信息
创建工程
在Linux系统下
mkdir /selenium/seleniumProject
touch getProxyFromKuaidaili.py
cd /selenium/seleniumProject
cp /mylog.py ./工程实现
编写log类,记录操作过程
编写getProxyFromKuaidaili.py,实现数据爬取
mylog类
# -*- coding:utf-8 -*-
''' Created on 2017年6月5日 @author: root '''
import logging
import getpass
import sys
#### 定义MyLog类
class MyLog(object):
#### 类MyLog的构造函数
def __init__(self):
self.user = getpass.getuser() #获取当前登录名
self.logger = logging.getLogger(self.user)
self.logger.setLevel(logging.DEBUG)
#### 日志文件名
self.logFile = sys.argv[0][0:-3] + '.log' #sys.argv[0]表示代码文件本身的路径 [0:-3]即获取除了末尾三个字符.py的文件名
#log格式 当前时间-日志级别-Logger名称-用户输出信息
self.formatter = logging.Formatter('%(asctime)-12s %(levelname)-8s %(name)-10s %(message)-12s\r\n')
#### 日志显示到屏幕上并输出到日志文件内
self.logHand = logging.FileHandler(self.logFile, encoding='utf8') #创建日志文件流
self.logHand.setFormatter(self.formatter) #输出文件格式
self.logHand.setLevel(logging.DEBUG) #log等级
self.logHandSt = logging.StreamHandler() #创建输出到sys.stdout流,stdout在Eclipse里就是Console
self.logHandSt.setFormatter(self.formatter) #输出流格式
self.logHandSt.setLevel(logging.DEBUG)
self.logger.addHandler(self.logHand) #添加文件输出流
self.logger.addHandler(self.logHandSt) #添加stdout输出流
#### 日志的5个级别对应以下的5个函数
def debug(self,msg):
self.logger.debug(msg)
def info(self,msg):
self.logger.info(msg)
def warn(self,msg):
self.logger.warn(msg)
def error(self,msg):
self.logger.error(msg)
def critical(self,msg):
self.logger.critical(msg)
if __name__ == '__main__':
mylog = MyLog()
mylog.debug(u"I'm debug 测试中文")
mylog.info("I'm info")
mylog.warn("I'm warn")
mylog.error(u"I'm error 测试中文")
mylog.critical("I'm critical")getProxyFromKuaidaili类
#-*- coding: utf-8 -*-
from selenium import webdriver
from mylog import MyLog as mylog
class Item(object):
ip = None
port = None
anonymous = None
type = None
support = None
local = None
speed = None
class GetProxy(object):
def __init__(self):
self.startUrl = 'http://www.kuaidaili.com/proxylist/'
self.log = mylog()
self.urls = self.getUrls()
