大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
ENFRN 动态进化混合模型2010
摘要
跟据基因调控网络重建面临的三个问题:数据高维、时间动态、测量噪声,提出了一种多层进化训练的神经-模糊递归网络(ENFRN),可以用于描述潜在目标基因和调控的类型。
其中递归、自组织机构和进化训练等特点优化了弱调控关系,模糊的特性避免了噪声影响的问题,最后为每一组调控都给定了分数。方法最终在酵母的基准数集上进行了测试。
各个方法的特点
传统方法:
- Boolean Networks(布尔网络):只有0和1两个状态,不能表示中间的状态等级。
- Bayesian Networks(贝叶斯网络):不能考虑到时间动态性
- Dynamic Byesian Networks(动态贝叶斯网络):较高的计算复杂度
- linear additive regulation models(线性附加调控网络):不能计算非线性的动态基因调控网络
近期的方法:(相对于2010年)
- hybrid neuro-genetic algorithm(混合神经进化算法):当模型面对复杂动态基因时间序列时ANN可能会陷入局部陷阱中。
详情见https://blog.csdn.net/loveC__/article/details/88977410 - recurrent neural networks(RNNs,递归神经网络):虽然有自使用循环,反向链接,递归可以记录历史信息,但是没有recurrent fuzzy neural networks(RFNNs,递归模糊神经网络)表现好,模糊特性可以更好的处理不确定的噪声数据。
算法
由于算法较为复杂,故此大致描述一下算法的整体流程,核心结构是一个5层的递归神经模糊网络,通过三次对其优化,得到基因调控之间的调控类型和潜在调控关系。其中最初第一次初始化网络结构,接着第二次优化使用BPSO对网络的结构进行优化,最后使用PSO对网络结构参数进行微调,对每个基因分配Regulation Score(RS)和Regulation Type。
ENFRN 5层结构
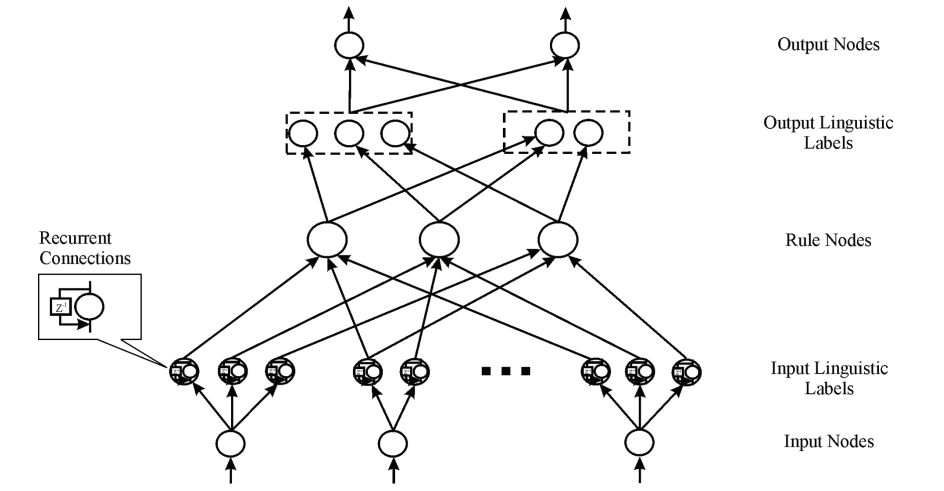

ϕ i ( k ) \phi_i^{(k)} ϕi(k)表示节点 i i i在第 k k k层上的输入, Ψ i ( k ) \Psi_i^{(k)} Ψi(k)表示节点 i i i在第 k k k层上的输出。
1. 第一层:第一层为输入层,每个节点直接输入变量到下一层中
Ψ i ( 1 ) = ϕ i ( 1 ) = x i \Psi_i^{(1)}= \phi_i^{(1)}=x_i Ψi(1)=ϕi(1)=xi
2. 第二层:标签语言输入层,该层中的每个节点表示一个高斯隶属函数,该函数对应于一个语言标签
Ψ i j ( 2 ) = e x p ( ( ϕ i j ( 2 ) − c i j ) 2 σ i j 2 ) \Psi_{ij}^{(2)} = exp \Bigg({\frac {(\phi_{ij}^{(2)}-c_{ij})^2}{\sigma_{ij}^2}} \Bigg) Ψij(2)=exp(σij2(ϕij(2)−cij)2)
其中 c i j c_{ij} cij代表均值, σ \sigma σ表示标准差, Ψ i j \Psi_{ij} Ψij表示第 i i i个输入变量的第 j j j个隶属函数。在第二层中有递归的结构,这一层中每一个节点的输入的某个时间点为 t t t:
ϕ i j ( 2 ) ( t ) = x i ( t ) + β i j ⋅ Ψ i j ( 2 ) ( t − 1 ) \phi_{ij}^{(2)}(t) = x_i(t)+\beta_{ij} \cdot \Psi_{ij}^{(2)}(t-1) ϕij(2)(t)=xi(t)+βij⋅Ψij(2)(t−1)
其中 β i j \beta_{ij} βij表示反馈单元的链接权重, ϕ i j \phi_{ij} ϕij表示第 i i i个输入变量的第 j j j个隶属函数。可以从公式看出其中 Ψ i j ( 2 ) \Psi_{ij}^{(2)} Ψij(2)是节点上一个时间的输出,作为了现在隶属函数中的输入。此公式表示了第二层的递归链接的方式,保存了每一层的过去状态的信息。