self.proxyList = self.getProxyList(self.urls)
self.fileName = 'proxy.txt'
self.saveFile(self.fileName, self.proxyList)
def getUrls(self):
urls = []
for i in xrange(1,11):
url = self.startUrl + str(i)
urls.append(url)
self.log.info('get url %s to urls' %url)
return urls
def getProxyList(self, urls):
browser = webdriver.PhantomJS()
proxyList = []
item = Item()
for url in urls:
browser.get(url)
browser.implicitly_wait(5)
elements = browser.find_elements_by_xpath('//tbody/tr')
for element in elements:
item.ip = element.find_element_by_xpath('./td[1]').text.encode('utf8')
item.port = element.find_element_by_xpath('./td[2]').text.encode('utf8')
item.anonymous = element.find_element_by_xpath('./td[3]').text.encode('utf8')
item.type = element.find_element_by_xpath('./td[4]').text.encode('utf8')
item.support = element.find_element_by_xpath('./td[5]').text.encode('utf8')
item.local = element.find_element_by_xpath('./td[6]').text.encode('utf8')
item.speed = element.find_element_by_xpath('./td[7]').text.encode('utf8')
proxyList.append(item)
self.log.info('add proxy %s:%s to list' %(item.ip, item.port))
browser.quit()
return proxyList
def saveFile(self, fileName, proxyList):
self.log.info('add all proxy to %s' %fileName)
with open(fileName, 'w') as fp:
for item in proxyList:
fp.write(item.ip + '\t')
fp.write(item.port + '\t')
fp.write(item.anonymous + '\t')
fp.write(item.type + '\t')
fp.write(item.support + '\t')
fp.write(item.local + '\t')
fp.write(item.speed + '\n')
if __name__ == '__main__':
GP = GetProxy()运行结果
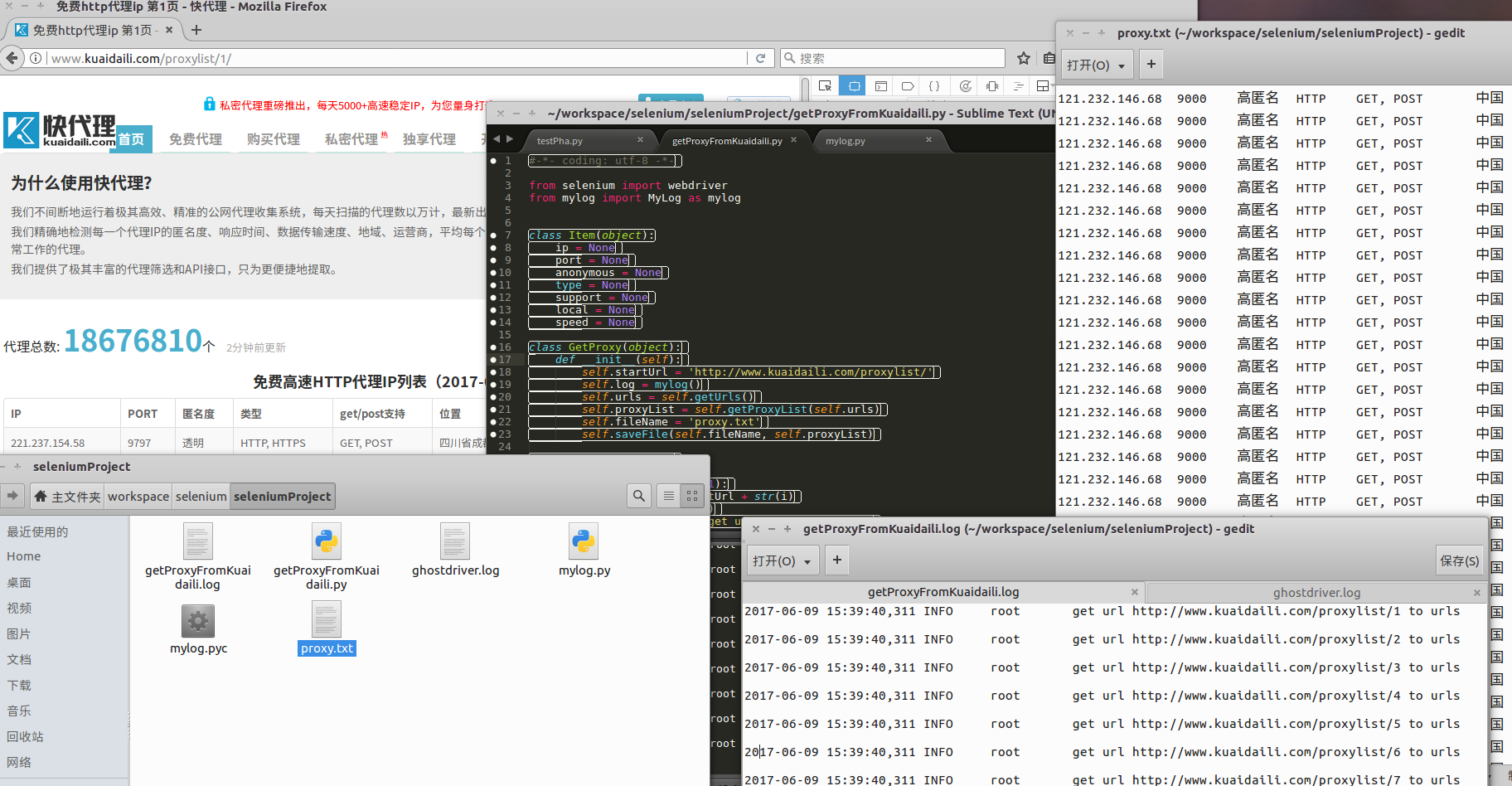
生成
- getProxyFromKuaidaili.log 日志文件
- ghostdriver.log PhantomJS日志文件
- proxy.txt 代理存储文件
Selenium&PhantomJS实战-爬取漫画
Selenium&PhantomJS方案主要是爬取JavaScript数据,一般JavaScript数据一是为了美观,二是为了保护数据。
本次目标
获取http://www.1kkk.com/的漫画
获取数据思路
网页中在最后一页后还是有下一页按钮,不能通过这么来判断总页数,使用Selenium&PhantomJS解释JavaScript,网站在防盗链上做的很到位,只要在页面上执行一次刷新操作,网站就判断为盗链,显示出防盗链的图片,并且得到的图片地址也无法下载,这里最简单的方法就是对整个页面截图。Selenium本身带有截图工具。
创建工程
在eclipse下创建getCartoon工程.
编写log类,记录操作过程
编写cartoon.py
工程实现
mylog类(同上)
编写cartoon.py
#-*- coding: utf-8 -*-
''' Created on 2017年6月9日 @author: root '''
import os
import time
from selenium import webdriver
from mylog import MyLog as mylog
class GetCartoon(object):
def __init__(self):
self.startUrl = u'http://www.1kkk.com/ch1-430180/'
self.log = mylog()
self.browser = self.getBrowser()
self.saveCartoon(self.browser)
self.browser.quit()
def getBrowser(self):
browser = webdriver.PhantomJS()
try:
browser.get(self.startUrl)
except:
mylog.error('open the %s failed' %self.startUrl)
browser.implicitly_wait(20)
return browser
def saveCartoon(self, browser):
cartoonTitle = browser.title.split('_')[0]
self.createDir(cartoonTitle)
os.chdir(cartoonTitle)
sumPage = int(self.browser.find_element_by_xpath('//font[@class="zf40"]/span[2]').text)
i = 1
while i<=sumPage:
imgName = str(i) + '.png'
browser.get_screenshot_as_file(imgName) #对后面的JavaScript内容直接截图
self.log.info('save img %s' %imgName)
i += 1
NextTag = browser.find_element_by_id('next')
NextTag.click()
# browser.implicitly_wait(20)
time.sleep(5) #使用sleep保证刷新时间,因为implicitly_wait(20)对NextTag.click()不起作用_
self.log.info('save img sccess')
def createDir(self, dirName):
if os.path.exists(dirName):
self.log.error('create directory %s failed, hava a same name file or directory' %dirName)
else:
try:
os.makedirs(dirName)
except:
self.log.error('create directory %s failed' %dirName)
else:
self.log.info('create directory %s success' %dirName)
if __name__ == '__main__':
GC = GetCartoon()运行结果
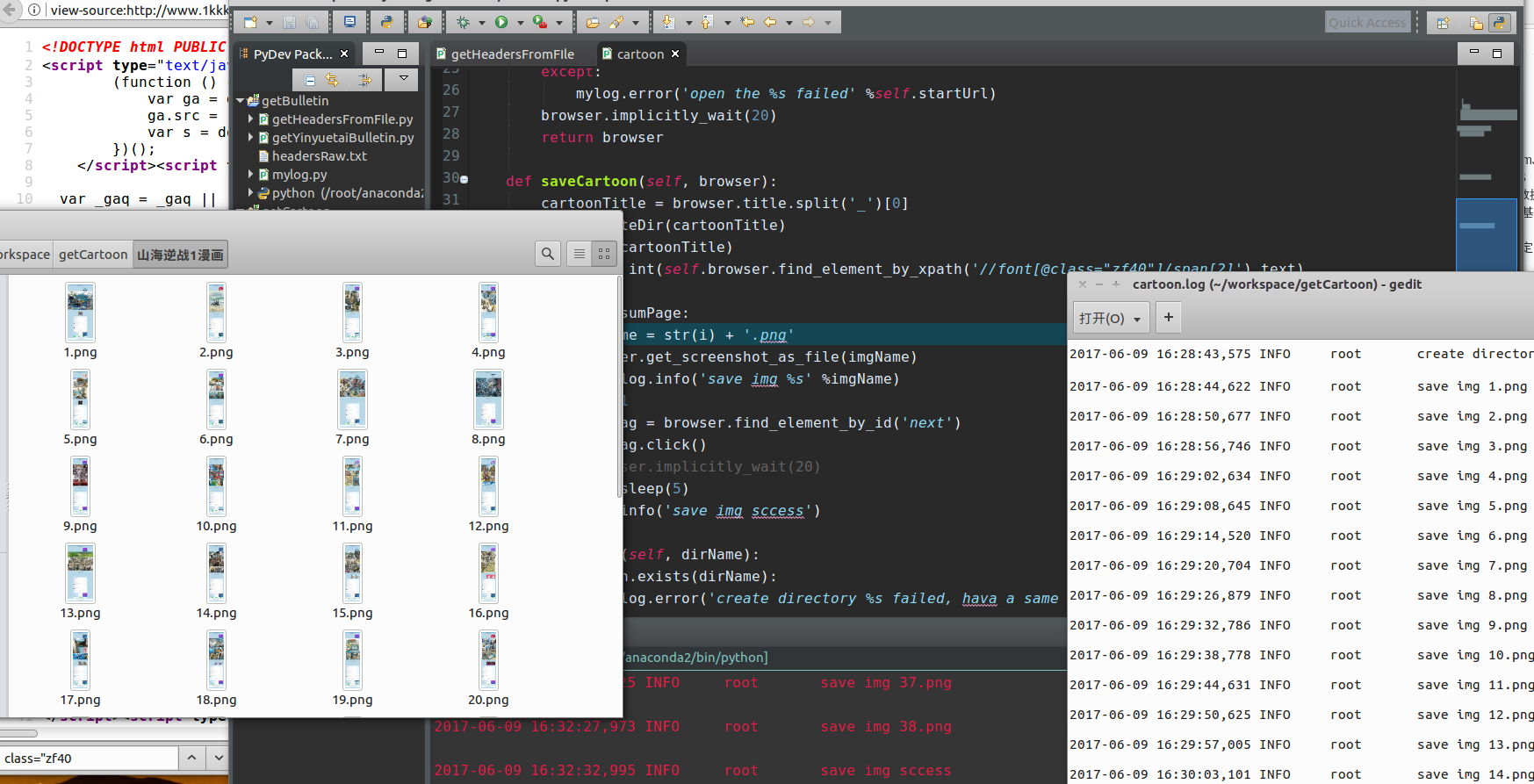
生成
- cartoon.log 日志文件
- ghostdriver.log PhantomJS日志文件
- 山海逆战1漫画 漫画图片文件夹
参考资料
《Python网络爬虫实战》-胡松涛
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/209934.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