3. 第三层:规则层,包括所有的规则节点,每一个节点都匹配一个规则,后面将会详细讲述,第三层节点的添加规则。
Ψ i ( 3 ) = ∏ i ϕ i ( 3 ) \Psi_i^{(3)} = \prod_i \phi_i^{(3)} Ψi(3)=i∏ϕi(3)
其中:
∏ i ϕ i ( 3 ) = e x p ( − [ D i ( ϕ i ( 2 ) − c i ) ] T [ D i ( ϕ i ( 2 ) − c i ) ] ) \prod_i \phi_i^{(3)} = exp \Bigg( -[D_i \big(\phi_i^{(2)}-c_i \big)]^T[D_i \big(\phi_i^{(2)} -c_i \big)] \Bigg) i∏ϕi(3)=exp(−[Di(ϕi(2)−ci)]T[Di(ϕi(2)−ci)])
每个规则节点的输出,对应这个规则的触发强度。
4. 第四层:ENFRN对输出进行分区,这些节点被称为语言节点,对应于模糊规则的后面部分。
Ψ i ( 4 ) = ∑ i ϕ i ( 4 ) \Psi_i^{(4)} = \sum_i \phi_i^{(4)} Ψi(4)=i∑ϕi(4)
当前层的每个节点的输出,是规则层中规则节点的和(这些规则层中对应节点的结果是当前节点)。
5. 第五层:输出层,去模糊过程
y j = Ψ i ( 5 ) = ∑ i w i j ϕ i ( 5 ) ∑ i ϕ i ( 5 ) y_j = \Psi_i^{(5)} = \frac {\sum_i w_{ij}\phi_i^{(5)}}{\sum_i \phi_i^{(5)}} yj=Ψi(5)=∑iϕi(5)∑iwijϕi(5)
w i j w_{ij} wij是输出层模糊集的宽度。ENFRN为对应输出变量计算预测值。
算法分为三大部分:
- 第一部分:5层结构的创建。首先需要对第三层规则层进行初始化,初始化规则节点,通过训练集得到规则层的规则节点数量。
- 第二部分:使用BPSO对ENFRN进行优化和学习,这一层主要优化ENFRN的结构,简化模型,降低冗余的规则。
- 第三部分:使用PSO对ENFRN中的具体参数进行学习优化。
实验结果
由于论文中链接失效,无法获取数据集和测试集,最终在网络上找到了cdc_15和cdc_28的时间序列测试集,使用cdc_15作为训练集,cdc_28作为测试集,得到以下结果。
| a/a | Regulator | Type | Target | Train Composite Score | Test Composite Score |
|---|---|---|---|---|---|
| 1 | Gene5 | + | Gene1 | 0.32194 | 0.26300 |
| 2 | Gene3 | – | Gene1 | 31.19813 | 32.06183 |
| 3 | Gene4 | + | Gene4 | 30.34433 | 30.25702 |
| 4 | Gene5 | + | Gene6 | 0.39765 | 0.31757 |
| 5 | Gene12 | + | Gene6 | 0.39765 | 0.31757 |
| 6 | Gene6 | + | Gene7 | 0.33661 | 0.20830 |
| 7 | Gene8 | + | Gene7 | 0.33661 | 0.22057 |
| 8 | Gene1 | – | Gene7 | 0.52834 | 0.40458 |
| 9 | Gene9 | – | Gene10 | 30.38451 | 29.63479 |
由于数据中没有基因的名称,故对基因进行了1-12进行了编号,从数据可以看出,从12个基因中得到了9组调控信息,其中+代表积极调控(Up Regulation)
-代表不稳定调控(UnStable Regulation)。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/206817.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
